国外AI大模型(OpenAI、Anthropic、Gemini、Copilot、Llama3、xAI、Groq、BloombergGPT)
OpenAI(OpenAI o1|SearchGPT)
OpenAI is an AI research and deployment company. Our mission is to ensure that artificial general intelligence benefits all of humanity.
OpenAI 是一家人工智能研究和部署公司。我们的使命是确保通用人工智能造福全人类。
Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.
我们的使命是确保通用人工智能(通常比人类更智能的 AI 系统)造福全人类。
We are governed by a nonprofit and our unique capped-profit model drives our commitment to safety. This means that as AI becomes more powerful, we can redistribute profits from our work to maximize the social and economic benefits of AI technology.
我们由非营利组织管理,我们独特的利润上限模式推动了我们对安全的承诺。这意味着,随着 AI 变得越来越强大,我们可以重新分配我们工作的利润,以最大限度地发挥 AI 技术的社会和经济效益。
维基百科:https://zh.wikipedia.org/wiki/OpenAI
OpenAI About:https://openai.com/about
OpenAI创始于2015年,当时Elon Musk和Sam Altman等一群科技界领军人物,在门洛帕克的一个晚餐聚集。他们基于共同的愿景——构建安全的人工智能以造福人类,决定一起创建一个非营利性机构。
OpenAI,是一个美国人工智能研究实验室,由非营利组织OpenAI Inc,和其营利组织子公司OpenAI LP所组成。OpenAI进行AI研究的目的是促进和发展友好的人工智能,使人类整体受益。OpenAI系统运行在微软基于Azure的超级计算平台上。
该组织于2015年由萨姆·阿尔特曼、里德·霍夫曼、杰西卡·利文斯顿、伊隆·马斯克、伊尔亚·苏茨克维、沃伊切赫·萨伦巴、彼得·泰尔等人在旧金山成立,他们共同认捐了10亿美元。微软在2019年向OpenAI LP提供了10亿美元的投资,并在2023年1月向其提供了第二笔多年投资,据报导为100亿美元,用于独家授权使用GPT-4,这将为微软自己的Bing Prometheus模型提供支持。
发展历史
2015–2018年:作为非营利机构起步
2015年底,萨姆·阿尔特曼、格雷格·布洛克曼、里德·霍夫曼、杰西卡·利文斯顿、彼得·蒂尔、伊隆·马斯克、亚马逊云计算(AWS)、印孚瑟斯和YC Research宣布成立OpenAI,并承诺向这个项目投入超过10亿美元。该组织表示将通过向公众开放其专利和研究,并与其他机构和研究者“自由合作”。OpenAI的总部设于旧金山教会区的先锋大厦。
据《连线》杂志报道,布洛克曼会见了深度学习“创始人”之一的约书亚·本希奥,并列出了该领域的“最佳研究者”名单。在2015年12月,布洛克曼成功聘请了其中的九位作为首批员工。2016年,OpenAI支付了公司级别(而非营利组织级别)的薪水,但并未支付与Facebook或谷歌相当的AI研究者薪水。
微软的Peter Lee表示,顶级AI研究者的成本超过了顶级NFL四分卫新秀的成本。OpenAI的潜力和使命吸引了这些研究者来到这个公司;一位谷歌员工表示,他愿意离开谷歌去OpenAI,“部分原因是因为那里有一群非常强大的人,而更大程度上,是因为它的使命。”布洛克曼表示,"我能想象到的最好的事情就是以安全的方式推动人类更接近真正的AI。"OpenAI联合创始人沃伊切赫·扎伦巴表示,他拒绝了"近乎疯狂"的报价,这些报价是他市场价值的两到三倍,而他选择加入OpenAI。
2016年,OpenAI宣称将制造“通用”机器人,希望能够预防人工智能的灾难性影响,推动人工智能发挥积极作用。4月,OpenAI发布了“OpenAI Gym”的公共测试版,这是其强化学习研究平台。12月,OpenAI发布了“Universe”,这是一个软件平台,用于测量和训练AI在全球游戏、网站和其他应用中的通用智能。
2017年,OpenAI仅在云计算上就花费了$790万美元,占其职能支出的四分之一。相比之下,DeepMind2017年的总支出为$4.42亿美元。2018年夏天,仅仅训练OpenAI的Dota 2机器人就需要从谷歌租用128,000个CPU和256个GPU,持续数周。
2018年2月,马斯克辞去了董事会席位,理由是与他作为特斯拉首席执行官的角色存在“潜在的未来(利益)冲突”因为特斯拉为自动驾驶汽车开发人工智能,萨姆·阿尔特曼声称马斯克认为OpenAI已经落后于谷歌等其他公司,马斯克提议自己接管OpenAI,但董事会拒绝了。马斯克随后将离开OpenAI,但声称仍然是捐赠者,但在他离开后没有进行任何捐赠。
2019年:向营利性公司转型,2019年3月1日成立OpenAI LP子公司,目的为营利所用。
该公司随后向其员工分配股权并与微软合作,宣布向该公司投资10亿美元。2019年7月22日微软投资OpenAI $10亿美元,双方将携手合作替Azure云端平台服务开发人工智能技术。OpenAI还宣布打算对其技术进行商业许可。OpenAI计划“在五年内,而且可能更快”花费这10亿美元。萨姆·阿尔特曼表示,即使是10亿美元也可能不够,实验室最终可能需要“比任何非营利组织筹集到的资金都多的资金”来实现通用人工智能。
2020年至今:ChatGPT、Sora、DALL-E以及与微软的合作伙伴关系
2020年6月11日宣布了GPT-3语言模型,微软于2020年9月22日获取独家授权。
2021年,OpenAI推出了DALL-E,这是一种深度学习模型,可以从自然语言描述中生成数字图像
2022年11月30日,OpenAI发布了一个名为ChatGPT的自然语言生成式模型[43],它以对话方式进行交互。在研究预览期间,用户注册并登陆后可免费使用ChatGPT。[44]。根据OpenAI的说法,预览版在前五天内收到了超过一百万的注册。据路透社2022年12月援引的匿名消息来源称,OpenAI 预计2023年收入为$2亿美元,2024年收入为$10亿美元[46]。但是该项目对一些包括中国大陆、香港在内的地区暂不可用。
2023年3月2日,OpenAI发布了官方ChatGPT API,并允许第三方开发者利用该API将ChatGPT集成到他们的网站、产品和服务中
2023年3月3日,霍夫曼辞去了他的董事会席位,理由是希望避免他在OpenAI的董事会席位与他通过格雷洛克合伙公司(Greylock Partners)对AI技术公司的投资之间的利益冲突,以及他作为OpenAI的联合创始人的角色AI技术初创公司Inflection AI。霍夫曼仍然是OpenAI的主要投资者微软的董事会成员。
2023年3月14日,OpenAI发布了GPT-4,既作为API(带有waiting list)又作为ChatGPT Plus的一项功能。
2024年2月15日,OpenAI发布了Sora,称该模型能够生成长达一分钟的视频。同时,OpenAI也承认了该技术的一些缺点,包括在模拟复杂物理现象方面的困难。
2024年4月1日,OpenAI表示将许可用户在无注册的前提下直接使用ChatGPT。
2024年5月13日,OpenAI发布了新模型GPT-4o,GPT-4o可以处理文字、语音、图像,“o”代表“omni”,即全能的意思。
2024年6月25日,OpenAI表示自7月9日起,将停止对中国开发者提供API接口服务。
2024年11月,OpenAI收购了历史悠久的域名Chat.com,并将Chat.com重定向至ChatGPT。
2024年12月5日,OpenAI启动了“12 Days of OpenAI”活动,推出了多个重要更新,包括对ChatGPT和o1模型的重大改进。
2024年12月6日,扩展了强化学习微调研究计划,允许开发者和研究人员针对特定任务进行模型微调。
2024年12月9日,发布了Sora Turbo,一个先进的视频生成模型,允许用户生成文本到视频和视频到视频的内容。
2024年12月10日,Canvas交互式工作区正式上线,集成到GPT-4o中,用户可以运行Python代码并管理项目。
2024年12月11日,Apple将ChatGPT集成到iOS 18.2中,增强了Siri和写作工具的功能。
2024年12月12日,发布会当天,OpenAI宣布了“圣诞老人模式”,用户可以通过新的声音功能与ChatGPT进行互动,同时推出了屏幕共享功能。
2024年12月13日,引入“项目”工具,帮助用户组织对话,并允许用户将聊天分组和添加上下文。
2024年12月16日,扩展了ChatGPT的搜索功能,使所有用户都能访问网络浏览。
2024年12月17日,举办“迷你开发者日”,专注于开发者更新和API支持。
2024年12月18日,ChatGPT通过电话和WhatsApp提供服务,用户可以免费拨打1-800-ChatGPT进行咨询。
2024年12月19日,推出新的MacOS桌面应用程序,并与多种应用程序集成。
2024年12月20日,宣布推出o3和o3-mini模型,进一步提升推理能力。
OpenAI o1(推理)
OpenAI o1-preview (简介)
We’ve developed a new series of AI models designed to spend more time thinking before they respond. They can reason through complex tasks and solve harder problems than previous models in science, coding, and math.
我们开发了一系列新的 AI 模型,旨在花更多时间思考,然后再做出响应。他们可以推理完成复杂的任务并解决比以前的科学、编码和数学模型更难的问题。
How it works (运作方式
)
We trained these models to spend more time thinking through problems before they respond, much like a person would. Through training, they learn to refine their thinking process, try different strategies, and recognize their mistakes. .
我们训练这些模型在问题做出响应之前花更多时间思考问题,就像一个人一样。通过培训,他们学会完善自己的思维过程,尝试不同的策略,并认识到自己的错误。
In our tests, the next model update performs similarly to PhD students on challenging benchmark tasks in physics, chemistry, and biology. We also found that it excels in math and coding. In a qualifying exam for the International Mathematics Olympiad (IMO), GPT-4o correctly solved only 13% of problems, while the reasoning model scored 83%. Their coding abilities were evaluated in contests and reached the 89th percentile in Codeforces competitions. You can read more about this in our technical research post.
在我们的测试中,下一次模型更新的性能类似于博士生在物理、化学和生物学中具有挑战性的基准任务。我们还发现它在数学和编码方面表现出色。在国际数学奥林匹克竞赛 (IMO) 的资格考试中,GPT-4o 仅正确解决了 13% 的问题,而推理模型得分为 83%。他们的编码能力在比赛中得到了评估,并在 Codeforces 比赛中达到了第 89 个百分位。您可以在我们的技术研究帖子中阅读更多相关信息。
As an early model, it doesn’t yet have many of the features that make ChatGPT useful, like browsing the web for information and uploading files and images. For many common cases GPT-4o will be more capable in the near term.
作为早期模型,它还不具备使 ChatGPT 有用的许多功能,例如浏览网页以获取信息以及上传文件和图像。对于许多常见情况,GPT-4o 在短期内会更有能力。
But for complex reasoning tasks this is a significant advancement and represents a new level of AI capability. Given this, we are resetting the counter back to 1 and naming this series OpenAI o1.
但对于复杂的推理任务来说,这是一个重大进步,代表了 AI 能力的新水平。鉴于此,我们将计数器重置回 1 并将此系列命名为 OpenAI o1。
Safety (安全)
As part of developing these new models, we have come up with a new safety training approach that harnesses their reasoning capabilities to make them adhere to safety and alignment guidelines. By being able to reason about our safety rules in context, it can apply them more effectively.
作为开发这些新模型的一部分,我们提出了一种新的安全培训方法,该方法利用他们的推理能力使他们遵守安全和对齐准则。通过能够在上下文中推理我们的安全规则,它可以更有效地应用它们。
One way we measure safety is by testing how well our model continues to follow its safety rules if a user tries to bypass them (known as “jailbreaking”). On one of our hardest jailbreaking tests, GPT-4o scored 22 (on a scale of 0-100) while our o1-preview model scored 84. You can read more about this in the system card and our research post.
