目录
Flink流处理、自定义时间流处理、有状态流处理及其容错
Flink流处理、自定义时间流处理、有状态流处理及其容错
流处理
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕 有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。
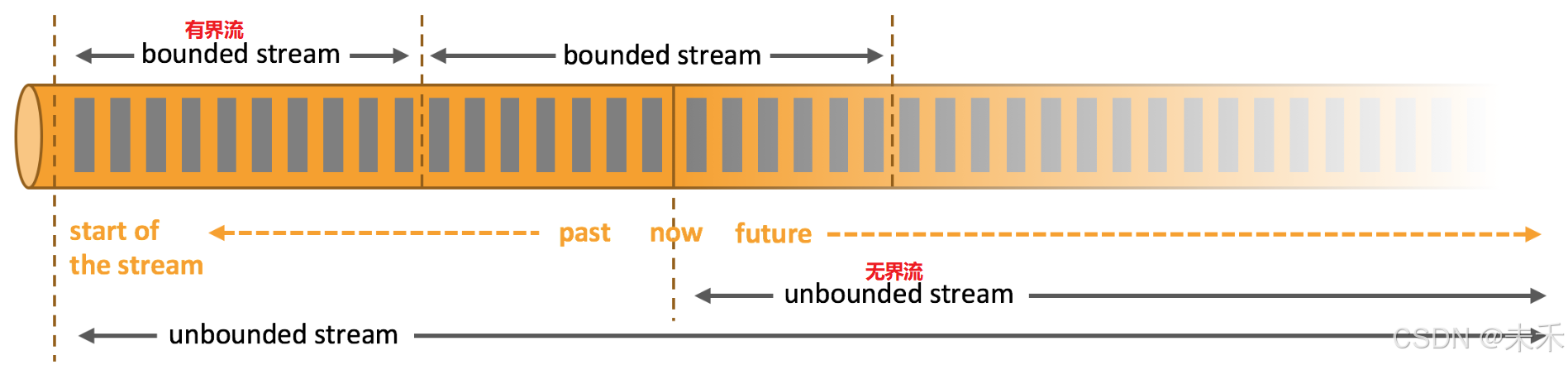
(1)批处理:有界数据流
批处理是有界数据流处理的范例。在这种模式下,你可以选择在计算结果输出之前输入整个数据集,这也就意味着你可以对整个数据集的数据进行排序、统计或汇总计算后再输出结果。
(2)流处理:无界数据流
流处理正相反,其涉及无界数据流。至少理论上来说,它的数据输入永远不会结束,因此程序必须持续不断地对到达的数据进行处理。
在 Flink 中,应用程序由用户自定义算子转换而来的流式 dataflows 所组成。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束。
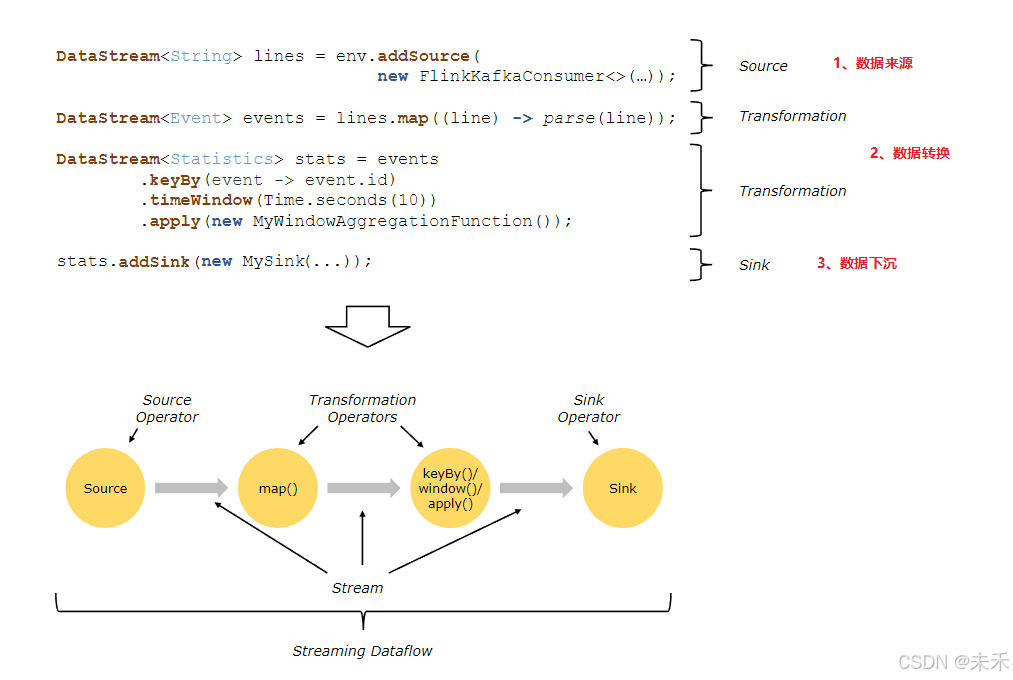
通常,程序代码中的*transformation 和 dataflow 中的算子(operator)之间是一一对应的。但有时也会出现一个 transformation 包含多个算子的情况,如上图所示。
Flink 应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如 Apache Kafka 或 Kinesis)的实时数据,也可以从各种的数据源中消费有界的历史数据。同样,Flink 应用程序生成的结果流也可以发送到各种数据汇中。
并行 Dataflows
Flink 程序本质上是分布式并行程序。在程序执行期间,一个流有一个或多个流分区(Stream Partition),每个算子有一个或多个算子子任务(Operator Subtask)。每个子任务彼此独立,并在不同的线程中运行,或在不同的计算机或容器中运行。
算子子任务数就是其对应算子的并行度。在同一程序中,不同算子也可能具有不同的并行度。
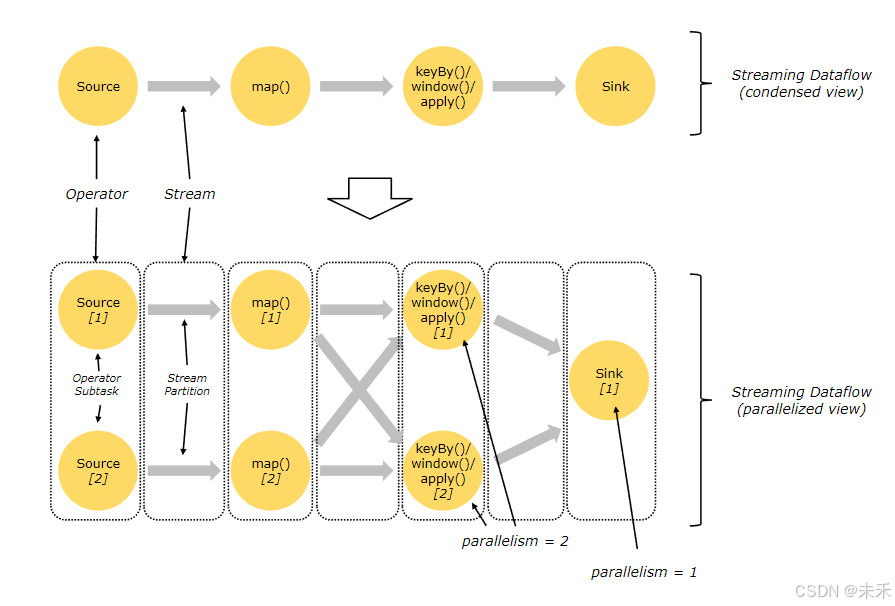
Flink 算子之间可以通过一对一(直传)模式或重新分发模式传输数据:
(1)一对一模式:保留元素的分区和顺序
(例如:上图中的 Source 和 map() 算子之间)可以保留元素的分区和顺序信息。这意味着 map() 算子的 subtask[1] 输入的数据以及其顺序与 Source 算子的 subtask[1] 输出的数据和顺序完全相同,即同一分区的数据只会进入到下游算子的同一分区。
