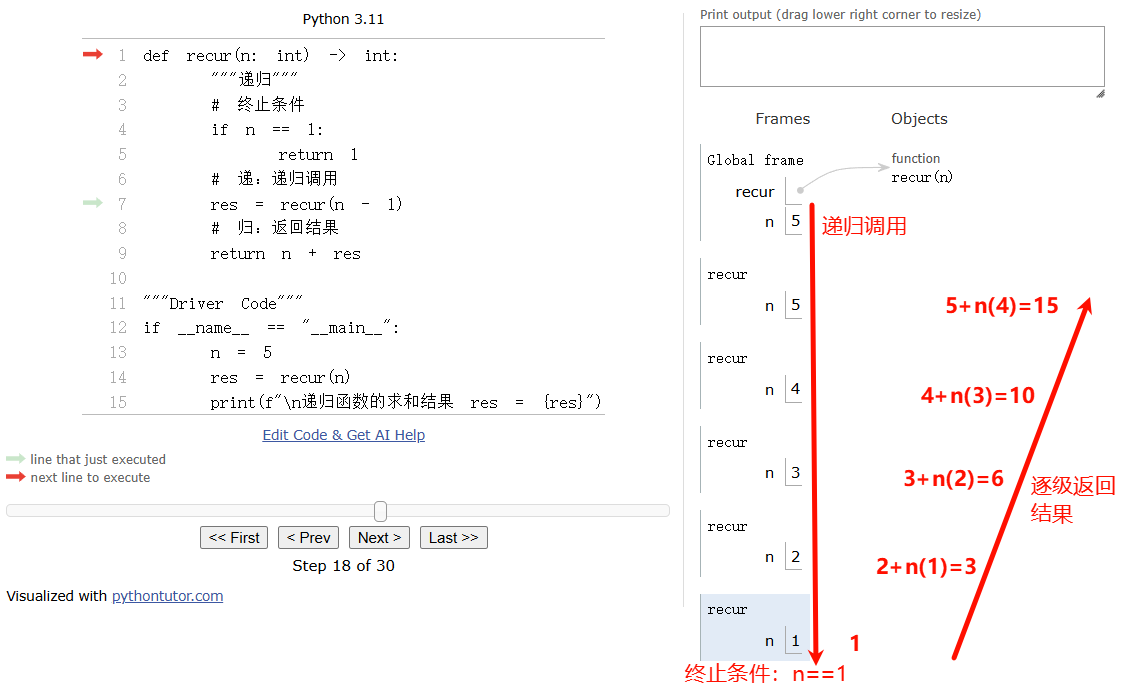
递归的本质

一个求和理解过程
/* 递归 */
int recur(int n) {
// 终止条件
if (n == 1)
return 1;
// 递:递归调用
int res = recur(n - 1);
// 归:返回结果
return n + res;
}
为什么要用递归?
查找文件

递归代码(简洁优雅):
/**
* 递归方式实现文件搜索
* 优势:代码简洁,直接反映树形结构的遍历逻辑
* @param dir 当前要搜索的目录对象
*/
void search(File dir) {
// 获取当前目录下的所有文件和子目录
for (File f : dir.listFiles()) {
// 如果是文件,则进行检查处理
if (f.isFile()) {
checkFile(f); // 对文件进行自定义检查(如文件名匹配等)
}
// 如果是目录,则递归调用自身进行搜索
else if (f.isDirectory()) {
search(f); // 递归调用,自动处理任意深度的目录层级
}
}
}
循环代码(维护复杂):
/**
* 迭代方式处理当前目录对象(与递归参数语义完全一致)
* @param currentDir 当前要处理的目录对象
*/
void iterativeSearch(File currentDir) {
// 参数校验
if (currentDir == null || !currentDir.isDirectory()) {
return; // 与递归版本行为一致,非法输入直接返回
}
// 使用双端队列作为栈(实现深度优先搜索)
Deque<File> dirStack = new ArrayDeque<>();
dirStack.push(currentDir); // 初始放入当前目录
while (!dirStack.isEmpty()) {
File dir = dirStack.pop();
File[] children = dir.listFiles();
if (children == null) continue; // 处理无权限情况
for (File f : children) {
if (f.isFile()) {
checkFile(f); // 文件处理
} else if (f.isDirectory()) {
dirStack.push(f); // 子目录入栈(后续处理)
}
}
}
}
扩展
调用栈
递归每次调用本身,都会在系统内存新建开一个空间存储。可能会导致:
- 比普通循环更耗费内存空间
- 递归调用函数会产生额外开销,时间效率一般也会更低
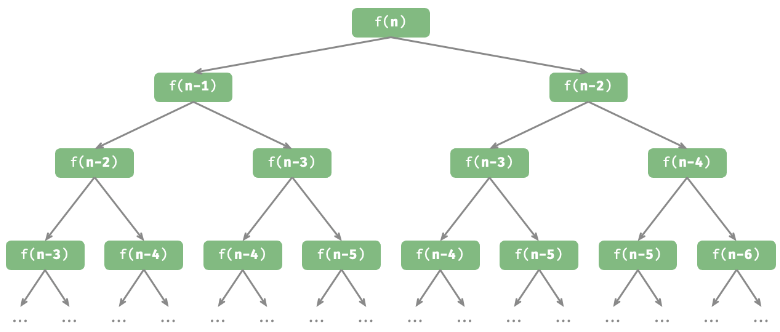
递归树
一个调用产生了两个调用分支。这样不断递归调用下去, 最终将产生一棵层数为 n 的递归树(recursion tree)。
当处理与“分治”相关的算法问题时,递归往往比迭代的思路更加直观、代码更加易读。以“斐波那契数列”为例。代码如下:
/* 斐波那契数列:递归 */
int fib(int n) {
// 终止条件 f(1) = 0, f(2) = 1
if (n == 1 || n == 2)
return n - 1;
// 递归调用 f(n) = f(n-1) + f(n-2)
int res = fib(n - 1) + fib(n - 2);
// 返回结果 f(n)
return res;
}
递归树如下: