点一下关注吧!!!非常感谢!!持续更新!!!
Java篇开始了!
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新…)
- Spark MLib (正在更新…)
Spark MLib 介绍
SparkMLib 是Spark的机器学习库(Machine Learning),封装了一些通用机器学习算法和工具,便于我们开展机器学习实践。
具体来说,SparkMLib 主要包括以下几块内容:
- 常用算法:包括类、回归、聚类和协同过滤
- 特征化工具:包括特征提取、转换、降维和选择工具
- 管道:用于构建、评估和调整机器学习管道的工具
- 持久化工具:保存和加载算法、模型、管道
- 其他工具:线性代数、统计、数据处理等
支持的机器学习算法
Spark MLib 支持4种常见机器学习算法(分类、回归、聚类、推荐算法)且计算效率较高
分类算法
基本分类
- 决策树分类:DecisionTreeClassifier
- 支持向量机:LinearSVC
- 朴素贝叶斯:NaiveBayes
- 逻辑回归:LogisticRegression
- 集成分类算法:基于决策树之上的算法
- 梯度提升树:GBTClassifier
- 随机森林:RandomForestClassifier
回归算法
- 基本回归算法
- 线性回归:LinearRegression
- 决策树回归:DecisionTreeRegressor
- 集成回归算法
- 梯度提升树:GBTRegressor
- 随机森林:RandomForestRegressor
聚类算法
- KMeans
- BisectingKMeans
- GaussianMixture
- LDA
推荐算法
- 协同过滤算法:ALS
- 关联规则:AssociationRules、FPGrowth
环境准备
我当前是在 MacOS M1 下进行测试学习,如果你是别的环境,类似即可。
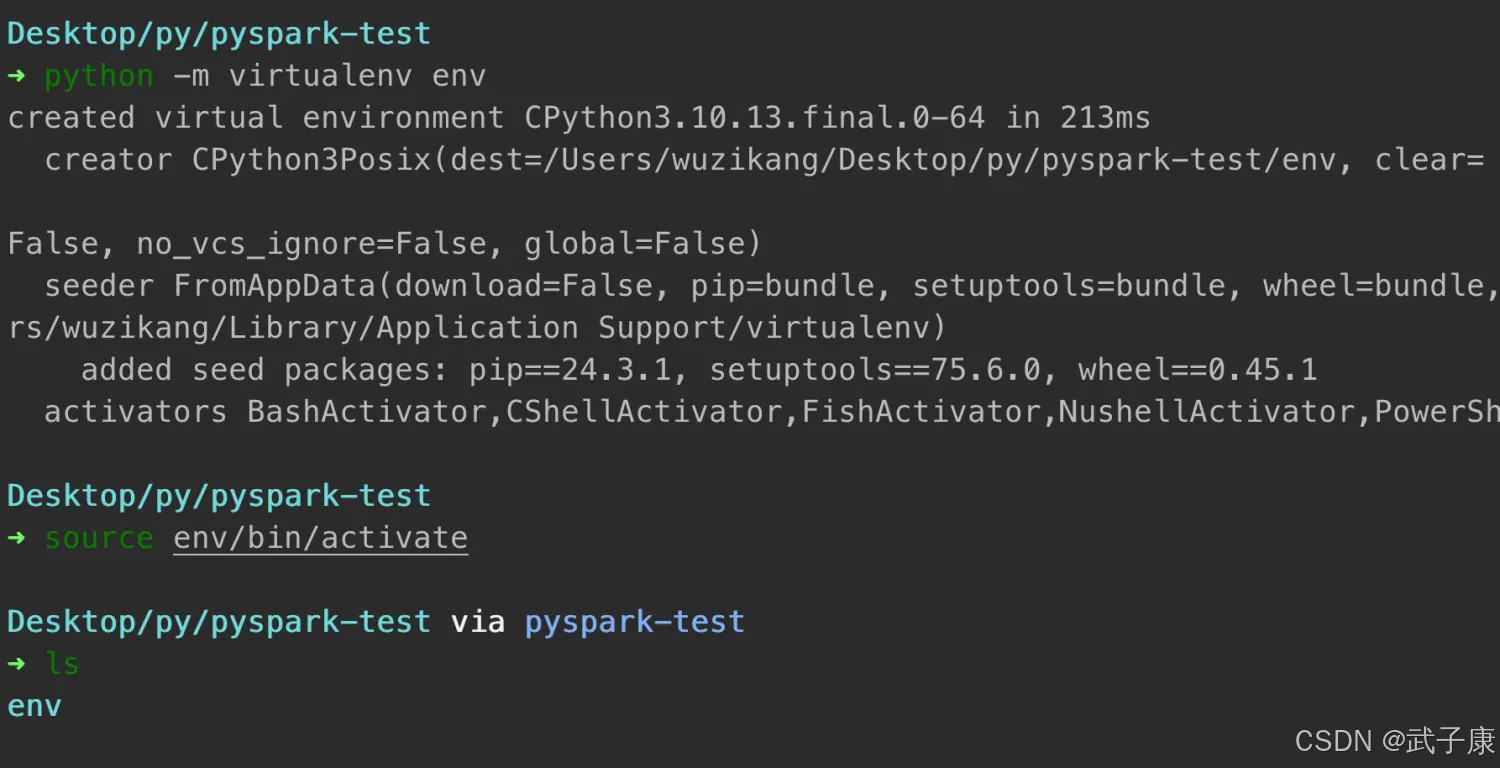
我们安装包:
python -m virtualenv env
source env/bin/activate
对应截图如下所示:
WordCount
编写代码
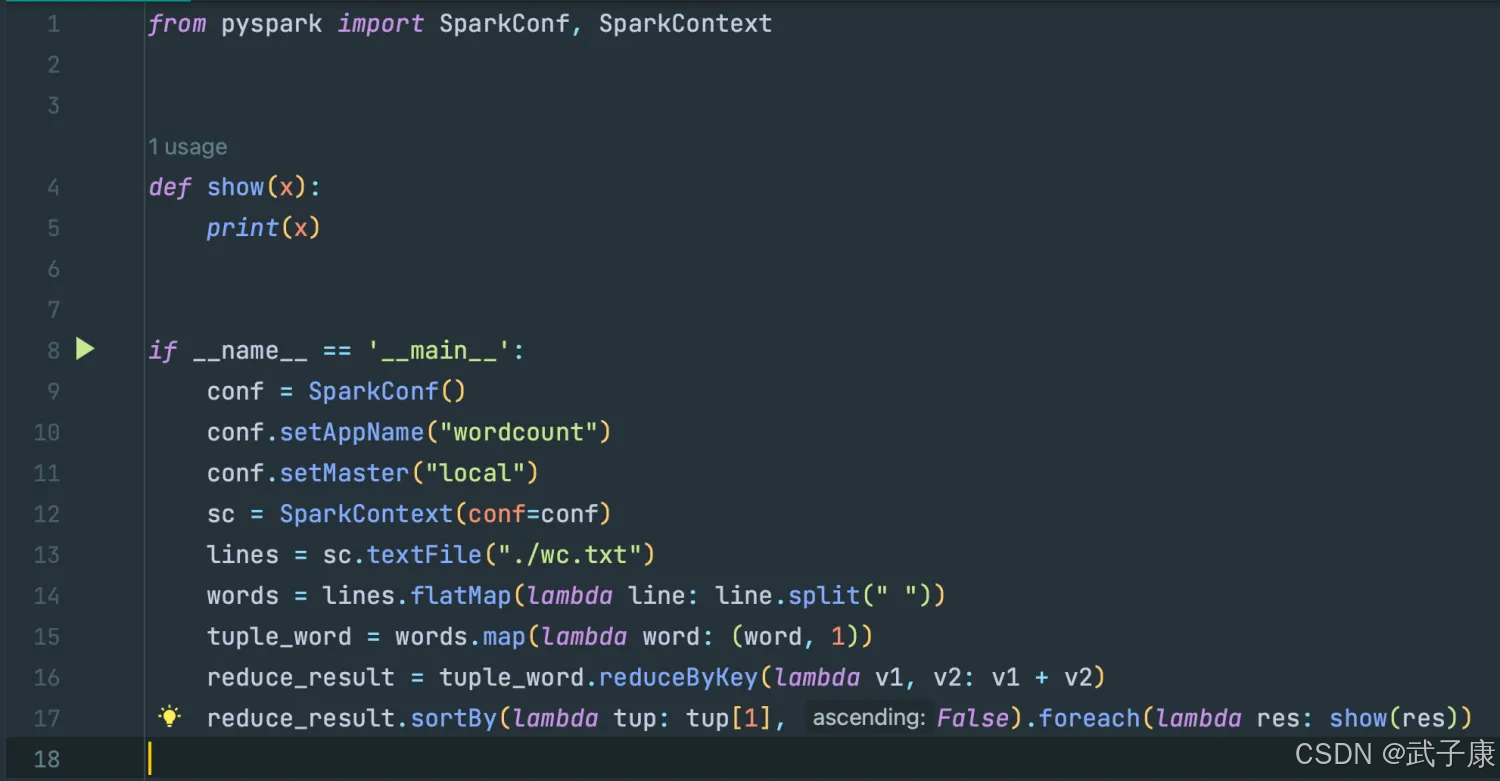
编写代码,对 pyspark 进行测试:
from pyspark import SparkConf, SparkContext
def show(x):
print(x)
if __name__ == '__main__':
conf = SparkConf()
conf.setAppName("wordcount")
conf.setMaster("local")
sc = SparkContext(conf=conf)
lines = sc.textFile("./wc.txt")
words = lines.flatMap(lambda line: line.split(" "))
tuple_word = words.map(lambda word: (word, 1))
reduce_result = tuple_word.reduceByKey(lambda v1, v2: v1 + v2)
reduce_result.sortBy(lambda tup: tup[1], False).foreach(lambda res: show(res))
对应的截图如下所示:
我们准备一些数据,我这里是从网上随便复制一段。
测试运行
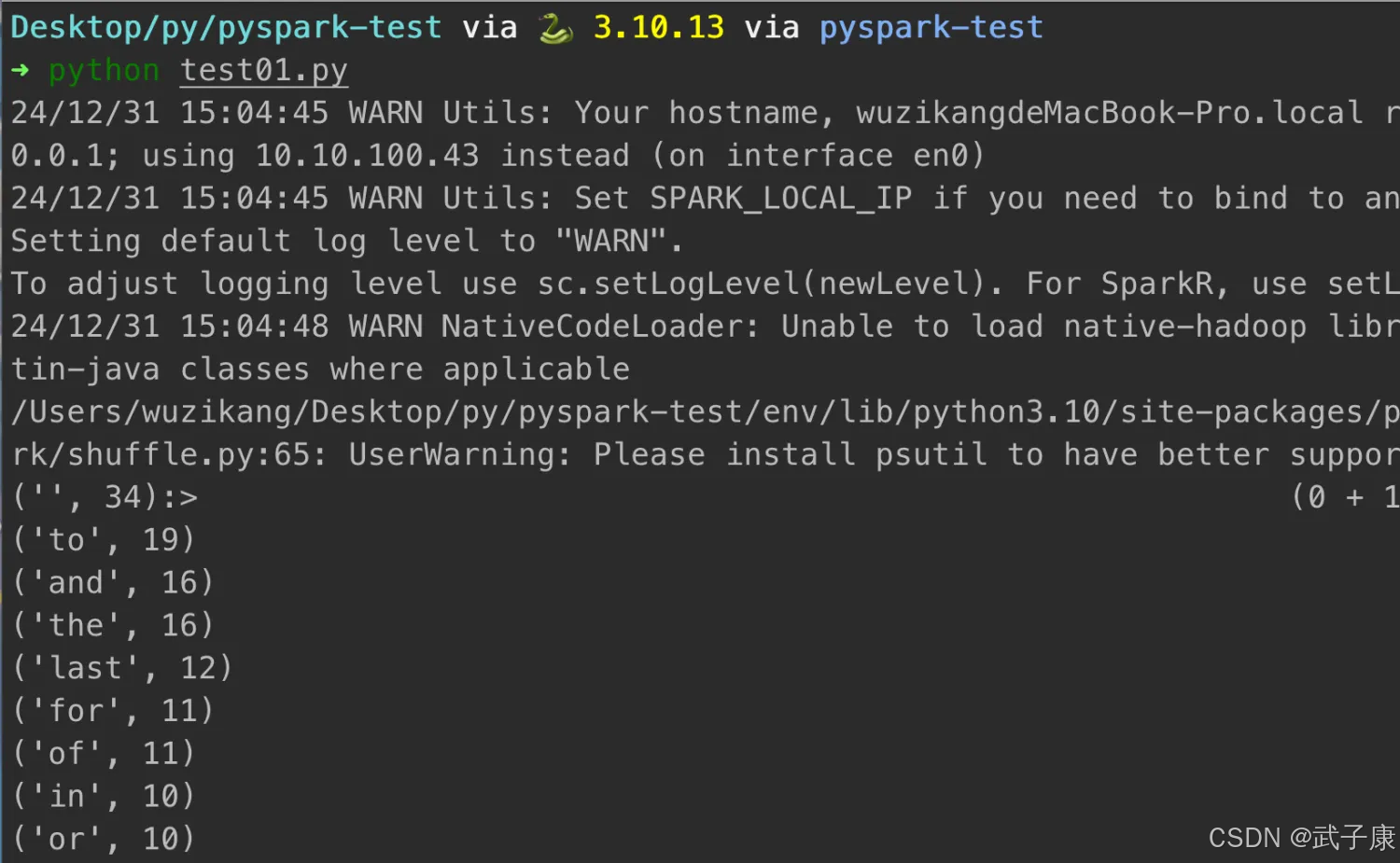
我们运行代码,运行输出如下:
('', 34):> (0 + 1) / 1]
('to', 19)
('and', 16)
('the', 16)
('l
对应的截图如下所示:
职位投递统计
职位投递行为数据格式如下所示:
uid56231 shanghai jobid53 192.168.54.90 2020-10-15
uid56231 shanghai jobid32 192.168.54.90 2020-10-15
uid56231 shanghai jobid32 192.168.54.90 2020-10-15
uid56231 shanghai jobid20 192.168.54.90 2020-10-15
