目录
文章目录
AI 分布式训练
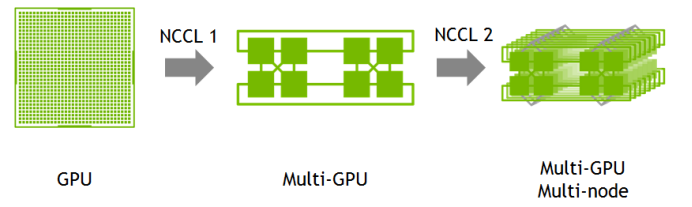
在一个最初的 AI 模型训练场景中,由于模型自身的程序体积、输入的参数量以及样本的数据量都比较有限,一张 GPU 的显存足以放下和处理这些数据,那么一张 GPU 既可以完成训练。但对于现如今的 AI 大模型而言,模型自身的体量就已经需要拆分放置到上万张 GPU 卡中,那么多张 GPU 甚至是多台 GPU 服务器进行分布式训练就是必然的选择。
NCCL 的诞生
20 世纪 90 年代,随着超级计算机和分布式计算需求的爆发,传统单机计算已无法满足大规模科学模拟、数据处理等需求。开发者亟需一种标准化的通信接口,以实现跨节点间的进程通信与协同。
最初,超算解决方案厂商们(如 IBM、Cray)提供了各自私有的通信库,但私有协议存在代码兼容性差、移植成本高等问题。1994 年,MPI(Message Passing Interface)的提出旨在统一消息传递标准,解决跨平台通信的碎片化问题。自诞生时 MPI 就是面向 CPU 设计的,是以 CPU 为中心的计算架构中最常用的集合通信库之一。
OpenMPI 开源实现就是在这一时期发展起来,支基于消息传递模型(Message Passing Model),持多线程与跨平台部署,支持点对点(Point-to-Point)和集合通信(Collective Communication)。
- 点对点通信:支持阻塞式点对点和非阻塞式点对点等。
- 集合通信:支持 all-reduce、all-to-all、all-gather 等。
2009 年,OpenMPI 已经完全成熟,但 MPI 在设计之初就基本没有考虑过 GPU 体系结构,缺乏对 GPU 并行计算中关键的时延(Latency)和带宽(Bandwidth)等问题的考量和设计。
因此,2015 年,NVIDIA 基于 MPI 的实现参考之上开发了专用于 NVIDIA GPU 的 NCCL(NVIDIA Collective Communication Library)集合通讯库,用于控制 multi-GPU 和 multi-Node 之间进行高效通信。NCCL 充分地利用了 NVIDIA GPU 的特性,应用于分布式 AI 训练场景。
值得注意的是,MPI 和 NCCL 并发替代关系,而是协同关系,即:CPU 通信由 MPI 完成,GPU 通信由 NCCL 完成。
The NVIDIA Collective Communication Library (NCCL) implements multi-GPU and multi-node communication primitives optimized for NVIDIA GPUs and Networking.
-
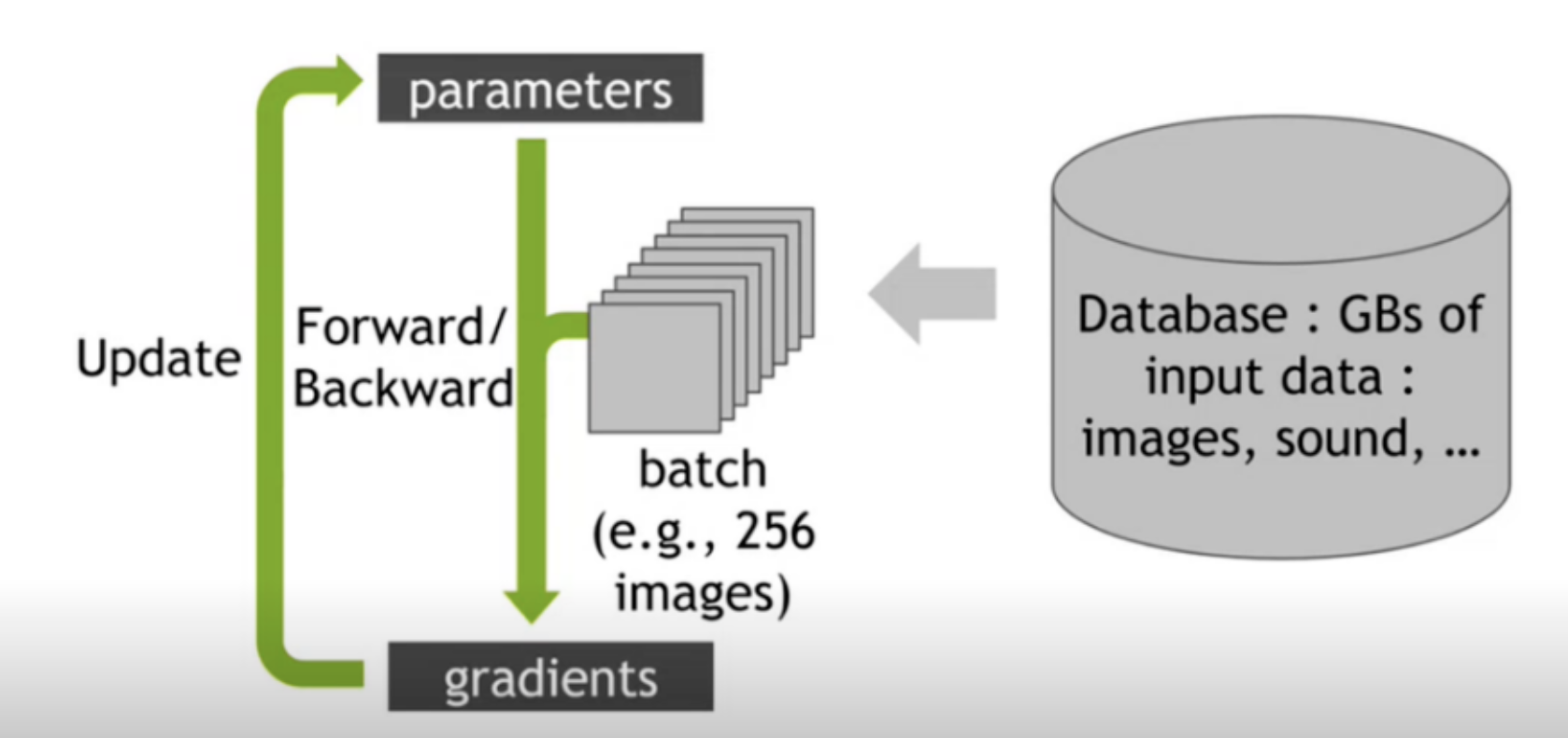
单卡 GPU 训练。
-
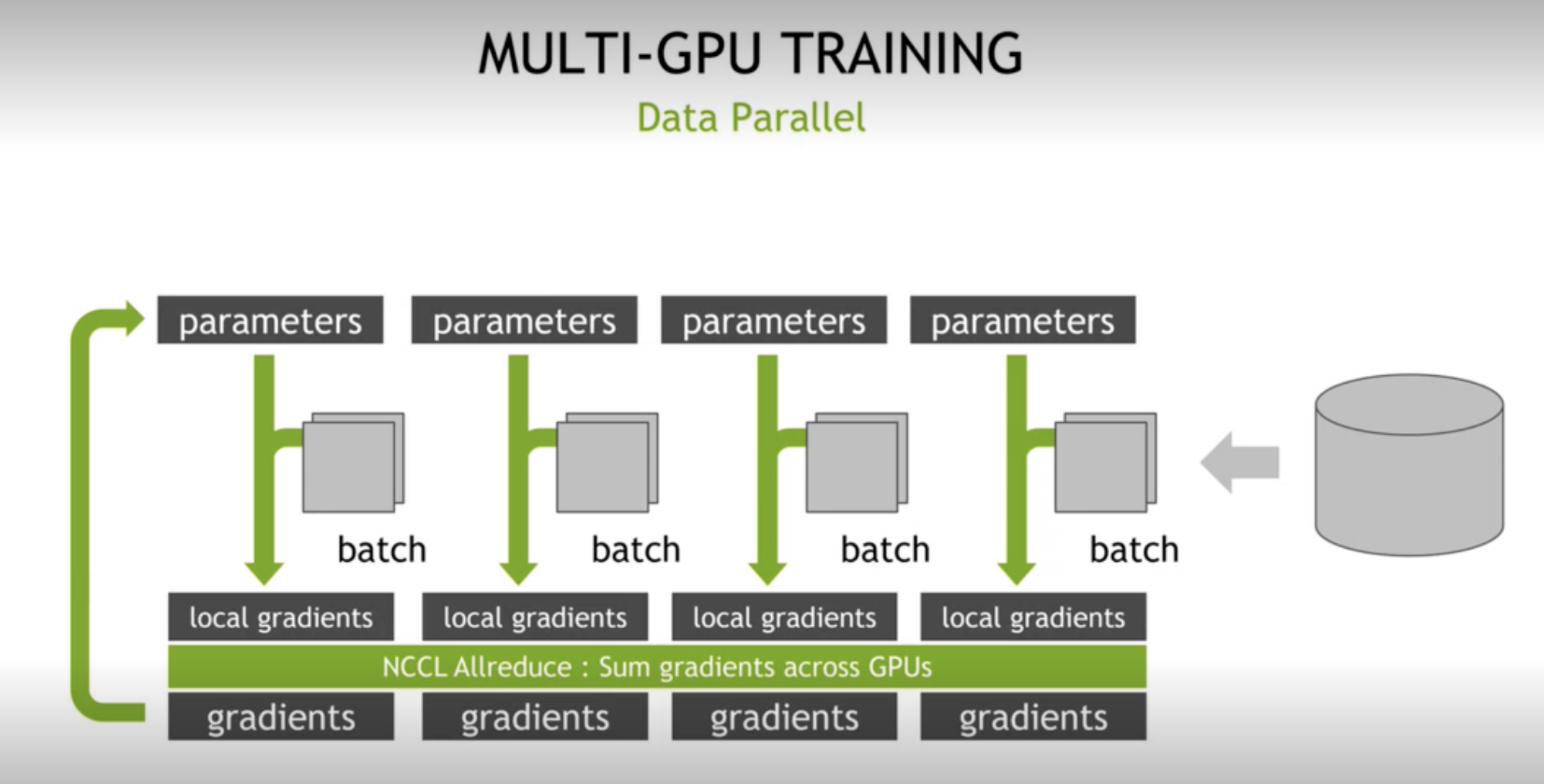
分布式 GPU 训练,DP 场景,基于 NCCL 集合通信库。
NCCL 的核心功能
如下深度学习软件堆栈图所示。NCCL 的北向是 AI 模型开发框架 PyTorch、Paddle、TensorFlow 等,这些 AI 框架通过集成、调用 NCCL lib 库来控制 GPU 之间的数据通信方式。NCCL 的南向是 CUDA 库,NCCL 通过 CUDA lib 来最终控制 GPU 设备的通信行为。

- 集合通信 Verbs API:NCCL 北向提供了多种集合通信操作 API,供上层 AI 训练框架调用。
- 点到点通信 Verbs API:NCCL 除了支持集合通信之外,也支持 Send/Receive 点到点通信方式。
- GPU/CUDA 通信控制:NCCL 南向调用 CUDA API 来控制 GPU 通信方式。CUDA 程序能够无缝地使用 NCCL 进行高效的数据传输和同步。
- RNIC/RDMA 数据传输:NCCL 南向调用 RMDA API 来完成跨节点之间的 RNIC 数据传输,即 GPU Direct RDMA 技术。
- GPU 通信自适应拓扑:包括单节点的 GPU、NVLink、NVSwitch、PCIe Switch、CPU 等设备之间的拓扑感知,以及多节点的 RNIC 拓扑感知。NCCL 能够自动检测并适应不同的硬件拓扑,无论是单节点多 GPU 还是跨节点的多 GPU 环境,支持多种 GPU 通信技术,包括:GPU Shared Memory、GPU Direct P2P、NVLink 等。
- GPU 通信路径自动优化:根据拓扑结构自动地优化 GPU 间的通信路径,自动选择使用性能最高的通信环路。例如:NCCL 会优先使用单节点内的 NVLink 高速连接进行 GPU 间通信,而不是通过较慢的跨节点 RNIC 网络接口;
NCCL 的安装部署
NCCL 主要针对 Linux 进行开发和优化,并于 Linux 上的 AI 框架集成,暂不支持在 Windows 上安装和使用。另外,NCCL 支持单包安装和 NVIDIA HPC SDK 打包安装这两种方式。下载地址:https://developer.nvidia.com/nccl
需要注意:在某些环境中,NCCL 可能已经随 CUDA 或 PyTorch 等软件包一同安装,所以在手动安装之前需要确定 NCCL 是否已经被隐式安装。
- NVIDIA HPC SDK 打包安装的软件堆栈如下图所示,包含了大量 Development 和 Analysis 相关的软件程序。
- NCCL 单包安装则手动单独安装 NCCL。本文主要记录该方式。

下面介绍手动安装 NCCL 的步骤:
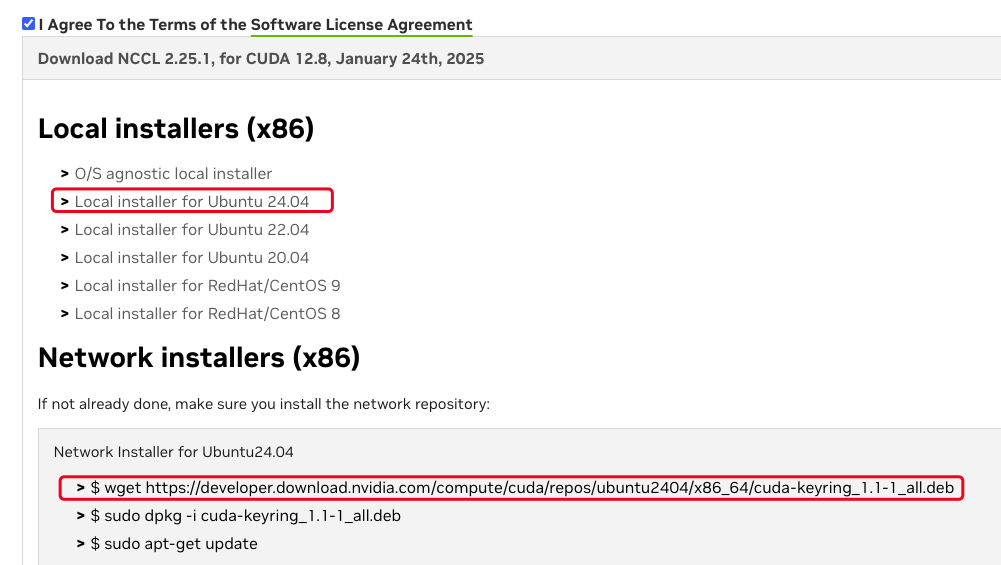
- 下载 NCCL,需要根据环境中实际的 CUDA 版本、CPU 架构、Linux 操作系统版本进行选择,支持本地离线安装包和网络安装这 2 种方式。
$ uname -a
$ cat /etc/redhat-release
$ lspci -nn | grep -i nvidia
-
下载本地离线安装包之后,直接在操作系统上使用 rpm/dpkg 安装即可。
-
如果下载的是网络远程仓库源,则继续执行 yum/apt 安装。
# For Ubuntu:
sudo apt install libnccl2=2.25.1-1+cuda12.8 libnccl-dev=2.25.1-1+cuda12.8
# For RHEL/Centos:
sudo yum install libnccl-2.25.1-1+cuda12.8 libnccl-devel-2.25.1-1+cuda12.8 libnccl-static-2.25.1-1+cuda12.8
- libnccl:NCCL 的共享库文件。
- libnccl-static:NCCL 的静态库文件。
- libnccl-devel:NCCL 的开发包,包含了头文件和其他开发工具。
