在过去两年中,检索增强生成(RAG,Retrieval-Augmented Generation)技术逐渐成为提升智能体的核心组成部分。通过结合检索与生成的双重能力,RAG能够引入外部知识,从而为大模型在复杂场景中的应用提供更多可能性。但是在实际落地场景中,往往会存在检索准确率低,噪音干扰多,召回完整性,专业性不够,导致LLM幻觉严重的问题。本次分享会聚焦RAG在实际落地场景中的知识加工和检索细节,如何去优化RAG Pineline链路,最终提升召回准确率。
快速搭建一个RAG智能问答应用很简单,但是需要在实际业务场景落地还需要做大量的工作。
本文将主要介绍围绕DB-GPT应用开发框架(https://github.com/eosphoros-ai/DB-GPT),如何在实际落地场景做RAG优化。
一、RAG关键流程源码解读
主要讲述在DB-GPT中,知识加工和RAG流程关键源码实现。
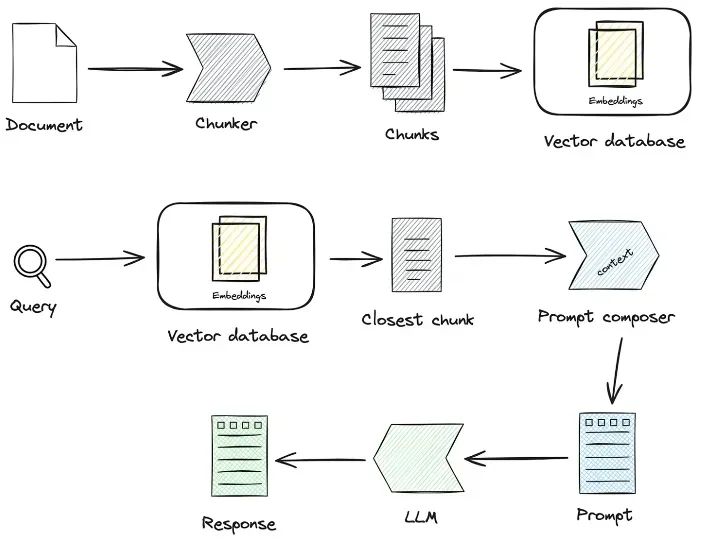
1.1 知识加工
知识加载 -> 知识切片 -&