区块链100问之共识机制
双花问题解决方法?
答:中心化机构的治理和共识算法的出现。
PS区别机制和算法:
- 机制:是一组规则集,侧重结果。
- 算法:是敏感指令,有明确输出和输入,侧重过程。
分布式系统是什么?数据有什么要求?
答:分布式系统是分布在不同互联网计算机上,组件通过传递信息通信、协调共同完成一个任务。
-
节点:包括计算机、服务器、组件、副本
-
举例:DNS(Domain Name System)分布式数据库
作为一种新型的DNS架构,将解析工作分散到多个节点上,以提高系统的可靠性和性能

要求:一致性,数据要完整同步。
为什么会有同步一说,是因为数据有多个副本replica(是为了保证数据的高可用),放置在不同的物理机器上,为了保证用户像访问同一数据库一样的操作,需要保证这些数据的副本一致,也就是数据同步。
一致性,也叫状态机复制
传统分布式系统一致性问题有?
答:数据多副本面临的问题就是存放副本的机器(也就是数据节点)出现故障,副本无法一致;还有就是网络问题,无法将数据传给不同的节点也不行,导致各个副班之间的数据不一致,数据内容冲突。
总结一下,引起一致性问题的原因有:
- 节点本身:对数据的处理是错误的,或者自己党纪宕机
- 网络:通信有延迟、阻塞,通信不可靠
- 节点间:节点间的速度不太相同,数据在一定时间内不同步
- 特殊:有节点作恶
解决方法:
-
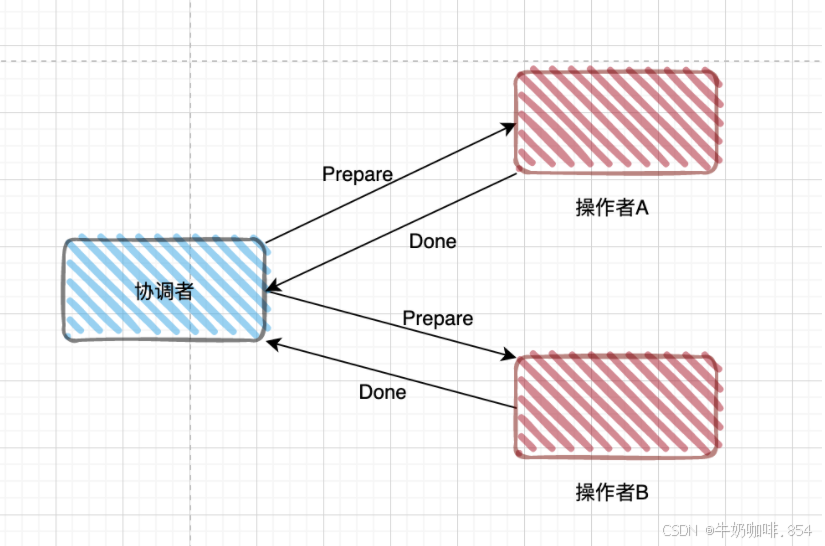
两段式提交
第一阶段:
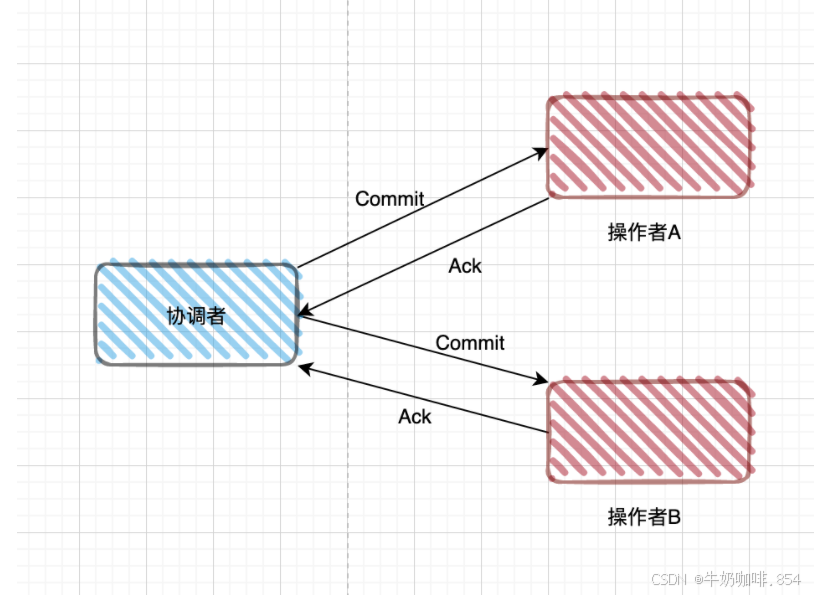
第二阶段:
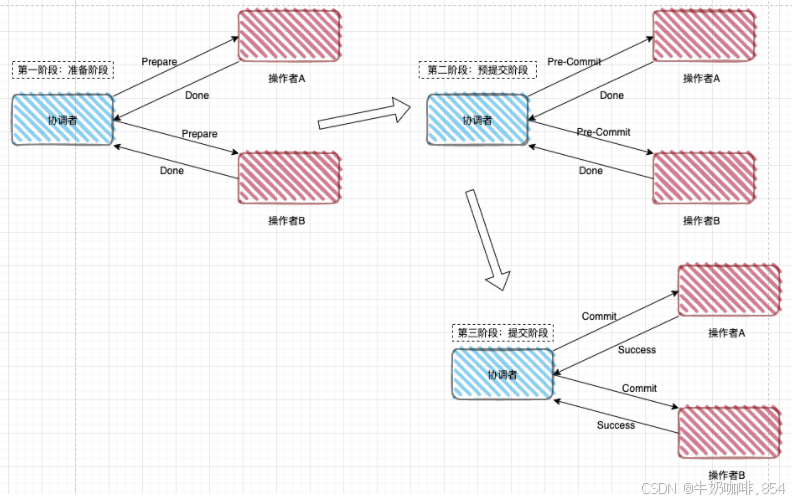
-
三段式提交
引入了超时限制
-
令牌环
FIP定理是什么?
答:即使网络可靠没有问题,分布式系统的共识问题在纯异步环境下还是没法解决。
In this paper, we show the surprising result that no completely asynchronous consensus protocol can tolerate even a single unannounced process death. We do not consider Byzantine failures, and we assume that the message system is reliableit delivers all messages correctly and exactly once.
-
同步:时间误差存在上界
-
异步:时钟误差过大;处理速度可能很慢=>难以区分故障/延时
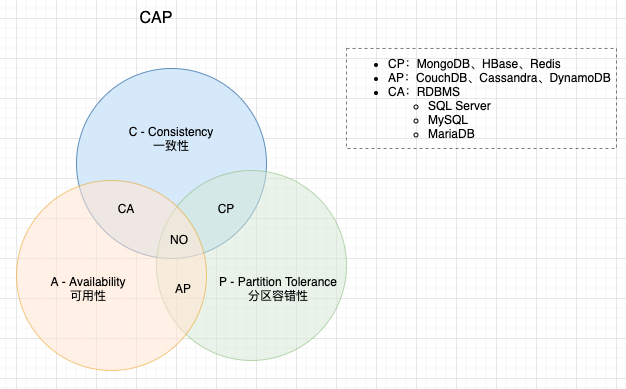
CAP定理是什么?
答:
- C一致性(Consistency):再分布,所有实例节点同一时间看到是相同的数据
- A可用性(Availability):不管是否成功,确保每一个请求都能接收到响应
- P分区容错性(Partition Tolerance):系统任意分区后,在网络故障时,仍能操作
CAP定理就是说,分布式系统不能同时满足这三者,只能同时满足其中的两项,并且P很多时候是必需的,以下是一些组合:
- CP:放弃高可用性,优先考虑一致性,比如zookeeper在leader宕机之后是不提供服务的(不可用)。还有hbase,Neo4j
- AP: 放弃一致性,优先考虑可用性,追求的是最终一致性,比如说POW。
- CA:放弃分区容忍性,也就是非分布式架构,比如关系型数据库(不是分布式系统)
区块链共识算法解决什么问题?有什么特点?
