导航
安装教程导航
Mamba 及 Vim 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(初版)- Linux 下 Mamba 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(重置版)
- Windows 下 Mamba 的安装参看本人博客:Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)
- Linux 下 Vim 安装问题参看本人博客:Linux 下 Vim 环境安装踩坑问题汇总及解决方法(重置版)
- Windows 下 Vim 安装问题参看本人博客:Window 下 Vim 环境安装踩坑问题汇总及解决方法
- Linux 下Vmamba 安装教程参看本人博客:Vmamba 安装教程(无需更改base环境中的cuda版本)
- Windows 下 VMamba的安装参看本人博客:Windows 下 VMamba 安装教程(无需更改base环境中的cuda版本且可加速)
- Windows下 Mamba2及高版本 causal_conv1d 安装参考本人博客:Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)
- Windows 下 Mamba / Vim / Vmamba 环境安装终极版参考本人博客:Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)
- (GPU算力12.0版本)Windows 下 Mamba / Vim / Vmamba 环境配置教程 参考本人博客:Windows 下 Mamba / Vim / Vmamba 环境配置安装教程(适用于5070,5080,5070Ti等GTX 50系显卡)
安装教程及安装包索引
不知道如何入手请先阅读新手索引:Linux / Windows 下 Mamba / Vim / Vmamba 安装教程及安装包索引
本系列教程已接入ima知识库,欢迎在ima小程序里进行提问!(如问题无法解决,安装问题 / 资源售后 / 论文合作想法请+文末vx)
目录
- 导航
- 背景
- 安装步骤
- 出现的问题
-
- 1. 出现 `fatal error C1083: 无法打开包括文件: “nv/target”'`
- 2. 出现 `module 'triton.language.math' has no attribute 'log1p'`
- 3. 出现 selective_scan_backend 有关的 AssertionError
- 4. RuntimeError:CUDA error:no kernel image is available
- 5. ImportError: DLL load failed
- 6. 算力12.0 GPU版本 (20250330更新)
- 7. Mamba2 出现 IndexError: invalid map<K, T> key 或者 IndexError: map::at (20250401更新)
- 后记
背景
在笔者之前的系列博客中,例如 Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0),以及 Window 下 Vim 环境安装踩坑问题汇总及解决方法 遭遇了与 triton 有关的问题,之后在本人博客 Windows 下安装 triton 教程 ,配置 triton-Windows 之后,终于实现了 mamba / vim / vmamba 在Windows下,无需更改重要代码,直接运行程序。本博客安装版本为:mamba_ssm-2.2.2 和 causal_conv1d-1.4.0。CUDA 版本为12.4。
关于 triton 的问题
由于 triton 官方目前只支持Linux,因此在 Windows 系统运行时,函数中只要涉及到其调用都会出现报错,包括但不限于:
KeyError: 'HOME'RuntimeError: failed to find C compiler, Please specify via cc environment variable.
终极解决方案参考Windows 下 Mamba / Vim / Vmamba 环境安装终极版:Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)
即本文在配置 triton-Windows 之后,运行原来的程序将不会出现这些报错。
安装步骤
1. Windows 下前期环境准备
前期环境准备,类似本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)” ,但是由于 triton-Windows 对 CUDA 版本的高要求,所以具体更改为:
conda create -n mamba python=3.10
conda activate mamba
# CUDA 12.4
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
python -c "import torch; print(torch.cuda.is_available())" # 验证torch安装
# 安装cuda
conda install nvidia/label/cuda-12.4.0::cuda-nvcc
pip install setuptools==68.2.2
conda install packaging
2. triton-windows 环境准备
配置参考本人之前博客 Windows 下安装 triton 教程 ,环境要求:torch >= 2.4.0;CUDA >=12;主要是利用大佬的工作:triton-windows。triton 官方目前只支持Linux系统,之前系列博客中安装的 triton 包只是大佬强行打包,配置均在Linux下,无法实现triton 核心的 triton.jit 和 torch.compile 等功能,配置过程包括:
- 安装 MSVC 和 Windows SDK
- 修改环境变量
- vcredist 安装
前期环境都配置无误后,直接下载 whl 安装:
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post5/triton-3.1.0-cp310-cp310-win_amd64.whl
也可手动下载下来然后在下载路径下安装:
pip install triton-3.1.0-cp310-cp310-win_amd64.whl
验证脚本为:
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_elements = output.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta["BLOCK_SIZE"]),)
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
return output
a = torch.rand(3, device="cuda")
b = a + a
b_compiled = add(a, a)
print(b_compiled - b)
print("If you see tensor([0., 0., 0.], device='cuda:0'), then it works")
正常输出结果无报错。如下图所示,不再出现 KeyError: 'HOME' 或者 RuntimeError: failed to find C compiler:

一定要等 triton 配置成功了之后才能进行下面的步骤!
3. 从源码编译causal-conv1d 1.4.0 版本
步骤还是参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”,不过有可能会遭遇问题,需要先
conda install nvidia/label/cuda-12.4.0::cuda-cccl
如果下载缓慢,可以先把安装包下载下来,然后进行本地安装
conda install --use-local cuda-cccl-12.4.99-0.tar.bz2
接着是下载工程文件,即
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
set CAUSAL_CONV1D_FORCE_BUILD=TRUE # 也可修改setup.py第37行
# 先按照博客修改源码然后再执行这最后一步
pip install .
在执行最后一步编译之前,还是需要修改,参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”。
官方没有编译好的适用于Windows版本的 whl,因此需要用上述步骤来手动编译,一般均能安装成功。
此外,笔者编译好了 Windows 下的 (cuda12.4)causal-conv1d-1.4.0-cp310-cp310-win-amd64.whl 或者 优惠地址,亦可直接下载安装(只适用于torch 2.4,cuda12.4,python 3.10,GPU算力6.0-9.0)。(不要急着下,先看完,后面还有全家桶)
pip install causal_conv1d-1.4.0-cp310-cp310-win_amd64.whl
成功安装之后,会在相应虚拟环境中(xxx\conda\envs\xxx\Lib\site-packages\)产生 causal_conv1d_cuda.cp310-win_amd64.pyd 文件,此文件对应 causal_conv1d_cuda 包。
4. 从源码编译 mamba-ssm 版本
前期准备以及部分文件的修改同原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”,具体来说:
1)mamba-ssm 环境准备,下载工程文件,即
git clone https://github.com/state-spaces/mamba.git
cd mamba
set MAMBA_FORCE_BUILD=TRUE # 也可修改setup.py第40行
# 先按照博客修改源码然后再执行这最后一步
pip install . --no-build-isolation
2)在执行最后一步编译之前,还是需要修改,参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”
3)本人编译好的Windows 下的whl 也有:(cuda12.4)mamba-ssm-2.2.2 (只适用于torch 2.4,cuda12.4,python 3.10,GPU算力6.0-9.0)或者 优惠地址 以及【全家桶csdn】 【全家桶优惠】,可直接下载安装。利用 whl 安装命令为:
pip install mamba_ssm-2.2.2-cp310-cp310-win_amd64.whl
由于此时没有绕过selective_scan_cuda,在虚拟环境中(xxx\conda\envs\xxx\Lib\site-packages\)产生了 selective_scan_cuda.cp310-win-amd64.pyd 文件。
5. Mamba 环境运行验证
参考官方的 readme 文件,运行以下示例:
import torch
from mamba_ssm import Mamba
from mamba_ssm import Mamba2
batch, length, dim = 2, 64, 16
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=16, # SSM state expansion factor
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
y = model(x)
assert y.shape == x.shape
print('Mamba:', x.shape)
batch, length, dim = 2, 64, 256
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba2(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=64, # SSM state expansion factor, typically 64 or 128
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
y = model(x)
assert y.shape == x.shape
print('Mamba2:', x.shape)
正常输出结果无报错。如下图所示,不再出现 KeyError: 'HOME' :

6. Windows 下 Vim 的安装
1)Vim 官方代码仓给的 causal-conv1d 源码有误,过于老旧且不兼容,causal-conv1d版本应≥1.1.0,其他部分还是参考原来的博客 Window 下 Vim 环境安装踩坑问题汇总及解决方法:
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
git checkout v1.1.1 # 安装最新版的话,此步可省略
set CAUSAL_CONV1D_FORCE_BUILD=TRUE
pip install .