uid56231 shanghai jobid73 192.168.54.90 2020-10-15
uid56231 shanghai jobid34 192.168.54.90 2020-10-15
uid56231 shanghai jobid73 192.168.54.90 2020-10-15
uid09796 beijing jobid74 192.168.74.167 2020-10-15
uid09796 beijing jobid74 192.168.74.167 2020-10-15
uid09796 beijing jobid52 192.168.74.167 2020-10-15
uid09796 beijing jobid33 192.168.74.167 2020-10-15
uid09796 beijing jobid11 192.168.74.167 2020-10-15
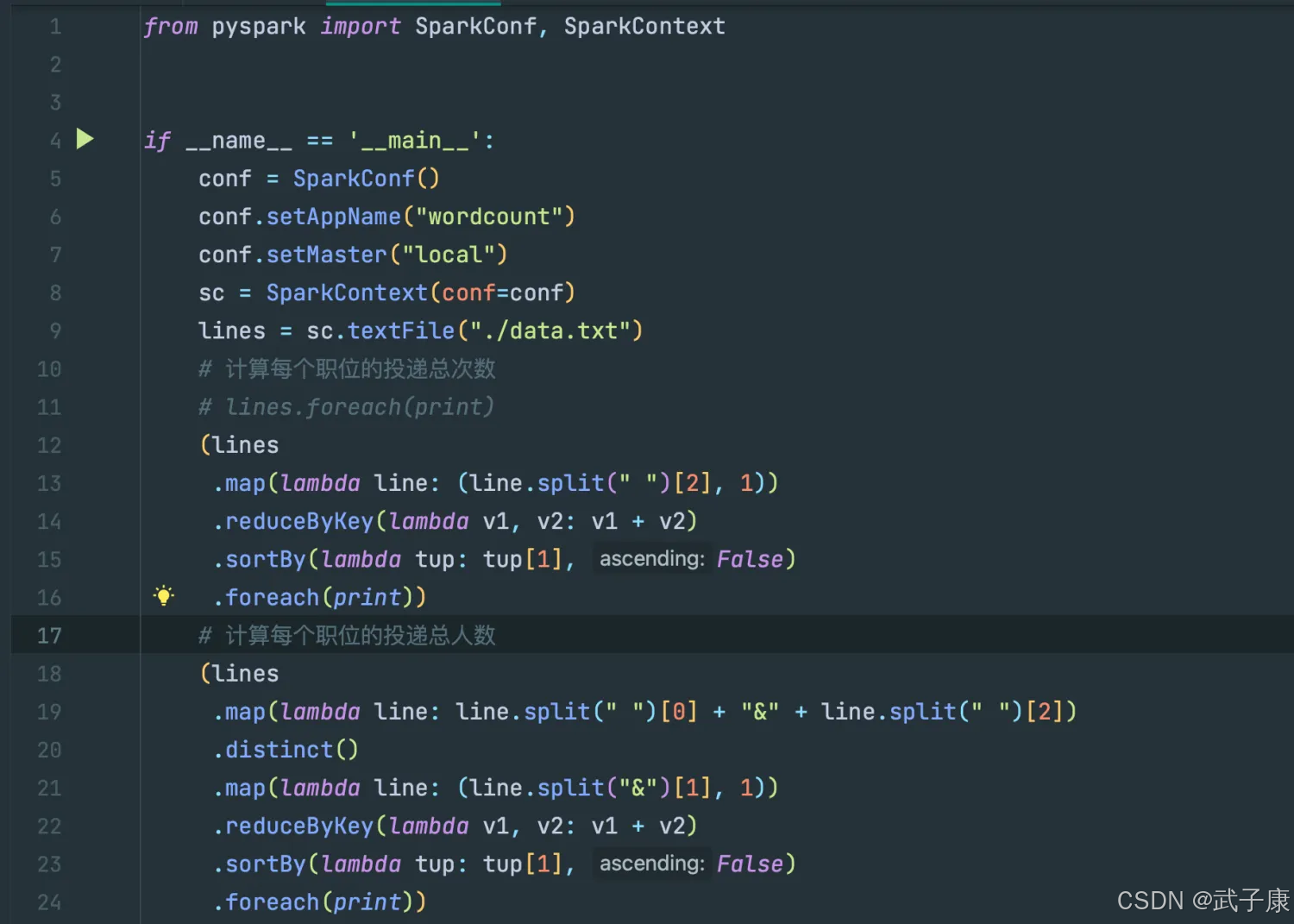
测试1: 每个职位投递总次数、投递总人数
编写代码
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf()
conf.setAppName("wordcount")
conf.setMaster("local")
sc = SparkContext(conf=conf)
lines = sc.textFile("./data.txt")