我们衡量安全性的一种方法是,在用户试图绕过安全规则(称为“越狱”)时,我们的模型继续遵守其安全规则的程度。在我们最难的越狱测试之一中,GPT-4o 得分为 22(0-100 分),而我们的 o1-preview 模型得分为 84。您可以在系统卡和我们的研究帖子中阅读更多相关信息。
To match the new capabilities of these models, we’ve bolstered our safety work, internal governance, and federal government collaboration. This includes rigorous testing and evaluations using our Preparedness Framework(opens in a new window), best-in-class red teaming, and board-level review processes, including by our Safety & Security Committee.
为了匹配这些模型的新功能,我们加强了安全工作、内部治理和联邦政府合作。这包括使用我们的准备框架进行严格的测试和评估,一流的红队,以及包括我们的安全与保障委员会在内的董事会级审查流程。
To advance our commitment to AI safety, we recently formalized agreements with the U.S. and U.K. AI Safety Institutes. We’ve begun operationalizing these agreements, including granting the institutes early access to a research version of this model. This was an important first step in our partnership, helping to establish a process for research, evaluation, and testing of future models prior to and following their public release.
为了推进我们对 AI 安全的承诺,我们最近与美国和英国 AI 安全研究所正式达成协议。我们已经开始实施这些协议,包括允许这些机构提前获得该模型的研究版本。这是我们合作中重要的第一步,有助于建立未来模型公开发布之前和之后的研究、评估和测试流程。
Whom it’s for (适用对象)
These enhanced reasoning capabilities may be particularly useful if you’re tackling complex problems in science, coding, math, and similar fields. For example, o1 can be used by healthcare researchers to annotate cell sequencing data, by physicists to generate complicated mathematical formulas needed for quantum optics, and by developers in all fields to build and execute multi-step workflows.
如果您正在处理科学、编码、数学和类似领域的复杂问题,这些增强的推理功能可能特别有用。例如,医疗保健研究人员可以使用它来注释细胞测序数据,物理学家可以使用它来生成量子光学所需的复杂数学公式,所有领域的开发人员都可以使用它来构建和执行多步骤工作流程。
OpenAI o1-mini (OpenAI o1-迷你)
The o1 series excels at accurately generating and debugging complex code. To offer a more efficient solution for developers, we’re also releasing OpenAI o1-mini, a faster, cheaper reasoning model that is particularly effective at coding. As a smaller model, o1-mini is 80% cheaper than o1-preview, making it a powerful, cost-effective model for applications that require reasoning but not broad world knowledge.
o1 系列擅长准确生成和调试复杂代码。为了向开发人员提供更高效的解决方案,我们还发布了 OpenAI o1-mini,这是一种更快、更便宜的推理模型,在编码方面特别有效。作为较小的模型,o1-mini 比 o1-preview 便宜 80%,使其成为一个功能强大、经济高效的模型,适用于需要推理但不需要广泛世界知识的应用程序。
How to use OpenAI o1 (如何使用 OpenAI o1)
ChatGPT Plus and Team users will be able to access o1 models in ChatGPT starting today. Both o1-preview and o1-mini can be selected manually in the model picker, and at launch, weekly rate limits will be 30 messages for o1-preview and 50 for o1-mini. We are working to increase those rates and enable ChatGPT to automatically choose the right model for a given prompt.
从今天开始,ChatGPT Plus 和 Team 用户将能够访问 ChatGPT 中的 o1 模型。o1-preview 和 o1-mini 都可以在模型选取器中手动选择,在启动时,o1-preview 的每周速率限制为 30 条消息,o1-mini 的每周速率限制为 50 条消息。我们正在努力提高这些比率,并使 ChatGPT 能够自动为给定的提示选择正确的模型。
ChatGPT Enterprise and Edu users will get access to both models beginning next week.
从下周开始,ChatGPT Enterprise 和 Edu 用户将可以访问这两种模型。
Developers who qualify for API usage tier 5(opens in a new window) can start prototyping with both models in the API today with a rate limit of 20 RPM. We’re working to increase these limits after additional testing. The API for these models currently doesn’t include function calling, streaming, support for system messages, and other features. To get started, check out the API documentation(opens in a new window).
符合API 使用层 5(在新窗口中打开)条件的开发人员现在可以在 API 中开始使用这两种模型进行原型设计,速率限制为 20 RPM。我们正在努力在进行额外测试后提高这些限制。这些模型的 API 目前不包括函数调用、流式处理、对系统消息的支持和其他功能。要开始使用,请查看 API 文档(在新窗口中打开)。
We also are planning to bring o1-mini access to all ChatGPT Free users.
我们还计划为所有 ChatGPTFree 用户提供 o1-mini 访问权限。
What’s next 下一步
This is an early preview of these reasoning models in ChatGPT and the API. In addition to model updates, we expect to add browsing, file and image uploading, and other features to make them more useful to everyone.
这是 ChatGPT 和 API 中这些推理模型的早期预览。除了模型更新之外,我们还希望添加浏览、文件和图像上传以及其他功能,使其对每个人都更有用。
We also plan to continue developing and releasing models in our GPT series, in addition to the new OpenAI o1 series.
除了新的 OpenAI o1 系列之外,我们还计划继续开发和发布 GPT 系列中的模型
Anthropic(Claude 3.5 Sonnet)
Claude官网:https://www.anthropic.com/
