背景:
家人最近很爱看查理芒格的文章,希望能做一个文章目录合集,把所有的公众号文章标题保存下来。我想之前学过一些BeautifulSoup提取网页信息的知识,就动手做了一些测试。
正文:
1.手动滚动网页+BeautifulSoup解析HTML获取合集标题:
这个微信公众号的合集页面比较特殊,是个动态加载的网页。传送门
https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzIxOTQwODMzNA==&action=getalbum&album_id=3754847637367488525&subscene=1&scenenote=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzIxOTQwODMzNA%3D%3D%26mid%3D2247489196%26idx%3D1%26sn%3D0560e5d10a818aa8d4804e3c459ed76c%26chksm%3D961ed99e8ee33e1d4fa8b36670a26db3d767ed512ab4acd63b960f81769bfde4d59dc59a05c8%26mpshare%3D1%26srcid%3D0330gKaCngywRfLcXfuugmto%26sharer_shareinfo%3D4ecaed5f49b2aa034f310d9f0bdacb86%26sharer_shareinfo_first%3D4ecaed5f49b2aa034f310d9f0bdacb86%26from%3Dsinglemessage%26scene%3D1%26subscene%3D10000%26sessionid%3D1743227851%26clicktime%3D1743310347%26enterid%3D1743310347%26ascene%3D1%26fasttmpl_type%3D0%26fasttmpl_fullversion%3D7663006-zh_CN-zip%26fasttmpl_flag%3D0%26realreporttime%3D1743310347338%26devicetype%3Dandroid-35%26version%3D28003936%26nettype%3DWIFI%26