# 计算每个职位的投递总次数
# lines.foreach(print)
(lines
.map(lambda line: (line.split(" ")[2], 1))
.reduceByKey(lambda v1, v2: v1 + v2)
.sortBy(lambda tup: tup[1], False)
.foreach(print))
# 计算每个职位的投递总人数
(lines
.map(lambda line: line.split(" ")[0] + "&" + line.split(" ")[2])
.distinct()
.map(lambda line: (line.split("&")[1], 1))
.reduceByKey(lambda v1, v2: v1 + v2)
.sortBy(lambda tup: tup[1], False)
.foreach(print))
对应的截图如下所示:
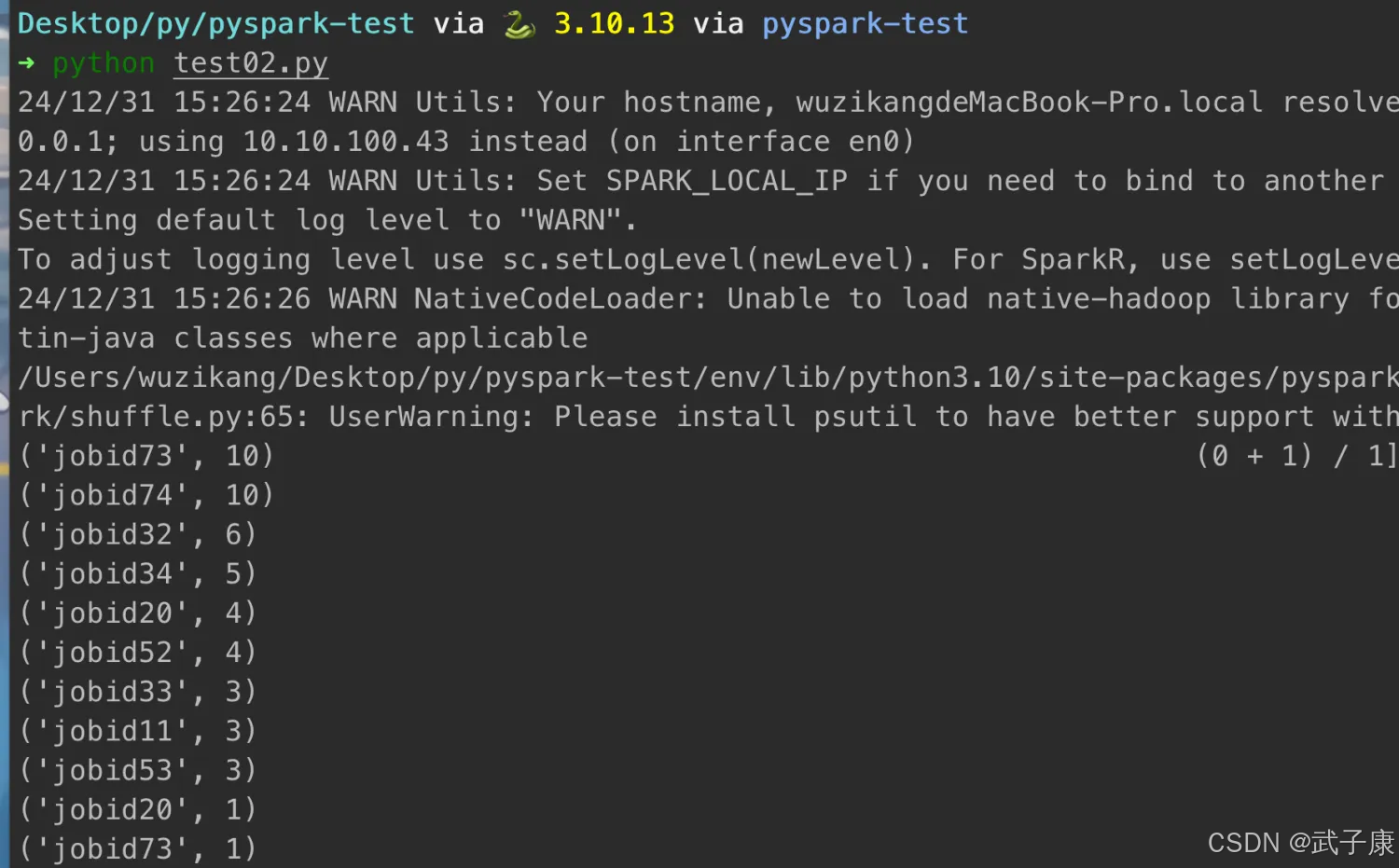
测试运行
运行之后,输出的结果如下所示:
('jobid73', 10) (0 + 1) / 1]
('jobid74', 10)
('jobid32', 6)
('jobid34', 5)
('jobid20', 4)
('jobid52', 4)
('jobid33', 3)
('jobid11', 3)
('jobid53', 3)
('jobid20', 1)