答:共识算法指的是区块链事务达到分布式共识,从而建立信任。
那么在区块链事务中需要解决什么呢?
- 如何创建区块
- 创建区块之后如何维护全网数据一致
主要特点就是:少数服从多数(多方参与博弈,最终达成共识)
共识算法的分类?
答:
-
强一致性非拜占庭共识算法(Paxos/Raft)
-
强一致性拜占庭共识算法(PBFT)
-
非强一致性共识算法(POW/POS)
什么是拜占庭将军问题?什么是拜占庭容错算法?
答:拜占庭将军问题就是基于一个不完全受信任的环境下(也就是有恶意节点),如何将各个节点的数据同步,并在各个节点上达成共识,使整个计算机系统可靠。
拜占庭帝国派出多支军队去围攻一个强大的敌人,每支军队有一个将军,但由于彼此距离较远,他们之间只能通过信使传递消息。敌方很强大,必须有超过半数的拜占庭军队一同参与进攻才可能击败敌人。在此期间,将军们彼此之间需要通过信使传递消息并协商一致后,在同一时间点发动进攻。
- **拜占庭容错算法(BFT算法)**广义上就是解决拜占庭将军的问题,也就是解决分布式系统中既存在节点故障又存在恶意攻击的场景下的共识问题。包括pbft算法和非pbft算法。
- 故障容错算法,也就是非拜占庭容错算法,解决分布式系统中存在的故障,但没有恶意攻击,该场景下消息可能会丢失重复,但不存在伪造或篡改。

如何解决拜占庭问题?Pbft算法各个阶段?
答:BFT算法是解决这个问题的统称。分为两个:
-
概率算法:PoW(共识结果暂定)
-
确定性算法:PBFT(共识即结果)
该情况下有解 n > = 3 f + 1 f : 故障节点数 n : 总服务节点数 该情况下有解\ n>=3f+1\ f:故障节点数\ n:总服务节点数 该情况下有解 n>=3f+1 f:故障节点数 n:总服务节点数
协议:- 一致性协议(不适用于公有链)
- primary: 主节点
- Backups:备份/副本
- 检查点协议:CheckPoint:最终确定不可修改
- 视图更换协议
- 局部视图
- 全局视图
5阶段:
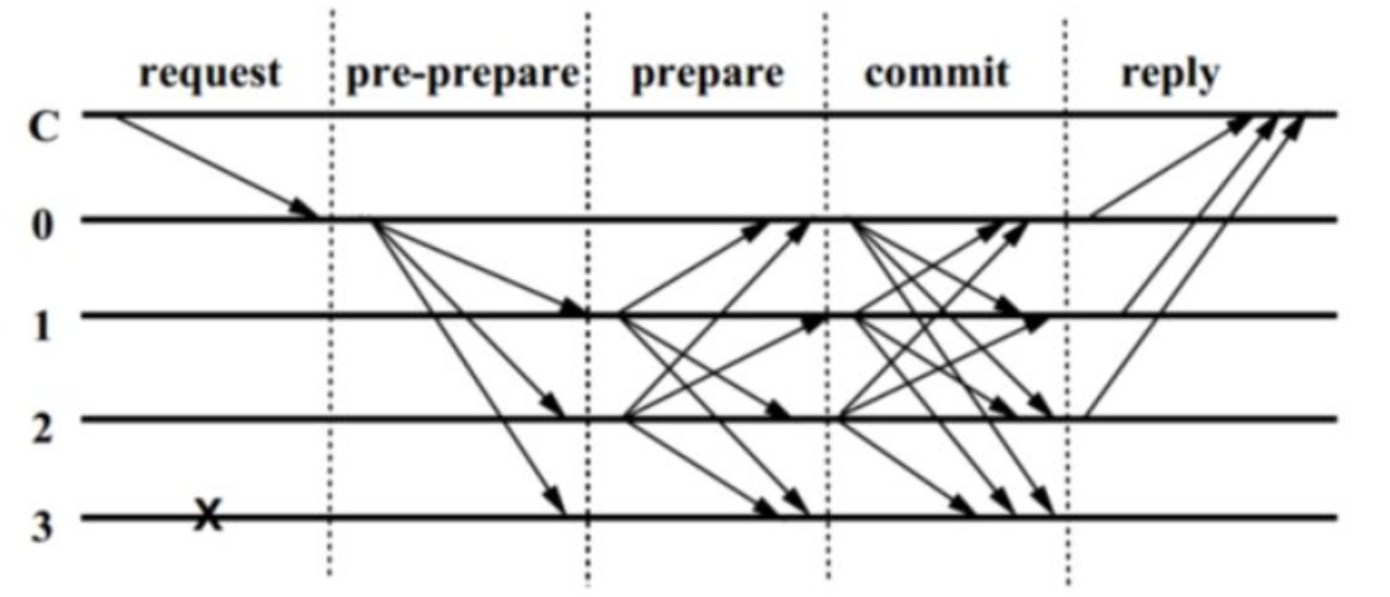
-
request:client发起request
(content,ID,Timestamp) -
pre-prepare:primary发起广播消息pre-prepare
replica收到消息
<<PRE_PREPARE,v,n,d>,m>并进行验证通过 -
