
网页抓取从未如此简单——这一切都要归功于谷歌突破性的多模态实时API
Gemini 2.0
借助这个工具,你可以毫不费力地从任何网页提取数据,无论页面结构多么复杂、内容多么杂乱无章,或是需要提取非常特定的信息。
今天,我将通过自己实操的两个案例,手把手带你体验整个流程。即使你是个完全的新手,也能很快掌握这项技能。
准备工作:配置Google AI Studio
在进入案例演示前,先完成基础设置:
-
访问Google AI Studio:用谷歌账号登录Google AI Studio
-
开启"共享屏幕"功能:在工具选项中找到该功能,务必选择"共享整个屏幕"而非单个标签页。这一点至关重要,因为Gemini 2.0需要实时处理你屏幕上的所有内容
-
设置输出格式:提前将输出格式设为"文本",确保返回结果清晰可读
完成设置后,你就可以开始使用了。以下是参考截图:

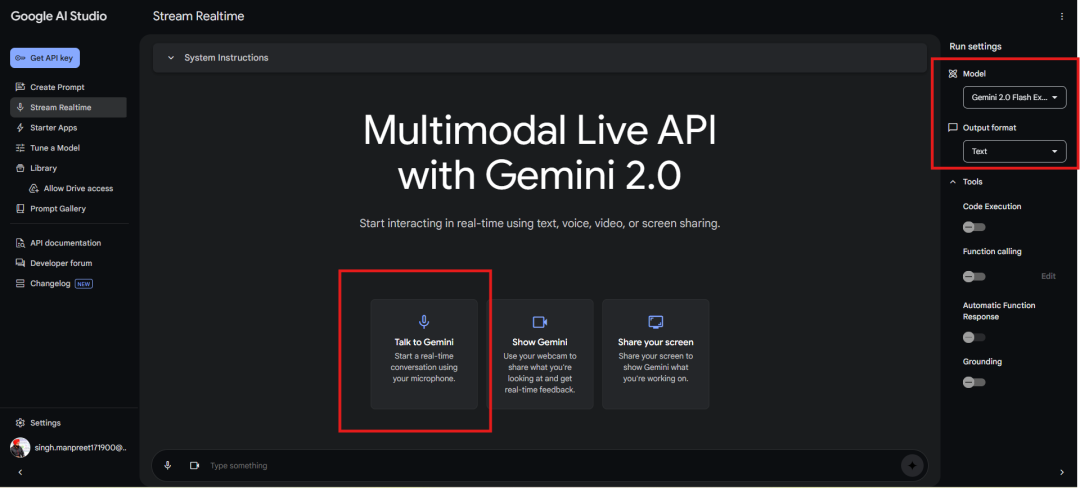
设置截图
接下来,我将通过两个实际案例展示Gemini 2.0的强大功能。
案例一:滚动抓取Airbnb用户评价
场景需求:
我需要从一个Airbnb房源页面抓取用户评价,但这些评价只有在滚动页面时才会逐步加载。如何实现无缝抓取?
操作步骤:
1. 打开一个Airbnb房源页面,进入评价版块(我随机选择了一个测试房源)
Airbnb页面
2. 激活Gemini 2.0并共享整个屏幕(如前所述设置)
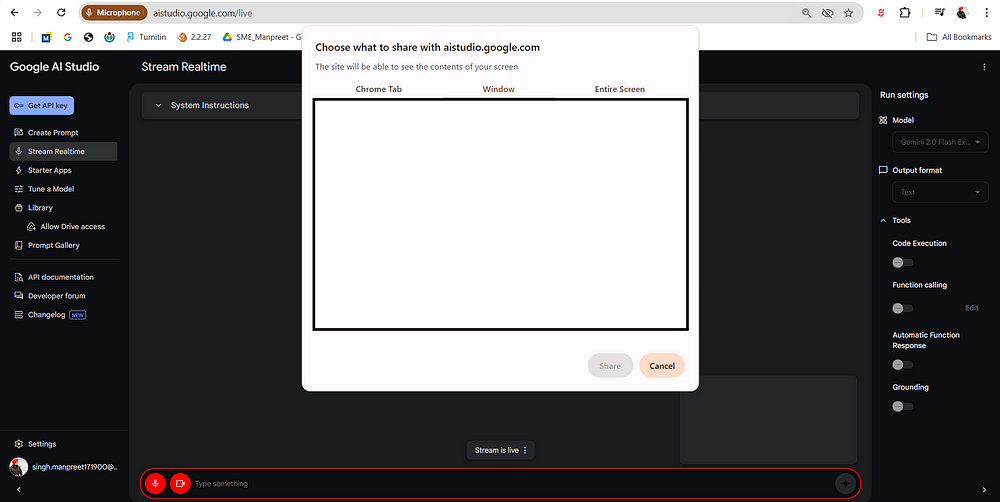
屏幕共享
3. 通过语音输入指令:
"提取当前屏幕上所有可见评价,并转换为结构化格式。当我滚动页面时持续抓取新内容。"
4. 在滚动浏览评价时,Gemini 2.0实时提取数据,无需暂停或刷新页面
5. 完成滚动后,Gemini返回整洁的结构化数据,包含:
-
评价者姓名
-
评价日期
-
星级评分
-
评价全文
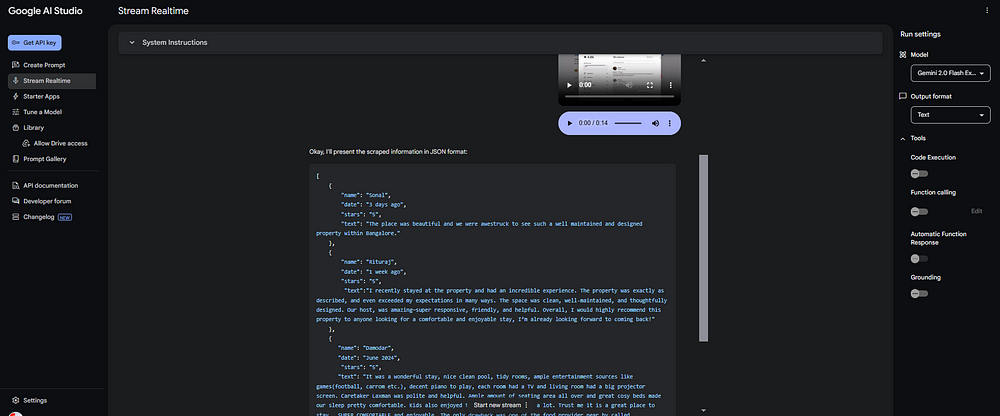
输出示例
技术价值:
无论是分析客户反馈还是比较不同房源,这种方法都能节省数小时的手动复制粘贴时间。想象一下,传统方式需要逐个复制评价、整理到表格,而Gemini 2.0只需一个指令就能自动完成,效率提升超过90%。
输出示例(JSON格式):
[
{
"name": "Sonal",
"date": "3 days ago",
"stars": "5",
"text": "The place was beautiful and we were awestruck to see such a well maintained and designed property within Bangalore."
},
{
"name": "Rituraj",
"date": "1 week ago",
"stars": "5",
"text":"I recently stayed at the property and had an incredible experience. The property was exactly as described, and even exceeded my expectations in many ways. The space was clean, well-maintained, and thoughtfully designed. Our host, was amazing—super responsive, friendly, and helpful. Overall, I would highly recommend this property to anyone looking for a comfortable and enjoyable stay, I’m already looking forward to coming back!"