对应的截图如下所示:
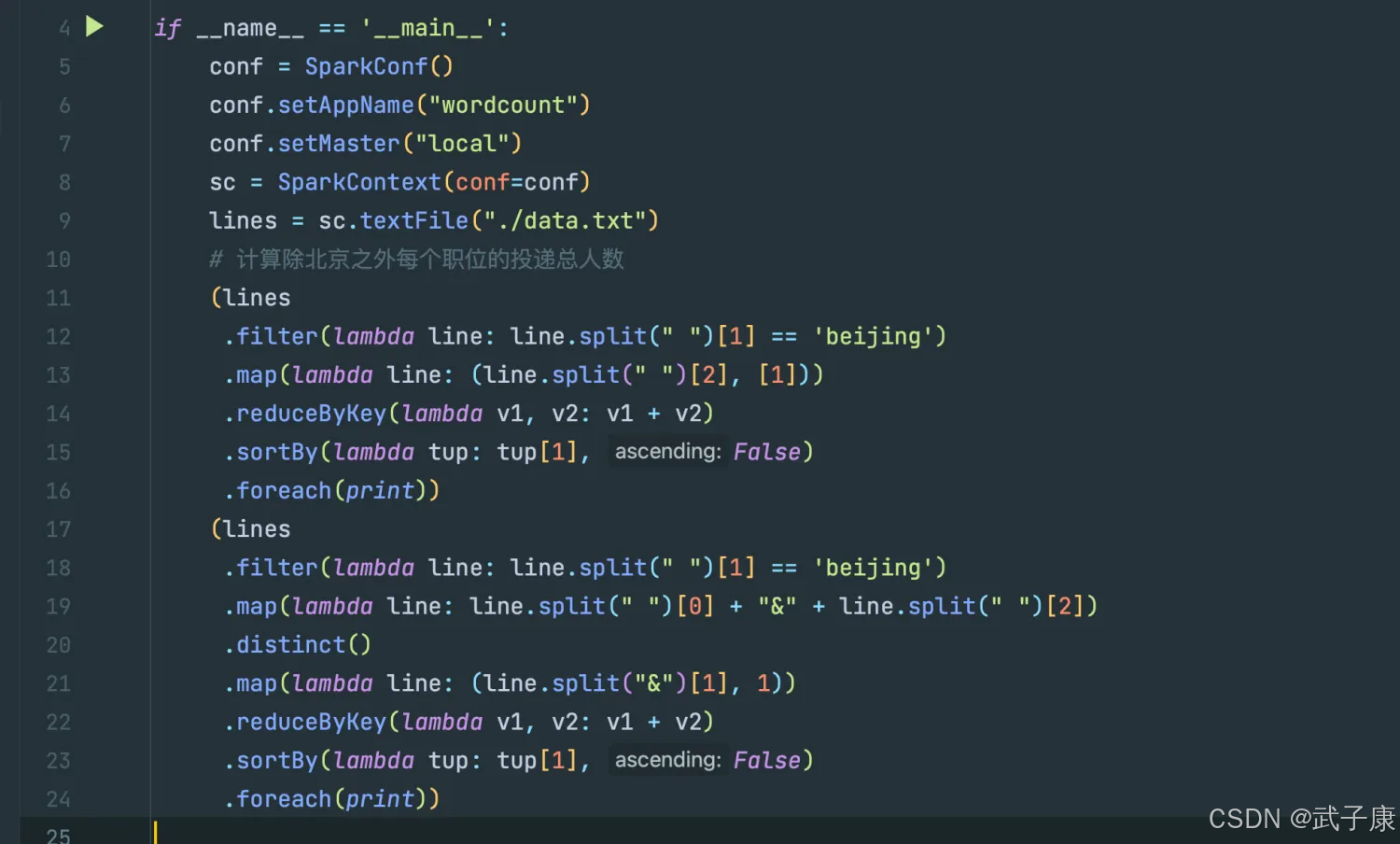
测试2: 统计指定地区的投递的总人数、总次数
编写测试
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf()
conf.setAppName("wordcount")
conf.setMaster("local")
sc = SparkContext(conf=conf)
lines = sc.textFile("./data.txt")
# 计算除北京之外每个职位的投递总人数
(lines
.filter(lambda line: line.split(" ")[1] == 'beijing')
.map(lambda line: (line.split(" ")[2], [1]))
.reduceByKey(lambda v1, v2: v1 + v2)
.sortBy(lambda tup: tup[1], False)
.foreach(print))
(lines
.filter(lambda line: line.split(" ")[1] == 'beijing')
.map(lambda line: line.split(" ")[0] + "&" + line.split(" ")[2])
.distinct()
.map(lambda line: (line.split("&")[1], 1))