- 安装 mpi:NCCL 依赖 OpenMPI 来完成 CPU 控制面的数据通信。
sudo apt-get update
sudo apt-get install openmpi-bin openmpi-doc libopenmpi-dev
mpirun --version
- 安装检验:如果输出为 True,则说明 NCCL 已成功安装并与 PyTorch 集成。
python -c "import torch; print(torch.cuda.nccl.version())"
NCCL 的基本概念
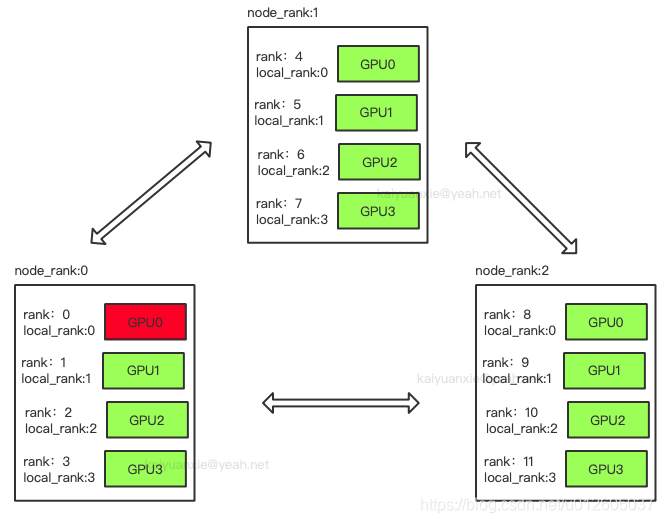
- rank:表示全局(一个 multi-node 分布式训练任务)中每个进程的全局唯一编号,通常一个 rank 进程对应一个 GPU 设备。用于进程间通讯,例如:在 all-reduce 操作时,每个 rank 都需要知道自己的数据应发送给哪些 ranks。(注:rank 和 GPU 实际上没有必然的 1: 1 关系,只是通常会对应起来。)
- rank0:作为通信中控的 rank,通常是第一个启动的进程。
- ranks:作为其他 ranks。
- node:通常表示一台物理服务器,内含 8 块 GPU 设备。
- nnodes:表示全局中 node 的数量。
- node_rank:表示全局中每个 node 的唯一编号。
- local_rank:表示一个 node 中的每个进程的相对编号,例如:8 卡 GPU 服务器中的进程 0~7。local_rank 和 node 之前没有关系。
- nproc_per_node:表示每个 node 上的 rank 进程的数量,通常是 8 个。
- nranks / WORLD_SIZE :表示全局中 rank 的总数。
- group:进程组,需要进行多组管理时才会设置,通常一个训练任务只有一个默认组。
- communicator:定义了一组可以相互通信的 ranks 进程。一个 rank 可以属于多个不同的 communicators。
NCCL 编程示例
一个官方 NCCL demo 程序如下,包含了 10 个关键步骤,详见 main() 中的注释。后面我们将通过分析 NCCL 代码来理解里面的工作细节。
- https://github.com/NVIDIA/nccl
#include <stdio.h>
#include "cuda_runtime.h"
#include "nccl.h"
#include "mpi.h"
#include <unistd.h>
#include <stdint.h>
#define MPICHECK(cmd) do {
\
int e = cmd; \
if( e != MPI_SUCCESS ) {
\
printf("Failed: MPI error %s:%d '%d'\n", \
__FILE__,__LINE__, e); \
exit(EXIT_FAILURE); \
} \
} while(0)
#define CUDACHECK(cmd) do {
\
cudaError_t e = cmd; \
if( e != cudaSuccess ) {
\
printf("Failed: Cuda error %s:%d '%s'\n", \
__FILE__,__LINE__,cudaGetErrorString(e)); \
exit(EXIT_FAILURE); \
} \
} while(0)
#define NCCLCHECK(cmd) do {
\
ncclResult_t r = cmd; \
if (r!= ncclSuccess) {
\
printf("Failed, NCCL error %s:%d '%s'\n", \
__FILE__,__LINE__,ncclGetErrorString(r)); \
exit(EXIT_FAILURE); \
} \
} while(0)
static uint64_t getHostHash(const char* string) {
// Based on DJB2a, result = result * 33 ^ char
uint64_t result = 5381;
for (int c = 0; string[c] != '\0'; c++){
result = ((result << 5) + result) ^ string[c];
}
return result;
}
static void getHostName(char* hostname, int maxlen) {
gethostname(hostname, maxlen);
for (int i=0; i< maxlen; i++) {
if (hostname[i] == '.') {
hostname[i] = '\0';
return;
}
}
}
int main(int argc, char* argv[])
{
int size = 32*1024*1024;
int myRank, nRanks, localRank = 0;
// 1. 每个 node 初试化和启动 MPI 通信。
MPICHECK(MPI_Init(&argc, &argv));
MPICHECK(MPI_Comm_rank(MPI_COMM_WORLD, &myRank)); // 获取当前 rank 进程自身的 ID 编号
MPICHECK(MPI_Comm_size(MPI_COMM_WORLD, &nRanks)); // 获取 nranks 总数
// 2. 每个 node 计算自己 hostname 的 HASH 值。
uint64_t hostHashs[nRanks]; // 初始化 hostname HASH 数组
char hostname[1024];
getHostName(hostname, 1024);
hostHashs[myRank] = getHostHash(hostname); // hostname HASH
// 3. 每个 node 调用 MPI_allgather 收集所有 nodes 的 hostname HASH。
MPICHECK(MPI_Allgather(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, hostHashs, sizeof(uint64_t), MPI_BYTE, MPI_COMM_WORLD));
// 根据获取到的 HASH 值列表,计算用于绑定 GPU 的 local_rank 的数量。
for (int p=0; p<nRanks; p++) {
if (p == myRank) break; // 如果是当前 rank 进程,则跳出循环
if (hostHashs[p] == hostHashs[myRank]) localRank++; // HASH 值相同的 rank 在同一个 node 上。