abtest_cookie%3DAAACAA%253D%253D%26lang%3Dzh_CN%26countrycode%3DCN%26exportkey%3Dn_ChQIAhIQmwA5OQm0zgqjxuurLyJuYBL2AQIE97dBBAEAAAAAAMHsN%252BlmkpIAAAAOpnltbLcz9gKNyK89dVj0GKluV1DPcNwvWJY61S3edeHH0S18aYGkjXv%252B36hLUVT%252FFcOBZHsgLx3NBJnNOM69V8%252B7RMb%252FGCGxXhW0RqfzmRyaZ3%252BiBGXvnPsS4mBeB3SbSO9ECADkeOln7AjMXNSlM%252F737GzqA9Hcea6N%252BJZdyncZf%252BjXlerflGaJIJ0miLDn19GSJ2%252FeHInEUiTMFcV2Mbvb%252BywUnJNsEiuu3QNhngiPLbkcXBfpXjjKqEEcrXRQOAjxAT0BFGQsD6Hptrv5aI0VoX91eC8%252FnDU5DESfqQ%253D%253D%26pass_ticket%3DlvE5hX83IvY2ryzuNsc6hc4rKFgM9YwVmACGIICYu2QmaFKGcg1Jmg2uc6X0kAkG%26wx_header%3D3&nolastread=1#wechat_redirect
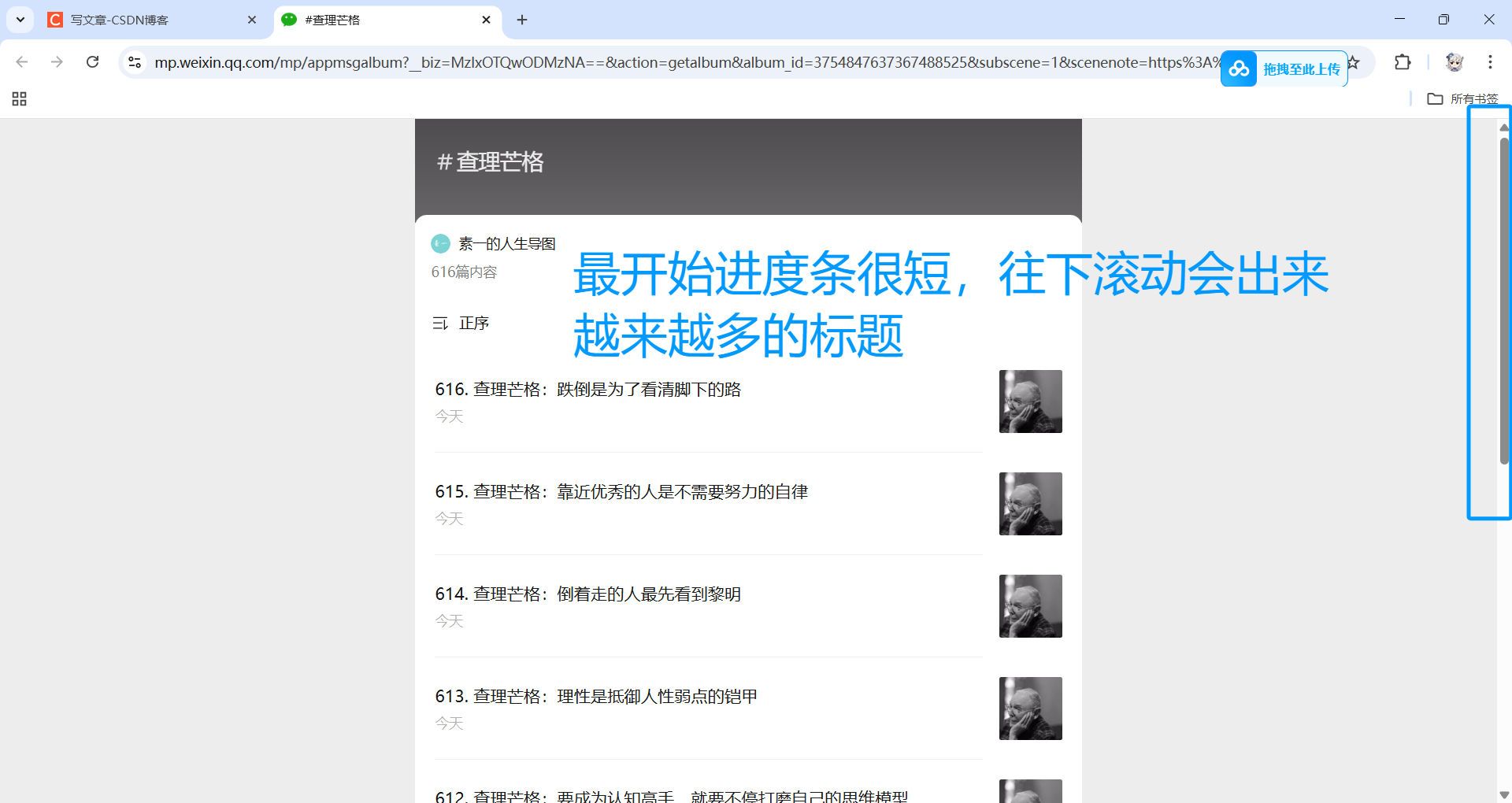
 如果不会或者不想用自动化的话,就简单粗暴,人工把页面拖拽到最底下,确保所有标题都加载完了,然后右键单击网页——另存为——把HTML文件保存下来。
如果不会或者不想用自动化的话,就简单粗暴,人工把页面拖拽到最底下,确保所有标题都加载完了,然后右键单击网页——另存为——把HTML文件保存下来。
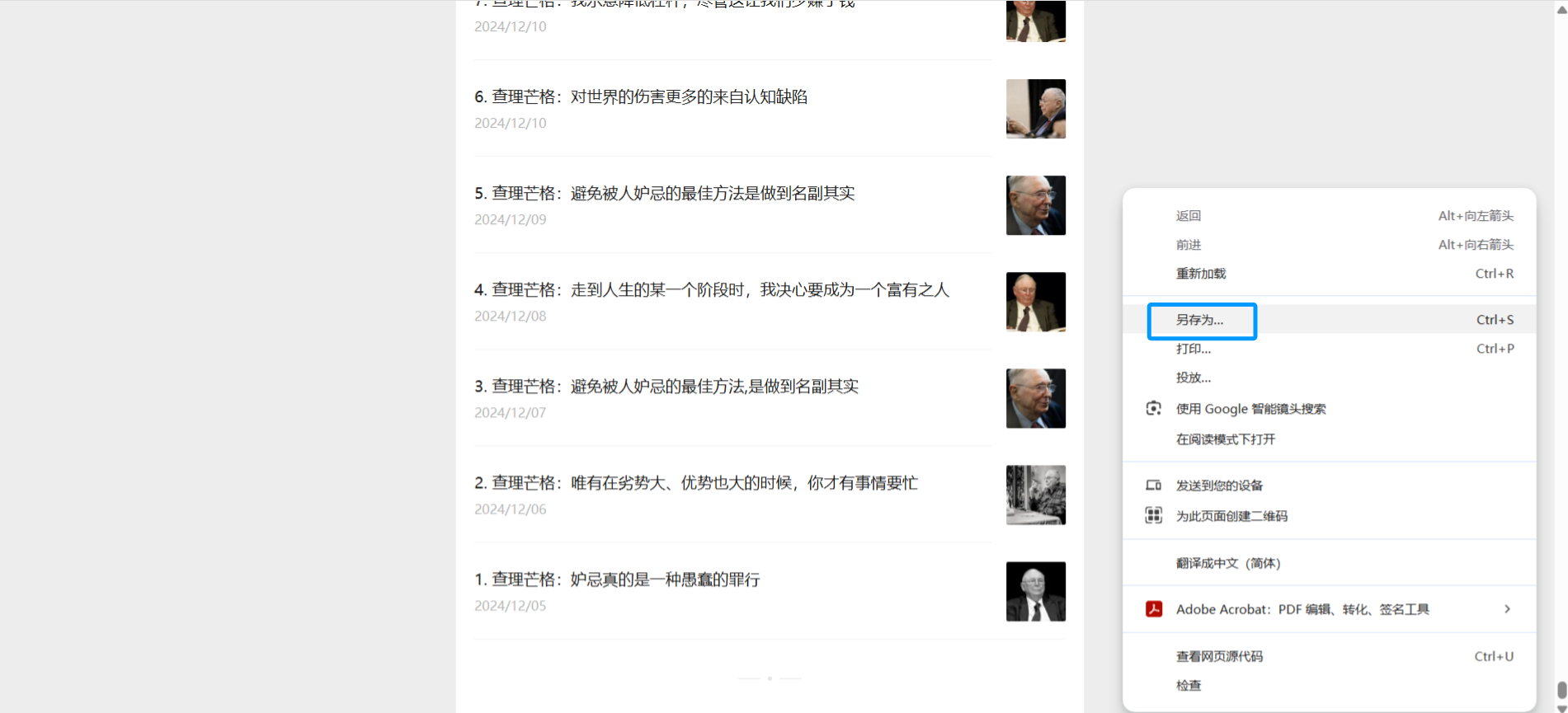
这里的保存选项很重要,必须选择【网页,全部】,也就是会有HTML代码+一个图片等资源文件夹下载到电脑上。
如果【网页(单个文件)】格式会变成mhtml,这个解析起来会比较麻烦,不要选择。
如果选了【网页,仅HTML】,那么HTML文件里没有动态加载的标题,获得的内容不全。
保存好后,打开看是个html文件就很有希望了,为了稳妥起见,可以打开这个文件,随便搜索一个位于原网页很底下的标题,看看是否确实都包括在html文件里面了。
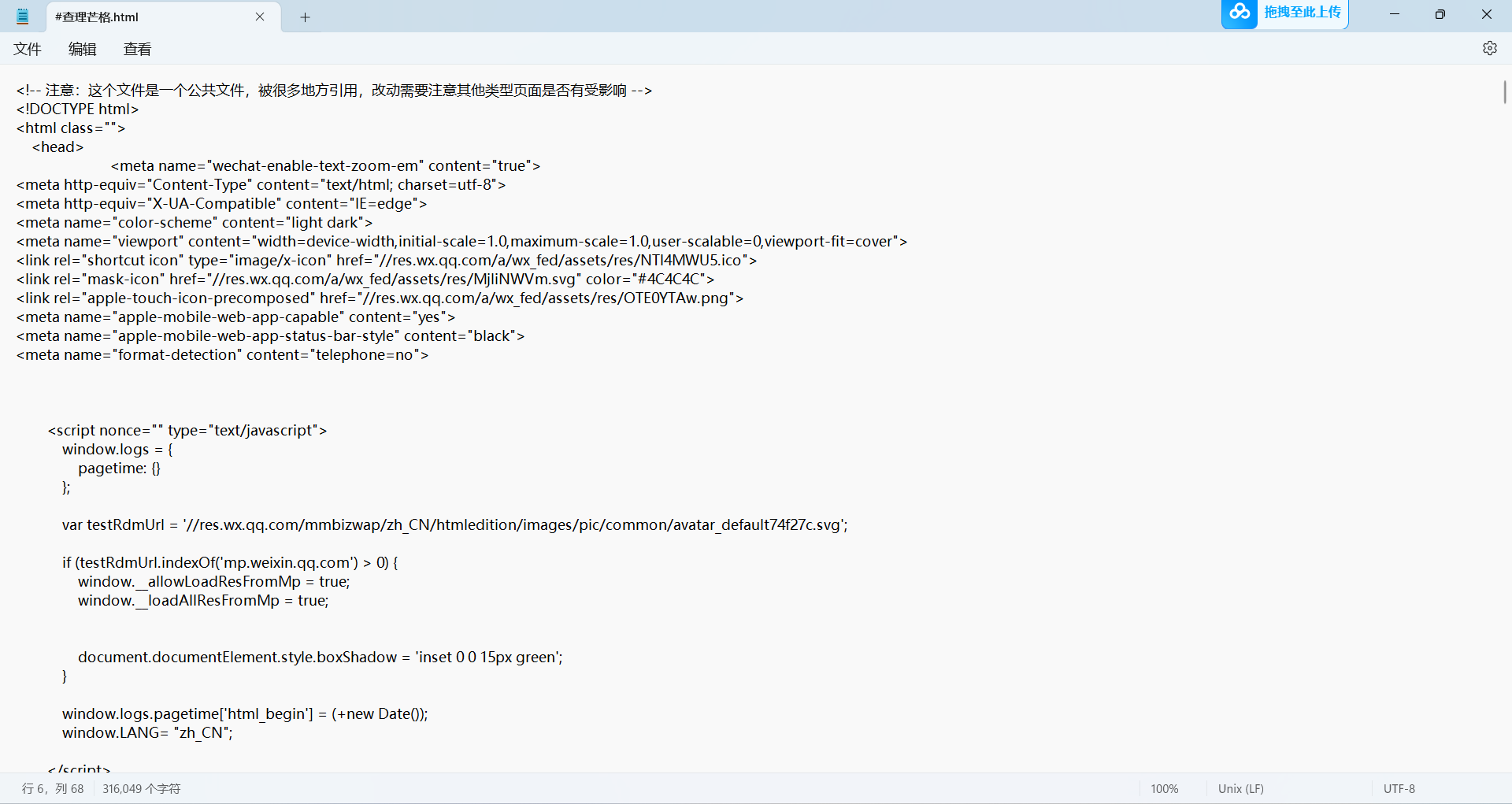
这个html文件可以用记事本打开都行。

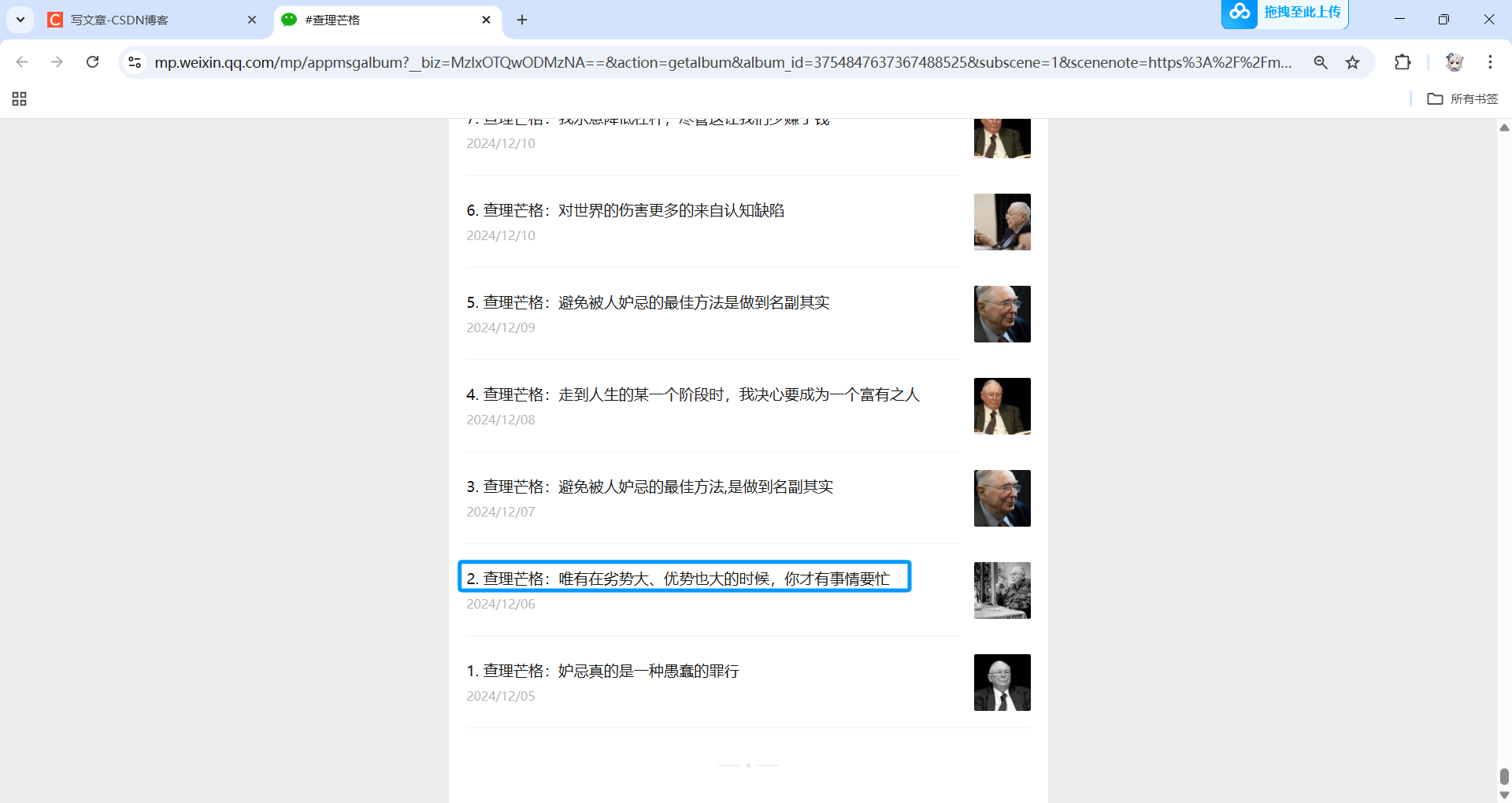
然后,在网页里找到我们需要获取的标题在HTML文件里所在的结构,如类名等。

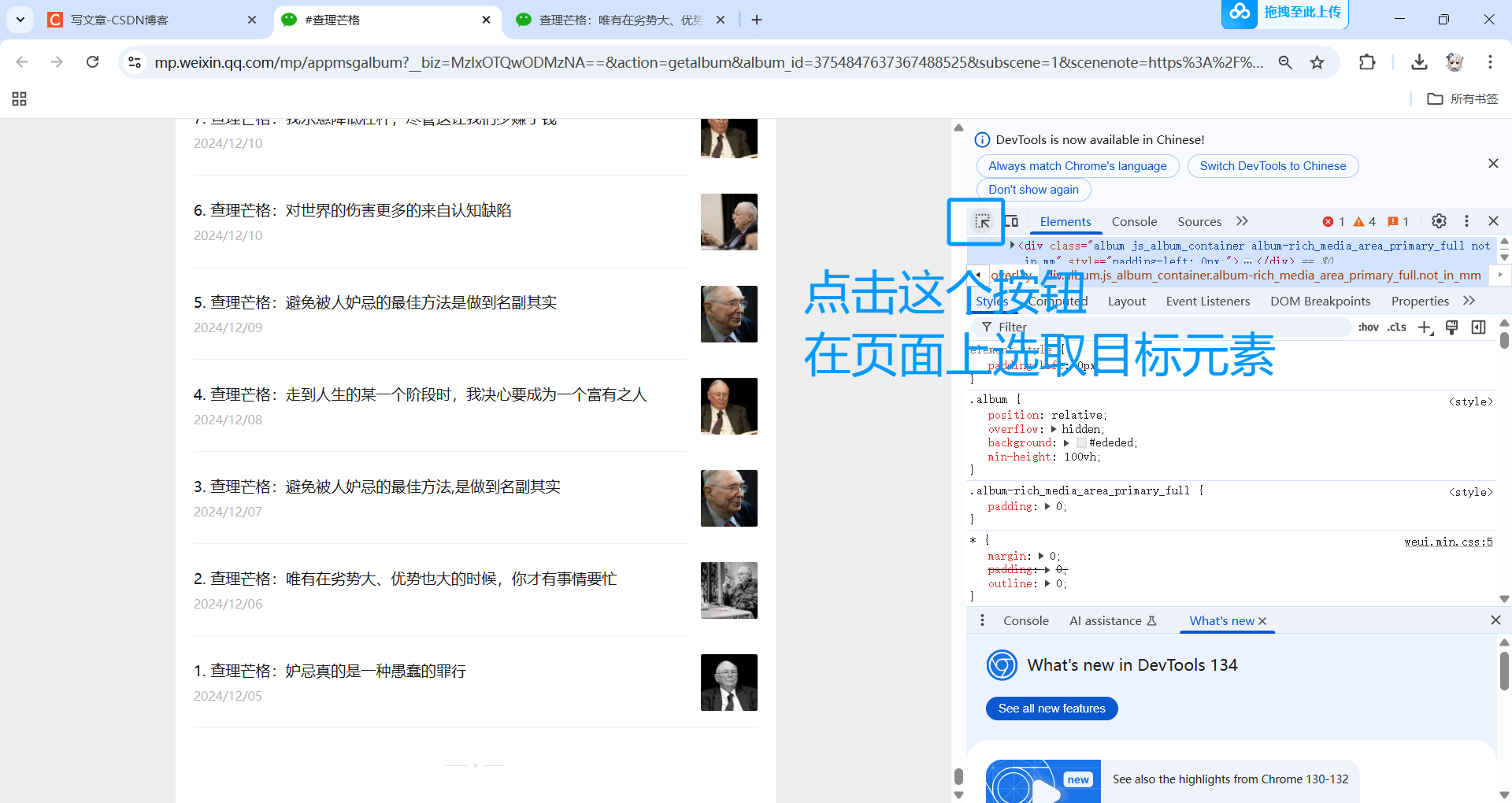
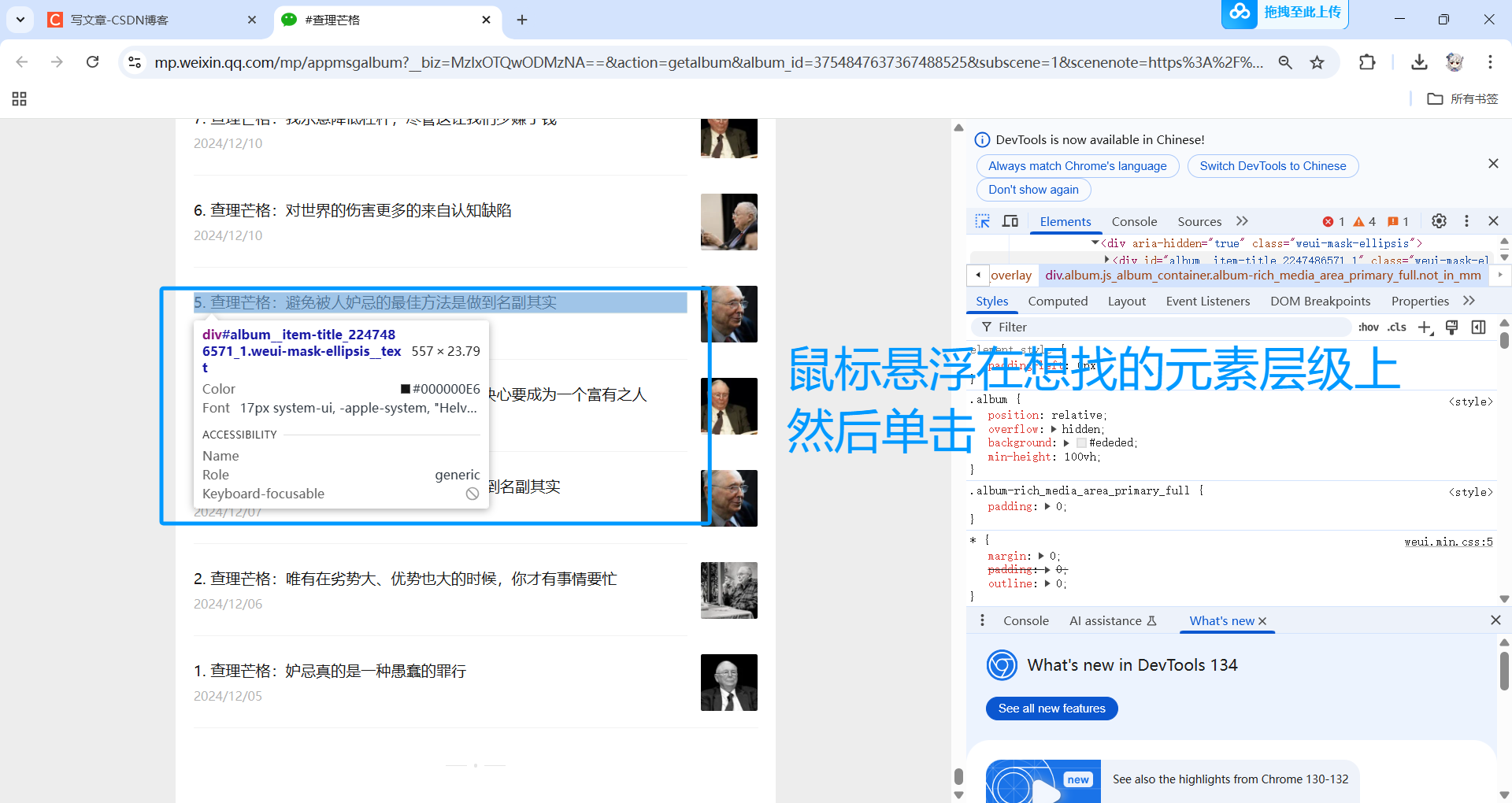
我们要获取的序号和标题所在的HTML结构就找到了。
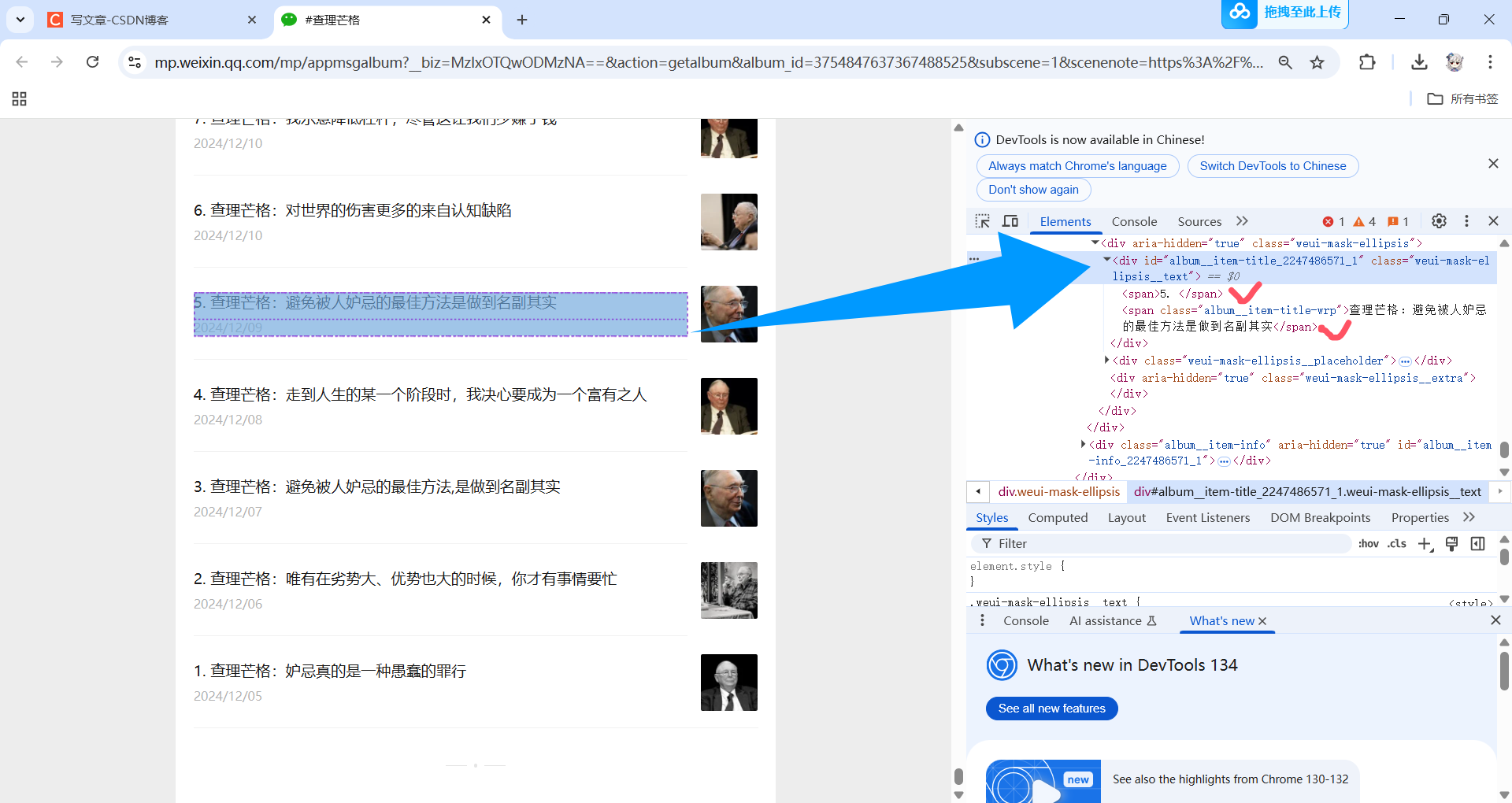
在右侧代码上右键单击,复制元素。

就会得到:
<div id="album__item-title_2247486571_1" class="weui-mask-ellipsis__text"> <span>5. </span> <span class="album__item-title-wrp">查理芒格:避免被人妒忌的最佳方法是做到名副其实</span> </div>
最后,只需要在AI的帮助下写一段Python代码,读入这个html文件,然后调用BeautifulSoup等库正常解析HTML文件就行了。
代码详细逻辑我就不赘述了,我当时想到这个思路,是觉得既然HTML都能拿记事本打开,那么本质上这个任务就是《在一个文本文件里面匹配字符串并组合》,只不过HTML拿元素的方式比普通txt要特殊一些而已,需要按照类名或者正则表达式等方法,在HTML文件里面提取内容,按序号排序,拼接为一个dataframe,最后输出为csv。
如果确实看不明白的,可以粘贴给AI问下。甚至这段代码就是AI写的,我看大致逻辑是正确的+确实功能如期实现了,也没有去深究了。
import os
import pandas as pd
from bs4 import BeautifulSoup
import re # 导入正则表达式模块
# 1. 解析HTML文件
def parse_html(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
html_content = file.read()
return BeautifulSoup(html_content, 'html.parser')
# 2. 提取内容
def extract_data(soup):
items = []
divs = soup.find_all('div', class_='weui-mask-ellipsis__text', id=lambda x: x and x.startswith('album__item-title_'))
for div in divs:
spans = div.find_all('span')
if len(spans) >= 2:
number = spans[0].text.strip()
title = spans[1].text.strip()
items.append(f"{
number} {
title}")
return items
# 3. 去重
def deduplicate(items):
return list(set(items))
# 4. 按序号排序
def sort_by_number(items):
# 使用正则表达式提取序号并转换为整数
def extract_number(item):
match = re.match(r'^(\d+)\.', item)
if match:
return int(match.group(1))
return 0 # 如果没有匹配到序号,默认返回0
return sorted(items, key=extract_number)
# 5. 保存到Excel
def save_to_excel(data, output_file):
df = pd.DataFrame(data, columns=['内容'])
df.to_excel(output_file, index=False)
print(f"数据已保存到 {
output_file}")
# 主函数
def main():
html_file = './#查理芒格.html' # 替换为你的HTML文件路径
output_excel = './output.xlsx' # 输出的Excel文件名
if not os.path.exists(html_file):
print(f"文件 {
html_file} 不存在!")