官方没有编译好的适用于Windows版本的 whl,因此需要用上述步骤来手动编译。笔者编译好了 Windows 下的 (cuda12.4)causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl 或者 优惠地址,亦可直接下载安装(只适用于torch 2.4,cuda12.4,python 3.10,GPU算力6.0-9.0)。
pip install causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl
完成前期工作后进入下一步正式编译。注意安装成功后会在相应环境(xxx\conda\envs\xxx\Lib\site-packages\)中生成 causal_conv1d_cuda.cp310-win_amd64.pyd 文件,此文件对应 causal_conv1d_cuda 包。
2)Vim 官方对 mamba-ssm 的源码进行了修改,所以其与原版有不同,可以直接强行利用Vim的源码进行编译,参考原来的博客 Window 下 Vim 环境安装踩坑问题汇总及解决方法。
本人编译好的Windows 下的适用于Vim的whl 也有:(Vim)(cuda12.4)mamba-ssm-1.1.1-cp310-cp310-win-amd64.whl (只适用于torch 2.4,cuda12.4,python 3.10,GPU算力6.0-9.0)或者 优惠地址 以及【全家桶csdn】 【全家桶优惠】,可直接下载安装。利用 whl 安装命令为:
pip install mamba_ssm-1.1.1-cp310-cp310-win_amd64.whl --no-dependencies causal_conv1d
由于此时没有绕过selective_scan_cuda,在虚拟环境中(xxx\conda\envs\xxx\Lib\site-packages\)产生了 selective-scan-cuda.cp310-win-amd64.pyd 文件,所以运行速度较快。
3)注意在 pip install -r vim/vim_requirements.txt 其他环境时,将 vim/vim_requirements.txt 里面的triton版本注释掉。
7. Vim 环境运行验证
运行以下示例:
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
import torch
import torch.nn as nn
from functools import partial
from torch import Tensor
from typing import Optional
from timm.models.vision_transformer import VisionTransformer, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, lecun_normal_
from timm.models.layers import DropPath, to_2tuple
from timm.models.vision_transformer import _load_weights
import math
from collections import namedtuple
from mamba_ssm.modules.mamba_simple import Mamba
from mamba_ssm.utils.generation import GenerationMixin
from mamba_ssm.utils.hf import load_config_hf, load_state_dict_hf
from rope import *
import random
try:
from mamba_ssm.ops.triton.layernorm import RMSNorm, layer_norm_fn, rms_norm_fn
except ImportError:
RMSNorm, layer_norm_fn, rms_norm_fn = None, None, None
__all__ = [
'vim_tiny_patch16_224', 'vim_small_patch16_224', 'vim_base_patch16_224',
'vim_tiny_patch16_384', 'vim_small_patch16_384', 'vim_base_patch16_384',
]
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, stride=16, in_chans=3, embed_dim=768, norm_layer=None,
flatten=True):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = ((img_size[0] - patch_size[0]) // stride + 1, (img_size[1] - patch_size[1]) // stride + 1)
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({
H}*{
W}) doesn't match model ({
self.img_size[0]}*{
self.img_size[1]})."
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x
class Block(nn.Module):
def __init__(
self, dim, mixer_cls, norm_cls=nn.LayerNorm, fused_add_norm=False, residual_in_fp32=False, drop_path=0.,
):
"""
Simple block wrapping a mixer class with LayerNorm/RMSNorm and residual connection"
This Block has a slightly different structure compared to a regular
prenorm Transformer block.
The standard block is: LN -> MHA/MLP -> Add.
[Ref: https://arxiv.org/abs/2002.04745]
Here we have: Add -> LN -> Mixer, returning both
the hidden_states (output of the mixer) and the residual.
This is purely for performance reasons, as we can fuse add and LayerNorm.
The residual needs to be provided (except for the very first block).
"""
super().__init__()
self.residual_in_fp32 = residual_in_fp32
self.fused_add_norm = fused_add_norm
self.mixer = mixer_cls(dim)
self.norm = norm_cls(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if self.fused_add_norm:
assert RMSNorm is not None, "RMSNorm import fails"
assert isinstance(
self.norm, (nn.LayerNorm, RMSNorm)
), "Only LayerNorm and RMSNorm are supported for fused_add_norm"
def forward(
self, hidden_states: Tensor, residual: Optional[Tensor] = None, inference_params=None
):
r"""Pass the input through the encoder layer.
Args:
hidden_states: the sequence to the encoder layer (required).