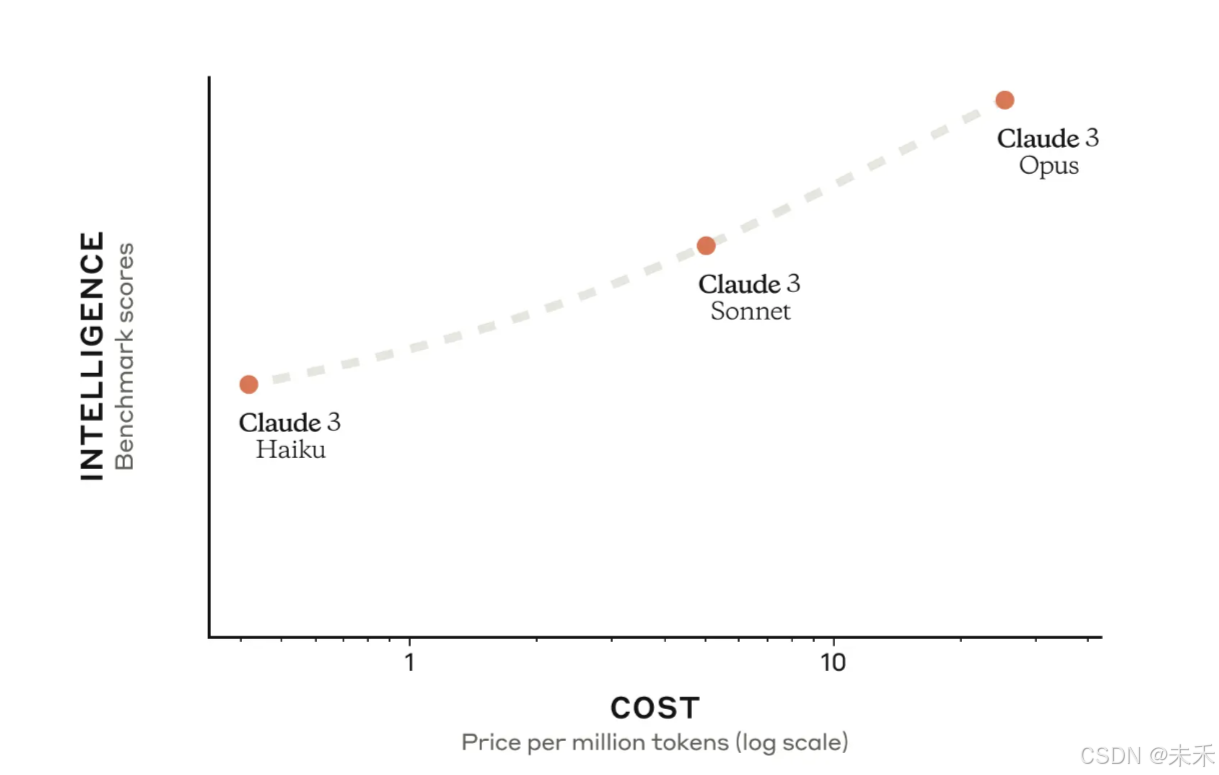
2024年3月4日,宣布推出 Claude 3 模型系列,它为广泛的认知任务树立了新的行业基准。该系列包括三种最先进的型号(按功能升序排列):Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。每个后续型号都提供越来越强大的性能,允许用户为其特定应用选择智能、速度和成本的最佳平衡。
Opus 和 Sonnet 现已可在 claude.ai 中使用,而 Claude API 现已在159 个国家/地区广泛使用。
Claude 3模型家族
智能的新标准
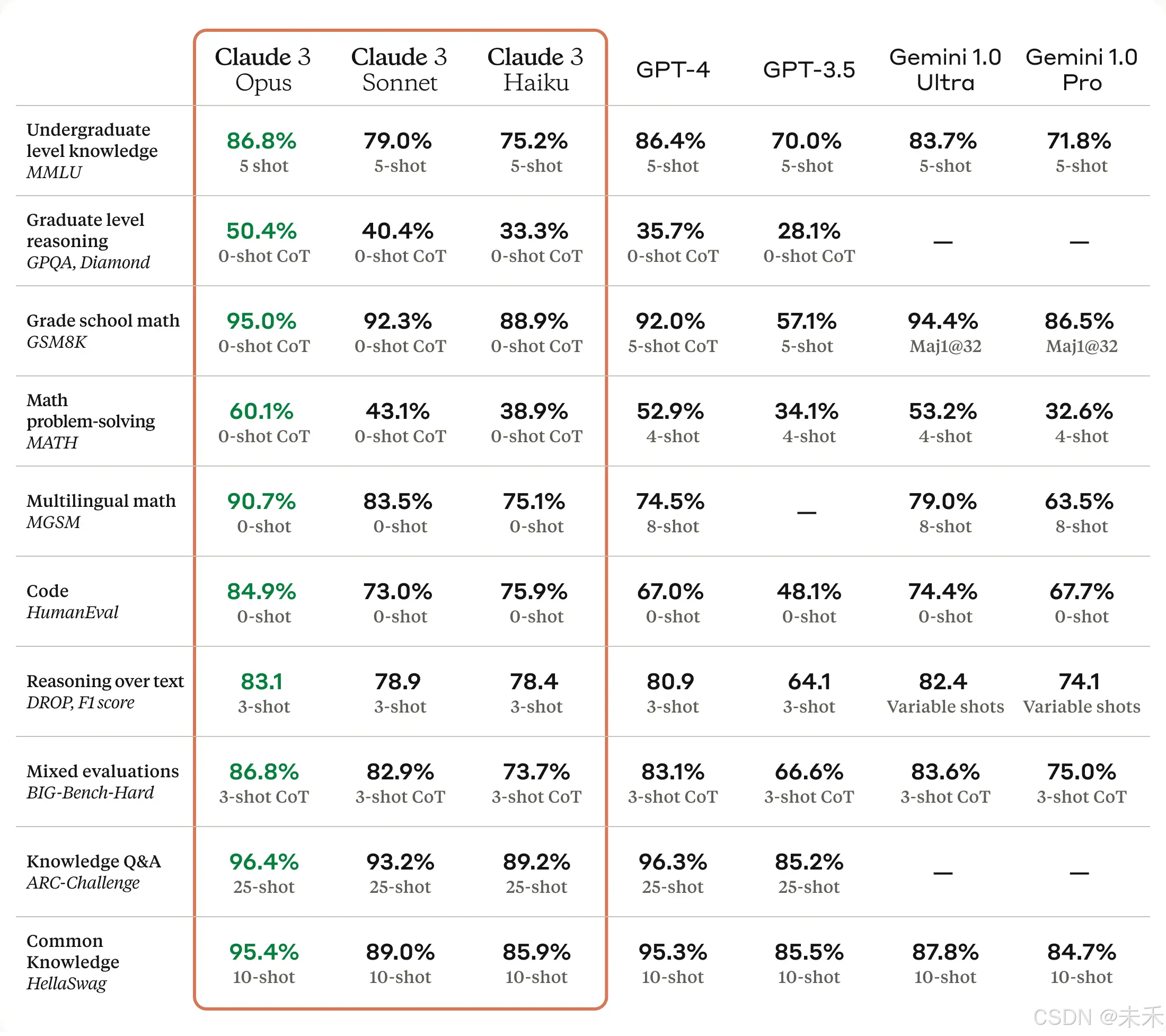
Opus 是我们最智能的模型,在人工智能系统的大多数常见评估基准上都优于同行,包括本科水平专家知识 (MMLU)、研究生水平专家推理 (GPQA)、基础数学 (GSM8K) 等。它在复杂任务上表现出接近人类水平的理解力和流畅性,引领通用智能的前沿。
所有Claude 3模型都显示出在分析和预测、细致内容创建、代码生成以及西班牙语、日语和法语等非英语语言对话方面的增强能力。
以下是 Claude 3 模型与我们的同行模型在多个性能基准上的比较:
近乎即时的结果
Claude 3 模型可以支持实时客户聊天、自动完成和数据提取任务,其中响应必须立即且实时。
Haiku 是智能类别市场上速度最快且最具成本效益的型号。它可以在不到三秒的时间内阅读 arXiv 上包含图表和图形的信息和数据密集的研究论文(约 10k 代币)。发布后,我们期望进一步提高性能。
对于绝大多数工作负载,Sonnet 的速度比 Claude 2 和 Claude 2.1 快 2 倍,且智能水平更高。它擅长执行需要快速响应的任务,例如知识检索或销售自动化。Opus 的速度与 Claude 2 和 2.1 相似,但智能水平更高。
强大的视觉能力
Claude 3 型号具有与其他领先型号相当的复杂视觉功能。他们可以处理各种视觉格式,包括照片、图表、图形和技术图表。我们特别高兴能够为我们的企业客户提供这种新模式,其中一些客户的知识库高达 50% 以各种格式编码,例如 PDF、流程图或演示幻灯片。

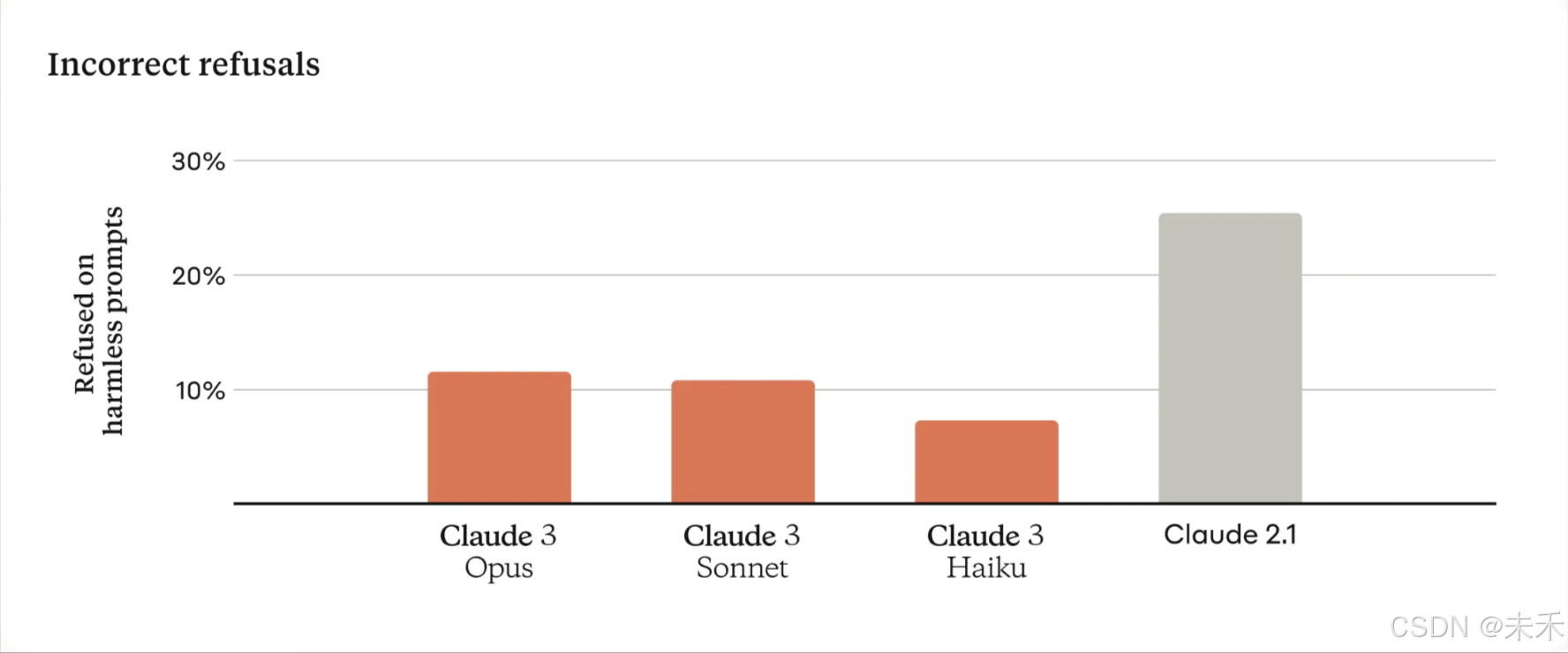
更少的拒绝
以前的Claude模型经常做出不必要的拒绝,这表明缺乏语境理解。我们在这一领域取得了有意义的进展:与前几代模型相比,Opus、Sonnet 和 Haiku 拒绝回答接近系统护栏的提示的可能性明显降低。如下所示,Claude 3 模型对请求表现出更细致的理解,能够识别真正的伤害,并且拒绝回答无害提示的频率要少得多
提高准确性
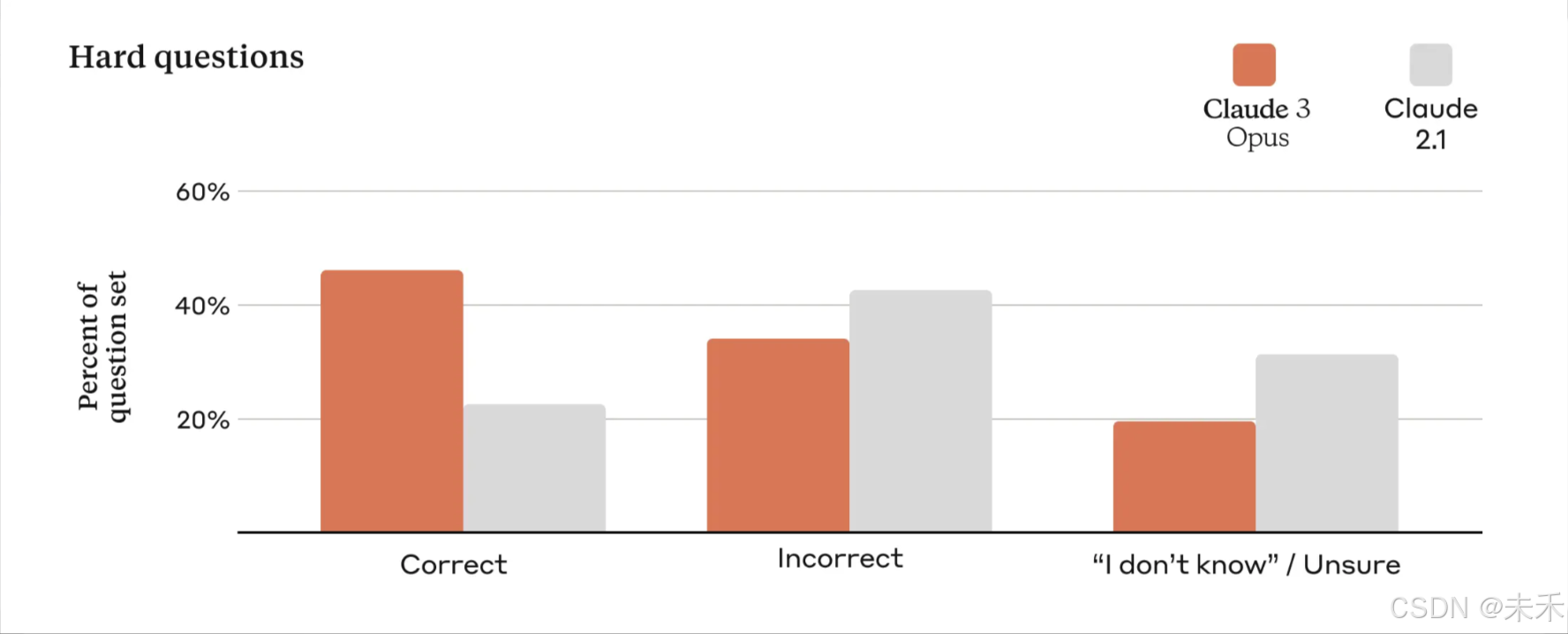
各种规模的企业都依赖Claude模型来为其客户提供服务,因此模型输出必须保持大规模的高精度。为了评估这一点,使用了大量复杂的事实问题来针对当前模型中已知的弱点。将答案分为正确答案、错误答案(或幻觉)和承认不确定性,其中模型表示它不知道答案,而不是提供不正确的信息。与 Claude 2.1 相比,Opus 在这些具有挑战性的开放式问题上的准确性(或正确答案)提高了一倍,同时也减少了错误答案的水平。
除了产生更值得信赖的回复之外,还将在 Claude 3 模型中启用引用,以便可以指出参考材料中的精确句子来验证他们的答案。
长上下文和近乎完美的回忆
Claude 3 系列型号在发布时最初将提供 200K 上下文窗口。然而,所有三种模型都能够接受超过 100 万个代币的输入,我们可能会将其提供给需要增强处理能力的精选客户。
为了有效地处理长上下文提示,模型需要强大的回忆能力。“大海捞针”(NIAH)评估衡量模型从大量数据中准确回忆信息的能力。我们通过在每个提示中使用 30 个随机针/问题对之一并在不同的众包文档库上进行测试,增强了该基准的稳健性。Claude 3 Opus 不仅实现了近乎完美的召回率,超过 99% 的准确率,而且在某些情况下,它甚至通过识别“针”这句话似乎是人类人为插入到原文中来识别评估本身的局限性。
负责任的设计
Claude 3 系列型号不仅功能强大,而且值得信赖。有几个专门的团队来跟踪和减轻广泛的风险,从错误信息和 CSAM 到生物滥用、选举干扰和自主复制技能。我们继续开发宪法人工智能等方法来提高模型的安全性和透明度,并调整我们的模型以减轻新模式可能引发的隐私问题。
解决日益复杂的模型中的偏差是一项持续的努力,在这个新版本中取得了长足的进步。如模型卡所示,根据问答 (BBQ) 偏差基准, Claude 3 显示的偏差比我们之前的模型要少。我们仍然致力于改进技术,减少偏见并促进我们模型的更大中立性,确保它们不偏向任何特定的党派立场。
虽然与之前的模型相比,Claude 3 模型系列在生物知识、网络相关知识和自主性的关键指标方面取得了进步,但根据负责任的扩展政策,它仍处于 AI 安全级别 2 (ASL-2) 。
更容易使用
Claude 3 模型更擅长遵循复杂的多步骤指令。特别擅长遵守品牌声音和响应准则,并开发用户可以信赖的面向客户的体验。此外,Claude 3 模型更擅长以 JSON 等格式生成流行的结构化输出,从而可以更轻松地指导 Claude 进行自然语言分类和情感分析等用例。
谷歌(Gemini)
官方地址:https://gemini.google.com/
Gemini 是一系列由 Google AI 和 DeepMind 共同开发的多模态语言模型。它的前身是 Google Bard,在 Bard 的基础上进行了多项重大改进,使其在各方面的性能都得到了大幅提升。Gemini 可以处理不同类型的信息,包括文本、代码、音频、图像和视频,从而具备了更强大的功能。
Gemini 简介:最大、能力最强的人工智能模型
谷歌和 Alphabet 首席执行官桑达尔·皮查伊 (Sundar Pichai) 的注释:
每一次技术变革都是推进科学发现、加速人类进步和改善生活的机会。我相信我们现在所看到的人工智能转变将是我们一生中最深刻的转变,远远大于之前向移动或网络的转变。人工智能有潜力为世界各地的人们创造从日常生活到非凡的机会。它将带来新一轮的创新和经济进步,并以我们从未见过的规模推动知识、学习、创造力和生产力。
这让我感到兴奋:有机会让人工智能为世界各地的每个人提供帮助。
作为一家人工智能优先的公司,我们已经走过了近八年的历程,进步的步伐只会不断加快:数百万人现在在我们的产品中使用生成式人工智能来完成一年前无法完成的事情,从寻找答案到更复杂的问题使用新工具进行协作和创造的问题。与此同时,开发人员正在使用我们的模型和基础设施来构建新的生成式人工智能应用程序,世界各地的初创公司和企业正在利用我们的人工智能工具不断成长。
这是令人难以置信的势头,然而,我们才刚刚开始触及可能性的表面。
我们正在大胆而负责任地开展这项工作。这意味着我们的研究要雄心勃勃,追求能够为人类和社会带来巨大利益的能力,同时建立保障措施并与政府和专家合作,应对人工智能变得更加强大的风险。我们继续投资最好的工具、基础模型和基础设施,并在我们的人工智能原则的指导下将它们引入我们的产品和其他产品。
现在,我们正在与 Gemini 一起迈出下一步,这是我们迄今为止功能最强大、最通用的模型,在许多领先的基准测试中都具有最先进的性能。我们的第一个版本 Gemini 1.0 针对不同尺寸进行了优化:Ultra、Pro 和 Nano。这些是 Gemini 时代的第一个模型,也是我们今年早些时候成立 Google DeepMind 时的愿景的首次实现。这个模型的新时代代表了我们作为一家公司所做出的最大的科学和工程努力之一。我对未来以及双子座将为世界各地的人们带来的机会感到由衷的兴奋。
Gemini 也是我们迄今为止最灵活的模型 - 能够在从数据中心到移动设备的所有设备上高效运行。其最先进的功能将显着增强开发人员和企业客户利用人工智能进行构建和扩展的方式。
针对三种不同的尺寸优化了 Gemini 1.0(第一个版本):
(1)Gemini Ultra:最大、最有能力的模型,适用于高度复杂的任务。
(2)Gemini Pro:可扩展各种任务的最佳模型。
(3)Gemini Nano:最高效的设备端任务模型。
最先进的性能
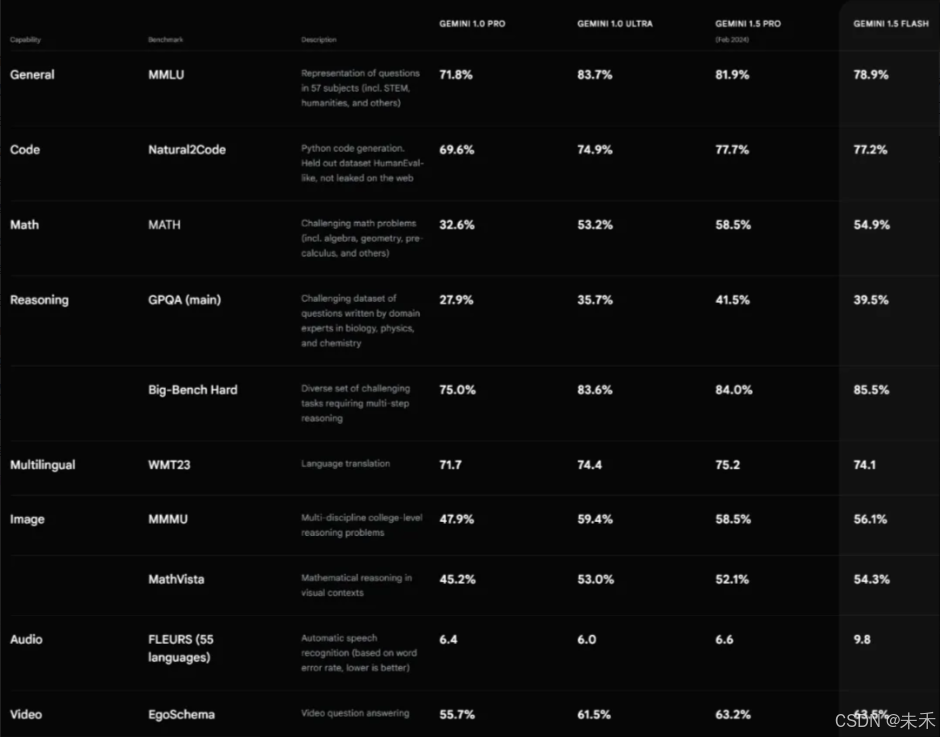
一直在严格测试 Gemini 模型并评估其在各种任务中的性能。从自然图像、音频和视频理解到数学推理,Gemini Ultra 的性能在大型语言模型 (LLM) 研发中使用的 32 个广泛使用的学术基准中的 30 个上超过了当前最先进的结果。
Gemini Ultra 的得分高达 90.0%,是第一个在MMLU(大规模多任务语言理解)上超越人类专家的模型,该模型结合了数学、物理、历史、法律、医学和伦理学等 57 个科目来测试知识和解决问题的能力。
新的 MMLU 基准方法使 Gemini 能够利用其推理能力在回答难题之前更仔细地思考,从而比仅使用第一印象有显着改进。
Gemini 在文本和编码等一系列基准测试中超越了最先进的性能。
Gemini Ultra 还在新的MMMU基准测试中取得了 59.4% 的最先进分数,该基准测试由跨越不同领域、需要深思熟虑的推理的多模态任务组成。
https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
根据我们测试的图像基准,Gemini Ultra 的性能优于以前最先进的模型,无需光学字符识别 (OCR) 系统从图像中提取文本以进行进一步处理的帮助。这些基准凸显了双子座天生的多模态性,并表明了双子座更复杂推理能力的早期迹象。
Gemini 在一系列多模式基准测试中超越了最先进的性能。
下一代功能
到目前为止,创建多模态模型的标准方法涉及针对不同模态训练单独的组件,然后将它们拼接在一起以粗略地模仿其中的一些功能。这些模型有时擅长执行某些任务,例如描述图像,但难以处理更概念性和复杂的推理。