(2)重新分发模式:聚合结果到达 Sink 的顺序是不确定
(例如:上图中的 map() 和 keyBy/window 之间,以及 keyBy/window 和 Sink 之间)则会更改数据所在的流分区。当你在程序中选择使用不同的 transformation,每个算子子任务也会根据不同的 transformation 将数据发送到不同的目标子任务。
例如以下这几种 transformation 和其对应分发数据的模式:keyBy()(通过散列键重新分区)、broadcast()(广播)或 rebalance()(随机重新分发)。在重新分发数据的过程中,元素只有在每对输出和输入子任务之间才能保留其之间的顺序信息(例如,keyBy/window 的 subtask[2] 接收到的 map() 的 subtask[1] 中的元素都是有序的)。因此,上图所示的 keyBy/window 和 Sink 算子之间数据的重新分发时,不同键(key)的聚合结果到达 Sink 的顺序是不确定的。
自定义时间流处理
对于大多数流数据处理应用程序而言,能够使用处理实时数据的代码重新处理历史数据并产生确定并一致的结果非常有价值。
在处理流式数据时,我们通常更需要关注事件本身发生的顺序而不是事件被传输以及处理的顺序,因为这能够帮助我们推理出一组事件(事件集合)是何时发生以及结束的。例如电子商务交易或金融交易中涉及到的事件集合。
为了满足上述这类的实时流处理场景,我们通常会使用记录在数据流中的事件时间的时间戳,而不是处理数据的机器时钟的时间戳。
有状态流处理
Flink 中的算子可以是有状态的。这意味着如何处理一个事件可能取决于该事件之前所有事件数据的累积结果。Flink 中的状态不仅可以用于简单的场景(例如统计仪表板上每分钟显示的数据),也可以用于复杂的场景(例如训练作弊检测模型)。
Flink 应用程序可以在分布式群集上并行运行,其中每个算子的各个并行实例会在单独的线程中独立运行,并且通常情况下是会在不同的机器上运行。
有状态算子的并行实例组在存储其对应状态时通常是按照键(key)进行分片存储的。每个并行实例算子负责处理一组特定键的事件数据,并且这组键对应的状态会保存在本地。
如下图的 Flink 作业,其前三个算子的并行度为 2,最后一个 sink 算子的并行度为 1,其中第三个算子是有状态的,并且你可以看到第二个算子和第三个算子之间是全互联的(fully-connected),它们之间通过网络进行数据分发。通常情况下,实现这种类型的 Flink 程序是为了通过某些键对数据流进行分区,以便将需要一起处理的事件进行汇合,然后做统一计算处理。
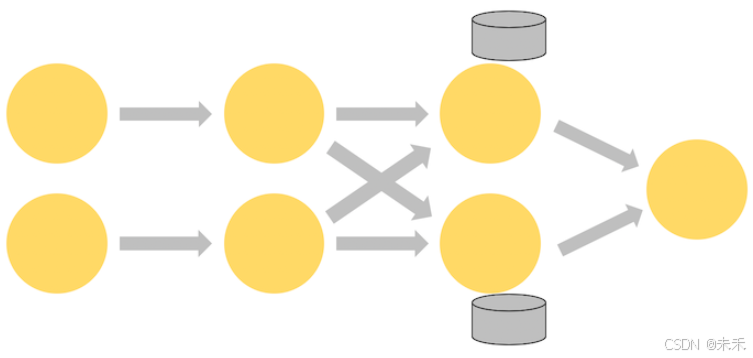
算子的状态
(1)无状态
无状态的算子只需要观察每个独立事件,根据当前输入的数据直接转换输出结果,如map、filter、flatMap,计算时不依赖其他数据,就属于无状态算子。
(2)有状态
有状态的算子任务,则除当前数据之外,还需要一些其他数据来得到计算结果。这里的“其他数据”就是所谓的状态(state)。聚合算子、窗口算子都属于有状态的算子。
Flink 应用程序的状态访问都在本地进行,因为这有助于其提高吞吐量和降低延迟。通常情况下 Flink 应用程序都是将状态存储在 JVM 堆上,但如果状态太大,我们也可以选择将其以结构化数据格式存储在高速磁盘中。
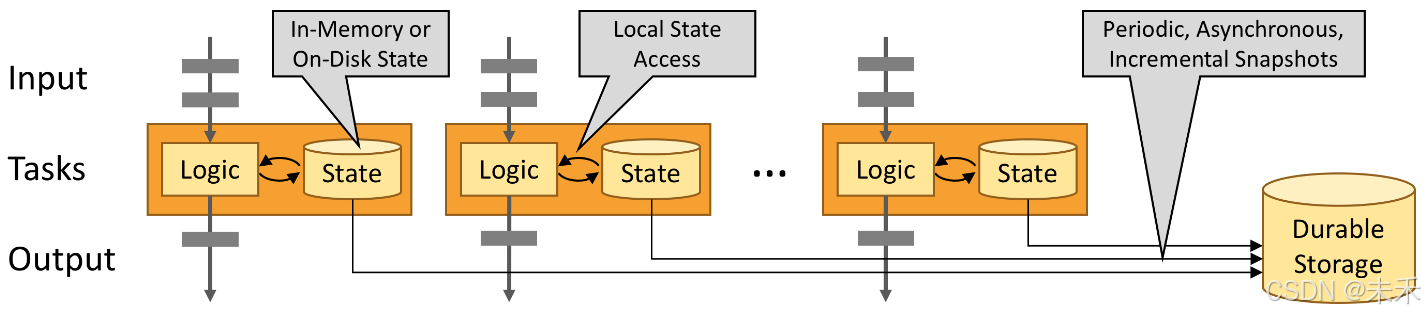
通过状态快照和流重放实现的容错
通过状态快照和流重放两种方式的组合,Flink 能够提供可容错的,精确一次计算的语义。这些状态快照在执行时会获取并存储分布式 pipeline 中整体的状态,它会将数据源中消费数据的偏移量记录下来,并将整个 job graph 中算子获取到该数据(记录的偏移量对应的数据)时的状态记录并存储下来。当发生故障时,Flink 作业会恢复上次存储的状态,重置数据源从状态中记录的上次消费的偏移量开始重新进行消费处理。而且状态快照在执行时会异步获取状态并存储,并不会阻塞正在进行的数据处理逻辑。
State Backends(状态存储)
由 Flink 管理的 keyed state 是一种分片的键/值存储,每个 keyed state 的工作副本都保存在负责该键的 taskmanager 本地中。另外,Operator state 也保存在机器节点本地。Flink 定期获取所有状态的快照,并将这些快照复制到持久化的位置,例如:分布式文件系统。
如果发生故障,Flink 可以恢复应用程序的完整状态并继续处理,就如同没有出现过异常。
Flink 管理的状态存储在 state backend 中。Flink 有两种 state backend 的实现: ①一种基于 RocksDB 内嵌 key/value 存储将其工作状态保存在磁盘上的,②另一种基于堆的 state backend,将其工作状态保存在 Java 的堆内存中
①磁盘:RocksDBStateBackend,将其状态保存到本地磁盘
②堆内存:FsStateBackend,将其状态快照持久化到分布式文件系统;MemoryStateBackend,使用 JobManager 的堆保存状态快照
| 名称 | Working State | 状态备份 | 快照 | 描述 |
|---|---|---|---|---|
| RocksDBStateBackend | 本地磁盘(tmp dir) | 分布式文件系统 | 全量 / 增量 | 支持大于内存大小的状态 经验法则:比基于堆的后端慢10倍 |
| FsStateBackend | JVM Heap | 分布式文件系统 | 全量 | 快速,需要大的堆内存 受限制于 GC |
| MemoryStateBackend | JVM Heap | JobManager JVM Heap | 全量 | 适用于小状态(本地)的测试和实验 |
当使用基于堆的 state backend 保存状态时,访问和更新涉及在堆上读写对象。但是对于保存在 RocksDBStateBackend 中的对象,访问和更新涉及序列化和反序列化,所以会有更大的开销。但 RocksDB 的状态量仅受本地磁盘大小的限制。还要注意,只有 RocksDBStateBackend 能够进行增量快照,这对于具有大量变化缓慢状态的应用程序来说是大有裨益的。
所有这些 state backends 都能够异步执行快照,这意味着它们可以在不妨碍正在进行的流处理的情况下执行快照。
Checkpoint Storage(检查点存储)
Flink 定期对每个算子的所有状态进行持久化快照,并将这些快照复制到更持久的地方,例如:分布式文件系统。 如果发生故障,Flink 可以恢复应用程序的完整状态并恢复处理,就好像没有出现任何问题一样。
这些快照的存储位置是通过作业_checkpoint storage_定义的。 有两种可用检查点存储实现:
①持久保存其状态快照到一个分布式文件系统
②使用 JobManager 的堆
| 名称 | 状态备份 | 描述 |
|---|---|---|
| FileSystemCheckpointStorage | 分布式文件系统 | 支持非常大的状态大小 高度可靠 推荐用于生产部署 |
| JobManagerCheckpointStorage | JobManager JVM Heap | 适合小状态(本地)的测试和实验 |
状态快照
定义
(1)快照:镜像
Flink 作业状态全局一致镜像的通用术语。快照包括指向每个数据源的指针(例如,到文件或 Kafka 分区的偏移量)以及每个作业的有状态运算符的状态副本,该状态副本是处理了 sources 偏移位置之前所有的事件后而生成的状态。
(2)Checkpoint:检查点
由 Flink 自动执行的快照,其目的是能够从故障中恢复。Checkpoints 可以是增量的,并为快速恢复进行了优化。
(3)外部化的 Checkpoint
通常 checkpoints 不会被用户操纵。Flink 只保留作业运行时的最近的 n 个 checkpoints(n 可配置),并在作业取消时删除它们。但可以将它们配置为保留,在这种情况下,你可以手动从中恢复。
(4)Savepoint:保存点
用户出于某种操作目的(例如有状态的重新部署/升级/缩放操作)手动(或 API 调用)触发的快照。Savepoints 始终是完整的,并且已针对操作灵活性进行了优化。
状态快照如何工作?