residual: hidden_states = Mixer(LN(residual))
"""
if not self.fused_add_norm:
if residual is None:
residual = hidden_states
else:
residual = residual + self.drop_path(hidden_states)
hidden_states = self.norm(residual.to(dtype=self.norm.weight.dtype))
if self.residual_in_fp32:
residual = residual.to(torch.float32)
else:
fused_add_norm_fn = rms_norm_fn if isinstance(self.norm, RMSNorm) else layer_norm_fn
if residual is None:
hidden_states, residual = fused_add_norm_fn(
hidden_states,
self.norm.weight,
self.norm.bias,
residual=residual,
prenorm=True,
residual_in_fp32=self.residual_in_fp32,
eps=self.norm.eps,
)
else:
hidden_states, residual = fused_add_norm_fn(
self.drop_path(hidden_states),
self.norm.weight,
self.norm.bias,
residual=residual,
prenorm=True,
residual_in_fp32=self.residual_in_fp32,
eps=self.norm.eps,
)
hidden_states = self.mixer(hidden_states, inference_params=inference_params)
return hidden_states, residual
def allocate_inference_cache(self, batch_size, max_seqlen, dtype=None, **kwargs):
return self.mixer.allocate_inference_cache(batch_size, max_seqlen, dtype=dtype, **kwargs)
def create_block(
d_model,
ssm_cfg=None,
norm_epsilon=1e-5,
drop_path=0.,
rms_norm=False,
residual_in_fp32=False,
fused_add_norm=False,
layer_idx=None,
device=None,
dtype=None,
if_bimamba=False,
bimamba_type="none",
if_divide_out=False,
init_layer_scale=None,
):
if if_bimamba:
bimamba_type = "v1"
if ssm_cfg is None:
ssm_cfg = {
}
factory_kwargs = {
"device": device, "dtype": dtype}
mixer_cls = partial(Mamba, layer_idx=layer_idx, bimamba_type=bimamba_type, if_divide_out=if_divide_out,
init_layer_scale=init_layer_scale, **ssm_cfg, **factory_kwargs)
norm_cls = partial(
nn.LayerNorm if not rms_norm else RMSNorm, eps=norm_epsilon, **factory_kwargs
)
block = Block(
d_model,
mixer_cls,
norm_cls=norm_cls,
drop_path=drop_path,
fused_add_norm=fused_add_norm,
residual_in_fp32=residual_in_fp32,
)
block.layer_idx = layer_idx
return block
# https://github.com/huggingface/transformers/blob/c28d04e9e252a1a099944e325685f14d242ecdcd/src/transformers/models/gpt2/modeling_gpt2.py#L454
def _init_weights(
module,
n_layer,
initializer_range=0.02, # Now only used for embedding layer.
rescale_prenorm_residual=True,
n_residuals_per_layer=1, # Change to 2 if we have MLP
):
if isinstance(module, nn.Linear):
if module.bias is not None:
if not getattr(module.bias, "_no_reinit", False):
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, std=initializer_range)
if rescale_prenorm_residual:
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
#
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
for name, p in module.named_parameters():
if name in ["out_proj.weight", "fc2.weight"]:
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
# We need to reinit p since this code could be called multiple times
# Having just p *= scale would repeatedly scale it down
nn.init.kaiming_uniform_(p, a=math.sqrt(5))
with torch.no_grad():
p /= math.sqrt(n_residuals_per_layer * n_layer)
def segm_init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
# NOTE conv was left to pytorch default in my original init
lecun_normal_(m.weight)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm, nn.BatchNorm2d)):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
class VisionMamba(nn.Module):
def __init__(self,
img_size=224,
patch_size=16,
stride=16,
depth=24,
embed_dim=192,
channels=3,
num_classes=1000,
ssm_cfg=None,
drop_rate=0.,
drop_path_rate=0.1,
norm_epsilon: float = 1e-5,
rms_norm: bool = False,
initializer_cfg=None,
fused_add_norm=False,
residual_in_fp32=False,
device=None,
dtype=None,
ft_seq_len=None,
pt_hw_seq_len=14,
if_bidirectional=False,
final_pool_type='none',
if_abs_pos_embed=False,
if_rope=False,
if_rope_residual=False,
flip_img_sequences_ratio=-1.,
if_bimamba=False,
bimamba_type="none",
if_cls_token=False,
if_divide_out=False,
init_layer_scale=None,
use_double_cls_token=False,
use_middle_cls_token=False,
**kwargs):
factory_kwargs = {
"device": device, "dtype": dtype}
# add factory_kwargs into kwargs
kwargs.update(factory_kwargs)
super().__init__()
self.residual_in_fp32 = residual_in_fp32
self.fused_add_norm = fused_add_norm
self.if_bidirectional = if_bidirectional
self.final_pool_type = final_pool_type
self.if_abs_pos_embed = if_abs_pos_embed
self.if_rope = if_rope
self.if_rope_residual = if_rope_residual
self.flip_img_sequences_ratio = flip_img_sequences_ratio
self.if_cls_token = if_cls_token
self.use_double_cls_token = use_double_cls_token
self.use_middle_cls_token = use_middle_cls_token
self.num_tokens = 1 if if_cls_token else 0
# pretrain parameters
self.num_classes = num_classes
self.d_model = self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, stride=stride, in_chans=channels, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
if if_cls_token:
if use_double_cls_token:
self.cls_token_head = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
self.cls_token_tail = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
self.num_tokens = 2
else:
self.cls_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
# self.num_tokens = 1
if if_abs_pos_embed:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, self.embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
if if_rope:
half_head_dim = embed_dim // 2
hw_seq_len = img_size // patch_size
self.rope = VisionRotaryEmbeddingFast(
dim=half_head_dim,
pt_seq_len=pt_hw_seq_len,
ft_seq_len=hw_seq_len
)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
# TODO: release this comment
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
# import ipdb;ipdb.set_trace()
inter_dpr = [0.0] + dpr
self.drop_path = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
# transformer blocks
self.layers = nn.ModuleList(
[
create_block(
embed_dim,
ssm_cfg=ssm_cfg,
norm_epsilon=norm_epsilon,
rms_norm=rms_norm,
residual_in_fp32=residual_in_fp32,
fused_add_norm=fused_add_norm,
layer_idx=i,
if_bimamba=if_bimamba,
bimamba_type=bimamba_type,
drop_path=inter_dpr[i],
if_divide_out=if_divide_out,
init_layer_scale=init_layer_scale,
**factory_kwargs,
)
for i in range(depth)
]
)
# output head
self.norm_f = (nn.LayerNorm if not rms_norm else RMSNorm)(
embed_dim, eps=norm_epsilon, **factory_kwargs
)
# self.pre_logits = nn.Identity()
# original init
self.patch_embed.apply(segm_init_weights)
self.head.apply(segm_init_weights)
if if_abs_pos_embed:
trunc_normal_(self.pos_embed, std=.02)
if if_cls_token:
if use_double_cls_token:
trunc_normal_(self.cls_token_head, std=.02)
trunc_normal_(self.cls_token_tail, std=.02)
else:
trunc_normal_(self.cls_token, std=.02)
# mamba init
self.apply(
partial(
_init_weights,
n_layer=depth,
**(initializer_cfg if initializer_cfg is not None else {
}),
)
)
def allocate_inference_cache(self, batch_size, max_seqlen, dtype=None, **kwargs):
return {
i: layer.allocate_inference_cache(batch_size, max_seqlen, dtype=dtype, **kwargs)
for i, layer in enumerate(self.layers)
}
@torch.jit.ignore
def no_weight_decay(self):
return {
"pos_embed", "cls_token", "dist_token", "cls_token_head", "cls_token_tail"}
@torch.jit.ignore()
def load_pretrained(self, checkpoint_path, prefix=""):
_load_weights(self, checkpoint_path, prefix)
def forward_features(self, x, inference_params=None, if_random_cls_token_position=False,
if_random_token_rank=False):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add the dist_token
x = self.patch_embed(x)
B, M, _ = x.shape
if self.if_cls_token:
if self.use_double_cls_token:
cls_token_head = self.cls_token_head.expand(B, -1, -1)
cls_token_tail = self.cls_token_tail.expand(B, -1, -1)
token_position = [0, M + 1]
x = torch.cat((cls_token_head, x, cls_token_tail), dim=1)
M = x.shape[1]
else:
if self.use_middle_cls_token:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = M // 2
# add cls token in the middle
x = torch.cat((x[:, :token_position, :], cls_token, x[:, token_position:, :]), dim=1)
elif if_random_cls_token_position:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = random.randint(0, M)
x = torch.cat((x[:, :token_position, :], cls_token, x[:, token_position:, :]), dim=1)
print("token_position: ", token_position)
else:
cls_token = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
token_position = 0
x = torch.cat((cls_token, x), dim=1)
M = x.shape[1]
if self.if_abs_pos_embed:
# if new_grid_size[0] == self.patch_embed.grid_size[0] and new_grid_size[1] == self.patch_embed.grid_size[1]:
# x = x + self.pos_embed
# else:
# pos_embed = interpolate_pos_embed_online(
# self.pos_embed, self.patch_embed.grid_size, new_grid_size,0
# )
x = x + self.pos_embed
x = self.pos_drop(x)
if if_random_token_rank:
# 生成随机 shuffle 索引
shuffle_indices = torch.randperm(M)
if isinstance(token_position, list):
print("original value: ", x[0, token_position[0], 0], x[0, token_position[1], 0])
else:
print("original value: ", x[0, token_position, 0])
print("original token_position: ", token_position)
# 执行 shuffle
x = x[:, shuffle_indices, :]
if isinstance(token_position, list):
# 找到 cls token 在 shuffle 之后的新位置
new_token_position = [torch.where(shuffle_indices == token_position[i])[0].item() for i in
range(len(token_position))]
token_position = new_token_position
else:
# 找到 cls token 在 shuffle 之后的新位置
token_position = torch.where(shuffle_indices == token_position)[0].item()