return
soup = parse_html(html_file)
items = extract_data(soup)
unique_items = deduplicate(items)
sorted_items = sort_by_number(unique_items) # 按序号排序
if sorted_items:
save_to_excel(sorted_items, output_excel)
else:
print("未找到符合条件的内容。")
if __name__ == "__main__":
main()
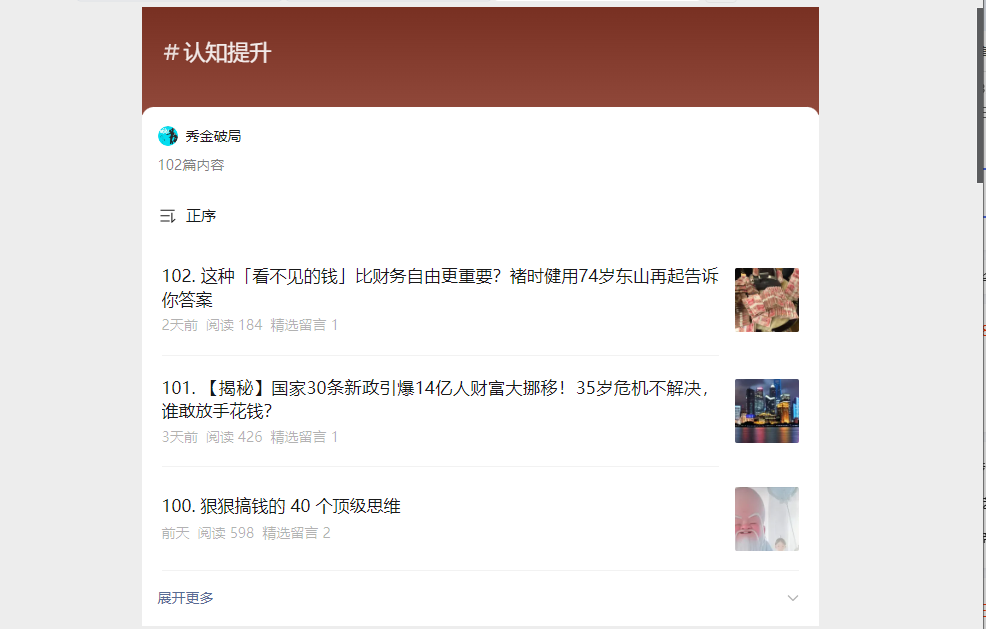
执行程序后,会把解析好的标题放进一个指定目录的CSV文件,并且按序号从小到大排序,效果如图:

1.html存成了mhtml文件怎么办?
如果之前的步骤没能选对,存成了mhtml文件,或者有些坑爹的浏览器,比如QQ浏览器,默认就是存mhtml文件,那么就需要转为html文件。
方法很多,我让AI生成了一些,可以参考:(其实最简单的解决方法是用Chrome浏览器,本来这个浏览器也很好用)

AI写的mhtml转html的Python脚本我单独粘出来,方便大家复制:(其实能实现这个功能的库有很多,我问了不同的AI,每个写的代码都不重样的)
from bs4 import BeautifulSoup
def mhtml_to_html(mhtml_file, output_file):
with open(mhtml_file, 'r', encoding='utf-8') as file:
soup = BeautifulSoup(file, 'html.parser')
html_content = soup.prettify()
with open(output_file, 'w', encoding='utf-8') as outfile:
outfile.write(html_content)
# 示例调用
mhtml_to_html('example.mhtml', 'output.html')
2.尝试更换网页链接获取公众号标题:
如果有一页就加载完的微信公众号合集,不需要滚动翻页的话,可以用下面这段代码,只需更改url链接,设置一下csv文件输出位置,即可获得任意微信公众号链接的文章标题。
例如:下面这个合集都占不完一页展示的。
import os
import pandas as pd
from bs4 import BeautifulSoup
import requests
import re
# 1. 获取网页内容
def fetch_webpage(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # 检查请求是否成功
return response.text
except requests.exceptions.RequestException as e:
print(f"请求失败:{
e}")
return None
# 2. 解析HTML内容
def parse_html(html_content):
return BeautifulSoup(html_content, 'html.parser')
# 3. 提取内容
def extract_data(soup):
items = []
divs = soup.find_all('div', class_='weui-mask-ellipsis__text', id=lambda x: x and x.startswith('album__item-title_'))
for div in divs:
spans = div.find_all('span')
if len(spans) >= 2:
number = spans[0].text.strip()
title = spans[1].text.strip()
items.append(f"{
number} {
title}")
return items
# 4. 去重
def deduplicate(items):
return list(set(items))
# 5. 按序号排序
def sort_by_number(items):
def extract_number(item):
match = re.match(r'^(\d+)\.', item)
if match:
return int(match.group(1))
return 0
return sorted(items, key=extract_number)
# 6. 保存到Excel
def save_to_excel(data, output_file):
df = pd.DataFrame(data, columns=['内容'])
df.to_excel(output_file, index=False)
print(f"数据已保存到 {
output_file}")
# 主函数
def main():
url = 'https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzkyNTQ1MjU0Nw==&action=getalbum&album_id=3765889640343846918&subscene=186&scenenote=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzkyNTQ1MjU0Nw%3D%3D%26mid%3D2247485552%26idx%3D1%26sn%3Db07941e544acbdc11a74380f04ed43bd%26chksm%3Dc1c7181cf6b0910ae13d1399a467142bc0bb1e2aa70efa9047c024c99d5090ac287488262e7b%26scene%3D186%26subscene%3D90%26exptype%3D%26key%3Ddaf9bdc5abc4e8d0f96a9cfbf0cf7f254e780af028163f0c8779dbd5685a565b43eb00014ba898e6514e3b31b1e3e70908ce514276e242670aec8221274b9ec2c5d78e9bf5c56114204e286ba65fb7df6da69e2e3b8678d0f780fe0006db30db01cc94afd240042e5b8d094ddee81337a3dd59b64d2e570b38a1e79352bf92a2%26ascene%3D0%26uin%3DMzcxNDAzMDc0Mw%253D%253D%26devicetype%3DWindows%2B10%2Bx64%26version%3D63090c33%26lang%3Dzh_CN%26countrycode%3DCN%26exportkey%3Dn_ChQIAhIQ9TG8xUAHHuPFzYLw%252F3VHJhLmAQIE97dBBAEAAAAAAEciKHD3iykAAAAOpnltbLcz9gKNyK89dVj0%252Fwgj%252FMV7tcUr4D8DElEICju4lAR8xT9BaptK1S97sgcQcgKZKlFR43%252F3w%252Fl80so5VScX4fdBJjwTzXuxA%252FrAf3XLGQMEyj8jsYdksCrZgd%252F4HgE4I99jf0UjdCR9K7dbETfMOx7hpzV2NKBvWCBTP2nLEd7IwTY7MRyEEdeQEQJ6Bj9EfGEea9Rd2R%252F0krkIxLn2YAq2YvNPKwwes7NtV5j97i3i2bRmRid0MS0ybD9if5bQQPxjtne0cXarkCMQ%26acctmode%3D0%26pass_ticket%3DY9vd6a2uwBev2HsJkrQvH3V8rlPJ%252BDiYV3QvsQsDryA9tIkfnXZFgKUHP1YTLId%252B%26wx_header%3D1&nolastread=1&sessionid=-444382924#wechat_redirect' # 替换为目标网页的URL
