前言:
手机刷手机广告多,还费流量。最好是自己抓去生成txt文本,再用小说App打开。随时随地没有流量,没有广告。
包含编程资料、学习路线图、源代码、软件安装包等!【点击这里免费领取】!
技术实现-Python抓取
一,首先随便打开一个小说网站,选一本小说打开第一章。
分析查看网站元素,这是一个GET请求,主要的需要关注的元素有,章节的标题、章节的内容和‘下一章’的链接。 
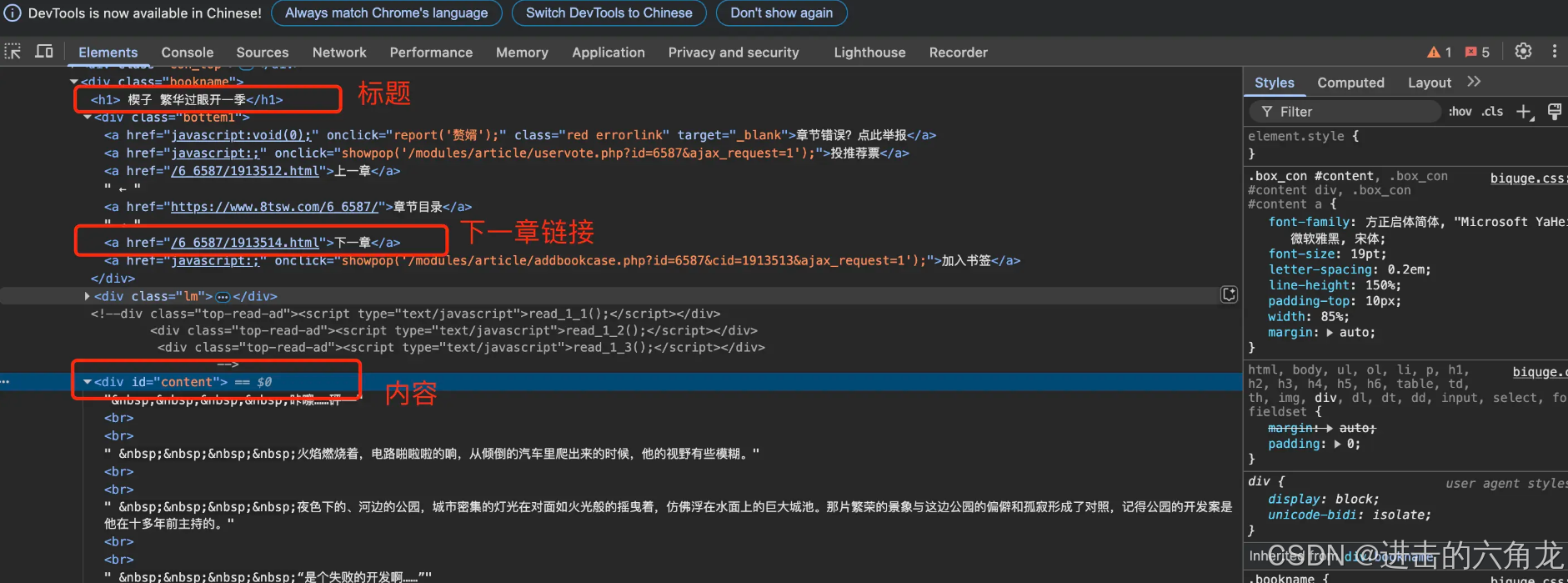
二,创建Python文件模拟网络请求,解析html、写入文件、循环爬取下一章
import html
from operator import truediv
# 倒入网络请求模块
import requests
# 导入lxml用于解析html
from lxml import etree
# 封装请求头,主要是伪装成浏览器
headers = {
'user-agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Mobile Safari/537.36',
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-encoding":"gzip, deflate, br, zstd",
"accept-language":"zh-CN,zh;q=0.9"
}
url = "换成自己打开的小说网章第一章的url"
#不断循环直到最后一章,它的‘下一章’链接就不是以html结尾的
while url.endswith("html"):
resp = requests.get(url, headers=headers)
