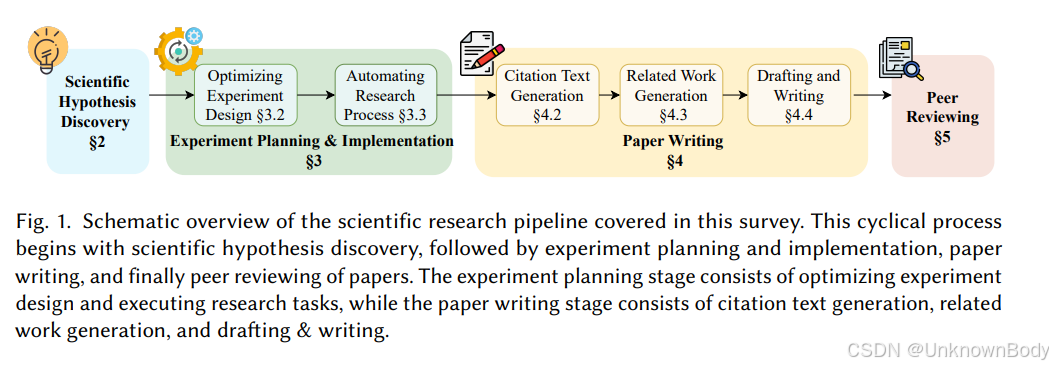
文章主要内容
文章围绕大语言模型(LLMs)在科学研究中的应用展开,系统探讨了其在科研各关键阶段的作用、方法、挑战及未来方向。
- 科学假设发现:LLMs生成科学假设的研究源于“基于文献的发现”和“归纳推理”。现有方法通过灵感检索策略、反馈模块等组件提升假设生成质量,相关基准测试分为基于文献和数据驱动两类,评估指标涵盖新颖性、有效性等。虽取得一定成果,但面临实验验证困难、依赖现有LLMs能力等挑战。
- 实验规划与实施:LLMs在实验设计优化中,通过任务分解、高级提示技术等提高实验效率;在实验过程自动化方面,涵盖数据准备、执行和数据分析等环节;相关基准测试用于评估其对实验工作流的支持效果。然而,其规划能力有限、易产生幻觉,在特定场景适应性上存在不足。
- 科学论文写作:LLMs在论文写作的引用文本生成、相关工作生成和起草写作等方面均有应用,不同任务采用不同方法和评估基准。但存在事实准确性、上下文连贯性等问题,还引发了学术诚信方面的担忧。
- 同行评审:LLMs融入同行评