output_excel = 'C:/data/QMT/output.xlsx' # 输出的Excel文件名
html_content = fetch_webpage(url)
if not html_content:
print("无法获取网页内容。")
return
soup = parse_html(html_content)
items = extract_data(soup)
unique_items = deduplicate(items)
sorted_items = sort_by_number(unique_items)
if sorted_items:
save_to_excel(sorted_items, output_excel)
else:
print("未找到符合条件的内容。")
if __name__ == "__main__":
main()
我手动滚动到网页底部,保存HTML解析实现后,突然想试试不同的公众号合集,是不是获取同一个HTML样式,之前那套代码逻辑是否还能用,然后这么尝试后发现果然都是一样的标签。
3.给定链接+Selenium自动滚动获取公众号标题:
需要同时满足能自动滚动到页面底端+给url就可以运行,无需手动存文件的话,可以用Selenium库代替人的机械操作。
运行Selenium需要安装对应库,并且需要下载一个适配浏览器的驱动,会有一些要安装环境的步骤。
完成前置流程后,执行下面这段代码,会自动打开Chrome浏览器,把微信公众号合集滚动到页面底端,然后提取HTML来获得我们需要的信息。

import os
import pandas as pd
from bs4 import BeautifulSoup
import re
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
# 使用 Selenium 获取网页内容并自动滚动到最底端
def fetch_webpage_with_selenium(url):
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(url)
scroll_pause_time = 2 # 每次滚动后等待的秒数
last_height = driver.execute_script("return document.body.scrollHeight") #通过执行 JavaScript 代码 document.body.scrollHeight 来获取当前页面的总高度。这个高度会随着页面加载更多内容而变化。
while True:
# 向下滚动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") #将浏览器滚动条滚动到页面底部
time.sleep(scroll_pause_time) #给页面足够的时间加载新内容
new_height = driver.execute_script("return document.body.scrollHeight") #滚动后再次获取页面高度 new_height,并与之前保存的 last_height 进行比较:
if new_height == last_height:
break # 页面高度不变,说明已滚动到底部
last_height = new_height
html_content = driver.page_source
driver.quit()
return html_content
# 解析HTML内容
def parse_html(html_content):
return BeautifulSoup(html_content, 'html.parser')
# 提取指定的标题内容
def extract_data(soup):
items = []
# 找到所有class为weui-mask-ellipsis__text且id以album__item-title_开头的div
divs = soup.find_all('div', class_='weui-mask-ellipsis__text', id=lambda x: x and x.startswith('album__item-title_'))
for div in divs:
spans = div.find_all('span')
if len(spans) >= 2:
number = spans[0].text.strip()
title = spans[1].text.strip()
items.append(f"{
number} {
title}")
return items
# 去重且保留原始顺序
def deduplicate(items):
seen = set()
unique_items = []
for item in items:
if item not in seen:
unique_items.append(item)
seen.add(item)
return unique_items
# 按序号排序
def sort_by_number(items):
def extract_number(item):
# 如果标题以数字开头,如 "1. 标题内容",则提取数字部分
match = re.match(r'^(\d+)', item)
if match:
return int(match.group(1))
return 0
return sorted(items, key=extract_number)
# 保存数据到 CSV 文件,保存在代码所在目录
def save_to_csv(data, output_file):
df = pd.DataFrame(data, columns=['内容'])
df.to_csv(output_file, index=False, encoding='utf-8-sig')
print(f"数据已保存到 {
output_file}")
# 主函数
def main():
