通常面试或者学习redis涉及到的redis缓存三大问题为缓存击穿、缓存穿透以及缓存雪崩。
下面就逐一讲解什么是缓存击、穿透以及雪崩,附上它们常见的解决方法。
缓存击穿
什么是缓存击穿?
通俗来讲就是部分key过期失效而导致的严重后果。缓存击穿问题也叫热点Key问题,就是⼀个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
解决方案:
1.互斥锁,保证强一致性,但是性能差
简单的来说:
并不是所有的线程都有 “ 资格 ” 去访问数据库,只有持有锁的线程才可以对其进行操作。
不过该操作有一个很明显的问题,就是会出现相互等待的情况
2.逻辑过期,高可用性能优,但不能保证数据绝对一致
不设置TTL
之前所说导致缓存击穿的原因就是该key的TTL到期了,所以我们在这就不设置TTL了,
而是使用一个字段,例如:expire表示过期时间(逻辑上的)。当我们想让它 “ 过期 ” 的时候,
我们可以直接手动将其删除(热点key,即只是在一段时间内,其被访问的频次很高)。
这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
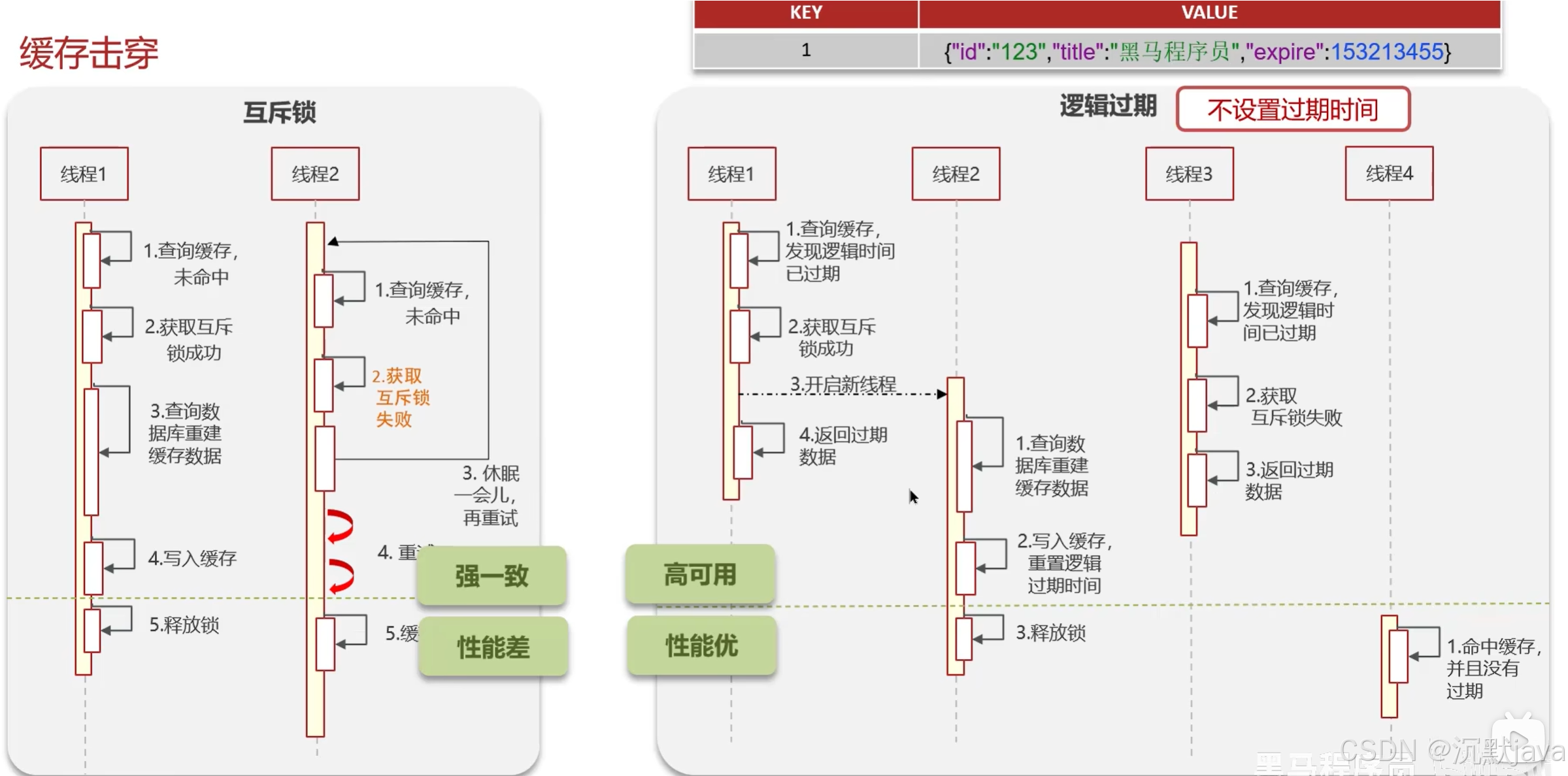
左边就是利用互斥锁来解决,当线程1查询缓存时,发现不存在该key,此时该线程会尝试获取互斥锁,如果获取成功,该线程就会查询数据库并且重建缓存数据,将数据写入缓存,释放锁;如果获取锁失败,意味着此时已经有线程在重建缓存,那么该线程需要不断等待重试,直到线程1重建缓存完成,成功获取缓存的数据。该方法会导致其余线程一直处于阻塞状态,占用大量线程,对cpu的消耗较高,性能低。
右边是利用逻辑过期的策略来解决,会提前给高并发访问量大的key设置一个逻辑过期时间,当有线程来访问数据时,先判断逻辑时间是否过期,如果过期了,该线程就会获取一个互斥锁,并开启一个新的线程,该线程负责查询数据库并进行缓存重建,同时重置逻辑时间,完成后释放锁,在此期间,所有对该key的请求访问的都是没有更新过的数据(包括线程1)。该方法的好处是,缓存中的热点key并不会过期,会一直存在,只是逻辑上设置了一个过期时间,即所有的请求不会未命中,线程不需要阻塞等待,性能比较高,缺点是一旦逻辑时间过期后,所有的请求访问的都是过期数据。因此该方法适用于那些对于数据实时性要求不高的key。