prepare:replica通过后接受并发送prepare消息
收到超过 2f 个其他节点的prepare 消息,就代表 prepare 阶段已经完成。
-
commit: 各个节点发送commit消息
当前节点i接收到2f个来自其他共识节点的commit消息
<COMMIT,v,n,d,i>同时将该消息插入log中(算上自己的共有2f+1个) 验证这些commit消息和自己发的commit消息的v,n,d三个数据都是一致后,共识节点将
committed-local(m,v,n)设置为true。 -
reply:client收到f+1个reply即可,这f+1个reply也就是f+1个
committed-local(m,v,n)为true也就是至少f+1个节点得到了2f+1个节点得到的commit共识。
- 一致性协议(不适用于公有链)
下图为n=4的示意:
**问题:**依赖主节点
解决:设置超时机制;replica发现作恶发起view change协议,重新选取主节点
PoW机制工作原理?
答:作为比特币的共识,每个节点独立选择最长链的区块链(包含区块最多的链),全网的所有节点都选择一条链则达成共识,即本地都保存内容一致的主链,而这是概率性的:
-
一致性:在不诚实节点总算力小于50%的情况下(即允许有1/2n节点作恶),同时每轮区块生成的区块很少的情况下,诚实的节点具有相同的区块的概率很高
-
正确性(validity):大多数的区块必须由诚实节点提供。严格来说,当不诚实算力非常小的时候,才能使大多数区块由诚实节点提供
比特币网络达到一致性的概率会随确认区块的数目增多而呈指数型增加。但当不诚实算力具有一定规模,甚至不用接近50%(例如30%)的时候,比特币的共识算法并不能保证正确性,即可能发生51%算力攻击
适用范围:公有链;共识效率比较低但安全性比较高
对比Pbft算法和PoW?
答:
| pbft算法 | PoW算法 | |
|---|---|---|
| 适用范围 | 联盟链 | 公有链 |
| 去中心化程度 | 去中心化程度较弱,需要选举primary | 去中心化程度较高,但是节点算力逐渐失配 |
| 效率 | 允许节点较少(个数固定),效率较高 | 节点数量不限,效率不高 |
| 安全性 | 较低,不能防女巫攻击 | 较高 |
| 耗电 | 不耗电 | 耗费大量电力,资源浪费 |