}
// 指定每个 rank 进程使用 1 个 GPU,1: 1 绑定
int nDev = 1;
// 4. 分配发送/接收缓冲区,创建 CUDA 流
float** sendbuff = (float**)malloc(nDev * sizeof(float*));
float** recvbuff = (float**)malloc(nDev * sizeof(float*));
cudaStream_t* s = (cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);
// 5. 基于 localRank 选择 GPU
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(localRank*nDev + i));
CUDACHECK(cudaMalloc(sendbuff + i, size * sizeof(float)));
CUDACHECK(cudaMalloc(recvbuff + i, size * sizeof(float)));
CUDACHECK(cudaMemset(sendbuff[i], 1, size * sizeof(float)));
CUDACHECK(cudaMemset(recvbuff[i], 0, size * sizeof(float)));
CUDACHECK(cudaStreamCreate(s+i));
}
ncclUniqueId id;
ncclComm_t comms[nDev];
// 6. 在一个 rank0 中生成 NCCL 通信组的唯一 ID 并调用 MPI_Bcast 将其广播给所有 ranks。
if (myRank == 0) ncclGetUniqueId(&id);
MPICHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD));
// 7. 初始化 NCCL 通信器
// group API is required around ncclCommInitRank as it is called across multiple GPUs in each thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i<nDev; i++) {
NCCLCHECK(ncclCommInitRank(comms+i, nRanks*nDev, id, myRank*nDev + i));
}
NCCLCHECK(ncclGroupEnd());
// 8. 调用 NCCL all-reduce 操作。
//Group API is required when using multiple devices per thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i<nDev; i++)
NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], size, ncclFloat, ncclSum, comms[i], s[i]));
NCCLCHECK(ncclGroupEnd());
// 9. 同步 CUDA 流以确保 NCCL 操作完成。
for (int i=0; i<nDev; i++)
CUDACHECK(cudaStreamSynchronize(s[i]));
// 10. 释放资源
//freeing device memory
for (int i=0; i<nDev; i++) {
CUDACHECK(cudaFree(sendbuff[i]));
CUDACHECK(cudaFree(recvbuff[i]));
}
//finalizing NCCL
for (int i=0; i<nDev; i++) {
ncclCommDestroy(comms[i]);
}
//finalizing MPI
MPICHECK(MPI_Finalize());
printf("[MPI Rank %d] Success \n", myRank);
return 0;
}
NCCL 的基本工作流程
- 拓扑发现:构建由全部 GPUs、NICs、CPUs、PICe Switches、NVLink、NVSwitch 设备组成的 Topology。
- 路径选择:通过搜索找出最优的 rings 或 trees 路径。
- GPU 建连:通过单节点内的 PCIe、NVLink,以及多节点间的 GPU Direct RDMA 将 GPUs 根据最优路径连接起来。
- 通信操作:在 GPUs 之间执行 all-reduce 等通信操作。

NCCL 的网络初始化
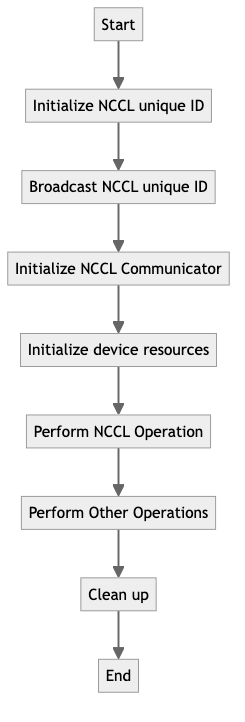
AI 程序加载 NCCL 模块首先需要完成 NCCL 运行环境的初始化,包括以下主要流程:
- Initialize NCCL unique ID:rank0 调用 ncclGetUniqueId() 生成 ncclUniqueId,用于标识一个 communicator。
- Broadcast NCCL unique ID:rank0 通过 MPI 广播把 ncclUniqueId 同步给所有 ranks,表示其加入同一个 communicator。
- Initialize NCCL Communicator:每个 ranks 调用 ncclCommInitRank() 并传入相同的 ncclUniqueId 来初始化 communicator。
- Initialize device resources:调用 ncclCudaLibraryInit() 加载 CUDA 驱动,并获取当前 GPU 设备的 ID 标识符。
初始化 Bootstrap 引导网络
NCCL 中存在作用不同的 2 个网络:
- bootstrap 引导网络:用于在不同的 ranks 之间传输控制面信息,由于数据量很小,而且只在初始化阶段执行一次,因此使用 MPI 通信方式。
- 训练数据网络:用于传输训练数据,高性能要求,因此单节点内优先使用 NVLink,多节点间优先使用 GDR(GPU Direct RDMA)。
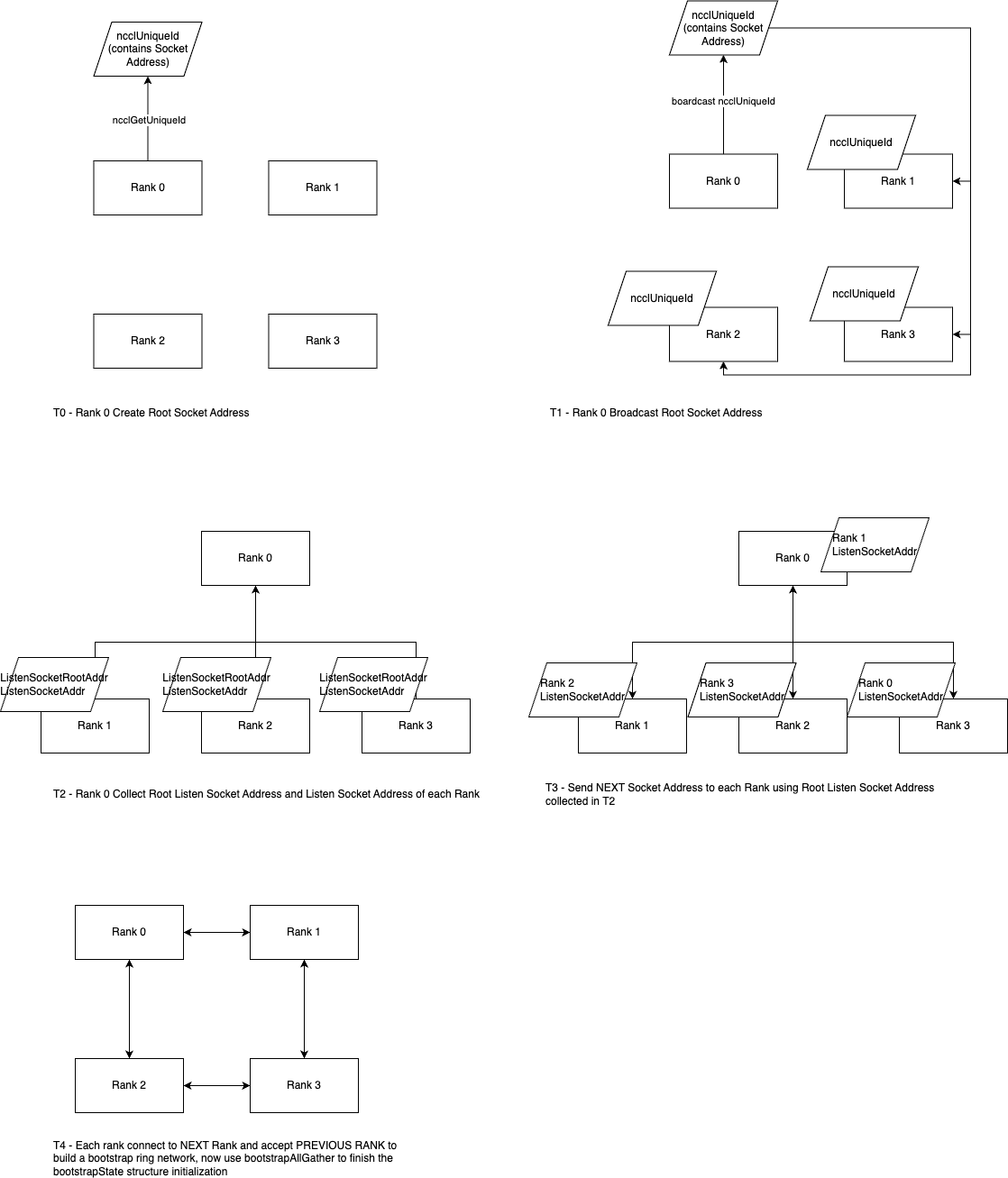
Bootstrap 引导环网的构建过程如下图所示。
- rank0 调用 ncclGetUniqueId() 生成 ncclUniqueId,里面包含了 rank0 的 root socket address。rank0 调用 bootstrapCreateRoot() 启动一个 bootstrapRoot 线程,等待其他 ranks 的连接。bootstrapNetInit() => findInterfaces() 根据匹配规则选出一个可用的 Network interface,并获取 bootstrapNetIfAddr IP 地址作为 ncclGetUniqueId 结构体的一部分。另外,可以使用 NCCL_SOCKET_IFNAME 环境变量指定 interface。