if isinstance(token_position, list):
print("new value: ", x[0, token_position[0], 0], x[0, token_position[1], 0])
else:
print("new value: ", x[0, token_position, 0])
print("new token_position: ", token_position)
if_flip_img_sequences = False
if self.flip_img_sequences_ratio > 0 and (self.flip_img_sequences_ratio - random.random()) > 1e-5:
x = x.flip([1])
if_flip_img_sequences = True
# mamba impl
residual = None
hidden_states = x
if not self.if_bidirectional:
for layer in self.layers:
if if_flip_img_sequences and self.if_rope:
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
# rope about
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residual:
residual = self.rope(residual)
if if_flip_img_sequences and self.if_rope:
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
hidden_states, residual = layer(
hidden_states, residual, inference_params=inference_params
)
else:
# get two layers in a single for-loop
for i in range(len(self.layers) // 2):
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residual:
residual = self.rope(residual)
hidden_states_f, residual_f = self.layers[i * 2](
hidden_states, residual, inference_params=inference_params
)
hidden_states_b, residual_b = self.layers[i * 2 + 1](
hidden_states.flip([1]), None if residual == None else residual.flip([1]),
inference_params=inference_params
)
hidden_states = hidden_states_f + hidden_states_b.flip([1])
residual = residual_f + residual_b.flip([1])
if not self.fused_add_norm:
if residual is None:
residual = hidden_states
else:
residual = residual + self.drop_path(hidden_states)
hidden_states = self.norm_f(residual.to(dtype=self.norm_f.weight.dtype))
else:
# Set prenorm=False here since we don't need the residual
fused_add_norm_fn = rms_norm_fn if isinstance(self.norm_f, RMSNorm) else layer_norm_fn
hidden_states = fused_add_norm_fn(
self.drop_path(hidden_states),
self.norm_f.weight,
self.norm_f.bias,
eps=self.norm_f.eps,
residual=residual,
prenorm=False,
residual_in_fp32=self.residual_in_fp32,
)
# return only cls token if it exists
if self.if_cls_token:
if self.use_double_cls_token:
return (hidden_states[:, token_position[0], :] + hidden_states[:, token_position[1], :]) / 2
else:
if self.use_middle_cls_token:
return hidden_states[:, token_position, :]
elif if_random_cls_token_position:
return hidden_states[:, token_position, :]
else:
return hidden_states[:, token_position, :]
if self.final_pool_type == 'none':
return hidden_states[:, -1, :]
elif self.final_pool_type == 'mean':
return hidden_states.mean(dim=1)
elif self.final_pool_type == 'max':
return hidden_states
elif self.final_pool_type == 'all':
return hidden_states
else:
raise NotImplementedError
def forward(self, x, return_features=False, inference_params=None, if_random_cls_token_position=False,
if_random_token_rank=False):
x = self.forward_features(x, inference_params, if_random_cls_token_position=if_random_cls_token_position,
if_random_token_rank=if_random_token_rank)
# if return_features:
# return x
# x = self.head(x)
# if self.final_pool_type == 'max':
# x = x.max(dim=1)[0]
return x
@register_model
def vim_tiny_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False, **kwargs):
model = VisionMamba(
patch_size=16, embed_dim=192, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True,
final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2",
if_cls_token=True, if_divide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_tiny_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False,
**kwargs):
model = VisionMamba(
patch_size=16, stride=8, embed_dim=192, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True,
final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2",
if_cls_token=True, if_divide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_small_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False, **kwargs):
model = VisionMamba(
patch_size=16, embed_dim=384, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True,
final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2",
if_cls_token=True, if_divide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def vim_small_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(pretrained=False,
**kwargs):
model = VisionMamba(
patch_size=16, stride=8, embed_dim=384, depth=24, rms_norm=True, residual_in_fp32=True, fused_add_norm=True,
final_pool_type='mean', if_abs_pos_embed=True, if_rope=False, if_rope_residual=False, bimamba_type="v2",
if_cls_token=True, if_divide_out=True, use_middle_cls_token=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="to.do",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
