什么是视频AI大模型?
视频 AI 大模型是一种利用先进的机器学习技术来生成、处理和理解视频内容的大规模人工智能模型
视频AI生成原理
(1)生成对抗网络(GANs)
由生成器和判别器组成。生成器负责生成逼真的视频,判别器则用于区分真实视频和生成的视频,二者通过对抗训练不断提升生成视频的质量。
(2)变分自编码器(VAEs)
先通过编码器将输入视频编码为潜在空间的分布,再由解码器从潜在空间生成视频,以此学习视频的潜在表示来生成新视频。
(3)扩散模型
逐步将噪声转化为清晰的视频,在多步过程中利用深度学习逐步去除噪声,从而生成高质量的视频。
视频AI大模型应用场景?
(1)内容创作
根据文本描述、图像或脚本自动生成视频内容,广泛应用于影视制作、广告创作等领域,还能为虚拟现实与增强现实创建逼真的虚拟环境和场景。
(2)娱乐和媒体
生成或修改视频中的特效和动画,应用于电影特效、游戏动画等,也可根据用户喜好和行为生成个性化的视频内容。
(3)研究与教育
在教育和培训中生成虚拟场景和模拟环境,辅助学习和实践,还可用于生成和分析医学视频数据,辅助医学研究和临床诊断。
视频AI大模型
EMO(表达性音频驱动的人像视频生成)
EMO是阿里提出的一种表达性音频驱动的人像视频生成框架。输入单个参考图像和语音音频,例如说话唱歌,该方法可以生成具有表达性面部表情和各种头部姿势的语音化身视频,同时,它可以根据输入视频的长度生成任何持续时间的视频。
项目主页:https://humanaigc.github.io/emote-portrait-alive
代码链接:https://github.com/HumanAIGC/EMO
论文链接:https://arxiv.org/abs/2402.17485.pdf

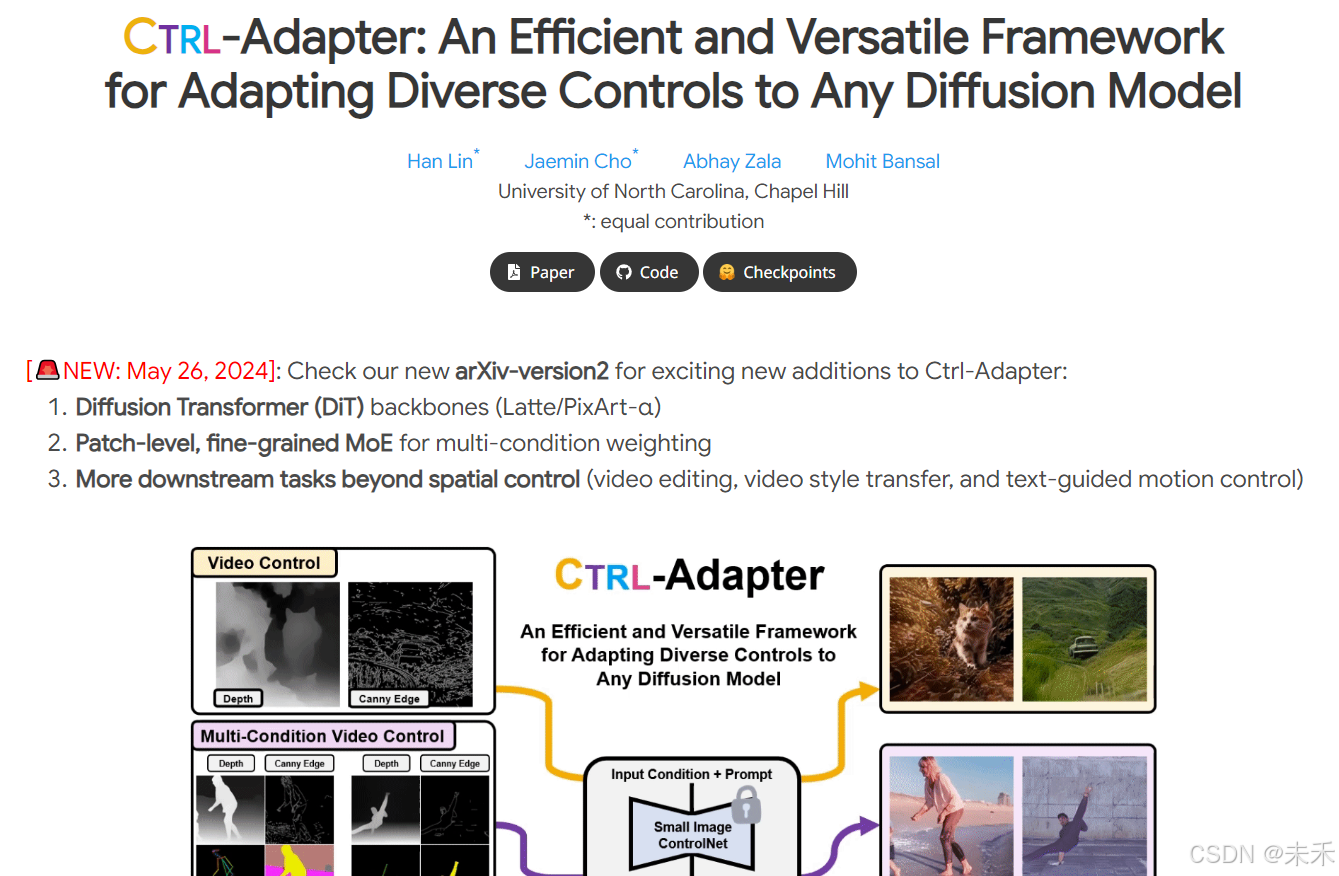
Ctrl-Adapter(多条件控制)
Ctrl-Adapter提供强大而多样的功能,包括图像控制、视频控制、稀疏帧视频控制、多条件控制、与不同骨干模型的兼容性、对看不见的控制条件的适应以及视频编辑。
项目主页:https://ctrl-adapter.github.io