.reduceByKey(lambda v1, v2: v1 + v2)
.sortBy(lambda tup: tup[1], False)
.foreach(print))
对应的截图如下所示:
测试运行
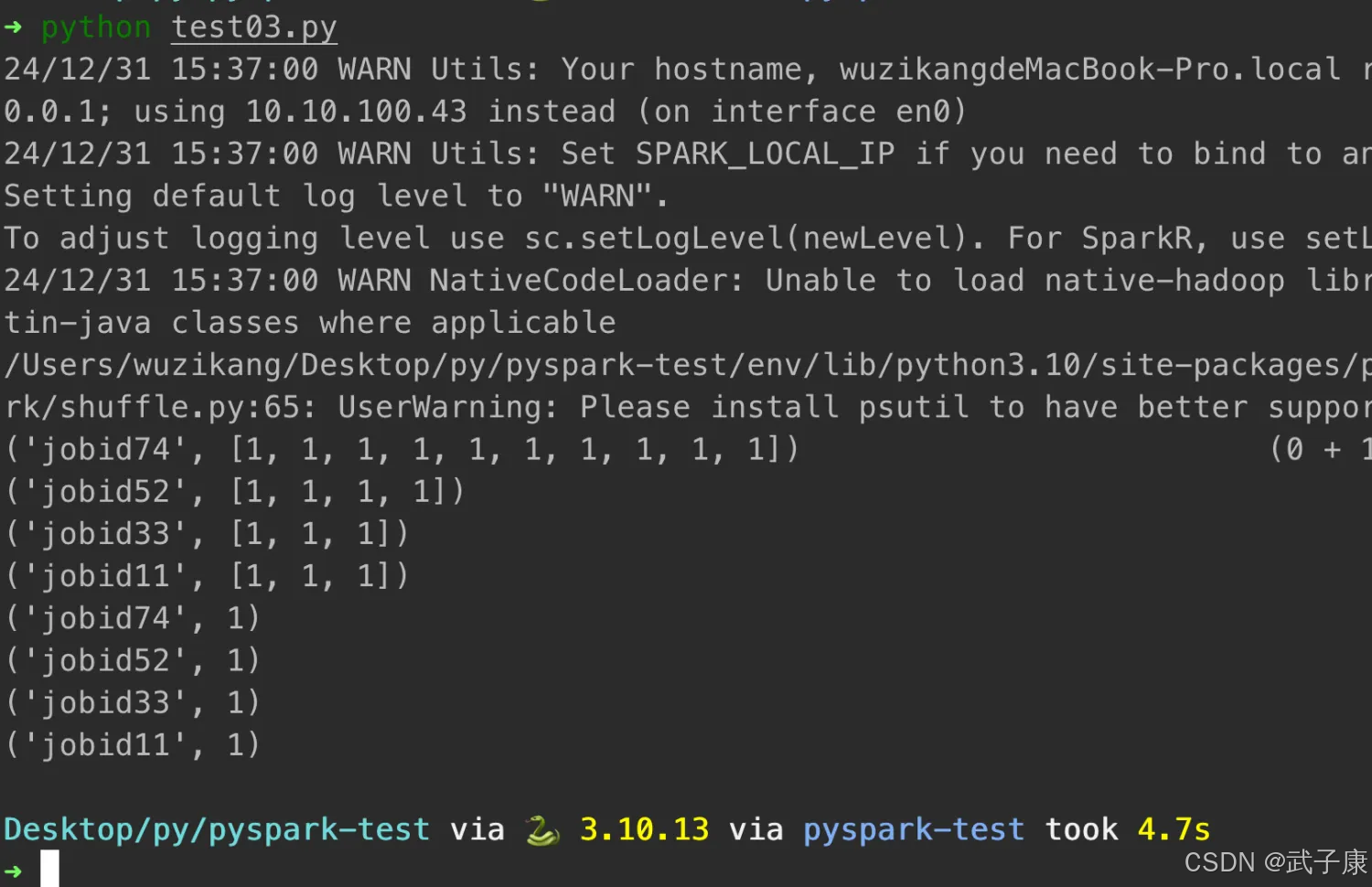
('jobid74', [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) (0 + 1) / 1]
('jobid52', [1, 1, 1, 1])
('jobid33', [1, 1, 1])
('jobid11', [1
对应的截图如下所示:
测试3: 统计每个地区投递次数最多职位TopN
编写代码
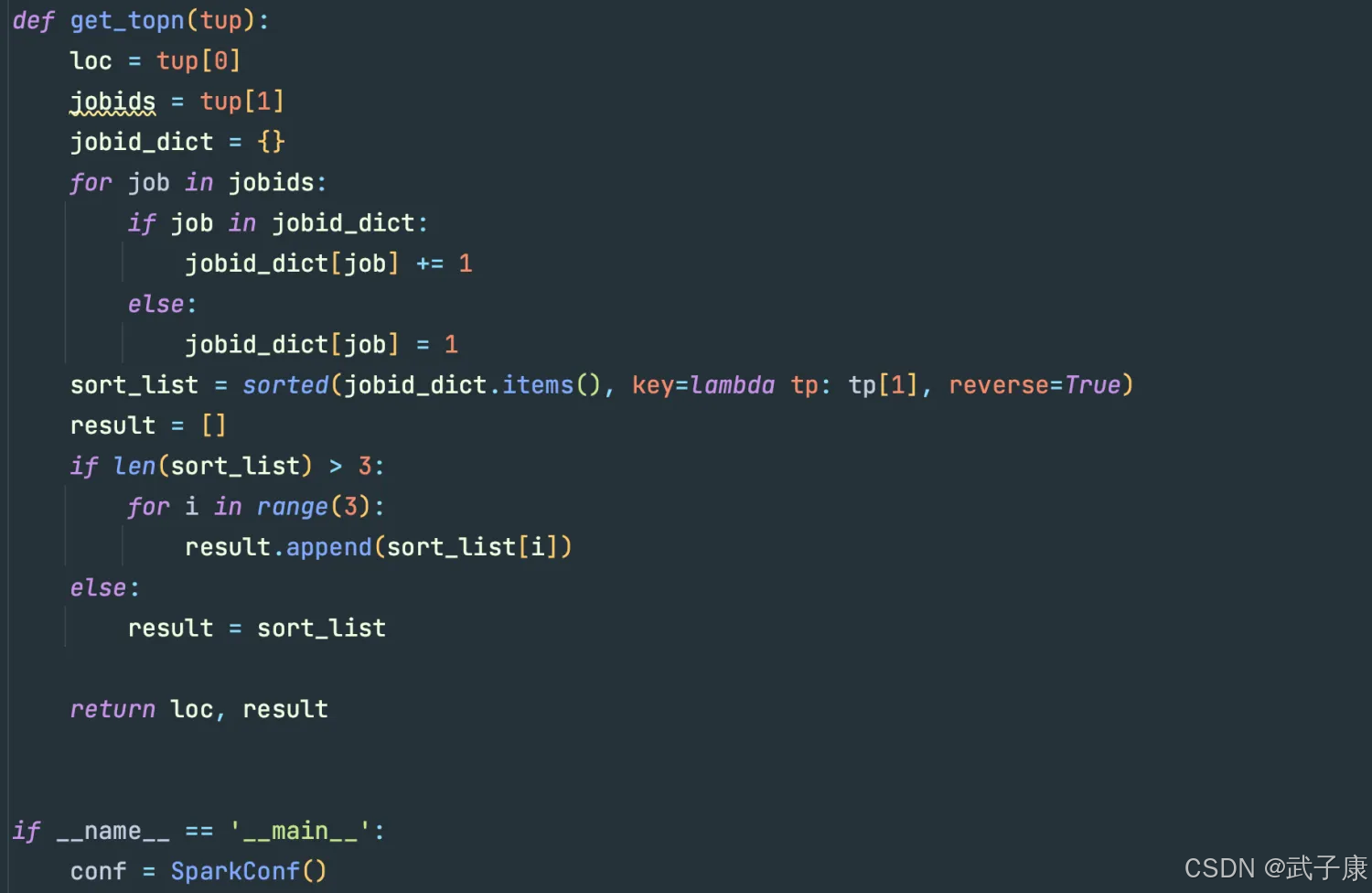
from pyspark import SparkConf, SparkContext
def get_topn(tup):
loc = tup[0]
jobids = tup[1]
jobid_dict = {
}
for job in jobids:
if job in jobid_dict:
jobid_dict[job] += 1
else:
jobid_dict[job] = 1
sort_list = sorted(jobid_dict.items(), key=lambda tp: tp[1], reverse=True)