if __name__ == '__main__':
# cuda or cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 实例化模型得到分类结果
inputs = torch.randn(1, 3, 224, 224).to(device)
model = vim_small_patch16_stride8_224_bimambav2_final_pool_mean_abs_pos_embed_with_midclstok_div2(
pretrained=False).to(device)
# print(model)
outputs = model(inputs)
print(outputs.shape)
# 实例化mamba模块,输入输出特征维度不变 B C H W
x = torch.rand(10, 16, 64, 128).to(device)
B, C, H, W = x.shape
print("输入特征维度:", x.shape)
x = x.view(B, C, H * W).permute(0, 2, 1)
print("维度变换:", x.shape)
mamba = create_block(d_model=C).to(device)
# mamba模型代码中返回的是一个元组:hidden_states, residual
hidden_states, residual = mamba(x)
x = hidden_states.permute(0, 2, 1).view(B, C, H, W)
print("输出特征维度:", x.shape)
正常输出结果无报错。如下图所示,不再出现 KeyError: 'HOME' 或者 RuntimeError: failed to find C compiler:

8. Windows 下 Vmamba 的安装
依旧参考原来的博客:Windows 下 VMamba 安装教程(无需更改base环境中的cuda版本且可加速) 。
Win 下面编译好的 whl (只适用于torch 2.4,cuda12.4,python 3.10,GPU算力8.9)为:(cuda12.4)selective-scan-0.0.2-cp310-cp310-win-amd64.whl(包含core) 或者 mbd优惠地址,相应生成的selective_scan_cuda_core 模块为:selective-scan-cuda-core.cp310-win-amd64.pyd;selective-scan-cuda-oflex.cp310-win-amd64.pyd。
注意,上面的包仅适用于算力为 8.9 的GPU设备, 包括 GeForce RTX 4050 ~ 4090,其他型号不要下载,有可能会报错!算力查询参考:Your GPU Compute Capability。
版本更新
应部分同学需求,通用算力版(cuda12.4)编译好的 whl (只适用于torch 2.4,cuda12.4,python 3.10,GPU算力6.0-9.0)为:通用算力版(cuda12.4)selective-scan-0.0.2-cp310-cp310-win-amd64.whl(包含core) 或者 mbd优惠地址,相应生成的selective_scan_cuda_core 模块为:selective-scan-cuda-core.cp310-win-amd64.pyd;selective-scan-cuda-oflex.cp310-win-amd64.pyd。
9. Vmamba 环境运行验证
在classification/models/vmamba.py最后添加:
if __name__ == '__main__':
device = torch.device("cuda:0")
hidden_dim = 3
network = VSSM(hidden_dim).to('cuda:0')
input_image = torch.randn(1, 3, 224, 224)
input_image = input_image.to(device)
output = network(input_image)
print("Output shape:", output.shape)
并修改509行的assert selective_scan_backend in [None, "oflex", "mamba", "torch"]为 assert selective_scan_backend in [None, "oflex", "mamba", "torch", "core"],即:
import os
import time
import math
import copy
from functools import partial
from typing import Optional, Callable, Any
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, trunc_normal_
from fvcore.nn import FlopCountAnalysis, flop_count_str, flop_count, parameter_count
DropPath.__repr__ = lambda self: f"timm.DropPath({
self.drop_prob})"
# train speed is slower after enabling this opts.
# torch.backends.cudnn.enabled = True
# torch.backends.cudnn.benchmark = True
# torch.backends.cudnn.deterministic = True
try:
from .csm_triton import cross_scan_fn, cross_merge_fn
except:
from csm_triton import cross_scan_fn, cross_merge_fn
try:
from .csms6s import selective_scan_fn, selective_scan_flop_jit
except:
from csms6s import selective_scan_fn, selective_scan_flop_jit
# FLOPs counter not prepared fro mamba2
try:
from .mamba2.ssd_minimal import selective_scan_chunk_fn
except:
from mamba2.ssd_minimal import selective_scan_chunk_fn
# =====================================================
# we have this class as linear and conv init differ from each other
# this function enable loading from both conv2d or linear
class Linear2d(nn.Linear):
def forward(self, x: torch.Tensor):
# B, C, H, W = x.shape
return F.conv2d(x, self.weight[:, :, None, None], self.bias)
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
state_dict[prefix + "weight"] = state_dict[prefix + "weight"].view(self.weight.shape)
return super()._load_from_state_dict(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
class LayerNorm2d(nn.LayerNorm):
def forward(self, x: torch.Tensor):
x = x.permute(0, 2, 3, 1)
x = nn.functional.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
x = x.permute(0, 3, 1, 2)
return x
class PatchMerging2D(nn.Module):
def __init__(self, dim, out_dim=-1, norm_layer=nn.LayerNorm, channel_first=False):
super().__init__()
self.dim = dim
Linear = Linear2d if channel_first else nn.Linear
self._patch_merging_pad = self._patch_merging_pad_channel_first if channel_first else self._patch_merging_pad_channel_last
self.reduction = Linear(4 * dim, (2 * dim) if out_dim < 0 else out_dim, bias=False)
self.norm = norm_layer(4 * dim)
@staticmethod
def _patch_merging_pad_channel_last(x: torch.Tensor):
H, W, _ = x.shape[-3:]
if (W % 2 != 0) or (H % 2 != 0):
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[..., 0::2, 0::2, :] # ... H/2 W/2 C
x1 = x[..., 1::2, 0::2, :] # ... H/2 W/2 C
x2 = x[..., 0::2, 1::2, :] # ... H/2 W/2 C
x3 = x[..., 1::2, 1::2, :] # ... H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # ... H/2 W/2 4*C
return x
@staticmethod
def _patch_merging_pad_channel_first(x: torch.Tensor):