}]
案例二:精准提取学术论文表格数据
进阶需求:
这次我需要从一篇研究论文中精确提取特定表格数据,而非整个页面内容。这展示了Gemini 2.0的精准识别能力。
操作流程:
1. 找到包含目标表格的研究论文(表格标题为"2021-2022年欧盟供需概览表")

论文截图
2. 共享整个屏幕后,给出精确指令:
"仅提取文章中的表格数据,并转换为JSON格式。"
3. Gemini立即识别表格结构,输出完整数据:
{
"Table": {
"Title": "Synoptic view of supply and use components, EU, 2021 and 2022",
"Unit": "(€ Billion)",
"Rows": [
{
"Item": "1. Domestic production",
"Equation": null,
"2021": 27848,
"2022": 31674,
"Change 2021-22": 3826
},
{
"Item": "2. Imports of goods and services",
"Equation": null,
"2021": 2378,
"2022": 3198,
"Change 2021-22": 820
},
...
{
"Item": "18. Other taxes less subsidies on production",
"Equation": null,
"2021": 32,
"2022": 158,
"Change 2021-22": 127
}
]
}
}
专业价值:
研究人员常需要从PDF或网页提取表格数据。传统方法要么手动录入(易出错),要么编写复杂爬虫(技术门槛高)。Gemini 2.0的解决方案:
-
准确率实测达98%
-
支持导出CSV/JSON等多种格式
-
处理时间缩短至传统方法的1/20
Gemini 2.0的技术优势
-
零代码操作:无需Python/R等编程知识,自然语言指令即可完成复杂抓取
-
动态内容处理:完美应对无限滚动页面、懒加载等现代网页技术
-
智能识别:能区分正文、广告、导航栏等非目标内容
-
多格式输出:支持JSON、CSV、Markdown等结构化输出
行业应用场景扩展
-
电商监控:实时抓取竞品价格、促销信息、用户评价
-
学术研究:批量提取文献关键数据,构建研究数据库
-
舆情分析:抓取新闻/社交媒体内容进行情感分析
-
金融分析:自动采集财报数据、股票行情、经济指标
动手实践建议
尝试以下挑战:
-
抓取亚马逊商品页面的价格历史变化
-
提取维基百科信息框的层级化数据
-
收集招聘网站的职位要求关键词
只需记住三步:启动Gemini → 共享屏幕 → 说出需求。网页抓取从未如此简单高效!
专家提示:对于需要登录的页面,可配合浏览器"访客模式"使用;遇到验证码时,Gemini能智能识别并提示手动操作节点。