缓存穿透
简单来讲,就是查询一个不存在的数据,mysql查询不到数据库也不会写入缓存,就会导致每次请求都进入数据库,一旦有人通过这些请求恶意攻击,就会导致数据库瘫痪。
解决方案:
1.缓存空对象
当请求访问到一个不存在的数据时,数据库会创建一个null值的对象缓存到缓存中,当下一次有请求访问该key时,就返回空对象。
缺点是可能会导致数据有一段时间的不一致,假设某次访问是对一个商品的数据请求,但是目前该商品并不存在,缓存和数据库都不存在,那么此时,就会返回一个空对象,并设置一个有效时间TTL,但是,某一时刻商家上架了该商品,数据库有该商品的信息,但是缓存中仍然是空对象,此时,新的请求访问的仍然是null值,直到该null值的有效时间过期,再次请求时数据库才会在缓存中缓存新的数据。
优点时该实现比较简单,不需要过多的编码和逻辑。
2.布隆过滤器
在客户端与Redis之间加了一个布隆过滤器,对请求进行过滤。
布隆过滤器的大致原理:布隆过滤器中存放二进制位。
数据库的数据通过hash算法计算其hash值并存放到布隆过滤器中,
之后判断数据是否存在的时候,就是判断该hash值是0还是1。
但是这是一种概率上的统计,当其判断不存在的时候就一定是不存在;
当其判断存在的时候就不一定存在。所以有一定的穿透风险

综上所述,可以两种方法结合一起用,这样比较保险。
缓存穿透的解决方案:
(1)缓存 null 值
(2)布隆过滤
(3)增强 id 的复杂度,避免被猜测 id 规律
(4)做好数据的基础格式校验
(5)加强用户权限校验
(6)做好热点参数的限流
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者redis服务器直接宕机,导致大量请求打到数据库,带来巨大压力。

解决方案
一、给不同的key的TTL添加随机值
操作简单,当我们在做缓存预热的时候,就有可能在同一时间批量插入大量的数据,
那么如果它们的TTL都一样的话就可能出现大量key同时过期的情况!!!
所以我们需要在设置过期时间TTL的时候,定义一个范围,追加该范围内的一个随机数。
二、利用redis集群提高服务的可用性
三、给缓存业务添加降级限流策略 (nginx或spring cloud gateway)
四、给业务添加多级缓存(Guava或Caffeine)
以上就是redis面试的最经典的三大缓存问题,解释以及相关的解决方案。