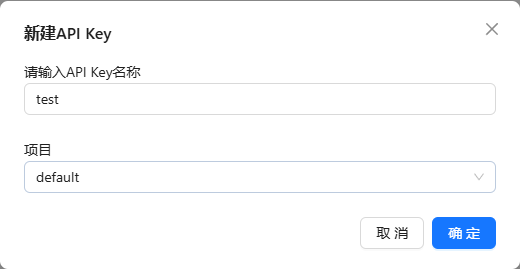
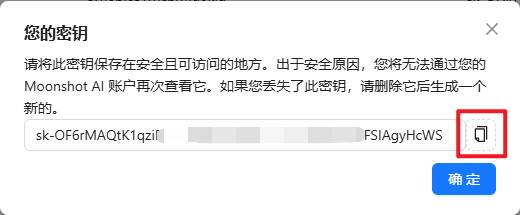
key
学习大模型第一步是申请key,一定要
记住(因为它只出现一次)!!!
概念
Token
可以被理解为文本处理的基本单位,根据具体的应用场景,这个基本单位可以是单词、子词或者字符等。
Prompt
模型在生成文本或响应之前所接收的初始输入或指令。请编写清晰的说明,模型越少猜测你的需求,你越有可能得到满意的结果。
快速上手
现在的大模型基本都兼容了 OpenAI 的接口规范,可以使用 OpenAI 提供的 Python 或 NodeJS SDK 来调用和使用,这意味着如果你的应用和服务基于 openai 的模型进行开发,那么只需要将 base_url 和 api_key 替换成对应的配置,即可无缝迁移使用其他的大模型
from openai import OpenAI # 导入OpenAI官方库中的OpenAI类
client = OpenAI(
api_key="MOONSHOT_API_KEY", # <--在这里将 MOONSHOT_API_KEY 替换为你从 Kimi 开放平台申请的 API Key
base_url="https://api.moonshot.cn/v1", # <-- 将 base_url 从 https://api.openai.com/v1 替换为https://api.moonshot.cn/v1
)
completion = client.chat.completions.create(
model = "moonshot-v1-8k", # 使用Moonshot的8k上下文模型
messages = [
{
"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。"}, # 系统角色消息,用于初始化AI行为准则
{
"role": "user", "content": "你好,我叫李雷,1+1等于多少?"}
],
temperature = 0.3, # 控制输出随机性(0-2,值越低越确定)
)
# 通过 API 我们获得了 Kimi 大模型给予我们的回复消息(role=assistant)
print(completion.choices[0].message.content)
# 输出:你好,李雷!1+1等于2。
接口规范
role
指定每条消息的来源,角色决定了在冲突情况下指令的权威性。
- *system: 由OpenAI添加的消息
- developer: 来自应用程序开发者(可能也包括OpenAI)
- *user: 终端用户输入
- assistant: 从语言模型中采样生成的内容
- tool: 由某些程序生成,例如代码执行或API调用
流式输出
每当大模型生成了一定数量的 Tokens 时(通常情况下,这个数量是 1 Token),立刻将这些 Tokens 传输给客户端,而不再是等待所有 Tokens 生成完毕后再传输给客户端。
from openai import OpenAI
client = OpenAI(
api_key = "MOONSHOT_API_KEY", # 在这里将 MOONSHOT_API_KEY 替换为你从 Kimi 开放平台申请的 API Key
base_url = "https://api.moonshot.cn/v1",
)
stream = client.chat.completions.create(
model = "moonshot-v1-8k",
messages = [
{
"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。"},
{
"role": "user", "content": "你好,我叫李雷,1+1等于多少?"}
],
temperature = 0.3,
stream=True, # <-- 注意这里,我们通过设置 stream=True 开启流式输出模式
)
# 当启用流式输出模式(stream=True),SDK 返回的内容也发生了变化,我们不再直接访问返回值中的 choice
# 而是通过 for 循环逐个访问返回值中每个单独的块(chunk)
for chunk in stream:
# 在这里,每个 chunk 的结构都与之前的 completion 相似,但 message 字段被替换成了 delta 字段
delta = chunk.choices[0].delta # <-- message 字段被替换成了 delta 字段
if delta.content:
# 我们在打印内容时,由于是流式输出,为了保证句子的连贯性,我们不人为地添加
# 换行符,因此通过设置 end="" 来取消 print 自带的换行符。
print(delta.content, end="")
/v1/chat/completions
/v1/files
/v1/files/{file_id}
/v1/files/{file_id}/content