将 Gemini 设计为原生多模式,从一开始就针对不同模式进行了预训练。然后使用额外的多模态数据对其进行微调,以进一步完善其有效性。这有助于 Gemini 从头开始无缝地理解和推理各种输入,远远优于现有的多模式模型 - 而且其功能几乎在每个领域都是最先进的。
复杂的推理
Gemini 1.0 复杂的多模式推理功能可以帮助理解复杂的书面和视觉信息。这使得它在发现大量数据中难以辨别的知识方面具有独特的能力。
其通过阅读、过滤和理解信息从数十万份文档中提取见解的卓越能力将有助于在从科学到金融的许多领域以数字速度实现新的突破。
理解文本、图像、音频等
Gemini 1.0 经过训练,可以同时识别和理解文本、图像、音频等,因此它可以更好地理解微妙的信息,并可以回答与复杂主题相关的问题。这使得它特别擅长解释数学和物理等复杂学科的推理。
高级编码
第一个版本的 Gemini 可以理解、解释和生成世界上最流行的编程语言(如 Python、Java、C++ 和 Go)的高质量代码。它跨语言工作和推理复杂信息的能力使其成为世界领先的编码基础模型之一。
Gemini Ultra 在多个编码基准测试中表现出色,包括HumanEval(用于评估编码任务性能的重要行业标准)和 Natural2Code(我们内部保留的数据集),该数据集使用作者生成的源而不是基于网络的信息。
Gemini 还可以用作更高级编码系统的引擎。两年前,我们推出了AlphaCode,这是第一个在编程竞赛中达到竞争性能水平的人工智能代码生成系统。
使用 Gemini 的专门版本,我们创建了更先进的代码生成系统AlphaCode 2,它擅长解决超出编码范围、涉及复杂数学和理论计算机科学的竞争性编程问题。
双子座擅长编码和竞争性编程
当在与原始 AlphaCode 相同的平台上进行评估时,AlphaCode 2 显示出巨大的改进,解决的问题数量几乎是原来的两倍,我们估计它的表现优于 85% 的竞赛参与者,而 AlphaCode 的这一比例接近 50%。当程序员通过为代码示例定义某些属性来与 AlphaCode 2 协作时,它的性能会更好。
我们很高兴程序员越来越多地使用功能强大的人工智能模型作为协作工具,帮助他们推理问题、提出代码设计并协助实施,这样他们就可以更快地发布应用程序并设计更好的服务。
更可靠、可扩展且高效
使用 Google 内部设计的张量处理单元(TPU) v4 和 v5e 在我们的 AI 优化基础设施上大规模训练 Gemini 1.0。我们将其设计为最可靠、最可扩展的训练模型,以及最高效的服务模型。
在 TPU 上,Gemini 的运行速度明显快于早期、较小且功能较差的型号。这些定制设计的人工智能加速器一直是谷歌人工智能产品的核心,这些产品为搜索、YouTube、Gmail、谷歌地图、Google Play 和 Android 等数十亿用户提供服务。它们还使世界各地的公司能够经济高效地训练大规模人工智能模型。
宣布推出迄今为止最强大、最高效且可扩展的 TPU 系统Cloud TPU v5p,专为训练尖端 AI 模型而设计。这款下一代TPU将加速Gemini的开发,帮助开发者和企业客户更快地训练大规模生成式AI模型,让新产品和能力更快地到达客户手中。
以责任和安全为核心构建
在 Google,致力于所做的一切事情中推进大胆且负责任的人工智能。基于 Google 的人工智能原则和我们产品中强大的安全政策,我们正在添加新的保护措施来考虑 Gemini 的多模式功能。在开发的每个阶段,我们都会考虑潜在的风险,并努力测试和减轻它们。
Gemini 拥有迄今为止所有 Google AI 模型中最全面的安全评估,包括偏见和毒性。我们对网络攻击、说服和自主等潜在风险领域进行了新颖的研究,并应用了 Google Research 一流的对抗性测试技术来帮助在 Gemini 部署之前识别关键的安全问题。
为了找出内部评估方法中的盲点,我们正在与各种外部专家和合作伙伴合作,针对一系列问题对我们的模型进行压力测试。
为了诊断 Gemini 训练阶段的内容安全问题并确保其输出符合我们的政策,我们使用了诸如“真实毒性提示”之类的基准,这是一组从网络中提取的 100,000 个不同程度毒性的提示,由艾伦研究所的专家开发。对于人工智能。有关这项工作的更多细节即将推出。
为了限制伤害,我们建立了专门的安全分类器来识别、标记和整理涉及暴力或负面刻板印象的内容。结合强大的过滤器,这种分层方法旨在使 Gemini 对每个人都更安全、更具包容性。此外,我们正在继续解决模型的已知挑战,例如事实性、基础性、归因和佐证。
责任和安全始终是我们模型开发和部署的核心。这是一项需要协作构建的长期承诺,因此我们正在与行业和更广泛的生态系统合作,通过 MLCommons 、 Frontier Model Forum 及其AI 安全基金以及我们的安全人工智能框架(SAIF),旨在帮助减轻公共和私营部门人工智能系统特有的安全风险。在开发 Gemini 的过程中,我们将继续与世界各地的研究人员、政府和民间社会团体合作。
让 Gemini 走向世界
Gemini 1.0 现已在一系列产品和平台上推出:
Google 产品中的 Gemini Pro
通过 Google 产品将 Gemini 带给数十亿人。
将使用 Gemini Pro 的微调版本来进行更高级的推理、计划、理解等。这是 Bard 自推出以来最大的升级。它将在 170 多个国家和地区提供英语版本,计划在不久的将来扩展到不同的模式并支持新的语言和地点。还将Gemini 引入 Pixel。Pixel 8 Pro 是第一款运行 Gemini Nano 的智能手机,它支持记录器应用中的 Summarize 等新功能,并在 Gboard 中的智能回复中推出,首先是 WhatsApp、Line 和 KakaoTalk(1)明年将推出更多消息应用程序。
Gemini 将出现在更多的产品和服务中,例如:搜索、广告、Chrome 和 Duet AI。已经开始在搜索中试验 Gemini,它使用户的搜索生成体验(SGE) 更快,美国英语的延迟减少了 40%,同时质量也得到了提高。
与双子座一起建设
从 12 月 13 日开始,开发者和企业客户可以通过Google AI Studio或Google Cloud Vertex AI中的 Gemini API 访问 Gemini Pro 。
Google AI Studio 是一款基于网络的免费开发者工具,可使用 API 密钥快速构建应用程序原型并启动应用程序。当需要完全托管的 AI 平台时,Vertex AI 允许对 Gemini 进行自定义,提供全面的数据控制,并受益于额外的 Google Cloud 功能,以实现企业安全、安全、隐私以及数据治理和合规性。
Android 开发人员还可以通过 AICore(Android 14 中提供的新系统功能,从 Pixel 8 Pro 设备开始)使用 Gemini Nano(我们最高效的设备端任务模型)进行构建。注册获取AICore 的早期预览版。
双子座超即将推出
对于 Gemini Ultra,我们目前正在完成广泛的信任和安全检查,包括由受信任的外部方进行红队检查,并在广泛使用之前使用微调和基于人类反馈的强化学习 (RLHF) 进一步完善模型。
作为此过程的一部分,我们将向选定的客户、开发人员、合作伙伴以及安全和责任专家提供 Gemini Ultra 进行早期实验和反馈,然后在明年初向开发人员和企业客户推出。
明年初,我们还将推出Bard Advanced,这是一种全新的尖端 AI 体验,让您可以从 Gemini Ultra 开始使用我们最好的模型和功能。
双子座时代:开启创新未来
这是人工智能发展的一个重要里程碑,也是谷歌新时代的开始。将继续快速创新并负责任地提高模型的能力。
到目前为止,在 Gemini 上取得了巨大进展,正在努力进一步扩展其未来版本的功能,包括规划和内存方面的进步,以及增加上下文窗口以处理更多信息以提供更好的响应。
对人工智能赋能的世界所带来的惊人可能性感到兴奋——这是一个创新的未来,它将增强创造力、扩展知识、推进科学并改变世界各地数十亿人的生活和工作方式。
Gemini 1.5
去年 12 月,谷歌推出了首款原生多模态模型 Gemini 1.0,共有三种尺寸:Ultra、Pro 和 Nano。仅仅几个月后,谷歌发布新版本 1.5 Pro,其性能得到了增强,并且上下文窗口突破了 100 万 token。
现在,谷歌宣布在 Gemini 系列模型中引入了一系列更新,包括新的 Gemini 1.5 Flash(这是谷歌追求速度和效率的轻量级模型)以及 Project Astra(这是谷歌对人工智能助手未来的愿景)。
目前,1.5 Pro 和 1.5 Flash 均已提供公共预览版,并在 Google AI Studio 和 Vertex AI 中提供 100 万 token 上下文窗口。现在,1.5 Pro 还通过候补名单向使用 API 的开发人员和 Google Cloud 客户提供了 200 万 token 上下文窗口。
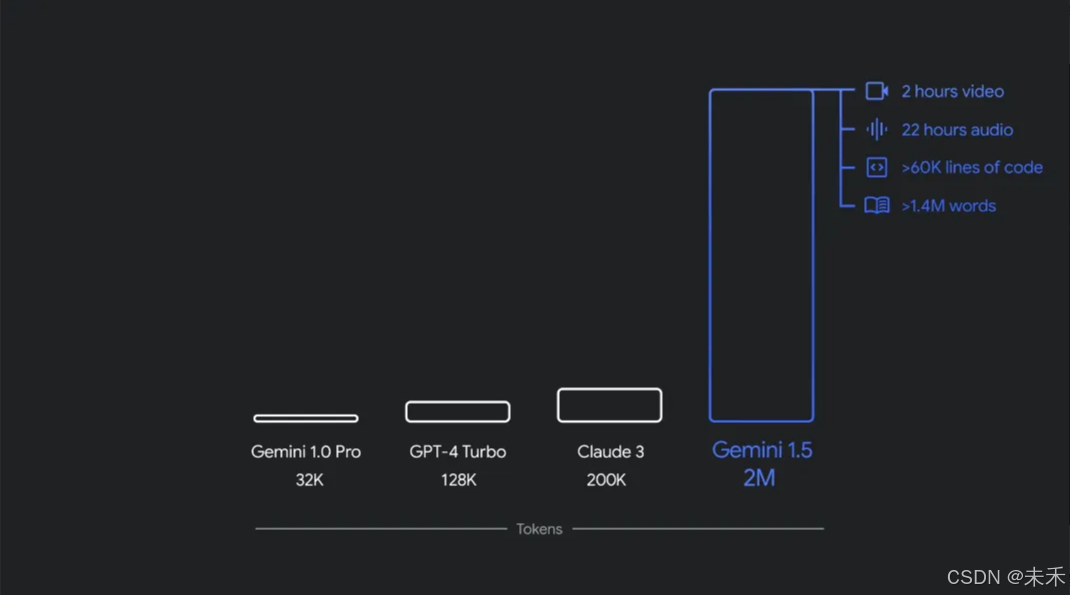
此外,Gemini Nano 也从纯文本输入扩展到可以图片输入。今年晚些时候,从 Pixel 开始,谷歌将推出多模态 Gemini Nano 。这意味着手机用户不仅能够处理文本输入,还能够理解更多上下文信息,例如视觉、声音和口语。
Gemini 家族迎来新成员:Gemini 1.5 Flash
新的 1.5 Flash 针对速度和效率进行了优化。

1.5 Flash 是 Gemini 模型系列的最新成员,也是 API 中速度最快的 Gemini 模型。它针对大规模、大批量、高频任务进行了优化,服务更具成本效益,并具有突破性的长上下文窗口(100 万 token )。

1.5 Flash 擅长摘要、聊天应用程序、图像和视频字幕、从长文档和表格中提取数据等。这是因为 1.5 Pro 通过一个名为「蒸馏」的过程对其进行了训练,将较大模型中最基本的知识和技能迁移到较小、更高效的模型中。
改进的 Gemini 1.5 Pro
上下文窗口扩展到 200 万 token
谷歌提到,如今有超过 150 万的开发人员在使用 Gemini 模型,超过 20 亿的产品用户都用到了 Gemini。

在过去的几个月里,谷歌除了将 Gemini 1.5 Pro 上下文窗口扩展到 200 万 token 之外,谷歌还通过数据和算法的改进增强了其代码生成、逻辑推理和规划、多轮对话以及音频和图像理解能力。

1.5 Pro 现在可以遵循日益复杂和细致的指令,包括那些指定涉及角色,格式和风格的产品级行为的指令。此外,谷歌还让用户能够通过设置系统指令来引导模型行为。
现在,谷歌在 Gemini API 和 Google AI Studio 中添加了音频理解,因此 1.5 Pro 现在可以对 Google AI Studio 中上传的视频图像和音频进行推理。此外,谷歌还将 1.5 Pro 集成到 Google 产品中,包括 Gemini Advanced 和 Workspace 应用程序。
Gemini 1.5 Pro 的定价为每 100 万 token 3.5 美元。
微软(Copilot)
2024 年 5 月 7 日《The Information》报道,微软正在开发一个拥有大约 5000 亿个参数的大语言模型(LLM)。
这标志着微软自从往 OpenAI投资逾 100 亿美元,以便可以重复使用这家初创公司的 AI 模型以来,首次自行开发这等规模的 AI 模型。该 LLM 在微软内部被称为 MAI-1,预计最早将于本月首次亮相。OpenAI 在 2020 年年中推出 GPT-3 时,详细说明该模型的初始版本有 1750 亿个参数。该公司透露,GPT-4 更庞大,拥有更多的参数,但尚未透露具体数字。一些报道显示,OpenAI 的旗舰 LLM 拥有 1.76 万亿个参数,而谷歌的 Gemini Ultra 据称拥有 1.6 万亿个参数,性能与 GPT-4 旗鼓相当。
微软的 MAI-1 拥有 5000 亿个参数,这表明它可能被定位为介于 GPT-3 和 GPT-4 之间的某种中档模型。这样的配置将允许模型提供高响应准确度,但耗用的功率比 OpenAI 的旗舰 LLM 低得多。言外之意,这将为微软带来更低的推理成本。
开发 MAI-1 的工作由 LLM 开发商 Inflection AI Inc.的创始人 Mustafa Suleyman 监管。
微软介绍
微软(Microsoft Corporation)是一家全球性的科技公司,总部位于美国华盛顿州的雷德蒙德。
自1975年比尔·盖茨和保罗·艾伦共同创立以来,微软已经发展成为世界上最大的软件制造商之一,业务范围覆盖了软件开发、硬件制造、云计算服务和其他科技领域。

微软的使命是“赋能每个人和每个组织在地球上实现更多”,致力于通过技术改善人们的生活和工作方式。
成立背景
微软成立于1975年4月4日,由比尔·盖茨和保罗·艾伦共同创立。最初以开发和销售BASIC解释器为起点,逐渐成为全球最大的个人电脑软件公司。
1980年代,微软推出了MS-DOS操作系统,并与IBM合作开发个人电脑。随后推出了Windows操作系统,成为家喻户晓的品牌。
发展历程
1、公司成立初期(1975-1980):
微软成立于1975年4月4日,由比尔·盖茨和保罗·艾伦共同创立。最初,公司专注于开发和销售BASIC解释器,这是一种早期的编程语言。1975年,微软为当时流行的Altair 8800微型计算机开发了BASIC解释器,这标志着公司的正式成立。
2、操作系统的发展(1980-1990):
1980年代,微软开始涉足操作系统领域。1981年,公司推出了MS-DOS(微软磁盘操作系统),这是一款基于命令行的操作系统,为个人电脑市场带来了重大影响。随后,微软与IBM合作,为IBM个人电脑开发操作系统,进一步巩固了公司在操作系统市场的地位。
3、Windows操作系统的诞生(1990-2000):
1985年,微软推出了Windows 1.0,这是公司首款图形用户界面操作系统。随着技术的发展和市场的扩大,Windows操作系统经历了多次重要的更新和升级,如Windows 95、Windows XP等,逐渐成为全球最流行的个人电脑操作系统。
4、多元化发展与互联网时代(2000-2010):
进入21世纪,微软开始拓展其业务范围,涵盖了办公软件(如Microsoft Office)、互联网服务(如MSN、Bing搜索引擎)、游戏娱乐(如Xbox游戏平台)等领域。同时,随着互联网的兴起,微软加强了对网络技术的投入,推出了Internet Explorer浏览器等产品。
5、云计算与移动时代(2010至2020):
在过去十年中,微软重点关注云计算和移动技术的发展。公司推出了云平台Azure,为企业提供了广泛的云服务和解决方案。此外,微软还进入了移动设备市场,推出Windows Phone操作系统和Surface系列硬件产品。
6、人工智能与混合现实时代(2020年代至今)
近年来,微软加大了在人工智能、混合现实等前沿技术领域的投资和研发,持续创新云计算、人工智能致力于可持续发展,进行战略性收购后发展(如LinkedIn、GitHub),并专注于人工智能和混合现实技术。
公司架构
微软的公司架构是一个分层和分散的结构,以适应其广泛的产品和服务。截至2023年,微软的组织架构主要分为以下几个部门:
(1)云与人工智能事业部(Cloud + AI Group)
负责微软云计算服务(如Azure)、人工智能和开发者工具(如Visual Studio)。
(2)生产力与业务流程事业部(Productivity and Business Processes)
主要负责Office产品线、Dynamics 365(企业资源规划和客户关系管理软件)以及LinkedIn。
(3)更多个人计算事业部(More Personal Computing)
负责Windows操作系统、Surface设备、Xbox游戏平台和搜索引擎Bing。
(4)全球销售、市场和运营(Global Sales, Marketing and Operations)
负责全球销售、市场营销和运营策略,以支持各个业务部门的销售和客户服务。
(5)财务部(Finance)
负责公司的财务管理、投资决策和财务报告。
(6)人力资源部(Human Resources)
负责员工招聘、培训、绩效管理和福利规划。
(7)法务与企业事务部(Legal and Corporate Affairs)
负责公司的法律事务、知识产权、合规和企业社会责任活动。
产品线
微软的产品线非常广泛,涵盖多领域,主要可分为以下几个部分:
(1)云计算与人工智能
(1)Azure:微软的云计算平台,提供包括虚拟机、数据库、存储、网络以及AI服务等在内的全面云服务。
(2)AI平台:包括机器学习、认知服务、机器人处理自动化等人工智能相关的服务和工具。
(2)生产力与业务流程
Microsoft 365:包括Office应用程序、企业级邮箱、云存储等服务的综合办公套件。
Dynamics 365:企业资源规划(ERP)和客户关系管理(CRM)应用程序。
LinkedIn:专业社交网络平台,提供招聘、营销和学习等服务。
(3)个人计算平台:
Windows:操作系统,包括Windows 10和Windows 11等版本。
Surface:微软自研硬件产品线,包括笔电、平板和一体机等。
Xbox:微软的游戏品牌,包括游戏主机和游戏内容。
(4)更多产品和服务:
Bing:微软的搜索引擎。
Microsoft Edge:基于Chromium的网页浏览器。
GitHub:全球最大的代码托管平台,微软于2018年收购。
Power Platform:包括Power BI、Power Apps、Power Automate和Power Virtual Agents等工具的业务分析和应用开发平台。
微软的产品和服务涵盖从个人用户到企业客户的广泛需求,公司不断创新和扩展其业务范围,以适应市场的变化和需求。
市场地位
微软一直是全球市值最高的公司之一,在全球科技行业中拥有非常强大的市场地位,各方面都可见一斑。
根据最新财报,微软的营收和利润持续增长,尤其是云计算服务Azure的增长势头强劲。微软的财务状况稳健,拥有充足的现金流和较低的负债水平。
(1)操作系统:微软的Windows操作系统是全球最流行的个人电脑操作系统,占据了全球桌面操作系统市场的主导地位。
(2)办公软件:微软Office套件是全球最广泛使用的办公软件,包括Word、Excel、PowerPoint等应用程序。
(3)云计算:微软的Azure云平台是全球第二大云计算服务提供商,仅次于亚马逊公司的AWS。Azure提供了广泛的云服务,包括计算、存储、数据库和人工智能服务。
(4)企业解决方案:微软提供一系列企业级解决方案,包括Dynamics 365(企业资源规划和客户关系管理软件)和Microsoft 365(集成了Office 365、Windows 10和企业安全性的服务)。
(5)游戏和娱乐:通过Xbox游戏平台和相关服务,微软在游戏产业中也占有重要地位。
(6)人工智能和研发:微软在人工智能领域持续投入研发资源,开发了一系列AI产品和服务,如Cognitive Services和Azure AI。
财报业绩
微软在2024财年的前两个季度表现较为出色:
第一季度:微软的总收入为565亿美元,比去年同期的501亿美元增长了13%。净利润为223亿美元,比去年同期的176亿美元增长了26%。每股收益为2.99美元,比去年同期的2.35美元增长了26%
第二季度:微软的总收入为620亿美元,比去年同期的527亿美元增长了18%。净利润为218.7亿美元,比去年同期的164.25亿美元增长了33%。每股收益为2.93美元,比去年同期的2.20美元增长了33%。