代码链接:https://github.com/HL-hanlin/Ctrl-Adapter
论文链接:https://arxiv.org/pdf/2404.09967.pdf

Runway Gen-2
《瞬息全宇宙》幕后技术公司 Runway 获谷歌投资,以加速 AI 在影视创作中的应用。Runway 公开了旗下具有 AI 功能的视频编辑工具 Gen-2,用户可以直接使用文本提示生成“逼真的视频内容”并“自动剪辑视频”。
Dreamina
即梦(Dreamina)是字节跳动旗下剪映推出的一站式 AI 创作平台,支持文生图、图生图、文生视频、图生视频等功能,具备智能画布、故事创作等特色,以简洁易用的操作、丰富多样的生成效果,为专业创作者和普通用户提供了便捷、智能的创意表达与内容创作服务。
官方地址:https://jimeng.jianying.com
体验地址:https://jimeng.jianying.com/ai-tool/home
可灵
快手可灵采用类 Sora 的 DiT 结构,能生成长达 2 分钟、30fps、1080p 分辨率且支持多种宽高比的视频,具备模拟物理世界特性、概念组合等强大能力 ,已推出独立 App 并形成多端跨平台产品矩阵。
官方地址:https://kling.kuaishou.com
体验地址:https://klingai.kuaishou.com/
Dream Machine
Dream Machine 是 Luma AI 于 2024 年 6 月推出的 AI 视频生成模型,支持文本和图像输入,能在 5 秒内生成 120 帧高质量视频,具备电影级摄影效果和智能相机运动,提供免费试用,适用于内容创作者。
官方地址:https://lumalabs.ai/dream-machine
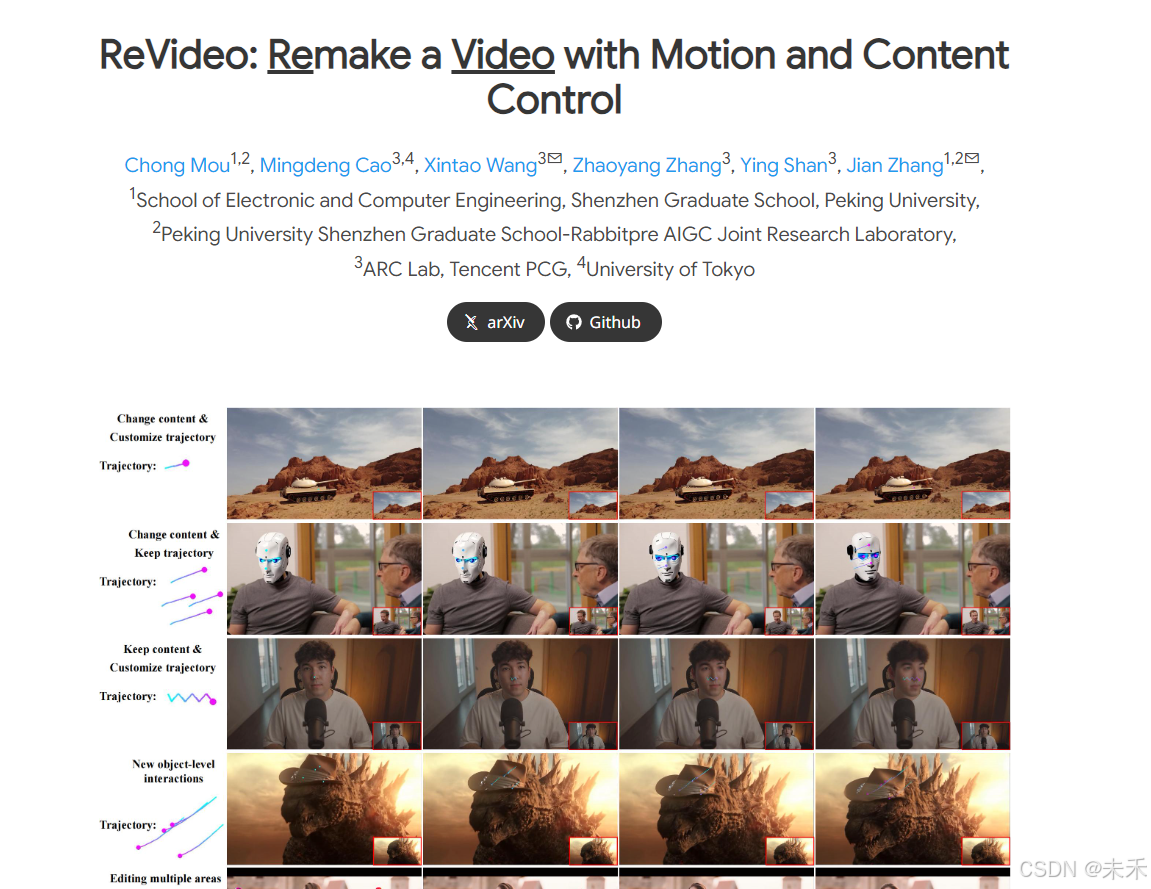
Revideo
Revideo 是由腾讯联合北大研发的 AI 视频编辑工具,基于扩散模型实现局部内容与运动轨迹的精确控制,支持通过修改首帧和指定运动路径编辑视频特定区域,可同时调整内容与动作或保持其一不变,适用于影视后期、短视频创作等场景。
项目地址:https://mc-e.github.io/project/ReVideo/