# 设置为自动检测的编码,否则会出现乱码
resp.encoding = resp.apparent_encoding
# 解析html
tree = etree.fromstring(resp.text, etree.HTMLParser())
# 解析出标题
title = tree.xpath("//h1//text()")[0]
# 解析出内容,info 是一个集合
info = tree.xpath("//div[@id="content"]//text()")
# 将内容拼接起来
content = ""
for txt in info:
#txt无法识别 直接删除
content = content + str(txt).replace(" ", '')
# 打印标题
print(f"title -> {title}")
# 将内容追加的形式写入到txt文件中,文件不存在会自动创建 w:写入, a:追加写入
with open('zhuixu.txt', 'a', encoding='utf-8') as file:
file.write(title + "\n" + content + "\n")
# 写完一章,还有下一章
nextP = tree.xpath("//a[contains(text(),"下一章")]//@href")[0]
# 合成下一章的url
url = f'https://www.xxx.com/{nextP}'
print(f"url -> {url}")
三,结果展示:
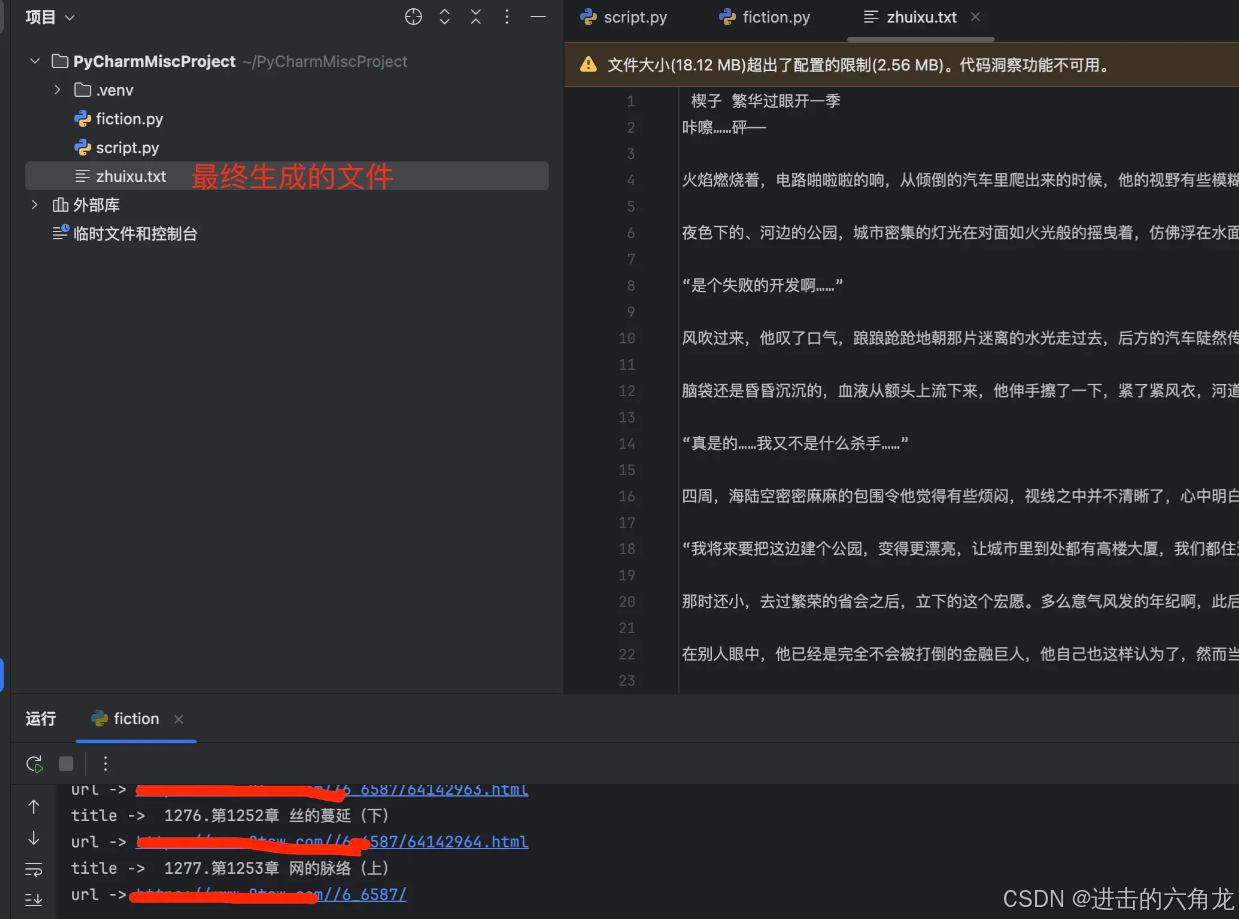
这种是最简单的抓取如果涉及到网络的动态加载,使用 Selenium 或 Puppeteer 等工具模拟浏览器行为,等待内容加载后再爬取