ncclResult_t ncclGetUniqueId(ncclUniqueId* out) {
NCCLCHECK(ncclInit()); // ncclInit() => initEnv() => initNet() => bootstrapNetInit() 初始化 Bootstrap 引导网络
NCCLCHECK(PtrCheck(out, "GetUniqueId", "out"));
return bootstrapGetUniqueId(out);
}
-
ran0 通过调用 MPI_Bcast() 把 ncclUniqueId 发送给其他 ranks,其他 ranks 接收到 ncclUniqueId 之后执行 ncclCommInitRank() 加入到同一个 communicator 中。同时,rank0 调用 bootstrapCreateRoot() 启动一个 bootstrapRoot 线程,等待其他 ranks 的连接。
-
**rank 执行 ncclCommInitRank() 期间还会收集自己的 socket address,此时 rank 拥有了 rank0 的 ListenSocketRootAddress,以及自己的 ListenSocketAddress。**前者用于 rank 和 rank0 通信,后者用于 rank 和 another rank 通信。rank 传参 ListenSocketRootAddress 到 ncclCommInitRank() => ncclCommInitRankSync() => initTransportsRank() => bootstrapInit() 与 rank0 的 bootstrapRoot 线程通信。把 2 个 address 收集到 rank0 中。
-
**rank0 收集到所有 ranks 的 ListenSocketAddress 之后,根据 Ring 环的链表关系(注:环形比星型同步更高效),向 rank 发送 next rank 的 ListenSocketAddress。**所有 ranks 执行 bootstrapInit() 时会实例化一个 extState 结构体,它用于存储各自的 next rank 和 previous rank 的 socket 信息。
struct extState {
void* extBstrapListenComm; // local rank 的 socket 连接
void* extBstrapRingRecvComm; // previous rank 的 socket 连接
void* extBstrapRingSendComm; // next rank 的 socket 连接
ncclNetHandle_t* peerBstrapHandles;
struct unexConn* unexpectedConnections;
int rank;
int nranks;
int dev;
};
- rank 都使用 next rank 的 ListenSocketAddress 进行 Ring 环互访链表的建立。至此,Bootstrap 引导环网就构建完成了,可以执行基于 MPI 的集合通信,包括以下:
- bootstrapAllGather / bootstrapIntraNodeAllGather
- bootstrapSend / bootstrapRecv
- bootstrapBarrier / bootstrapIntraNodeBarrier
- bootstrapBroadcast / bootstrapIntraNodeBroadcast
- 等
初始化数据网络
NCCL 的数据网络有 IB 和 RoCEv2 这两大类型,初始化阶段:
- initNet() => initNetPlugin() => ncclIbInit() 加载 libibverbs.so 动态库,确定支持 NCCL 跨节点通信。
- initNet() => ncclNetIb() => ncclIbInit() 加载 libibverbs.so 动态库,确定支持 RDMA 通信。
ncclIbInit() => ibv_get_device_list() 会遍历节点上所有的 RNIC 并将设备信息存储在全局的 ncclIbDevs 结构体中,信息包括:
- Device 和 Port 的映射关系;
- Port 使能了 IB 还是 ROCE;
- Device 的 PCIe path ;
- 等。
也支持使用 NCCL_IB_HCA 环境变量来指定要使用的 IB RNIC。
NCCL 的拓扑发现与建图
在《8 卡 GPU 服务器与 NVLink/NVSwitch 互联技术》一文中,我们介绍过单节点内的拓扑由 GPUs、NICs、CPUs、PICe Switches、NVLink、NVSwitch 等设备组成。NCCL 的拓扑发现功能就是要遍历以上这些设备并收集它们的信息,用于后续的 Topology 建图。
NCCL 的拓扑发现与建图由 XML 和 Topo 模块完成:
- XML 模块:但在拓扑发现阶段中,用于发现上述设备,并以 XML 格式描述物理拓扑和逻辑拓扑之间的关系,还提供了 XML 格式序列化/反序列化等接口。
- Topo 模块:基于 XML topo 文件来生成 Topology graph。
拓扑发现
- NCCL 定义了以下 6 种设备类型,也是 PCI tree 上的节点类型。
#define NCCL_TOPO_NODE_TYPES 7
#define GPU 0
#define PCI 1
#define NVS 2
#define CPU 3 // Actually NUMA domains
#define NIC 4
#define NET 5
-
调用 ncclTopoGetSystem() 来遍历 rank 的 PCI tree。

-
将每个 PCI 节点的信息被记录到 ncclXmlNode 结构体,包括:父节点和所有子节点的 name 和 attr,例如:一个 GPU 节点的 busId 和 sysfs path。busId 是 GPU 设备的唯一标识,而 path 是 PCI tree 中从 Root 到 Leaf 的完整路径。例如:/sys/devices/pci0000:10/0000:10:00.0/0000:11:00.0,其中最后的 0000:11:00.0 就是 GPU 的 busId。
XML 的示例如下:
<system version="1">
<cpu numaid="0" affinity="00000000,0000000f,ffff0000,00000000,000fffff" arch="x86_64" vendor="GenuineIntel" familyid="6" modelid="85">
<pci busid="0000:11:00.0" class="0x060400" link_speed="8 GT/s" link_width="16">
<pci busid="0000:13:00.0" class="0x060400" link_speed="8 GT/s" link_width="16">
<pci busid="0000:15:00.0" class="0x060400" link_speed="8 GT/s" link_width="16">
<pci busid="0000:17:00.0" class="0x030200" link_speed="16 GT/s" link_width="16">
<gpu dev="0" sm="80" rank="0" gdr="1">
<nvlink target="0000:e7:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e4:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e6:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e9:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e5:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e8:00.0" count="2" tclass="0x068000"/>
</gpu>
</pci>
</pci>
</pci>
<pci busid="0000:1c:00.0" class="0x020000" link_speed="8 GT/s" link_width="16">
<nic>
<net name="mlx5_0" dev="0" speed="100000" port="1" guid="0x82d0c0003f6ceb8" maxconn="262144" gdr="1"/>
</nic>
</pci>
</pci>
</cpu>
</system>
+-----------------------+
| CPU (numa=0) |
| Affinity: 00000000... |
+-----------------------+
|
v PCIe [0000:11:00.0] (Root Port)
|
+------+------------------+
| PCIe Switch [0000:11:00.0] |
+------+------------------+
| |
| +-------------------+
| |
v PCIe [0000:13:00.0] v PCIe [0000:1c:00.0] (NIC)
| |
v PCIe [0000:15:00.0] +---+-------------------+
| | NIC (mlx5_0) |
v PCIe [0000:17:00.0] | Speed: 100 Gbps |
| | Port: 1, GDR=1 |
+----------+---------+ +-----------------------+
| GPU0 (bus=0000:17:00.0) |
| Rank=0, SM=80, GDR=1 |
+-------------------------+
|
| NVLink (6 links, count=2 each)
+--> [0000:e4:00.0] (GPU1)
+--> [0000:e5:00.0] (GPU2)
+--> [0000:e6:00.0] (GPU3)
+--> [0000:e7:00.0] (GPU4)
+--> [0000:e8:00.0] (GPU5)
+--> [0000:e9:00.0] (GPU6)
拓扑建图
XML 模块采用 XML 格式来来描述整个 PCI tree 的拓扑,然后调用 Topo 模块 ncclTopoGetSystemFromXml() 将 ncclXmlNode 转换成 ncclTopoNode,并最终构建 ncclTopoSystem 结构体。
- 首先调用 ncclTopoAddCpu() 对每个 NUMA 节点进行递归发现 GPU 和 NIC 设备。虽然此时所有节点构造完毕,但是节点之间的连接信息还不全面;
- 然后再调用 ncclTopoAddNvLinks()、ncclTopoAddC2c()、ncclTopoConnectCpus() 来追加链接/连接信息。
Bootstrap 网络建立之后,会调用 bootstrapAllGather 接口将所有 ranks 的 Topo 信息进行同步。
更直观的,我们也可以执行指令查看当前节点上的拓扑信息,主要包括了 GPU 和 NIC 设备,以及它们之间的连接关系与方式。
$ nvidia-smi topo -m

NCCL 的路径选择和 Channel 搜索
NCCL 支持 Ring、Tree、CollNet 这三种通信算法类型,并且能够智能地利用 Topo 结构进行路径选择和 Channel 搜索,以实现在多 GPU 环境中选择最佳的通信策略。
首先需要注意,路径选择和 Channel 搜索的目标有所区别:
- 路径选择:是物理链路层面的优化,关注单一路径的最优性;
- Channel 搜索:是虚拟通道系统层面优化,通过多 Channel 并发提升整体性能。
两者通常结合使用:先通过路径选择确定物理最优路径,再通过 Channel 搜索组织多通道并行通信。
GPU 带宽性能问题
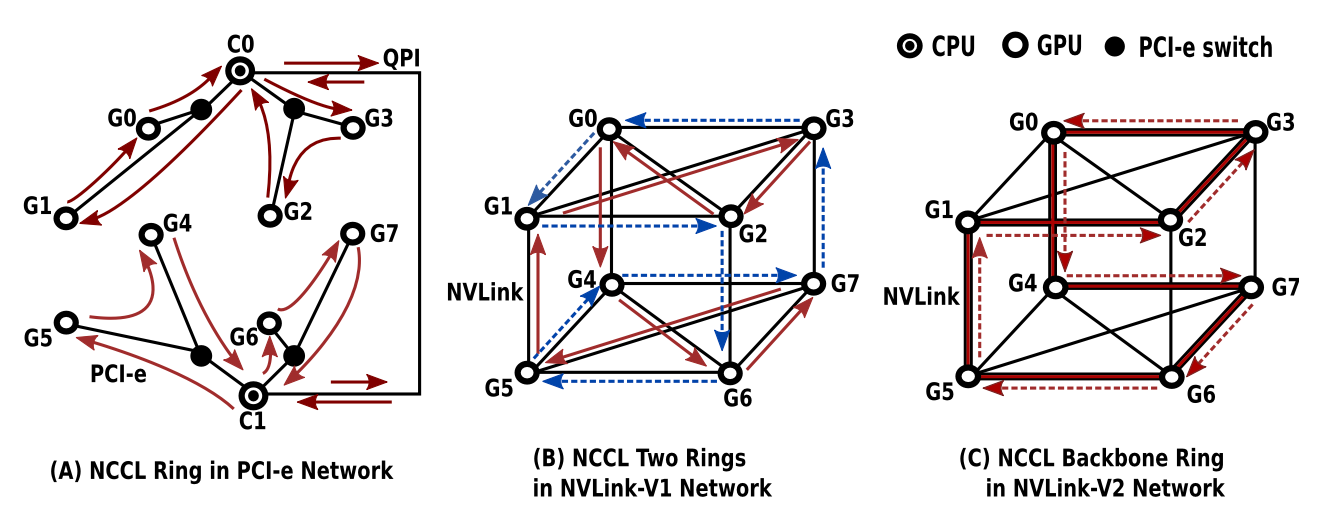
在一个复杂的 GPU 拓扑中,路径的正确选择对 NCCL 的性能至关重要。以单机多卡 Ring 算法场景为例:
- 图(A)中,Ring 的瓶颈显然在 CPU 之间的 QPI 节点上,所以 Ring 一定不能经过 CPU。
- 图(B)中,使用了 NVLink GPU p2p 技术,GPU 之间直连的 Latency 为 10 微秒左右。最多支持 4 条 Ring 环,理论带宽跑满且等价。
- 图(C)中,最多支持 4 条 Ring 环,但存在一条更加粗壮的骨干 Ring 环(2 条 NVLink),带宽最大,并不等价。
又由于 Cube-Mesh 不是 Full-Mesh,所以即便在图(C)中,如果用户指定了在 GPU 0/1/2/7 之间进行 all-reduce,由于 7 和 0/1/2 离得太远,就会对算法效率造成很大的影响。
可见,在一个 NCCL 环中,性能的瓶颈就是带宽最小的那个节点,因此 NCCL 需要具备自适应的路径选择能力,以达到各种拓扑结构下性能都尽可能的好。
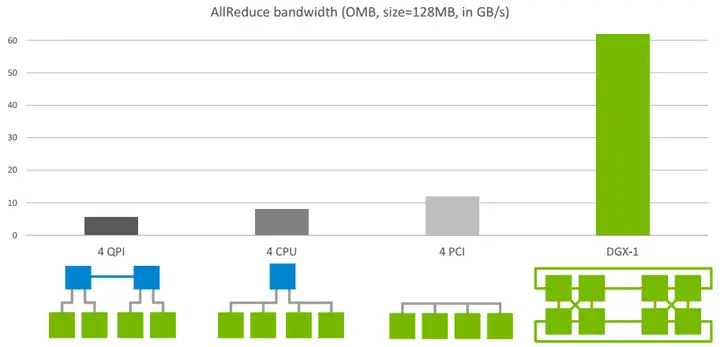
下图是 all-reduce 在单机内不同通信拓扑架构下的速度比较:
通信算法类型
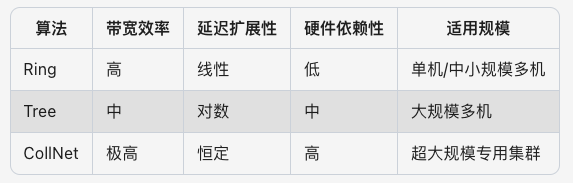
Ring 环算法:将每个相邻的 GPU “手牵手” 链接起来,构建一个环形网络进行数据交换。
- 优点:
- 对称性,GPU 设备带宽利用率高:每个 GPU 节点同时利用上行和下行带宽,理论带宽接近硬件极限,适合大数据量传输。
- 单机多卡场景性能优异:尤其当 GPU 间使用 NVLink 时。
- 简洁性:无需复杂拓扑管理,适合快速部署。
- 缺点:
- 延迟会随着 GPU 的数量线性增长,因为每个 GPU 每次发送完一个 chunk 的数据就必须等下一个 chunk 从另一张 GPU 发过来,整个过程总共需要发送 2(n-1)次,则延时为 2(n-1) 的倍数。这种情况涉及 all-reduce、reduce-scatter 和 all-gather 操作。所以在多机多卡场景中延迟较高。
- 跨节点性能受限:节点间 RDMA 带宽较低,环形通信会成为瓶颈。
- 应用场景:
- 单机多卡场景。
- 中小规模多机多卡集群场景:节点数较少且采用 RDMA 高带宽环境。
Tree(Double binary tree)树算法:2019 年 NCCL 2.4 提出,主要思想是利用二叉树中大约一半节点是叶子节点的特性,通过将叶子节点变换为非叶子节点,得到两颗二叉树(双二叉树结构)。每个节点在其中一颗二叉树上是叶子节点,在另一颗二叉树上是非叶子节点。NCCL 默认在多机多卡场景使用 Tree 算法。
- 优点:
- 延迟低:通信步骤数为 O(log N),适合大规模多机多卡集群。
- 跨节点优化:通过分层(Intra-node + Inter-node)流水线优化,减少跨网络通信次数。
- 缺点:
- 带宽利用率低于 Ring:由于分层操作和中间聚合,理论带宽可能略低于 Ring。
- 拓扑依赖性强:需动态构建最优树结构,对网络拓扑敏感,配置复杂度较高。
- 应用场景:
- 大规模多机多卡训练场景。
- 低延迟需求:需要快速完成小数据量同步的场景(如参数梯度聚合)。
CollNet(Collective Network)集合网络算法:建立在 SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)In-Network Computing 技术的基础之上的,专为与 IB 网络配合使用而设计。
- 优点:
- 超高性能:跨节点带宽可达 95GB/s(接近机内 NVLink 带宽),延迟极低,适合超大规模集群。
- 计算卸载:IB 交换机完成 Reduce 操作,减少 GPU 通信负担。
- 缺点:
- 成本高:依赖全套 NVIDIA 技术。
- 应用场景:
- 超大规模 HPC 集群
- 高吞吐低延迟需求:如大模型训练、实时推理任务。
路径选择
路径选择的目标是在 Topo 确定 ranks 之间的最优数据传输路径,通常基于带宽、延迟、跳数、硬件链接类型(NVLink、PCIe、NET 等)等参数作为选择指标,并执行最短路径算法(Dijkstra)、最小瓶颈路算法(SPFA)等。
NCCL 的 Path 模块实现了最优路径选择,其基于 Topo 结构,应用贪心算法来构造 “最大带宽、最低延迟” 的路径,方便后续的 Channel 通道搜索。
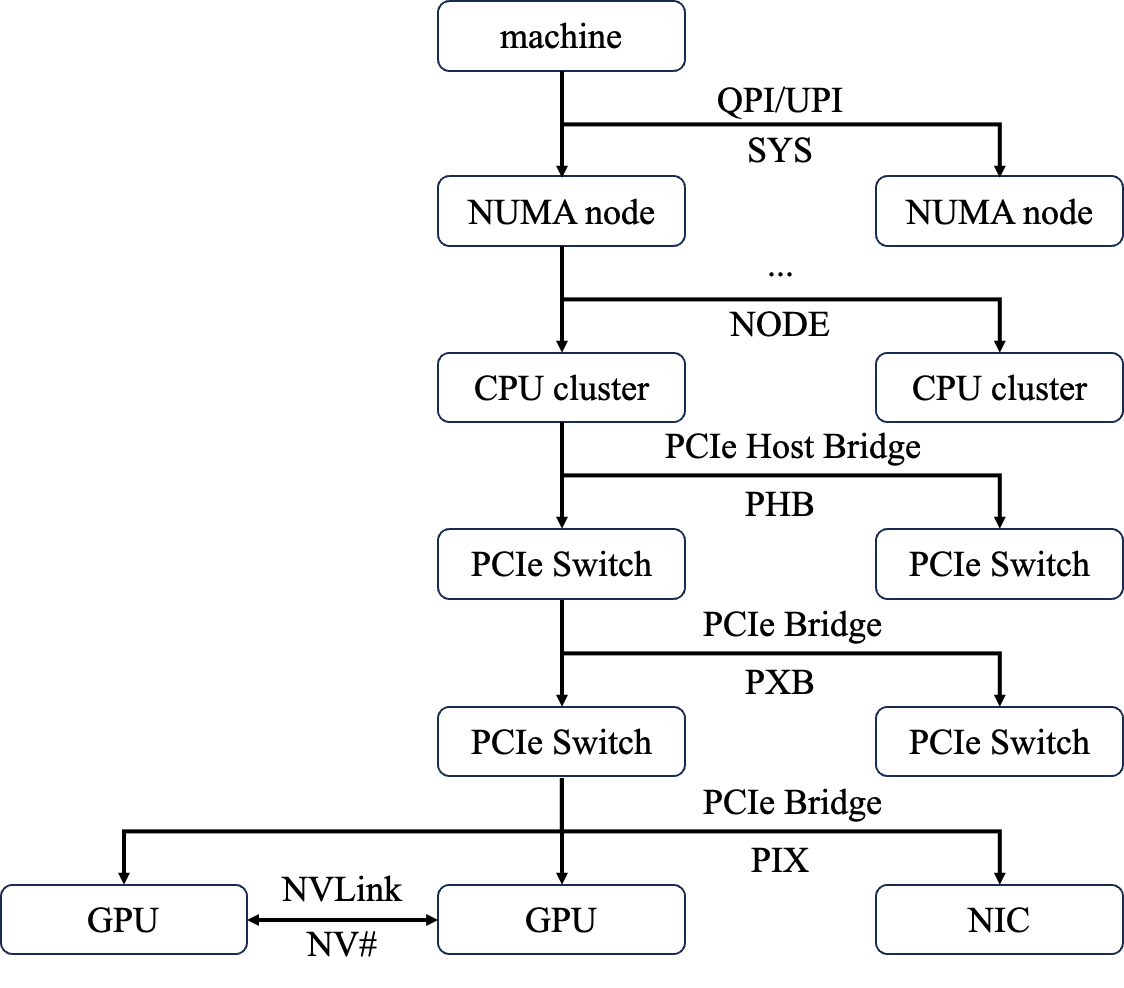
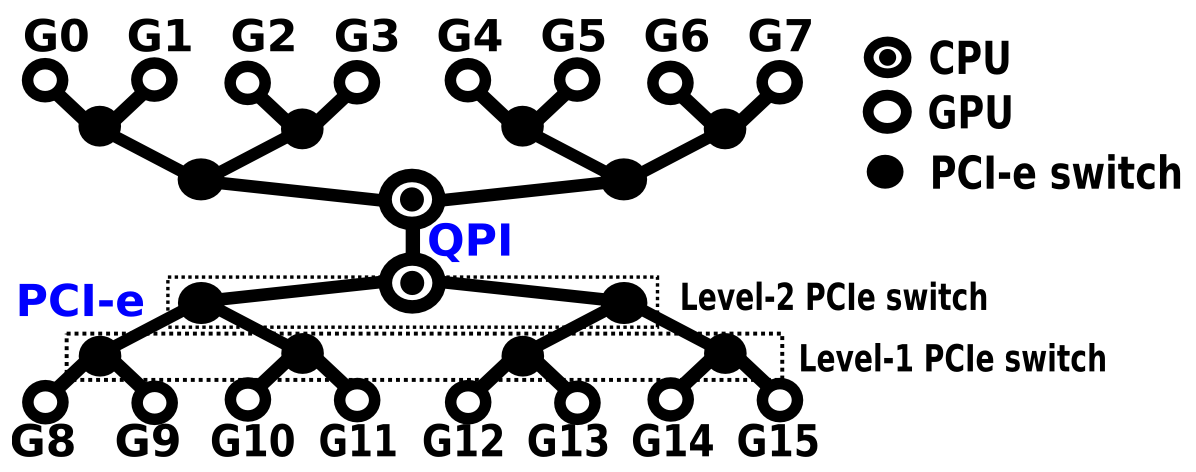
如下图所示,单机场景中,Path 模块定义了多种 GPU-GPU、GPU-NIC、NIC-NIC 之间路径类型:
- NV#(Connection traversing a bonded set of # NVLinks):通过 NVLink 实现 2 个 GPU 之间的直连,支持 GPU p2p read 技术。
- PIX(Connection traversing at most a single PCIe bridge):GPU8 和 GPU9 通过一跳 PCIe Switch 就能相连。
- PXB(Connection traversing multiple PCIe bridges but without traversing the PCIe Host Bridge):GPU8 和 GPU10 通过两跳 PCIe Switch 才能相连。
- PHB(Connection traversing PCIe as well as a PCIe Host Bridge):GPU8 和 GPU12 通过 CPU 根节点 PCIe Host Bridge 才能相连。如果 NIC 和 GPU 之间经过了 CPU 节点,则无法使用 GDR。
- NOTE:跨 CPU Cluster(一个 NUMA node 中的 2 个 CPU core 集合)但是不跨 NUMA node 的 GPU 之间的通信。
- SYS(Connection traversing PCIe as well as the SMP interconnect between NUMA nodes, e.g., QPI/UPI):GPU8 和 GPU0 要跨过 CPU 节点之间的 QPI 才能相连。一定要避免跨 NUMA node 的通信。
显然,它们的传输性能从高到低为:NV# > PIX > PXB > PHB > NODE > SYS。NCCL 路径选择的工作就是优先选择 NV# 直连,而非 PIX,以此确保路径上每个环节都使用了最大的带宽。
Channel 搜索
Channel 是 NCCL 中管理通信链路的基本单元,是虚拟的逻辑通信链路,而非直接的物理硬件链路。Channel 搜索由 Search 模块实现,NCCL 通过建立和管理一组并发的 Channel 来实现多路径并发通信,以此提升数据传输的并行性和带宽利用率。
但实际上虚拟的 Channel 搜索受到物理最优路径选择的影响。默认的,在路径选择的基础之上,NCCL 支持暴力搜索出性能最好的 Ring 或 Tree 通信 Channel。(根据输入的参数严格匹配,如果够不符合,则降低条件继续搜索。)
例如:单机 8 卡场景中,应用 Ring 算法的 Channel 搜索会构建出以下环形结构,物理路径层间全部使用 NVLink 链接,虚拟通道层面可以创建多个 Channel 并行传输数据。
Ring Channel 1:G0 => G4 => G7 => G6 => G5 => G1 => G2 => G3 => G0
Ring Channel 2:G0 => G4 => G7 => G6 => G5 => G1 => G2 => G3 => G0
Ring Channel 3:G0 => G4 => G7 => G6 => G5 => G1 => G2 => G3 => G0
小环和大环拓扑
实际上,在大模型训练场景中,虚拟 Channel 和物理路径的关系通常是 1: 1 的,因为大模型训练会瞬间把带宽跑满,通常不存在利用率低的情况。
在多机多卡 Ring 场景中,还存在小环(Intra-node Ring)和大环(Inter-node Ring)拓扑的区别:
- 小环:单机场景中的,单机内的 GPU Ring 环,通过 NVLink 直连。
- 大环:多机场景中的,多机间的 GPU Ring 环,通过 RNIC(IB 或 RoCEv2)互联。
以单机 8 张 P100 GPU 卡,Cube-Mesh 拓扑为例,拓扑信息详见:《8 卡 GPU 服务器与 NVLink/NVSwitch 互联技术》。

小环拓扑:如下图所示,存在 4 条 Ring,每条 Ring 的任意一条路径都不会重叠,带宽全部对称性的跑满,这也是 Ring 算法的特征。理想状态下,小环的带宽上限就是 GPU 设备的总带宽。

大环拓扑:如下所示,node1、2、… 组成一个大环,多节点之间都使用 rnicX 进行跨节点之间的数据传输。通过对交换机的配置实现了只允许同号 rnicX 之间的网络切面互通。理想状态下,大环的带宽上限就是服务器 RNIC 带宽之和(假设 GPU 带宽总是大于 RNIC 带宽)。
node1-rnic0 G0=>G1=>G3=>G2=>G6=>G7=>G5=>G4 node1-rnic0 : node2-rnic0 G0=>G1=>G3=>G2=>G6=>G7=>G5=>G4 node2-rnic0 : node3-rnic0 ......
node1-rnic1 G0=>G4=>G5=>G7=>G6=>G2=>G3=>G1 node1-rnic1 : node2-rnic1 G0=>G4=>G5=>G7=>G6=>G2=>G3=>G1 node2-rnic1 : node3-rnic1 ......
node1-rnic2 G0=>G2=>G6=>G4=>G5=>G7=>G3=>G1 node1-rnic2 : node2-rnic2 G0=>G2=>G6=>G4=>G5=>G7=>G3=>G1 node2-rnic2 : node3-rnic2 ......
node1-rnic3 G0=>G3=>G7=>G5=>G4=>G6=>G2=>G1 node1-rnic3 : node2-rnic3 G0=>G3=>G7=>G5=>G4=>G6=>G2=>G1 node2-rnic3 : node3-rnic3 ......
NCCL 的 GPU 建连
GPU 建连过程包括:
- 缓冲区分配:每个 Channel 分配发送(sendbuff)和接收(recvbuff)缓冲区,并通过 CUDA 统一内存管理减少拷贝开销。
- 双向链路建立:设置每个 GPU 的 prev 和 next 节点,形成 Ring 环链路。
- 硬件同步机制:通过 CUDA Stream 和事件(Event)实现异步通信,确保数据传输与计算并行。
GPU 建连后,即可进行后续的集合通信操作了。
NCCL 的集合通信操作方式
NCCL 最核心的功能就是提供了多种分布式训练场景中需要使用到的集合通信操作,包括:
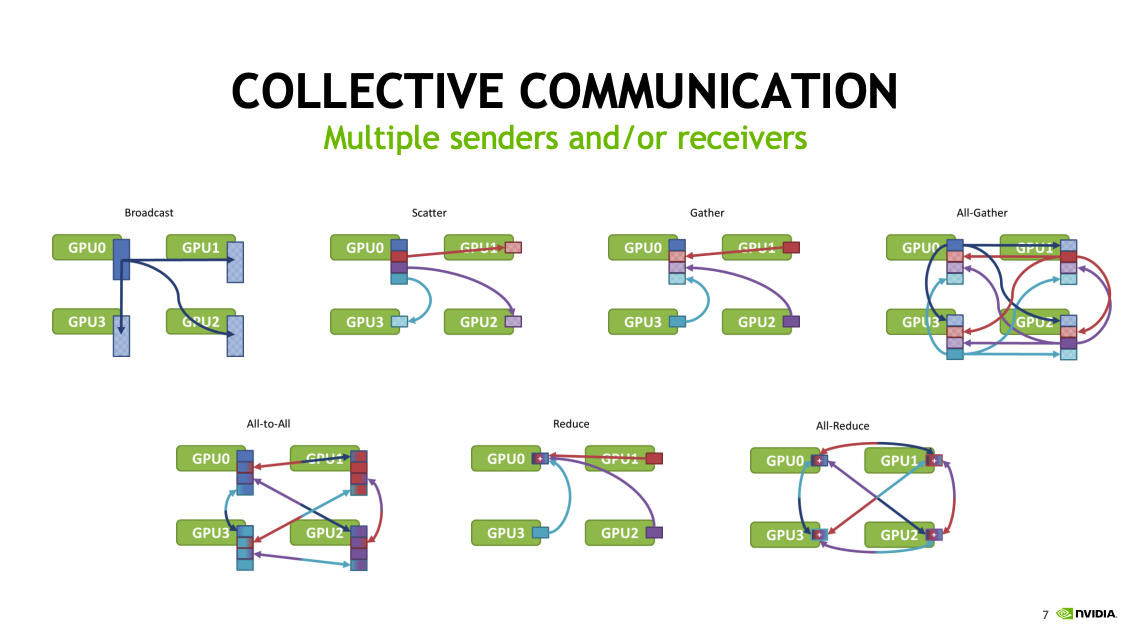
broadcast(广播)
将一个 GPU 上的数据广播到所有其他 GPU。常用于在训练开始时,将输入的参数分发、同步到所有 GPU。一个发送者,多个接受者。
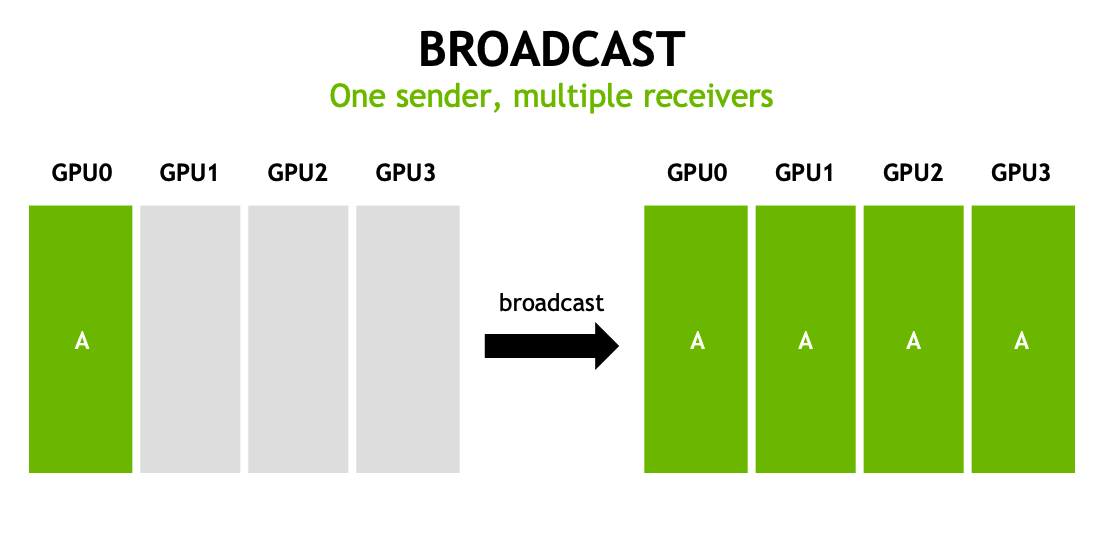
scatter(散射)
将一个 GPU 上的数据分散到多个 GPU 上,每个 GPU 获得数据的一部分。一个发送者,数据切分,给到多个接受者。
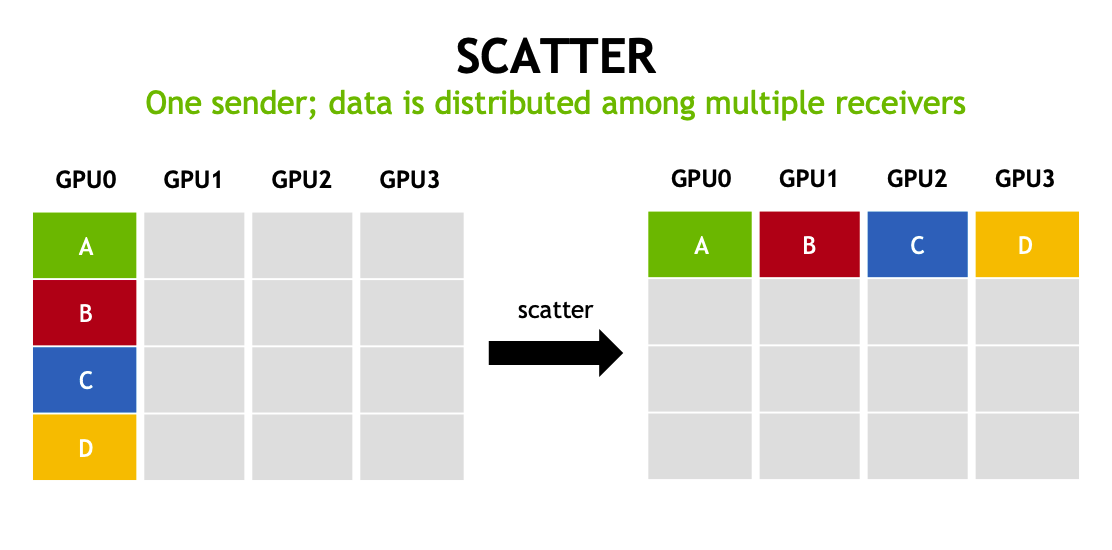
gather(收集)
将多个 GPU 上的数据收集到一个 GPU 上,与 Scatter 操作相反。多个发送者,一个接受者。
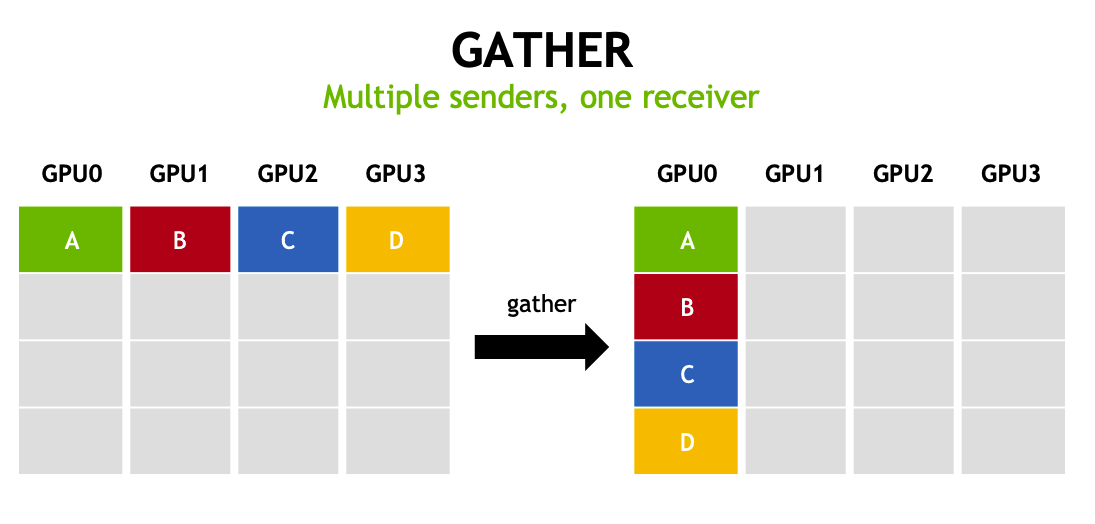
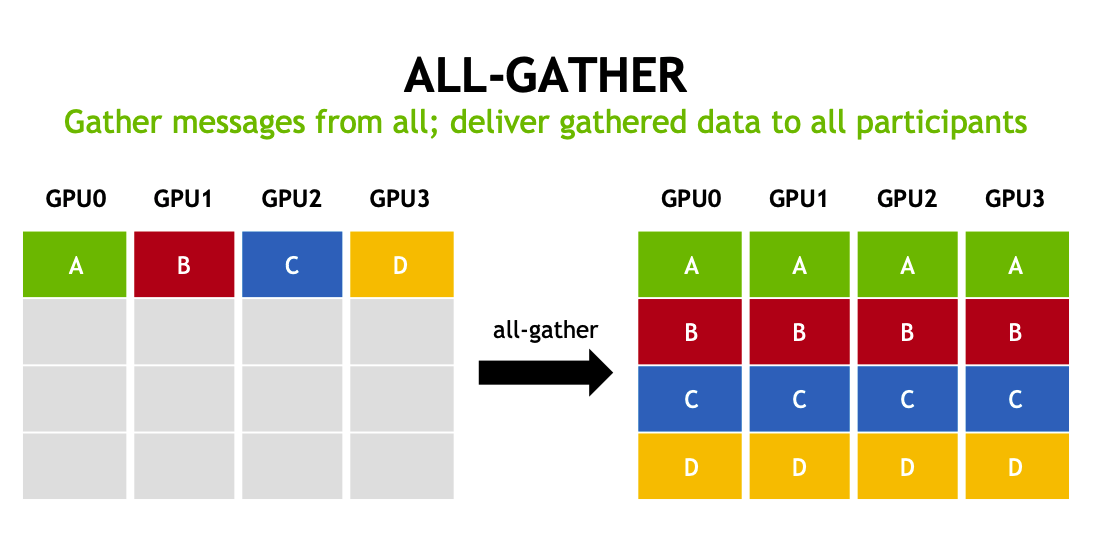
all-gather(全局收集)
将所有 GPU 上的数据收集到所有 GPU 上,每个 GPU 最终都会拥有所有数据。搜集所有 GPU 的数据,并将数据发送给到所有 GPU。
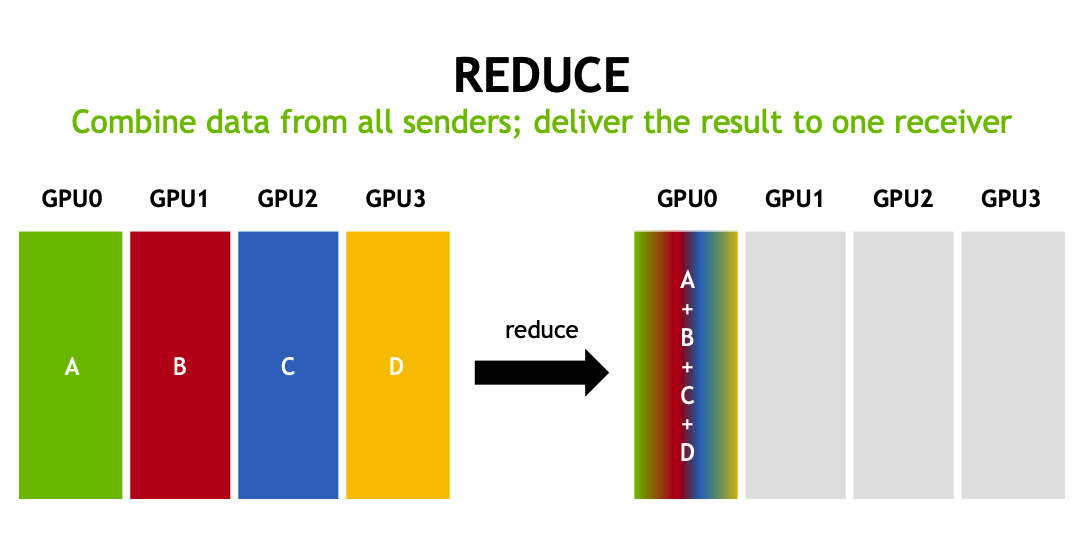
reduce(归约)
将所有 GPU 上的数据进行归约操作,并将结果存储在一个 GPU 上。合并所有发送者的数据,并将结果发送给一个接收者。
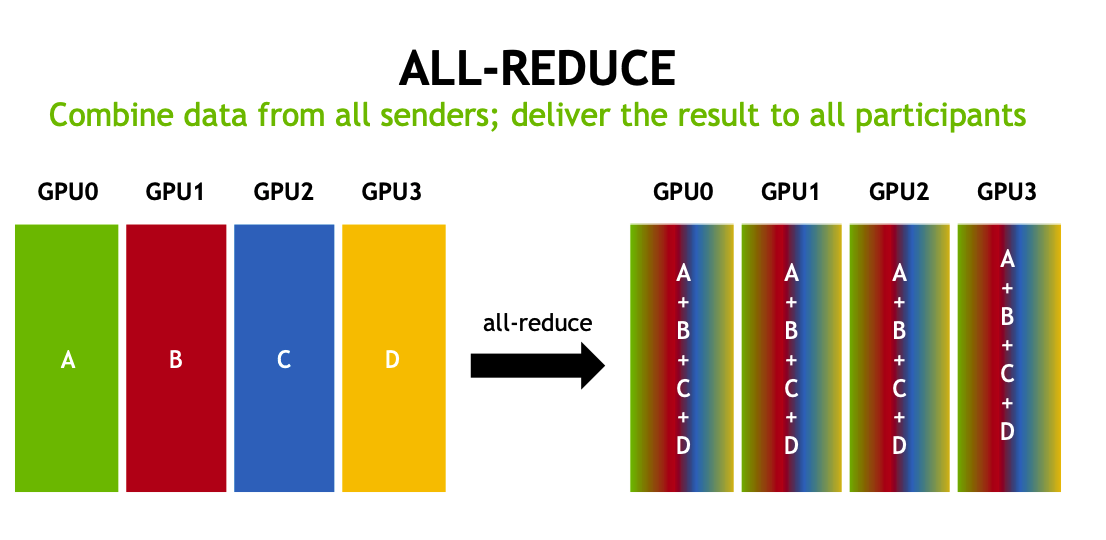
all-reduce(全局归约)
将所有 GPU 上的数据进行全局归约操作,并将结果广播到所有 GPU。这是分布式训练中最常用的操作之一,用于同步模型参数的梯度。合并所有发送者的数据,并将结果发送给所有参与者。
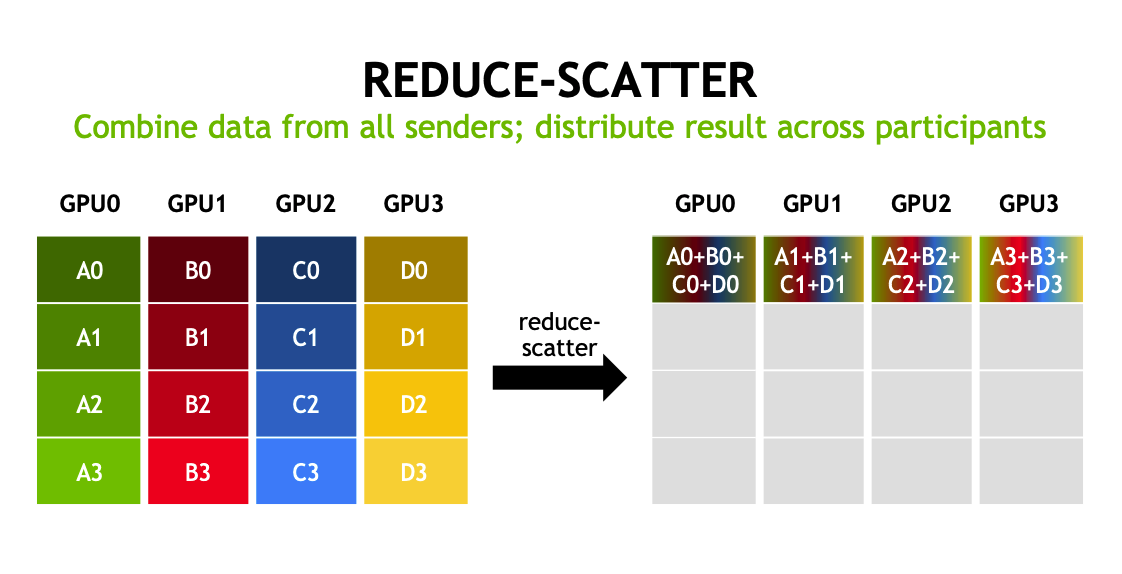
reduce-scatter(归约散射)
将所有 GPU 上的数据进行归约操作,并将结果分散到多个 GPU 上。合并所有发送者的数据,并将结果切分给参与者。
all-to-all
将每个参与者的不同消息分散/收集到其他参与者。

point-to-point(点对点发送和接收)
nccl-tests 项目
NVIDIA NCCL 提供了性能测试库(https://github.com/NVIDIA/nccl-tests),例如在 8 张 V100 GPU 的服务器上测试。
$ nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity
GPU0 X NV1 NV1 NV2 SYS SYS NV2 SYS 0-95
GPU1 NV1 X NV2 NV1 SYS SYS SYS NV2 0-95
GPU2 NV1 NV2 X NV2 NV1 SYS SYS SYS 0-95
GPU3 NV2 NV1 NV2 X SYS NV1 SYS SYS 0-95
GPU4 SYS SYS NV1 SYS X NV2 NV1 NV2 0-95
GPU5 SYS SYS SYS NV1 NV2 X NV2 NV1 0-95
GPU6 NV2 SYS SYS SYS NV1 NV2 X NV1 0-95
GPU7 SYS NV2 SYS SYS NV2 NV1 NV1 X 0-95
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe switches (without traversing the PCIe Host Bridge)
PIX = Connection traversing a single PCIe switch
NV# = Connection traversing a bonded set of # NVLinks
#$ .cuda-samples/Samples/1_Utilities/topologyQuery
$ ./build/all_reduce_perf -b 8 -e 128M -f 2 -g 8
# nThread 1 nGpus 8 minBytes 8 maxBytes 134217728 step: 2(factor) warmup iters: 5 iters: 20 validation: 1
#
# Using devices
# Rank 0 Pid 746 on 9a417caaf03b device 0 [0x4f] Tesla V100-SXM2-16GB
# Rank 1 Pid 746 on 9a417caaf03b device 1 [0x50] Tesla V100-SXM2-16GB
# Rank 2 Pid 746 on 9a417caaf03b device 2 [0x5f] Tesla V100-SXM2-16GB
# Rank 3 Pid 746 on 9a417caaf03b device 3 [0x60] Tesla V100-SXM2-16GB
# Rank 4 Pid 746 on 9a417caaf03b device 4 [0xb1] Tesla V100-SXM2-16GB
# Rank 5 Pid 746 on 9a417caaf03b device 5 [0xb2] Tesla V100-SXM2-16GB
# Rank 6 Pid 746 on 9a417caaf03b device 6 [0xdb] Tesla V100-SXM2-16GB
# Rank 7 Pid 746 on 9a417caaf03b device 7 [0xdc] Tesla V100-SXM2-16GB
#
# out-of-place in-place
# size count type redop time algbw busbw error time algbw busbw error
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
8 2 float sum 48.46 0.00 0.00 1e-07 48.17 0.00 0.00 1e-07
16 4 float sum 48.61 0.00 0.00 6e-08 49.16 0.00 0.00 6e-08
32 8 float sum 48.48 0.00 0.00 6e-08 48.14 0.00 0.00 6e-08
64 16 float sum 48.92 0.00 0.00 6e-08 48.50 0.00 0.00 6e-08
128 32 float sum 48.13 0.00 0.00 6e-08 48.25 0.00 0.00 6e-08
256 64 float sum 48.47 0.01 0.01 6e-08 48.50 0.01 0.01 6e-08
512 128 float sum 48.56 0.01 0.02 6e-08 48.29 0.01 0.02 6e-08
1024 256 float sum 48.88 0.02 0.04 2e-07 48.83 0.02 0.04 2e-07
2048 512 float sum 49.40 0.04 0.07 2e-07 49.15 0.04 0.07 2e-07
4096 1024 float sum 49.13 0.08 0.15 2e-07 48.97 0.08 0.15 2e-07
8192 2048 float sum 49.14 0.17 0.29 2e-07 49.25 0.17 0.29 2e-07
16384 4096 float sum 50.35 0.33 0.57 2e-07 49.77 0.33 0.58 2e-07
32768 8192 float sum 51.06 0.64 1.12 2e-07 50.78 0.65 1.13 2e-07
65536 16384 float sum 52.78 1.24 2.17 2e-07 52.64 1.24 2.18 2e-07
131072 32768 float sum 56.56 2.32 4.06 2e-07 55.63 2.36 4.12 2e-07
262144 65536 float sum 60.26 4.35 7.61 2e-07 59.48 4.41 7.71 2e-07
524288 131072 float sum 61.48 8.53 14.92 2e-07 61.34 8.55 14.96 2e-07
1048576 262144 float sum 89.27 11.75 20.56 2e-07 88.45 11.85 20.75 2e-07
2097152 524288 float sum 119.6 17.53 30.68 2e-07 116.7 17.97 31.45 2e-07
4194304 1048576 float sum 147.4 28.45 49.79 2e-07 145.1 28.91 50.59 2e-07
8388608 2097152 float sum 203.8 41.16 72.03 2e-07 204.0 41.12 71.97 2e-07
16777216 4194304 float sum 324.1 51.77 90.59 2e-07 325.7 51.51 90.14 2e-07
33554432 8388608 float sum 550.8 60.92 106.62 2e-07 553.3 60.64 106.12 2e-07
67108864 16777216 float sum 992.7 67.60 118.30 2e-07 995.0 67.45 118.04 2e-07
134217728 33554432 float sum 1818.8 73.80 129.14 2e-07 1821.9 73.67 128.92 2e-07
# Out of bounds values : 0 OK
# Avg bus bandwidth : 25.9598
- algbw = S/t:S 表示数据量,t 表示操作完 S 数据量所用时间。以 128MB 数据测试结果为例:
algbw = 134217728 / (1818.8*10^(-6))/1000^3 = 73.80 GB/s
- busbw = algbw * 2(n-1)/n:n 表示 collective operation 中节点的个数,即:-g GPU 的数目。
参考材料
- https://blog.csdn.net/u014443578/article/details/136045600
- https://blog.csdn.net/weixin_42371021/category_12713616.html
- https://blog.csdn.net/lianghuaju/article/details/138583268
- https://images.nvidia.cn/events/sc15/pdfs/NCCL-Woolley.pdf