# 微信公众号页面的 URL
url = 'https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzIxOTQwODMzNA==&action=getalbum&album_id=3754847637367488525&subscene=1&scenenote=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzIxOTQwODMzNA%3D%3D%26mid%3D2247489196%26idx%3D1%26sn%3D0560e5d10a818aa8d4804e3c459ed76c%26chksm%3D961ed99e8ee33e1d4fa8b36670a26db3d767ed512ab4acd63b960f81769bfde4d59dc59a05c8%26mpshare%3D1%26srcid%3D0330gKaCngywRfLcXfuugmto%26sharer_shareinfo%3D4ecaed5f49b2aa034f310d9f0bdacb86%26sharer_shareinfo_first%3D4ecaed5f49b2aa034f310d9f0bdacb86%26from%3Dsinglemessage%26scene%3D1%26subscene%3D10000%26sessionid%3D1743227851%26clicktime%3D1743310347%26enterid%3D1743310347%26ascene%3D1%26fasttmpl_type%3D0%26fasttmpl_fullversion%3D7663006-zh_CN-zip%26fasttmpl_flag%3D0%26realreporttime%3D1743310347338%26devicetype%3Dandroid-35%26version%3D28003936%26nettype%3DWIFI%26abtest_cookie%3DAAACAA%253D%253D%26lang%3Dzh_CN%26countrycode%3DCN%26exportkey%3Dn_ChQIAhIQmwA5OQm0zgqjxuurLyJuYBL2AQIE97dBBAEAAAAAAMHsN%252BlmkpIAAAAOpnltbLcz9gKNyK89dVj0GKluV1DPcNwvWJY61S3edeHH0S18aYGkjXv%252B36hLUVT%252FFcOBZHsgLx3NBJnNOM69V8%252B7RMb%252FGCGxXhW0RqfzmRyaZ3%252BiBGXvnPsS4mBeB3SbSO9ECADkeOln7AjMXNSlM%252F737GzqA9Hcea6N%252BJZdyncZf%252BjXlerflGaJIJ0miLDn19GSJ2%252FeHInEUiTMFcV2Mbvb%252BywUnJNsEiuu3QNhngiPLbkcXBfpXjjKqEEcrXRQOAjxAT0BFGQsD6Hptrv5aI0VoX91eC8%252FnDU5DESfqQ%253D%253D%26pass_ticket%3DlvE5hX83IvY2ryzuNsc6hc4rKFgM9YwVmACGIICYu2QmaFKGcg1Jmg2uc6X0kAkG%26wx_header%3D3&nolastread=1#wechat_redirect'
# 输出的 CSV 文件名(保存在与代码同一级目录)
output_csv = 'output.csv'
# 获取页面内容(自动滚动加载所有内容)
html_content = fetch_webpage_with_selenium(url)
if not html_content:
print("无法获取网页内容。")
return
# 解析 HTML 内容
soup = parse_html(html_content)
# 提取标题内容
items = extract_data(soup)
if not items:
print("未找到符合条件的内容。")
return
# 过滤掉仅为"0"的项
items = [item for item in items if item.strip() != "0"]
# 去重并按序号排序
unique_items = deduplicate(items)
sorted_items = sort_by_number(unique_items)
# 保存到 CSV 文件
save_to_csv(sorted_items, output_csv)
if __name__ == "__main__":
main()
运行效果:

1.代码运行时的控制台输出:
这个代码运行的时候,可能控制台会输出一些东西:
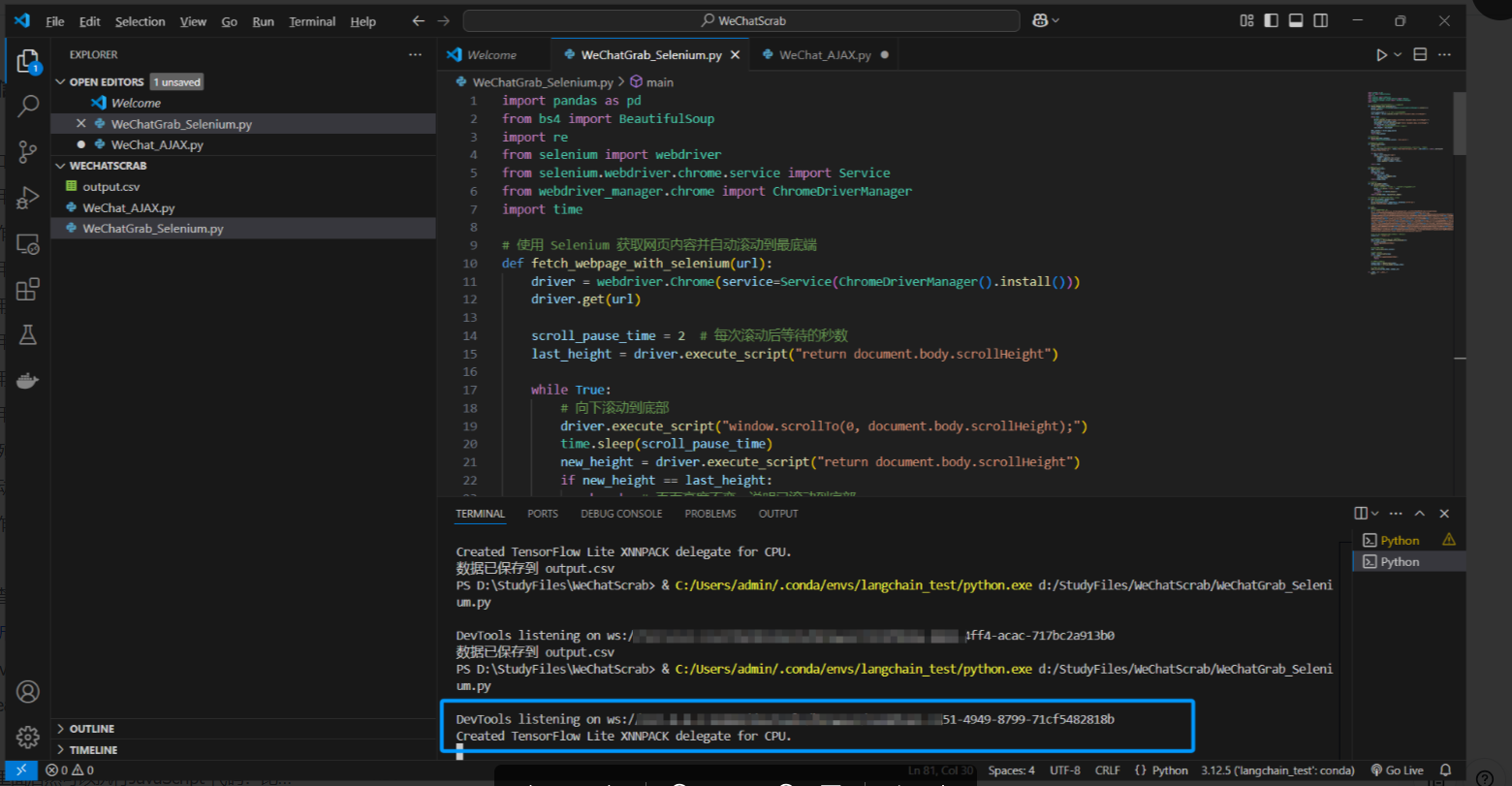
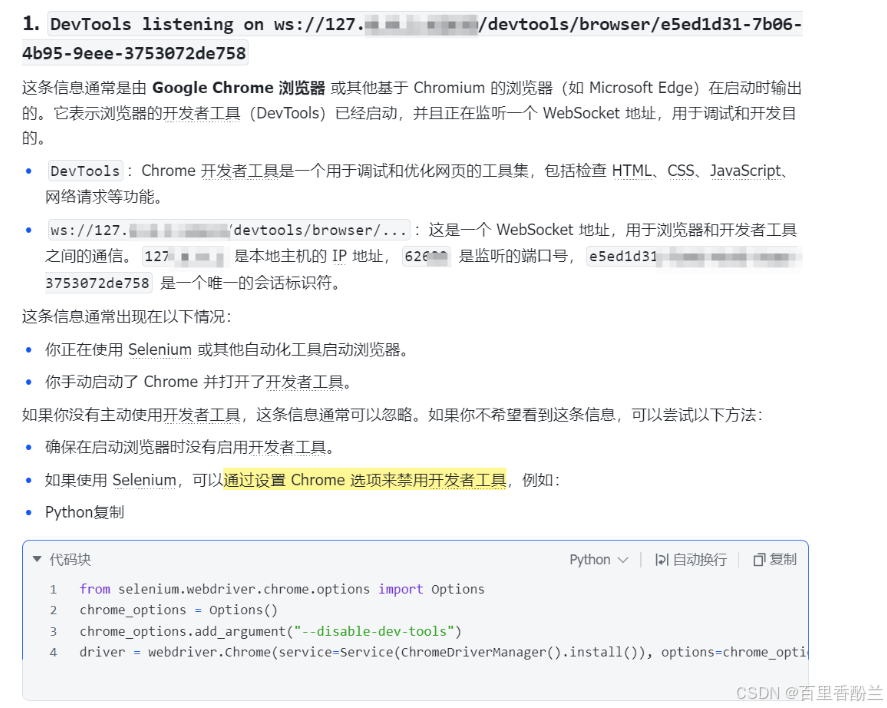
让AI解释了一下,问题不大,如果不需要,可以执行如下代码关闭输出:
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--disable-dev-tools")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)


2.Python里面居然可以执行JavaScript 代码:
这段代码有个我很新奇的地方,就是居然可以把JS代码写在Python里面给程序执行。
例如:
while True:
# 向下滚动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") #将浏览器滚动条滚动到页面底部
time.sleep(scroll_pause_time) #给页面足够的时间加载新内容
new_height = driver.execute_script("return document.body.scrollHeight") #滚动后再次获取页面高度 new_height,并与之前保存的 last_height 进行比较:
if new_height == last_height:
break # 页面高度不变,说明已滚动到底部
last_height = new_height
这个execute_script(“return document.body.scrollHeight”) 就是执行了JS代码。
同样,我找AI询问了解了一下原理,实际上是Selenium把这段JS代码传递给浏览器执行了。

这个是我觉得我在探索过程中发现的最大亮点,太酷啦!!
4.关于Selenium库的一些资料:
我对Selenium库了解也不深,可以给大家推荐的我看的俩入门视频:
1.了解什么是Selenium:传送门
https://www.bilibili.com/video/BV1Sk4y1y7DN/?spm_id_from=333.337.search-card.all.click&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82

2.通过一个实操案例,直观感受Selenium能做什么:传送门
https://www.bilibili.com/video/BV1As4y1v7Zh/?spm_id_from=333.337.search-card.all.click&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
3.如何安装Selenium?
当时我装的时候参考了不少大佬码友的教程,我这里放一些对我有帮助的。
难点集中在以下几个点:1.不知道Python库名称,2.不知道去哪下载驱动,3.不知道把驱动放哪个目录。
1.下载哪个Python库?
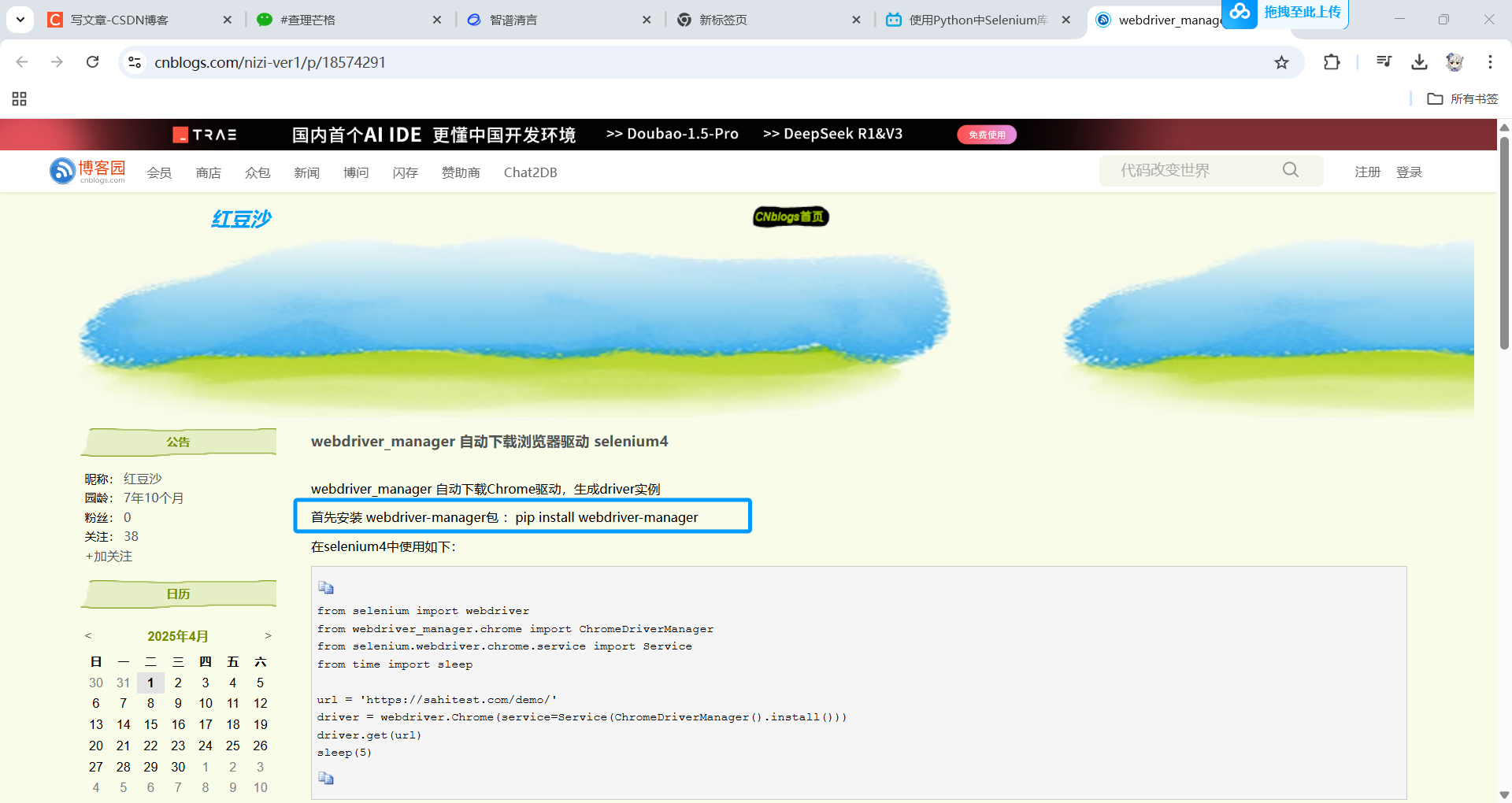
https://www.cnblogs.com/nizi-ver1/p/18574291 传送门
不熟悉这个库的同学可能会有点迷惑,没关系,我找到了。
pip install webdriver-manager
2.去哪下载驱动?