Flink 使用 Chandy-Lamport algorithm 算法的一种变体,称为异步 barrier 快照(asynchronous barrier snapshotting)。
当 checkpoint coordinator(job manager 的一部分)指示 task manager 开始 checkpoint 时,它会让所有 sources 记录它们的偏移量,并将编号的 checkpoint barriers 插入到它们的流中。这些 barriers 流经 job graph,标注每个 checkpoint 前后的流部分。
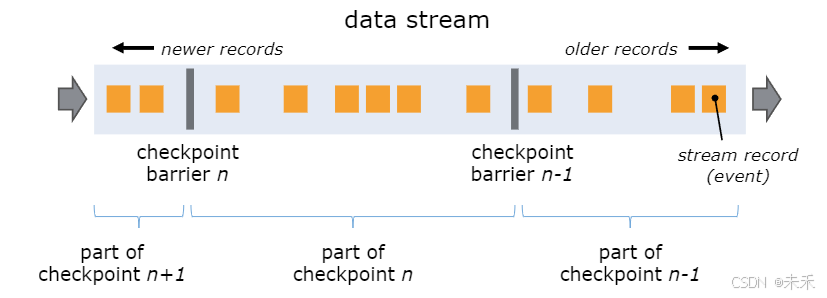
Checkpoint n 将包含每个 operator 的 state,这些 state 是对应的 operator 消费了严格在 checkpoint barrier n 之前的所有事件,并且不包含在此(checkpoint barrier n)后的任何事件后而生成的状态。
当 job graph 中的每个 operator 接收到 barriers 时,它就会记录下其状态。拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment) 以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。
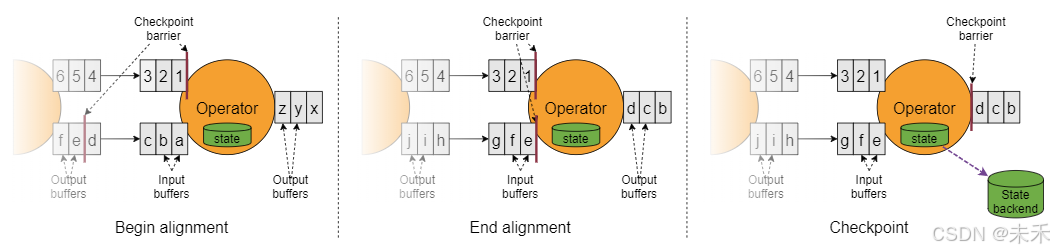
Flink 的 state backends 利用写时复制(copy-on-write)机制允许当异步生成旧版本的状态快照时,能够不受影响地继续流处理。只有当快照被持久保存后,这些旧版本的状态才会被当做垃圾回收。
确保精确一次(exactly once)
当流处理应用程序发生错误的时候,结果可能会产生丢失或者重复。Flink 根据应用程序和集群的配置,可以产生以下结果:
(1)Flink 不会从快照中进行恢复(at most once)
(2)没有任何丢失,但是你可能会得到重复冗余的结果(at least once)
(3)没有丢失或冗余重复(exactly once)
Flink 通过回退和重新发送 source 数据流从故障中恢复,当理想情况被描述为精确一次时,这并不意味着每个事件都将被精确一次处理。相反,这意味着 每一个事件都会影响 Flink 管理的状态精确一次。
Barrier 只有在需要提供精确一次的语义保证时需要进行对齐(Barrier alignment)。如果不需要这种语义,可以通过配置 CheckpointingMode.AT_LEAST_ONCE 关闭 Barrier 对齐来提高性能。
端到端精确一次
为了实现端到端的精确一次,以便 sources 中的每个事件都仅精确一次对 sinks 生效,必须满足以下条件:
(1)sources 必须是可重放的,并且
(2)sinks 必须是事务性的(或幂等的)