在这两个季度中,微软云服务的收入占公司总收入的一半以上,显示出微软在云计算领域的强劲增长。此外,微软365消费者订阅者数量也增长到7840万,比去年同期的6320万有所增加。
融资表现
微软的融资表现在公司2022年年报中有所体现:公司使用衍生金融工具来管理与外币、股票价格、利率和信用相关的风险,并增强投资回报和促进投资组合多样化。微软的收入和分红收入因投资组合余额降低而减少,而利息支出则因长期债务减少而降低。微软的净投资收益下降主要是由于股权证券收益减少。
截至2022年6月30日,微软的现金、现金等价物和短期投资总额为1048亿美元,较2021年的1303亿美元有所减少。公司的股权投资从2021年的60亿美元增加到2022年的69亿美元。微软的短期投资主要是为了促进流动性和资本保值,主要由投资级别的固定收益证券组成,这些证券在行业和个别发行人之间进行了多样化。这些投资主要是以美元计价的证券,但也包括一些外币计价的证券以分散风险。微软发行债券是为了利用债务市场的有利定价和流动性,反映了其信用评级和低利率环境。这些发行的收益将用于一般公司用途,包括资本支出、购买公司股份、收购和偿还现有债务等。在2021年3月和2020年6月,微软以溢价交换了部分现有债务以换取现金和更长期限的新债务,以利用债务市场的有利融资率。
此外,根据微软的2024财年第二季度财报数据,微软在该季度向股东返还了84亿美元,以股票回购和分红的形式。
技术创新
微软在技术创新和伙伴关系方面的发展是相辅相成的。通过不断的技术创新,微软加强在云计算、人工智能(AI)、芯片设计等领域领导地位,并通过构建强大的伙伴关系网络,将创新技术推广到更广泛的市场和行业中。
(1)人工智能(AI)基础设施:微软致力于构建AI基础设施,并通过其智能云Azure提供给企业,帮助开发者实现下一代AI创新。微软与OpenAI的合作,特别在AI模型的训练和部署方面,展示了微软在AI领域的深厚实力。
(2)云计算:微软智能云Azure作为AI基础设施的先行者,为客户提供了强大的云服务,支持大规模AI模型的训练和部署。
(3)芯片设计:在Ignite 2023技术大会上,微软发布了基于其数据中心集群的创新产品,包括AI加速器芯片Microsoft Azure Maia和基于Arm架构的云原生芯片Microsoft Azure Cobalt,这些芯片针对AI工作负载进行优化。
(4)AI转型:微软通过Copilot系列产品和Azure AI Studio等工具,推动了AI在企业中的应用,帮助企业实现数字化转型。
(5)数据与AI的结合:通过Microsoft Fabric等解决方案,微软加强了数据与AI的联系,提供了统一的数据管理平台,以支持企业级的数据资产处理。
伙伴关系
(1)合作伙伴中心:微软通过合作伙伴中心简化了与合作伙伴的业务流程,使合作伙伴能够更轻松地管理与微软及其客户的关系。合作伙伴中心提供了管理账户、与客户互动、建立关系、注册奖励计划等功能。
(2)解决方案合作伙伴计划:推出解决方案合作伙伴指定计划,帮助合作伙伴在特定解决方案领域内脱颖而出,提供与微软解决一致增量权益。
(3)联合销售:微软鼓励合作伙伴与共同销售,利用微软的品牌、销售团队和商业市场资源,触达全球客户。
(4)客户支持:微软为合作伙伴提供了强大的客户支持,包括部署和管理订阅、维护性能、设置用户和创建支持票证等服务。
(5)安全与合规:微软强调安全和隐私保护,要求合作伙伴使用多重身份验证等措施来确保数据安全。
.
AI时代下微软的大模型战略
微软的大模型战略集中在开发和部署大规模的人工智能模型,以推动自然语言处理、计算机视觉、语音识别等领域的创新。这些大模型是微软AI战略的核心部分,旨在提高AI技术的可用性、性能和效率,下面是关于微软大模型战略的一些关键方面:
(1)投资和研发: 微软在大模型的研发上进行了重大投资,致力于创建更先进、更高效的模型。这包括对Transformer架构的改进、模型压缩技术的开发以及训练和推理过程的优化。
(2)跨领域应用: 微软的大模型不仅限于自然语言处理领域,还涵盖了计算机视觉、语音识别等多个领域。这些模型能够处理和理解多种类型的数据,为各种应用提供强大的AI能力。
(3)云服务和平台: 微软通过Azure AI服务和其他平台,将大模型作为服务提供给开发者和企业。这使得用户可以轻松地访问、部署和定制这些模型,以满足他们的具体需求。
(4)合作和开放生态: 微软与学术界、开源社区和其他行业合作伙伴合作,共同推动大模型技术的发展。微软也积极参与开源项目,分享其研究成果和模型,以促进AI领域的创新和进步。

(5)负责任的AI: 在大模型战略中,微软强调负责任地使用AI技术。这包括确保模型的公平性、透明性和安全性,以及在开发和部署模型时考虑伦理与社会影响。
近年微软在大模型领域的关键动态和产品
微软近年来在大模型领域的发展涉及多个方面:
从思维导图中我们可以发现,微软业务广泛,包括Microsoft Copilot、Azure AI Studio、多模态大模型、自研AI芯片、开源模型、Microsoft Designer以及Microsoft Security Copilot等不同的方向,这些方向涵盖了文本生成、图像创建、数据分析、大规模AI解决方案开发、多模态理解、硬件加速以及安全领域的应用等多个方面。
Meta(Llama3)
官方网址:https://llama.meta.com/
下载链接:https://llama.meta.com/llama-downloads/
Github网址:https://github.com/meta-llama/
北京时间2024年7月23日23点,Meta正式发布了其最新的开源模型——Llama 3.1,包含8B、70B和405B三个尺寸,最大上下文提升到了128k。
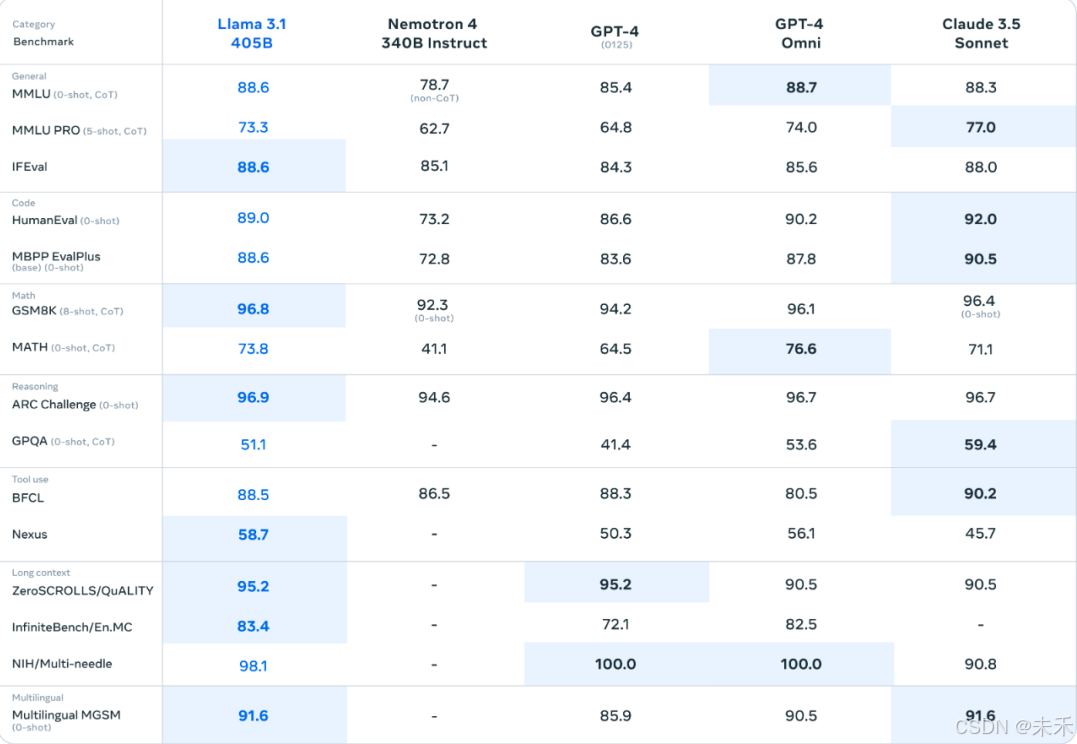
(1)Llama 3.1的发布:2024年7月23日,Meta发布了Llama 3.1,包括8B、70B和405B三个尺寸,其中405B是迄今最强大的模型。
(2)性能和上下文:Llama 3.1的最大上下文提升到了128k,405B模型在性能上超过了GPT-4 0125,与Claude 3.5不相上下。
(3)数据训练:Llama 3使用了超过15 T token的公开数据进行训练,采用了超过1.6万个H100 GPU。
(4)开源的重要性:文章强调了开源AI的重要性,认为它是未来的发展方向。扎克伯格在致辞中提到,开源AI将使更多人受益于AI技术,避免权力集中在少数公司手中。
(5)Llama 3.1的应用:Llama 3.1被设计为易于微调和定制,适用于各种规模的公司和研究机构。
生态系统的构建:Meta正在内部建立团队,与开发者和合作伙伴合作,推动Llama模型在生态系统中的应用。
其中,405B是其拓展最强大的模型,从评分上看,超过了GPT-4 0125,和Claude 3.5不相上下。
Llama 3进行快速工程
除此之外,Meta 此次和大模型一起发布的还有自己的AI助手,Meta AI。
Meta AI 网址:https://www.meta.ai/
Meta AI由最新的Llama 3模型提供支持,它不仅将被整合到Meta 旗下的 Instagram、WhatsApp、Facebook和Messenger的搜索框中,还将首次以独立网站Meta.ai的形式对外提供服务。
xAI(Grok)
官方网址:https://grok.x.ai/
官网最新公告:https://x.ai/blog
2024 年 5 月 26 日xAI 完成 60 亿美元的 B 轮融资
B 轮融资金额达 60 亿美元,主要投资者包括 Valor Equity Partners、Vy Capital、Andreessen Horowitz、Sequoia Capital、Fidelity Management & Research Company、阿尔瓦利德·本·塔拉勒王子和 Kingdom Holding 等。
xAI 在过去一年中取得了长足进步。从 2023 年 7 月宣布成立公司,到11 月在 X 上发布 Grok-1,再到最近宣布具有长上下文能力的改进型 Grok-1.5 模型,再到具有图像理解能力的 Grok-1.5V,xAI 的模型能力得到了迅速提升。随着Grok-1 的开源发布,xAI 为模型的各种应用、优化和扩展的进步打开了大门。
未来几个月,xAI 将沿着这一快速发展的轨迹继续前进,即将发布多项激动人心的技术更新和产品。本轮融资将用于将 xAI 的首批产品推向市场、构建先进的基础设施,并加速未来技术的研发。
…原文详情:https://x.ai/blog/series-b
2024 年 7月 1 日人工智能公司xAI CEO埃隆·马斯克表示,xAI()即将推出新一代大语言模型Grok-2。
xAI将于8月推出Grok-2,下一代Grok-3训练需10万块 H100
马斯克宣布其人工智能初创公司xAI的大预言模型Grok-2将于8月推出,而下一代Grok-3用了10万块英伟达H100芯片进行训练,预计将于年底发布。Grok-2即将推出,Grok-3的训练已经开启,可见xAI产品发布规划的延续性,且Grok-3训练所用的AI芯片数量已经超过大多数AI大模型训练所用的芯片数量(一般万卡级别)。
最新大模型Grok-1.5V
Grok-1.5V 在多个领域都与现有的前沿多模态模型相媲美,从多学科推理到理解文档、科学图表、图表、屏幕截图和照片。我们对 Grok 在理解物理世界方面的能力特别感兴趣。在我们新的 RealWorldQA 基准测试中,Grok 的表现优于同类产品,该基准测试衡量了现实世界的空间理解能力。对于以下所有数据集,我们在没有思路链提示的零样本设置中评估 Grok。



Grok-1 是一个由 xAI 从头开始训练的 3140 亿参数混合专家模型。