有专门的网站供下载驱动,记得先看好自己Chrome或者其他浏览器对应的版本。
https://blog.csdn.net/weixin_41956627/article/details/139173428 传送门
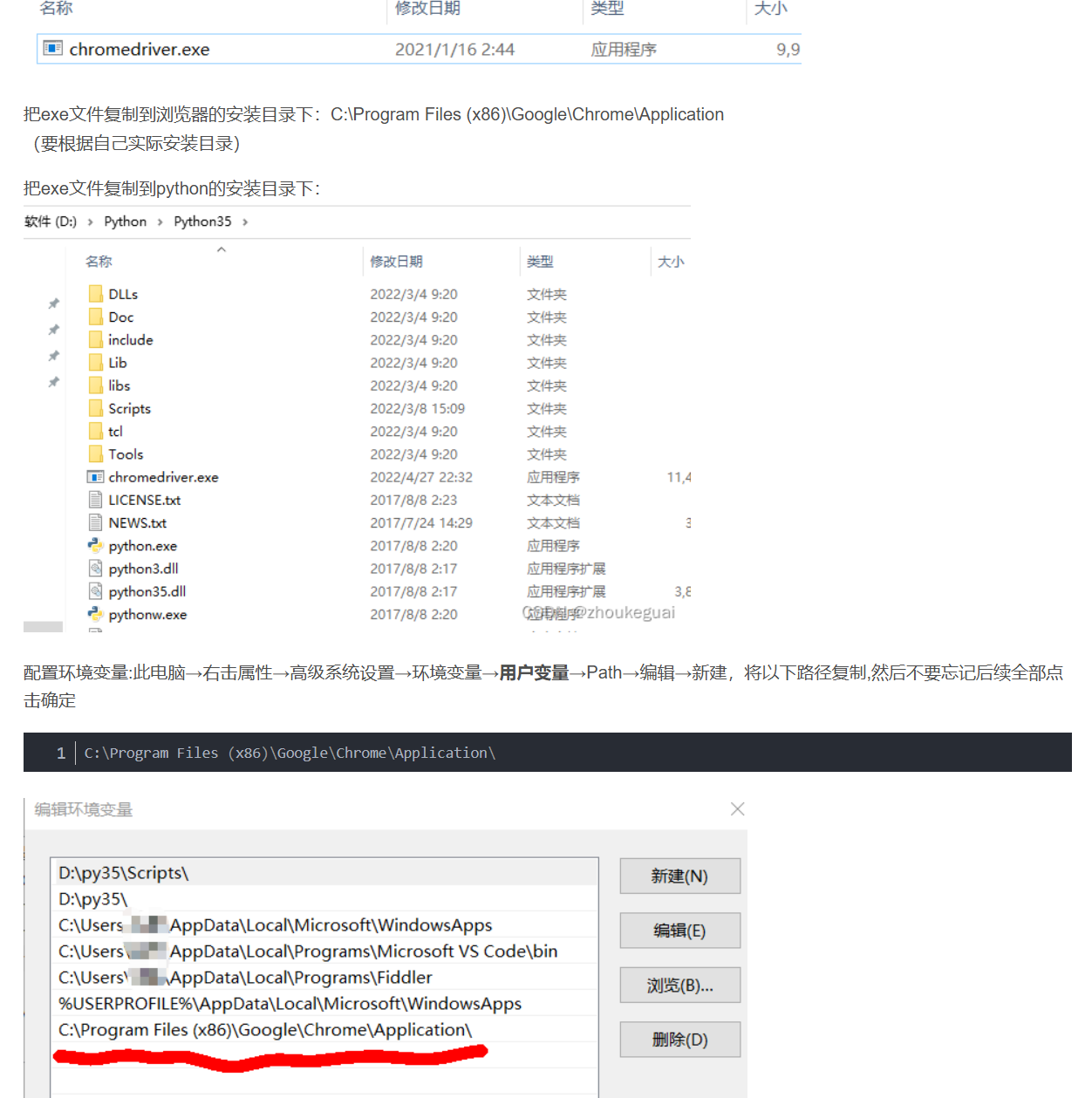
3.把驱动放哪个目录?
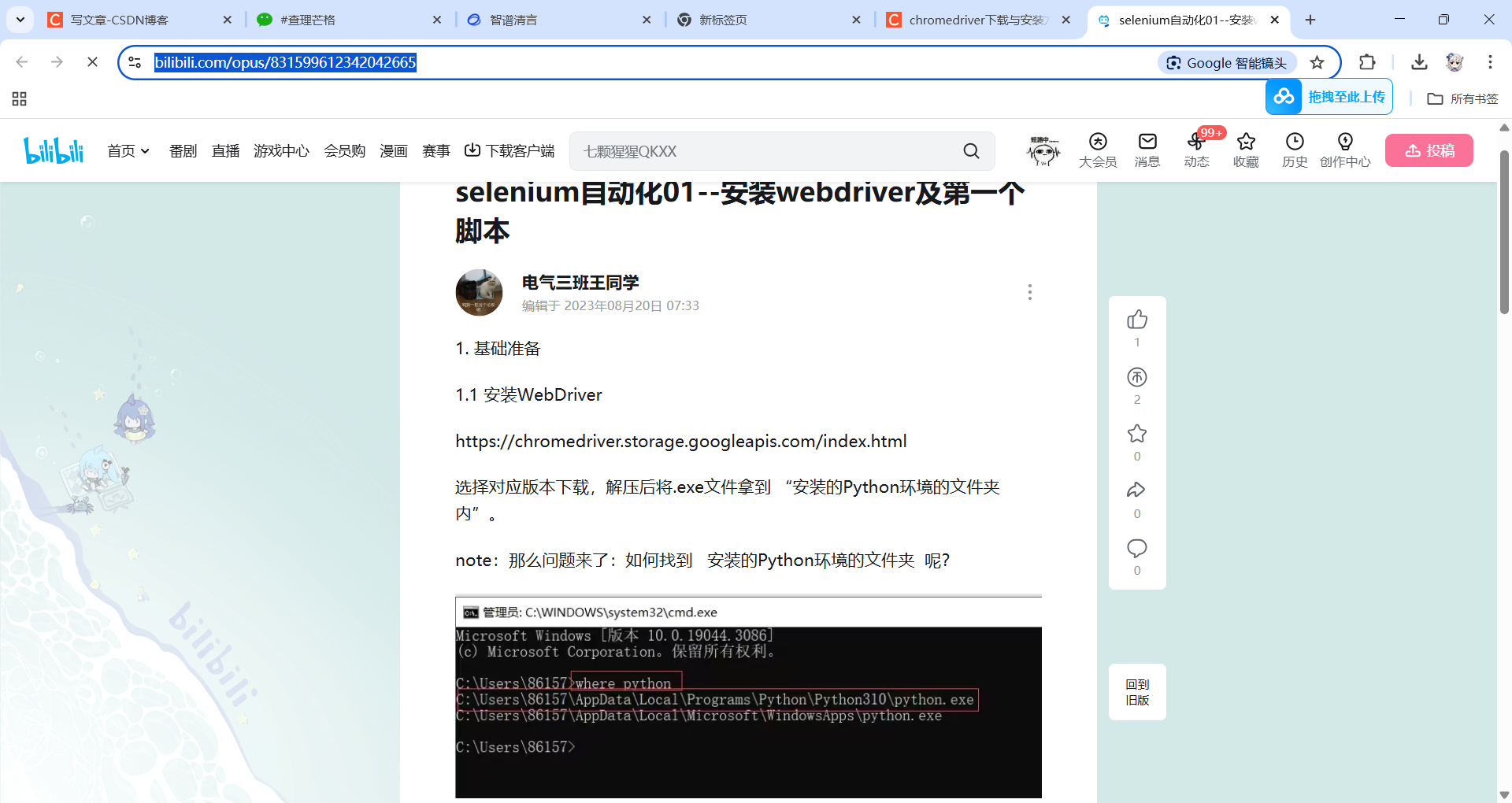
找Python安装目录的方法有很多,cmd窗口输入where python、开始菜单栏有Python快捷方式的可以”查看文件所在位置“、也可以上网查默认安装目录等。
下面是一些我找到的帖子,试了没效果的话自己再搜搜,或者问AI。
https://blog.csdn.net/weixin_45131680/article/details/146508623?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-146508623-blog-80531155.235v43control&spm=1001.2101.3001.4242.1&utm_relevant_index=2 传送门
 https://www.bilibili.com/opus/831599612342042665 传送门
https://www.bilibili.com/opus/831599612342042665 传送门
这个帖子也是个Selenium操作打开B站的实操小案例,新手可以研究下。