result = []
if len(sort_list) > 3:
for i in range(3):
result.append(sort_list[i])
else:
result = sort_list
return loc, result
if __name__ == '__main__':
conf = SparkConf()
conf.setAppName("wordcount")
conf.setMaster("local")
sc = SparkContext(conf=conf)
lines = sc.textFile("./data.txt")
(lines
.map(lambda line: (line.split(" ")[1], line.split(" ")[2]))
.groupByKey()
.map(lambda tup: get_topn(tup)).foreach(print))
对应的截图如下所示:
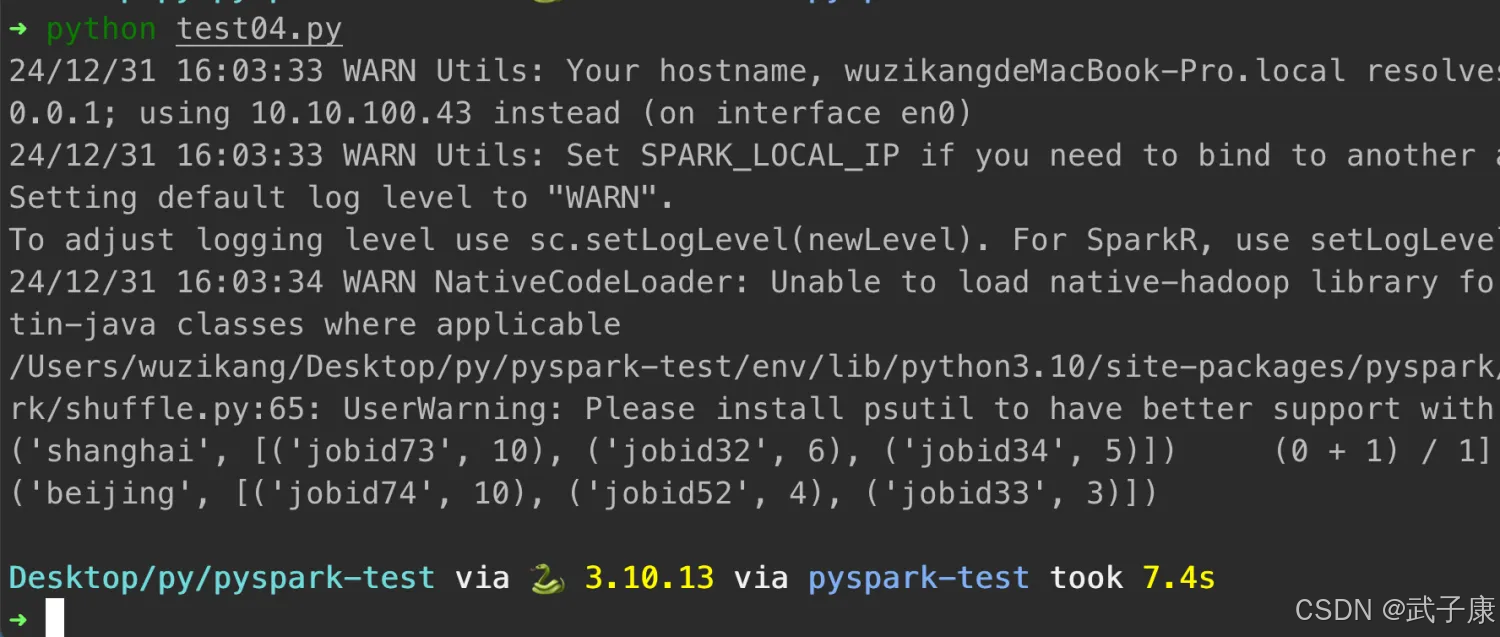
测试运行
('shanghai', [('jobid73', 10), ('jobid32', 6), ('jobid34', 5)]) (0 + 1) / 1]
('beijing', [('jobid74', 10), ('jobid52', 4), ('jobid33', 3)])
对应的截图如下所示: