前言
在蓝桥杯 C/C++ 语言程序设计竞赛中,深度优先搜索(DFS)和广度优先搜索(BFS)是极为重要的解题算法。DFS 如同一位无畏的探险家,执着地往一条路径深入,探寻所有可能的情况;而 BFS 则似层层扩散的涟漪,优先探索离起点近的区域,擅长寻找最优解。掌握这两种算法,能让我们在竞赛中如虎添翼。下面,就让我们深入了解 DFS 和 BFS 及其在真题中的应用。
一、深度优先搜索(DFS)
(一)DFS 简介
深度优先搜索是一种用于遍历或搜索树、图等数据结构的算法。它从起始节点出发,沿着一条路径尽可能深地探索,直到无法继续,然后回溯到上一个节点,尝试其他路径,直至遍历完所有可能的路径。
(二)思路介绍
DFS 的核心在于递归或借助栈来模拟递归过程。从初始状态开始,选择一个分支深入探索,同时标记已访问的状态以避免重复。遇到无法继续的情况(如边界条件、不满足条件等)时回溯,继续探索其他分支,直到找到目标状态或遍历完所有状态。
(三)模板
#include <iostream>
#include <vector>
using namespace std;
// 二维网格DFS模板示例
const int MAXN = 100;
bool visited[MAXN][MAXN];
int dx[] = {-1, 1, 0, 0};
int dy[] = {0, 0, -1, 1};
void dfs(int x, int y, const vector<vector<int>>& grid) {
int rows = grid.size();
int cols = grid[0].size();
if (x < 0 || x >= rows || y < 0 || y >= cols || visited[x][y]) {
return;
}
visited[x][y] = true;
// 此处可添加对当前节点的处理逻辑,如输出、计算等
// 根据具体题目需求修改
cout << "Visiting cell (" << x << ", " << y << ")" << endl;
for (int i = 0; i < 4; i++) {
int newX = x + dx[i];
int newY = y + dy[i];
dfs(newX, newY, grid);
}
}(四)真题讲解
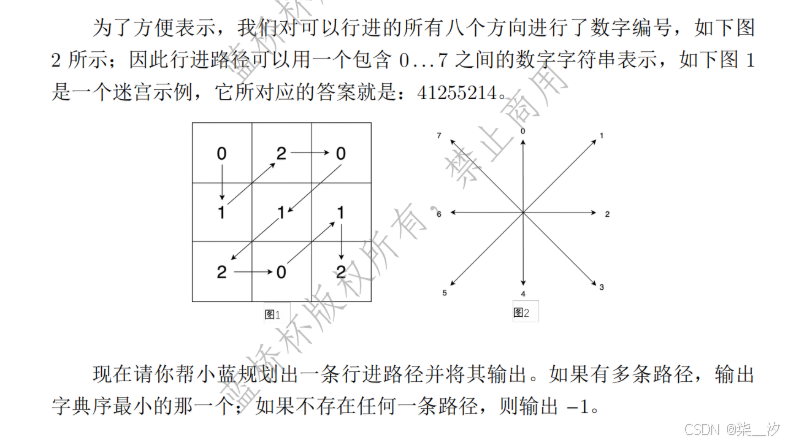
(1)数字接龙
-
问题描述:



-
整体思路
本题可通过深度优先搜索(DFS)来求解。由于要在 N×N的棋盘上,从左上角(0, 0)出发找到满足特定规则到达右下角(N - 1, N - 1)的路径,DFS 适合这种在多种可能路径中进行探索的场景。游戏规则要求路径数字按0到(K - 1)循环,且每个格子仅经过一次、路径不交叉,所以在 DFS 过程中,从起始点开始,每到一个格子,需按 8 个方向(水平、垂直、对角线)去探索新格子。对于每个新格子,要判断是否在棋盘内,防止越界;检查是否已访问,保证每个格子只走一次;确认数字是否符合循环序列,确保路径数字规则正确;还要查看路径是否交叉,满足所有这些条件才能继续递归探索。持续此过程,要么找到符合规则的路径,若有多条则按字典序选取最小的输出,要么确定不存在路径时输出-1 。
-
代码示例:
#include<bits/stdc++.h> using namespace std; const int N = 11; // 定义棋盘的最大大小 int n, k; // n 为棋盘大小,k 为数字循环的范围 int board[N][N]; // 存储棋盘上的数字 int dx[8] = {-1, -1, 0, 1, 1, 1, 0, -1}; // 定义 8 个方向的 x 坐标偏移 int dy[8] = {0, 1, 1, 1, 0, -1, -1, -1}; // 定义 8 个方向的 y 坐标偏移 string path; // 存储路径的方向编号 bool visited[N][N]; // 标记棋盘上的格子是否被访问过 bool edge[N][N][N][N]; // 检查路径是否交叉 // 深度优先搜索函数,用于寻找路径 bool dfs(int x, int y) { // 如果到达右下角格子,检查路径长度是否为 n*n - 1(因为起点不计入路径) if (x == n - 1 && y == n - 1) { return path.size() == n * n - 1; } visited[x][y] = true; // 标记当前格子已访问 for (int i = 0; i < 8; i++) { // 遍历 8 个方向 int newX = x + dx[i]; int newY = y + dy[i]; // 检查目标格子是否越界、是否访问过、数字是否满足循环序列要求 if (newX < 0 || newX >= n || newY < 0 || newY >= n) continue; if (visited[newX][newY]) continue; if (board[newX][newY] != (board[x][y] + 1) % k) continue; // 检查路径是否交叉(对于斜向移动,检查是否有反向的路径) if (edge[x][newY][newX][y] || edge[newX][y][x][newY]) continue; edge[x][y][newX][newY] = true; // 标记路径 path += i + '0'; // 将方向编号加入路径 if (dfs(newX, newY)) return true; // 递归搜索下一个格子 path.pop_back(); // 回溯,移除路径中的最后一个方向 edge[x][y][newX][newY] = false; // 回溯,取消路径标记 } visited[x][y] = false; // 回溯,取消当前格子的访问标记 return false; // 如果所有方向都无法到达终点,返回 false } int main() { cin >> n >> k; // 输入棋盘大小和数字循环范围 for (int i = 0; i < n; i++) { // 读取棋盘上的数字 for (int j = 0; j < n; j++) { cin >> board[i][j]; } } // 从起点 (0, 0) 开始搜索路径 if (!dfs(0, 0)) { cout << -1 << endl; // 如果没有找到路径,输出 -1 } else { cout << path << endl; // 输出路径的方向编号序列 } return 0; }
具体步骤及代码对应解释
- 初始化及数据存储
- 使用
const int N = 11;定义棋盘的最大大小,方便后续数组等数据结构的声明,确保程序能处理一定规模内的棋盘。 - 声明
int n, k;用于存储输入的棋盘实际大小n和数字循环范围k。 int board[N][N];二维数组用来存放棋盘上每个格子的数字,后续根据这个数组判断数字是否符合接龙规则。int dx[8]和int dy[8]数组分别存储 8 个移动方向在x和y坐标上的偏移量,便于在搜索时计算新格子的坐标。string path;用于记录从起点到终点的路径,通过不断添加方向编号来构建路径字符串。bool visited[N][N];二维布尔数组标记棋盘上的格子是否已被访问过,防止重复访问同一个格子,保证每个格子恰经过一次。bool edge[N][N][N][N];四维布尔数组用于检查路径是否交叉,对于斜向移动,通过标记和检查反向路径来判断是否交叉。
- 使用
- 深度优先搜索函数
dfs- 终点判断:在函数开头,通过
if (x == n - 1 && y == n - 1)判断是否到达右下角的终点格子。到达终点后,再用return path.size() == n * n - 1;检查路径长度是否等于棋盘格子总数减 1(因为起点本身不算在路径移动次数内),以此确定是否找到符合要求的完整路径。 - 标记当前格子:
visited[x][y] = true;将当前正在探索的格子标记为已访问,避免后续重复访问。 - 方向遍历:通过
for (int i = 0; i < 8; i++)循环遍历 8 个移动方向。在每次循环中,计算新格子的坐标newX = x + dx[i];和newY = y + dy[i];。 - 条件判断:
if (newX < 0 || newX >= n || newY < 0 || newY >= n) continue;检查新格子是否超出棋盘边界,若越界则跳过本次循环,不继续探索该方向。if (visited[newX][newY]) continue;检查新格子是否已被访问过,若已访问则跳过,保证每个格子仅经过一次。if (board[newX][newY] != (board[x][y] + 1) % k) continue;检查新格子上的数字是否符合接龙规则,即新数字应是当前数字按0到k - 1循环序列的下一个数字,不符合则跳过。if (edge[x][newY][newX][y] || edge[newX][y][x][newY]) continue;检查路径是否交叉,对于斜向移动,判断是否存在反向的路径标记,若交叉则跳过该方向。
- 路径探索与回溯:
- 当新格子满足所有条件时,
edge[x][y][newX][newY] = true;标记从当前格子到新格子的路径,path += i + '0';将该方向编号加入路径字符串。然后递归调用dfs(newX, newY)继续从新格子探索下一个可能的路径。 - 如果递归调用
dfs(newX, newY)返回false,说明该方向探索失败,需要进行回溯。通过path.pop_back();移除路径字符串中最后添加的方向编号,edge[x][y][newX][newY] = false;取消刚才标记的路径,visited[x][y] = false;取消当前格子的访问标记,以便后续重新探索。
- 当新格子满足所有条件时,
- 终点判断:在函数开头,通过
- 主函数
main- 首先通过
cin >> n >> k;读取输入的棋盘大小n和数字循环范围k。 - 然后使用嵌套的
for循环for (int i = 0; i < n; i++)读取棋盘上每个格子的数字并存储到board数组中。 - 最后从起点
(0, 0)调用dfs(0, 0)开始搜索路径。若dfs(0, 0)返回false,说明没有找到符合要求的路径,输出-1;若返回true,则输出记录路径的字符串path。
- 首先通过
(2)飞机降落
-
问题描述:



-
整体思路
本题要判断 N 架飞机能否在只有一条跑道的机场全部安全降落。因为飞机降落顺序有多种组合情况,且需满足每架飞机在其最晚降落时间(即到达时刻 \(T_i\) 加上可盘旋时间 \(D_i\) )之前开始降落,同时跑道同一时刻只能供一架飞机降落这两个关键条件。
深度优先搜索(DFS)适合解决此类问题。我们从还未安排降落的飞机中选择一架进行尝试。选择某架飞机后,先判断它能否在最晚降落时间之前开始降落。若不能,就放弃这架飞机,尝试其他未降落的飞机;若能,就标记这架飞机已降落,并计算它降落完成后的时间。然后以这个时间为基础,递归地去安排下一架飞机的降落。
通过这样不断地尝试不同飞机的降落顺序,深度优先地探索所有可能的组合情况。如果在某一种顺序下,所有飞机都能成功降落,那就说明 N 架飞机可以全部安全降落;要是把所有可能的降落顺序都尝试完了,还是无法让所有飞机都降落,那就意味着这些飞机不能全部安全降落。
-
代码示例:
#include<bits/stdc++.h> using namespace std; // 定义飞机结构体,包含到达时刻 t、可盘旋时间 d、降落所需时间 l 以及是否已降落的标记 judge struct Plane { int t, d, l; // t 时刻,盘旋时间 d,降落时间 l bool judge; // 判断各家飞机是否降落 }; // 自定义 max 函数,返回两个整数中的最大值 int max(int a, int b) { return (a > b)? a : b; } // 深度优先搜索函数,用于尝试所有可能的飞机降落顺序 // u 表示当前已经安排降落的飞机数量 // time 表示当前的时间 // n 表示飞机的总数 // a 是存储所有飞机信息的数组 bool dfs(int u, int time, int n, vector<Plane>& a) { // 如果已经安排降落的飞机数量达到了飞机总数,说明所有飞机都能安全降落,返回 true if (u >= n) return true; // 遍历所有飞机 for (int i = 0; i < n; i++) { // 如果这架飞机还没有降落 if (!a[i].judge) { // 标记这架飞机已经降落 a[i].judge = true; // 检查这架飞机是否能在其最晚降落时间之前开始降落 if (a[i].t + a[i].d < time) { // 如果不能,取消标记,继续尝试下一架飞机 a[i].judge = false; continue; } // 计算这架飞机降落完成后的时间 int t = max(time, a[i].t) + a[i].l; // 递归调用 dfs 函数,尝试安排下一架飞机降落 if (dfs(u + 1, t, n, a)) return true; // 如果递归调用返回 false,说明这种安排方式不可行,取消标记,回溯 a[i].judge = false; } } // 如果所有可能的安排方式都不可行,返回 false return false; } int main() { int sum; // 读取测试用例的数量 cin >> sum; // 循环处理每个测试用例 for (int i = 0; i < sum; i++) { int n; // 读取当前测试用例中飞机的数量 cin >> n; // 定义一个存储飞机信息的向量 vector<Plane> a(n); // 初始化所有飞机的降落标记为 false for (int j = 0; j < n; j++) a[j].judge = false; // 读取每架飞机的到达时刻、可盘旋时间和降落所需时间 for (int j = 0; j < n; j++) cin >> a[j].t >> a[j].d >> a[j].l; // 调用 dfs 函数尝试安排飞机降落 if (dfs(0, 0, n, a)) cout << "YES" << endl; else cout << "NO" << endl; } return 0; }具体步骤及代码对应解释
-
数据结构定义:
- 定义
Plane结构体,包含三个成员变量t(飞机到达机场上空的时刻)、d(飞机可继续盘旋的时间)、l(飞机降落所需的时间),以及一个布尔类型的judge变量,用于标记飞机是否已经降落。
- 定义
-
深度优先搜索函数
dfs:- 参数说明:
u:表示当前已经安排降落的飞机数量。time:表示当前的时间。n:表示飞机的总数。a:是存储所有飞机信息的向量。
- 递归终止条件:当
u >= n时,说明所有飞机都已经安排降落,返回true。 - 递归过程:
- 遍历所有飞机,对于每架还未降落的飞机,检查其是否能在其最晚降落时间(
t + d)之前开始降落。 - 如果可以,标记该飞机已经降落,并计算其降落完成后的时间
t。 - 递归调用
dfs函数,尝试安排下一架飞机降落。 - 如果递归调用返回
true,说明找到了一种可行的降落顺序,返回true;否则,取消标记,回溯,继续尝试其他飞机。
- 遍历所有飞机,对于每架还未降落的飞机,检查其是否能在其最晚降落时间(
- 参数说明:
-
主函数
main:- 读取测试用例的数量
sum。 - 对于每个测试用例,读取飞机的数量
n,并创建一个存储飞机信息的向量a。 - 初始化所有飞机的降落标记为
false,并读取每架飞机的到达时刻、可盘旋时间和降落所需时间。 - 调用
dfs函数,从第 0 架飞机开始,当前时间为 0,尝试安排飞机降落。 - 根据
dfs函数的返回值输出结果,如果返回true,输出"YES";否则,输出"NO"。
- 读取测试用例的数量
二、广度优先搜索(BFS)
(一)BFS 简介
广度优先搜索是一种用于遍历或搜索树、图等数据结构的算法。它从起始节点开始,按照层次逐层访问节点,先访问距离起始节点近的节点,再依次访问距离更远的节点。
(二)思路介绍
BFS 的核心是利用队列实现层次遍历。将起始节点入队,然后不断从队列中取出节点进行访问,并将其未访问的邻接节点入队。借助队列先进先出的特性,确保节点按距离起始节点的远近顺序被访问。
(三)模板
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
// 二维网格BFS模板示例
const int MAXN = 100;
bool visited[MAXN][MAXN];
int dx[] = {-1, 1, 0, 0};
int dy[] = {0, 0, -1, 1};
struct Node {
int x, y;
int step;
Node(int _x, int _y, int _step) : x(_x), y(_y), step(_step) {}
};
int bfs(int startX, int startY, const vector<vector<int>>& grid) {
int rows = grid.size();
int cols = grid[0].size();
queue<Node> q;
q.push(Node(startX, startY, 0));
visited[startX][startY] = true;
while (!q.empty()) {
Node cur = q.front();
q.pop();
if (cur.x == 目标x && cur.y == 目标y) {
return cur.step;
}
for (int i = 0; i < 4; i++) {
int newX = cur.x + dx[i];
int newY = cur.y + dy[i];
if (newX >= 0 && newX < rows && newY >= 0 && newY < cols &&!visited[newX][newY]) {
q.push(Node(newX, newY, cur.step + 1));
visited[newX][newY] = true;
}
}
}
return -1; // 未找到目标节点
}(四)真题讲解
(1)AB 路线



-
整体思路
本题要求在 \(N×M\) 的迷宫中,找到从左上角到右下角满足特定字母交替规则(先走 K 个 A 格子、再走 K 个 B 格子交替)的最少步数路径。
由于需要在满足规则的前提下找到最短路径,广度优先搜索(BFS)是合适的算法。BFS 从起点开始,按照层次逐步向外扩展搜索。之所以采用这种方式,是因为 BFS 天然具有按距离起点由近及远的特性,能确保在首次到达终点时得到的就是最少步数路径。
具体操作时,每次从队列中取出一个节点(该节点包含迷宫中的位置信息以及当前已走同类型字母的数量),然后向其上下左右四个方向进行扩展。在扩展过程中,要依次检查新位置是否满足多个条件:首先判断是否越界,若越界则该方向不可行;接着依据当前已走同类型字母的数量与 K 的关系,以及新位置字母与当前位置字母的一致性,判断是否符合字母交替规则;最后检查新位置的状态是否已被访问过,若已访问则说明该路径之前已探索过,无需重复。若新位置满足所有条件,就将其加入队列继续后续搜索。持续这个过程,直到找到终点(此时得到的步数就是最少步数),或者队列为空(表示无法到达终点,输出\(-1\) ) 。
-
代码示例:
#include<bits/stdc++.h> using namespace std; // dis[i][j][k] 表示走到坐标 (i, j) 且当前已走了 k 个同类型字母时的总步数 long long dis[1001][1001][11]; // vis[i][j][k] 表示坐标 (i, j) 且当前已走了 k 个同类型字母的状态是否被访问过 long long vis[1001][1001][11]; // direction 存储上下左右四个方向的坐标偏移量 int direction[4][2] = { {-1, 0}, {0, 1}, {1, 0}, {0, -1} }; // arr[i][j] 存储迷宫中坐标 (i, j) 位置的字母('A' 或 'B') char arr[1001][1001]; // 定义节点结构体,用于表示迷宫中的位置以及已走同类型字母的数量 struct node { int x, y, cnt; }; queue<node> qq; // 用于 BFS 的队列 int main() { int n, m, k; cin >> n >> m >> k; for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cin >> arr[i][j]; } } node next; next.x = 0; next.y = 0; next.cnt = 1; vis[0][0][1] = 1; // 起点标记为已访问,且已走 1 个 A 字母(因为起点保证是 A 格子) qq.push(next); while (!qq.empty()) { node now = qq.front(); qq.pop(); for (int i = 0; i < 4; i++) { int newX = now.x + direction[i][0]; int newY = now.y + direction[i][1]; int newCnt = now.cnt + 1; // 检查新位置是否越界,越界则跳过本次循环 if (newX < 0 || newX >= m || newY < 0 || newY >= n) { continue; } else { // 如果当前已走同类型字母数达到 k if (newCnt > k) { // 如果新位置字母和当前位置字母相同,则不符合规则,跳过 if (arr[now.x][now.y] == arr[newX][newY]) { continue; } else { // 否则重置已走同类型字母数为 1 newCnt = 1; } } else { // 如果当前已走同类型字母数未达到 k,新位置字母和当前位置字母不同则不符合规则,跳过 if (arr[now.x][now.y] != arr[newX][newY]) { continue; } } // 如果新位置的状态已被访问过,则跳过 if (vis[newX][newY][newCnt] != 0) { continue; } else { vis[newX][newY][newCnt] = 1; } // 更新新位置的总步数为当前位置总步数加 1 dis[newX][newY][newCnt] = dis[now.x][now.y][now.cnt] + 1; // 如果到达右下角,则输出总步数并结束程序 if (newX == m - 1 && newY == n - 1) { cout << dis[newX][newY][newCnt]; return 0; } node newNode; newNode.cnt = newCnt; newNode.x = newX; newNode.y = newY; qq.push(newNode); } } } // 如果循环结束还未找到路径,输出 -1 cout << -1; return 0; }具体步骤及代码对应解释
- 初始化:
- 读取迷宫的行数
n、列数m以及每次需要连续走的同类型字母数量k,并读取迷宫中每个位置的字母存储到arr数组中。 - 初始化起点的状态,将起点
(0, 0)标记为已访问(vis[0][0][1] = 1),表示已走 1 个 A 字母(因为起点保证是 A 格子),并将起点相关信息封装成node类型变量next加入队列qq。
- 读取迷宫的行数
- BFS 搜索过程:
- 当队列
qq不为空时,取出队首元素now。 - 对当前位置
now向四个方向进行扩展:- 计算新位置的坐标
newX、newY以及新的已走同类型字母数量newCnt。 - 检查新位置是否越界,若越界则跳过本次循环。
- 根据当前已走同类型字母数量
newCnt与k的关系进行判断:- 若
newCnt > k,则新位置字母必须与当前位置字母不同,否则不符合规则,跳过;若不同则将newCnt重置为 1。 - 若
newCnt <= k,则新位置字母必须与当前位置字母相同,否则不符合规则,跳过。
- 若
- 检查新位置的状态是否已被访问过,若已访问过则跳过。
- 若新位置满足所有条件,则标记其为已访问(
vis[newX][newY][newCnt] = 1),更新其总步数(dis[newX][newY][newCnt] = dis[now.x][now.y][now.cnt] + 1)。 - 若新位置是右下角终点,则输出该位置的总步数并结束程序。
- 将新位置相关信息封装成
node类型变量newNode加入队列qq继续后续搜索。
- 计算新位置的坐标
- 当队列
- 结果输出:如果队列
qq为空时还未找到终点,则输出-1,表示无法到达右下角。
(2)岛屿个数
- 题目链接:https://www.lanqiao.cn/problems/3513/learning/
- 问题描述:



-
整体思路
本题要求判断 N 架飞机能否在只有一条跑道的机场全部安全降落。由于飞机降落顺序存在多种可能性,且每架飞机都有其最晚降落时间(到达时刻 \(T_i\) 加上可盘旋时间 \(D_i\) ),同时跑道同一时间只能供一架飞机降落,这些因素使得问题的解空间是多种飞机降落顺序的组合情况。
深度优先搜索(DFS)算法适用于此类问题。其核心思路是尝试所有可能的飞机降落顺序。从初始状态开始,对于每一个未安排降落的飞机,依次尝试将其安排为下一架降落的飞机。在安排某架飞机降落时,首先判断它能否在最晚降落时间之前开始降落。如果不能,则跳过这架飞机,继续尝试其他未降落的飞机;如果可以,则标记这架飞机已降落,并计算它降落完成后的时间。然后,以这个时间为基础,递归地去安排下一架飞机的降落。
通过不断地递归探索所有可能的降落顺序组合,若能找到一种顺序使得所有飞机都能在其最晚降落时间之前安全降落,就表明存在可行的降落方案;若尝试完所有可能的顺序后,仍无法满足所有飞机安全降落的条件,则说明不存在这样的方案。
- 代码示例:
#include<bits/stdc++.h> using namespace std; // 定义一个二维字符数组来存储地图,这里数组大小固定为100*100 char a[100][100]; // 定义方向数组,分别表示左上、上、右上、左、右、左下、下、右下 8 个方向 int dir[8][2] = { {-1, -1}, {-1, 0}, {-1, 1}, {0, -1}, {0, 1}, {1, -1}, {1, 0}, {1, 1} }; // bfs1函数用于标记外海水区域,将其标记为'2' // i, j 是当前处理的坐标,n, m 是地图的行数和列数 void bfs1(int i, int j, int n, int m) { // 如果当前坐标越界,则直接返回 if (i < 0 || i > n + 1 || j < 0 || j > m + 1) return; // 如果当前位置是海水(字符为'0') if (a[i][j] == '0') { // 将当前位置标记为'2',表示这是外海水区域 a[i][j] = '2'; // 使用for循环遍历8个方向 for (int k = 0; k < 8; ++k) { int new_i = i + dir[k][0]; int new_j = j + dir[k][1]; // 递归地处理当前位置周围的8个方向的位置,如果它们也是海水(字符为'0') if (new_i >= 0 && new_i <= n + 1 && new_j >= 0 && new_j <= m + 1 && a[new_i][new_j] == '0') { bfs1(new_i, new_j, n, m); } } } } // 定义方向数组,分别表示上、左、右、下 4 个方向 int dir2[4][2] = { {-1, 0}, {0, -1}, {0, 1}, {1, 0} }; // bfs2函数用于标记岛屿区域,将其标记为'0' // i, j 是当前处理的坐标,n, m 是地图的行数和列数 void bfs2(int i, int j, int n, int m) { // 如果当前坐标越界,则直接返回 if (i < 1 || i > n || j < 1 || j > m) return; // 如果当前位置是陆地(字符为'1') if (a[i][j] == '1') { // 将当前位置标记为'0',表示这是已经处理过的陆地 a[i][j] = '0'; // 使用for循环遍历4个方向 for (int k = 0; k < 4; ++k) { int new_i = i + dir2[k][0]; int new_j = j + dir2[k][1]; // 递归地处理当前位置周围的4个方向的位置,如果它们也是陆地(字符为'1') if (new_i >= 1 && new_i <= n && new_j >= 1 && new_j <= m && a[new_i][new_j] == '1') { bfs2(new_i, new_j, n, m); } } } } int main() { int sum; // 读取测试用例的数量 cin >> sum; for (int k = 0; k < sum; k++) { int count = 0; // 初始化地图数组,将所有位置设置为'0' for (int i = 0; i < 100; i++) { for (int j = 0; j < 100; j++) { a[i][j] = '0'; } } int n, m; // 读取地图的行数和列数 cin >> n >> m; // 读取并忽略换行符,因为前面读取整数后会在缓冲区留下换行符 cin.get(); for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) // 读取地图中每个位置的字符 cin >> a[i][j]; // 读取并忽略换行符 cin.get(); } // 从坐标(0, 0)开始标记外海水区域 bfs1(0, 0, n, m); for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { // 如果当前位置是'0',则将其改为'1'(因为之前标记外海水可能留下一些'0',需要恢复为陆地) if (a[i][j] == '0') a[i][j] = '1'; } } for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { // 如果当前位置是'1'(表示是未处理的陆地),则进行标记并增加岛屿计数 if (a[i][j] == '1') { count++; bfs2(i, j, n, m); } } } // 输出当前测试用例的岛屿数量 cout << count << endl; } return 0; }具体步骤及代码对应解释
-
数据结构和变量定义:
- 使用二维字符数组
a[100][100]来存储地图信息,其中'0'表示海水,'1'表示陆地。 - 定义了两个方向数组
dir和dir2,dir用于处理外海水区域的 8 个方向(包括斜向),dir2用于处理岛屿区域的 4 个方向(上下左右)。
- 使用二维字符数组
-
输入和初始化:
- 从标准输入读取测试用例的数量
sum。 - 对于每个测试用例:
- 初始化地图数组
a,将所有位置设置为'0'。 - 读取地图的行数
n和列数m。 - 读取地图中每个位置的字符信息存储到
a数组中,同时处理输入缓冲区中的换行符,确保输入的准确性。
- 初始化地图数组
- 从标准输入读取测试用例的数量
-
标记外海水区域(
bfs1函数):- 从地图的左上角坐标
(0, 0)开始调用bfs1函数。 - 在
bfs1函数中,首先检查当前坐标(i, j)是否越界,如果越界则直接返回。 - 如果当前位置是海水(字符为
'0'),将其标记为'2',表示这是外海水区域。 - 使用
for循环遍历 8 个方向,对于每个方向,如果新坐标在地图范围内且也是海水(字符为'0'),则递归调用bfs1函数继续处理该方向的位置,从而实现对外海水区域的标记扩展。