这是 Grok-1 预训练阶段的原始基础模型检查点,该阶段于 2023 年 10 月结束。这意味着该模型没有针对任何特定应用(例如对话)进行微调。要开始使用该模型,请按照github.com/xai-org/grok上的说明进行操作。
型号详情
1、基础模型基于大量文本数据进行训练,未针对任何特定任务进行微调。
2、314B参数混合专家模型,其中 25% 的权重在给定代币上处于活动状态。
3、xAI 于 2023 年 10 月使用基于 JAX 和 Rust 的自定义训练堆栈从头开始训练。
封面图像是根据 Grok 提出的以下提示使用Midjourney生成的:神经网络的 3D 插图,具有透明节点和发光连接,以不同粗细和颜色的连接线展示不同的权重。
英伟达(Corporation)
英伟达(NVIDIA Corporation)是知名的美国跨国科技公司、全球领先的人工智能和图形处理器(GPU)技术公司,总部位于美国加利福尼亚州的圣克拉拉。专注于图形处理器(GPU)的设计和制造,同时也在人工智能(AI)计算领域占据重要地位。
自1993年成立以来,英伟达经历了从图形芯片制造商到人工智能技术领导者的转型。
成立背景与发展历程
1、成立于1993年,由黄仁勋(Jensen Huang)、克里斯·马拉科夫斯基(Chris Malachowsky)和柯蒂斯·普里姆(Curtis Priem)共同创立。
2、总部位于加利福尼亚州圣克拉拉市。
3、1993年在纳斯达克挂牌上市,股票代码为NVDA。
英伟达由Jensen Huang、Chris Malachowsky和Curtis Priem于1993年共同创立。公司最初专注于开发和销售图形处理单元(GPU),旨在提高计算机图形渲染的速度和效率。
英伟达(NVIDIA)的发展历程时间线:
1993年:英伟达成立于加利福尼亚州圣克拉拉,由詹森·黄(Jensen Huang)、克里斯·马拉科夫斯基(Chris Malachowsky)和柯蒂斯·普里姆(Curtis Priem)共同创立。
1995年:推出首款产品——NV1图形处理器。
1999年:推出GeForce 256,被誉为世界上第一个GPU。
2000年:开始为索尼的PlayStation 2游戏机提供图形技术。
2003年:推出NVIDIA Quadro FX系列,进军专业图形市场。
2004年:推出NVIDIA SLI技术,两个或更多个GPU并行提高图形性能。
2006年:推出CUDA(Compute Unified Device Architecture),开启GPU加速计算的新时代。
2007年:收购PortalPlayer,进军移动设备市场。
2010年:推出首款基于Fermi架构的GPU,大幅提升计算能力。
2011年:推出Tegra 2平台,标志着英伟达在移动市场的重要一步。
2012年:推出Kepler架构,进一步提升能效比。
2014年:推出Maxwell架构,带来更高的能效比和性能。
2016年:推出Pascal架构,支持深度学习和人工智能应用。
2017年:推出Volta架构,配备Tensor Core专为AI计算优化。
2018年:推出Turing架构,引入实时光线追踪技术。
2020年:推出Ampere架构,提供强大的AI和图形性能。
2021年:推出Grace CPU,标志着英伟达进入高性能计算CPU市场。
2022年:推出Hopper架构,专为高性能计算和AI设计。
重点节点:
1999年,英伟达推出了其标志性的GeForce系列GPU,这开启了PC游戏和图形渲染的新时代。
2022年以来,英伟达在人工智能领域取得了显著成就。英伟达的GPU已成为深度学习和机器学习应用的核心硬件,广泛应用于自动驾驶汽车、医疗影像分析、自然语言处理等领域。
公司架构与产品线
英伟达的公司架构旨在支持其在图形处理、人工智能和数据中心领域的业务发展,并适应不断变化的技术市场需求。
公司架构
管理层:英伟达的管理层由执行团队组成,包括首席执行官(CEO)詹森·黄(Jensen Huang)、首席财务官(CFO)以及其他高级副总裁和副总裁,他们负责公司的整体战略规划和运营管理。
业务部门:英伟达的业务主要分为几个部门,包括:
计算与网络(Compute & Networking):负责数据中心和高性能计算产品的研发和销售。
专业可视化(Professional Visuali zation):负责工作站图形和可视化解决方案的研发和销售。
游戏(Gaming):负责游戏图形处理器和平台的研发和销售。
汽车(Automotive):自动驾驶和车载信息娱乐系统研发销售。
研发部门:英伟达在全球设有多个研发中心,负责图形处理器、人工智能算法和软件等技术的研发。
市场和销售部门:负责全球市场推广、销售和客户服务。
运营和供应链部门:负责生产管理、供应链管理和物流等运营活动。
财务和法务部门:负责公司的财务管理、投资者关系和法律事务。
以下是英伟达公司主要架构制作的表格:这张表格简要概述了英伟达公司的主要部门及其职责。
| 英伟达(部门) | 部门职责 |
|---|---|
| 管理层 | 负责公司的整体战略规划和运营管理。包括CEO、CFO以及其他高级副总裁和副总裁。 |
| 计算与网络 | 负责数据中心和高性能计算产品的研发和销售。 |
| 专业可视化 | 负责工作站图形和可视化解决方案的研发和销售。 |
| 游戏 | 负责游戏图形处理器和平台的研发和销售。 |
| 汽车 | 负责自动驾驶和车载信息娱乐系统的研发和销售。 |
| 研发部门 | 负责图形处理器、人工智能算法和软件等技术的研发。 |
| 市场和销售部门 | 负责全球市场推广、销售和客户服务。 |
| 运营和供应链部门 | 负责生产管理、供应链管理和物流等运营活动。 |
| 财务和法务部门 | 负责公司的财务管理、投资者关系和法律事务。 |
产品线
英伟达的产品线主要包括以下几个方面:
(1)图形处理器(GPU):
GeForce:面向游戏和消费者市场的GPU。
Quadro / NVIDIA RTX:面向专业可视化、设计和内容创作的GPU。
Tesla / NVIDIA A100:面向数据中心和高性能计算的GPU。
(2)数据中心产品:
DGX系统:预配置的深度学习和人工智能超级计算机。
NVIDIA HGX:用于构建高性能GPU加速的数据中心的平台。
NVIDIA Networking(原Mellanox Technologies):提供高性能网络解决方案,包括交换机、适配器和软件。
(3)自动驾驶和汽车解决方案:
NVIDIA DRIVE:面向自动驾驶汽车的硬件和软件平台。
NVIDIA Clara AGX:医疗成像和机器人手术的边缘计算平台。
(4)人工智能和深度学习:
NVIDIA AI Platform:包括工具和框架,用于开发和部署AI应用。
NVIDIA Jetson:面向边缘计算的小型、低功耗AI计算模块。
(5)游戏和娱乐设备:
SHIELD:包括SHIELD TV和SHIELD Tablet等家庭娱乐设备。
市场地位
(1)英伟达作为全球AI算力的领导者,其GPU产品在高性能计算(HPC)、深度学习、自动驾驶等领域有着广泛应用。英伟达在GPU技术方面一直保持创新。除了传统的图形渲染,公司还将GPU的应用拓展到了并行计算领域。借助CUDA(Compute Unified Device Architecture)技术,英伟达的GPU能够处理复杂的科学计算和大数据分析任务,成为高性能计算(HPC)的重要工具。
(2)近年来,英伟达在AI等新领域取得了显著成就,成为深度学习和机器学习应用的核心硬件,广泛应用于自动驾驶、自然语言处理等领域。英伟达还推出了专为AI计算设计的DGX系统和Tensor Core技术,进一步加速了AI模型的训练和推理过程。
财报业绩
2024财年的年营业额达到了609.22亿美元,年利润为297.60亿美元,拥有约13775名员工(数据截至2024年)。
融资情况
英伟达在2024财年的融资活动主要包括以下几个方面:
(1)员工股票计划收入:根据财报,英伟达通过员工股票计划获得了约5亿美元的收入。
(2)普通股回购:在2024财年,英伟达进行了大量的普通股回购,总额达到约26.6亿美元。
(3)现金及现金等价物:截至2024财年第四季度末,英伟达的现金、现金等价物及可供出售证券总额为259.84亿美元。
技术创新
(1)GeForce RTX 40 SUPER系列GPU:GPU具有更强的游戏和生成式AI性能,支持4K全光线追踪游戏,并且速度比前一代GPU更快
(2)NVIDIA RTX Remix:这是一个开放beta版的应用程序,允许修改者使用全光线追踪、DLSS、(3)NVIDIA Reflex和生成式AI纹理工具重新制作经典游戏
(4)NVIDIA AI Foundations:这是一套云服务,旨在帮助企业构建和运行针对特定领域任务训练的生成式AI模型
合作伙伴关系
(1)与AWS的战略合作:英伟达与AWS合作,推出了新的超级计算基础设施、软件和服务,用于支持客户的生成式人工智能创新。他们共同开发的Project Ceiba超级计算机将用于研发,推进人工智能在各个领域的应用
(2)与Deloitte的战略联盟:英伟达扩大了与Deloitte的战略联盟,以帮助企业全球利用生成式AI重塑业务运作方式。Deloitte将利用英伟达的AI技术和专长构建高性能的生成式AI解决方案
(3)与Adobe和Getty Images的合作:英伟达正在与Adobe合作开发下一代商业可行的生成式AI模型,并与Getty Images合作培训负责任的生成式文本到图像和文本到视频模型
企业文化
“The way it’s meant to be played”,英伟达的企业文化和愿景强调创新、多样性、包容性和社会责任。公司致力于为员工创造一个能够实现其生涯最佳工作的文化环境,提供优异的薪酬和丰富的福利。英伟达鼓励员工发挥创造力,推动技术创新,同时注重环境保护和社会贡献。
企业愿景
在愿景方面,英伟达专注于加速计算的领导地位,通过人工智能和数字孪生技术转变世界上最大的行业,并对社会产生深远的影响。公司致力于开发可信赖的人工智能技术,以促进积极的变革并在AI开发中实现信任和透明度。此外,英伟达还通过其NVIDIA基金会支持各种社会和环境项目,包括教育、健康和气候变化解决方案等领域的创新。
Groq
官方网址:https://groq.com/
Groq相关白皮书:https://wow.groq.com/docs/
Groq API方案:https://wow.groq.com/
Groq 最新动态及新闻:https://wow.groq.com/press/
Groq 的使命是设定 GenAI 推理速度的标准,帮助实时人工智能应用程序在今天成为现实。
改变游戏规则的技术
Groq 创建并提供了第一个 LPU™ 推理引擎。
我们是唯一一家创建了“从沙到天”解决方案的提供商——从芯片到云以及介于两者之间的一切。我们的解决方案从头开始构建,旨在实现精确、节能和可重复的大规模推理性能。
截止 2024-09-18 groq官方新闻动态:
亚马逊Amazon(Titan)
Amazon简介
亚马逊Titan大模型是亚马逊推出的一系列高性能基础模型,旨在支持广泛的生成式人工智能应用,如内容创建、图像生成以及搜索和推荐体验。这些模型由AWS创建并在大型数据集上进行预训练,使其成为强大的通用模型,支持各种用例,同时还支持负责任地使用AI。
主要功能
文本生成:使用Titan Text模型可以提高各种文本相关任务的生产力和效率,例如为博客文章和网页创建副本、将文章分类、开放式问答、对话式聊天、信息提取等。
图像生成:Titan Image Generator模型具备“图片编辑”及“隐藏水印”等功能,允许用户以英语输入提示词句,以生成“专业等级”的图像。
多模态和文本模型:为广泛的生成式人工智能应用提供支持,例如内容创建、图像生成以及搜索和推荐体验。
模型版本
Amazon Titan Text Premier
Amazon Titan Text Premier 是 Amazon Titan Text 系列中一款功能强大的先进模型,旨在为各种企业应用程序提供卓越的性能。该模型针对与 Amazon Bedrock 的代理和知识库集成进行了优化,使其成为构建可使用 API 并与数据交互的交互式生成式人工智能应用程序的理想选择。
最大令牌数:32000
语言:英语
支持微调:是(预览版)
支持的使用案例:RAG、代理、聊天、思维链、开放式文本生成、头脑风暴、总结、代码生成、表格创建、数据格式化、释义、重写、提取和问答。
Amazon Titan Text Express
一款兼顾价格和性能的大型语言模型(LLM)。
最大令牌数:8000
语言:英语(GA),提供 100 多种语言(预览版)
支持微调:是
支持的使用案例:RAG、开放式文本生成、头脑风暴、汇总、代码生成、表格创建、数据格式化、释义、思维链、重写、提取、问答和聊天。
Amazon Titan Text Lite
经济实惠且高度可定制的 LLM。大小适中,适合特定用例,非常适合文本生成任务和微调。
最大令牌数:4 千
语言:英语
支持微调:是
支持的使用案例:摘要和文案写作。
Amazon Titan Text Embeddings
将文本转换为数字表示的 LLM。
最大令牌数:8K
语言:25 种以上的语言
支持微调:否
嵌入:1536
支持的使用案例:文本检索、语义相似度和集群化。
Amazon Titan Text Embeddings V2
LLM 针对较小维度的高精度和检索性能进行了优化,从而减少了存储和延迟。
最大令牌数:8000
语言:100 多种预训练语言
支持微调:否
支持标准化:是
嵌入:256、512、1024
支持的使用案例:进行语义相似度搜索以查找文档(例如,检测抄袭),将标签分类为基于数据的学习表现形式(例如,将电影按类型分类),以及提高检索或生成的搜索结果的质量和相关性。
Amazon Titan 多模态嵌入
提供准确的多模态搜索和推荐体验。
最大令牌数:128
最大图像大小:25MB
语言:英语
支持微调:是
嵌入:1024(默认)、384、256
支持的使用案例:搜索、推荐和个性化。
Amazon Titan 图像生成器
使用文本提示生成逼真、录音室品质的图像。
最大令牌数:77
最大输入图像大小:25MB
语言:英语
支持微调:是
支持的使用案例:文本到图像生成、图像编辑和图像变体。
Stability AI(StableLM)
GitHub 地址:https://github.com/stability-AI/stableLM/
模型官网:https://stability.ai/
Huggingface Chat 地址:https://huggingface.co/chat/
Stability AI简介
StableLM是StabilityAI开源的一个大语言模型,于2023年4月20日公布,目前属于开发中状态,只公布了部分版本模型训练结果。它是StabilityAI的第一个开源的大语言模型,基于Pile数据训练,包含约1.5万亿tokens,数据集目前没有公开,但官方表示后续会在适当的时机会公布。模型训练的context长度是4096个tokens。StableLM系列包含2种模型,一个是基础模型,名字中包含base。另一种是使用斯坦福Alpaca的微调流程在5个对话数据集上的联合微调得到的结果,名字中包含tuned。StableLM的能力包括闲聊、正式写作、创意写作和写代码等。
Stability AI特点
开源和可访问性:StableLM在GitHub上开源,允许任何人下载并部署在本地,包括笔记本等小型设备。
多语言支持:支持英语、西班牙语、德语等7种语言,展现了卓越的语言理解和生成能力。
高效性能:尽管参数规模相对较小,但通过使用大量多样化的数据集进行预训练,StableLM在对话和编码任务中表现出惊人的高性能。
Stability AI应用场景
自然语言处理任务:包括机器翻译、情感分析、文本分类和问答系统等。
智能客服和智能写作:帮助企业更好地处理用户反馈、生成优质内容等。
移动设备上的应用:如Stable LM 3B模型,为移动平台设备带来了高性能体验的曙光。
Bloomberg(BloombergGPT)
Bloomberg简介
BloombergGPT是布隆伯格2023年3月30日公开在arXiv的一篇文章——BloombergGPT: A Large Language Model for Finance中涉及到的语言模型,也是金融领域第一个公开发表文章的大语言模型(以下简称“LLM”)。
Bloomberg要点
(1)BloombergGPT是Bloomberg训练出来的金融大语言模型(LLM for Finance)
(2)模型参数量为500亿,使用了包含3630亿token的金融领域数据集以及3450亿token的通用数据集
(3)隐藏层维度为7680,多头的头数为40
(4)模型采用Unigram tokenizer,AdamW优化器
(5)模型在64个AWS的p4d.24xlarge实例上训练了53天,其中每个p4d.24xlarge实例包含了8块40GB的A100GPU
(6)对BloombergGPT的评估包含了两部分:金融领域评估与通用领域评估
(7)评估对比的其他大语言模型有GPT-NeoX、OPT、BLOOM、GPT-3
(8)在金融领域任务上,BloombergGPT综合表现最好;在通用任务上,BloombergGPT的综合得分(9)同样优于相同参数量级的其他模型,并且在某些任务上的得分要高于参数量更大的模型
BloombergGPT模型在金融领域取得好效果的同时,并没有以牺牲模型通用能力为代价
(10)对模型定性评估的结果表明,BloombergGPT可以提高工作效率
(11)出于安全性的考虑,BloogbergGPT模型不会被公开,但是模型训练和评估的相关经验和思考会被分享出来
模型效果提升促进最大的三个因素(按影响从高到低排序)分别为精心清洗的数据集、合理的tokenizer、流行的模型结构
数据集
BloombergGPT是一个有500亿参数、基于BLOOM模型的LLM,过程中采用了一种兼具通用能力和特定领域的方法。
作者首先构建了FinPile——一个包含了新闻、档案、网络爬取的新闻稿件、英文财经文档等英文金融文档的金融领域数据集,同时也采用了通用的数据集。
(1)金融领域数据集
金融领域数据集共包含了3630亿个token,占总数据集token量的54.2%,具体由以下几个部分构成:
(1)金融领域相关网页,2980亿token,占比42.01%
(2)金融领域知名新闻源,380亿token,占比5.31%
(3)公司财报,140亿token,占比2.04%
(4)金融相关公司的出版物,90亿token,占比1.21%
(5)bloomberg,50亿token,占比0.7%
因为包含一部分收费和私有数据,所以这份数据集不会被公开,但是文章中公开了模型训练方法。
(2)通用数据集
通用数据集共包含了3450亿个token,占总数据集token量的48.73%,具体分为如下几个部分:
(1)The Pile数据集,1840亿token,占比25.9%
(2)C4数据集,1380亿token,占比19.48%
(3)Wikipedia数据集,240亿token,占比3.35%
数据集使用Unigram tokenizer对原始文本进行tokenize。具体处理时,作者这了两点改进(具体内容可参考原论文《2.3Tokenization》):
(4)在pretokenization这一步,将数字视为单个token,并且允许词组的存在,以提高信息密度减少句子长度
(5)使用分治的思想优化Unigram tokenizer在大数据集上的实现,并对最终词表大小控制在13万这个数量级上