- 从地图的左上角坐标
-
处理剩余陆地并统计岛屿数量:
- 遍历地图,将之前未被标记为外海水的
'0'位置(即可能是内部海水的位置)改为'1',以便后续统计岛屿。 - 再次遍历地图,对于每个字符为
'1'的位置(表示是未处理的陆地),调用bfs2函数,并将岛屿计数count加 1。
- 遍历地图,将之前未被标记为外海水的
-
标记岛屿区域(
bfs2函数):- 在
bfs2函数中,首先检查当前坐标(i, j)是否越界,如果越界则直接返回。 - 如果当前位置是陆地(字符为
'1'),将其标记为'0',表示这是已经处理过的陆地。 - 使用
for循环遍历 4 个方向,对于每个方向,如果新坐标在地图范围内且也是陆地(字符为'1'),则递归调用bfs2函数继续处理该方向的位置,从而实现对岛屿区域的标记扩展,将整个岛屿都标记为'0'。
- 在
-
输出结果:
- 当处理完当前测试用例的地图后,输出岛屿的数量
count。 - 重复上述步骤,处理所有的测试用例。
- 当处理完当前测试用例的地图后,输出岛屿的数量
本题要求判断 N 架飞机能否在只有一条跑道的机场全部安全降落。由于飞机降落顺序存在多种可能性,且每架飞机都有其最晚降落时间(到达时刻 T_i 加上可盘旋时间 D_i),同时跑道同一时间只能供一架飞机降落,这些因素使得问题的解空间是多种飞机降落顺序的组合情况。
三、总结
(一)DFS(深度优先搜索)
- 原理:从初始状态开始,沿着一条路径尽可能地深入探索,直到无法继续或者达到目标状态,然后回溯到上一个节点,继续探索其他路径分支。它通过递归或者栈来实现,在递归实现中,函数不断调用自身深入探索;在栈实现中,将待探索节点压入栈中,按照后进先出原则进行探索。
- 适用场景
- 路径搜索类问题:如 “数字接龙” 问题,在棋盘上寻找满足特定数字序列、格子不重复经过且路径不交叉的路径。由于需要尝试各种可能的路径走向,DFS 能深入探索每一条可能路径,通过不断递归判断是否符合规则,直至找到目标路径或确定不存在。
- 排列组合类问题:像 “飞机降落” 问题,要判断多架飞机在有限跑道下的各种降落顺序是否能满足安全降落条件。DFS 可通过递归尝试不同飞机的降落顺序,对每种顺序进行逻辑判断,穷举所有可能的排列组合情况来确定是否存在可行方案。
- 优点
- 对于某些问题能快速找到解,尤其是在解空间树比较深但分支较少的情况下,能迅速深入找到目标。
- 实现相对简单,递归形式的代码简洁明了,易于理解和编写。
- 缺点
- 可能会陷入无穷递归,需要仔细设置递归终止条件。
- 不一定能找到最优解,它更侧重于找到一个解,而非全局最优。在找到一个解后可能还需要额外的处理来判断是否为最优。
- 当问题规模较大,解空间树很庞大时,可能会因为深度过深而导致栈溢出等问题。
(二)BFS(广度优先搜索)
- 原理:从起始节点开始,按照层次依次访问与当前节点相邻的节点,先访问距离起始节点近的节点,再访问距离更远的节点。通过队列来实现,将起始节点放入队列,每次从队列中取出节点进行扩展,将其相邻且未访问过的节点加入队列。
- 适用场景
- 最短路径类问题:例如 “AB 路线” 问题,在迷宫中寻找满足特定字母交替规则的最短路径。BFS 按层次搜索的特性保证了首次到达目标节点的路径就是最短路径,避免了像 DFS 那样可能会深入探索较长的非最优路径。
- 连通区域问题:如 “岛屿个数” 问题,用于标记和统计地图中的连通区域(岛屿)。通过从边界或特定起始点开始,利用 BFS 逐层扩展标记相邻的同类型区域,能高效地统计出连通区域的数量。
- 优点
- 能保证找到最短路径(在无权图或边权相同的图中),这是其在路径搜索问题上的重要优势。
- 对于一些规模较大但层次结构明显的问题,能更均衡地探索解空间,避免因深度过深而导致的问题。
- 缺点
- 空间复杂度较高,因为需要维护一个队列来存储待访问节点,当问题规模较大时,队列可能会占用大量内存。
- 对于某些解在较深层次的问题,可能会在浅层浪费大量时间和空间进行搜索,效率不如 DFS。
(三)两者对比与选择
- 对比:DFS 更注重深入探索一条路径,适合在复杂的路径选择和排列组合场景中寻找可行解;BFS 则侧重于按层次遍历,在寻找最短路径和处理连通区域问题上表现出色。DFS 通常使用递归或栈,空间消耗可能随着递归深度增加而增大;BFS 使用队列,空间消耗主要取决于队列中节点的数量。
- 选择:当问题关注是否存在某种方案,且解空间树分支较多、深度较深时,优先考虑 DFS;当问题需要求解最短路径、最小步数或者统计连通区域数量等,BFS 是更合适的选择。但在实际应用中,有时也会根据具体问题对两种算法进行变形或结合使用,以达到更好的解决效果。