H, W = x.shape[-2:]
if (W % 2 != 0) or (H % 2 != 0):
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[..., 0::2, 0::2] # ... H/2 W/2
x1 = x[..., 1::2, 0::2] # ... H/2 W/2
x2 = x[..., 0::2, 1::2] # ... H/2 W/2
x3 = x[..., 1::2, 1::2] # ... H/2 W/2
x = torch.cat([x0, x1, x2, x3], 1) # ... H/2 W/2 4*C
return x
def forward(self, x):
x = self._patch_merging_pad(x)
x = self.norm(x)
x = self.reduction(x)
return x
class Permute(nn.Module):
def __init__(self, *args):
super().__init__()
self.args = args
def forward(self, x: torch.Tensor):
return x.permute(*self.args)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.,channels_first=False):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
Linear = Linear2d if channels_first else nn.Linear
self.fc1 = Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class gMlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.,channels_first=False):
super().__init__()
self.channel_first = channels_first
out_features = out_features or in_features
hidden_features = hidden_features or in_features
Linear = Linear2d if channels_first else nn.Linear
self.fc1 = Linear(in_features, 2 * hidden_features)
self.act = act_layer()
self.fc2 = Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x: torch.Tensor):
x = self.fc1(x)
x, z = x.chunk(2, dim=(1 if self.channel_first else -1))
x = self.fc2(x * self.act(z))
x = self.drop(x)
return x
class SoftmaxSpatial(nn.Softmax):
def forward(self, x: torch.Tensor):
if self.dim == -1:
B, C, H, W = x.shape
return super().forward(x.view(B, C, -1)).view(B, C, H, W)
elif self.dim == 1:
B, H, W, C = x.shape
return super().forward(x.view(B, -1, C)).view(B, H, W, C)
else:
raise NotImplementedError
# =====================================================
class mamba_init:
@staticmethod
def dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4):
dt_proj = nn.Linear(dt_rank, d_inner, bias=True)
# Initialize special dt projection to preserve variance at initialization
dt_init_std = dt_rank**-0.5 * dt_scale
if dt_init == "constant":
nn.init.constant_(dt_proj.weight, dt_init_std)
elif dt_init == "random":
nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)
else:
raise NotImplementedError
# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_max
dt = torch.exp(
torch.rand(d_inner) * (math.log(dt_max) - math.log(dt_min))
+ math.log(dt_min)
).clamp(min=dt_init_floor)
# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
inv_dt = dt + torch.log(-torch.expm1(-dt))
with torch.no_grad():
dt_proj.bias.copy_(inv_dt)
# Our initialization would set all Linear.bias to zero, need to mark this one as _no_reinit
# dt_proj.bias._no_reinit = True
return dt_proj
@staticmethod
def A_log_init(d_state, d_inner, copies=-1, device=None, merge=True):
# S4D real initialization
A = torch.arange(1, d_state + 1, dtype=torch.float32, device=device).view(1, -1).repeat(d_inner, 1).contiguous()
A_log = torch.log(A) # Keep A_log in fp32
if copies > 0:
A_log = A_log[None].repeat(copies, 1, 1).contiguous()
if merge:
A_log = A_log.flatten(0, 1)
A_log = nn.Parameter(A_log)
A_log._no_weight_decay = True
return A_log
@staticmethod
def D_init(d_inner, copies=-1, device=None, merge=True):
# D "skip" parameter
D = torch.ones(d_inner, device=device)
if copies > 0:
D = D[None].repeat(copies, 1).contiguous()
if merge:
D = D.flatten(0, 1)
D = nn.Parameter(D) # Keep in fp32
D._no_weight_decay = True
return D
@classmethod
def init_dt_A_D(cls, d_state, dt_rank, d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, k_group=4):
# dt proj ============================
dt_projs = [
cls.dt_init(dt_rank, d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor)
for _ in range(k_group)
]
dt_projs_weight = nn.Parameter(torch.stack([t.weight for t in dt_projs], dim=0)) # (K, inner, rank)
dt_projs_bias = nn.Parameter(torch.stack([t.bias for t in dt_projs], dim=0)) # (K, inner)
del dt_projs
# A, D =======================================
A_logs = cls.A_log_init(d_state, d_inner, copies=k_group, merge=True) # (K * D, N)
Ds = cls.D_init(d_inner, copies=k_group, merge=True) # (K * D)
return A_logs, Ds, dt_projs_weight, dt_projs_bias
# support: v0, v0seq
class SS2Dv0:
def __initv0__(
self,
# basic dims ===========
d_model=96,
d_state=16,
ssm_ratio=2.0,
dt_rank="auto",
# ======================
dropout=0.0,
# ======================
seq=False,
force_fp32=True,
**kwargs,
):
if "channel_first" in kwargs:
assert not kwargs["channel_first"]
act_layer = nn.SiLU
dt_min = 0.001
dt_max = 0.1
dt_init = "random"
dt_scale = 1.0
dt_init_floor = 1e-4
bias = False
conv_bias = True
d_conv = 3
k_group = 4
factory_kwargs = {
"device": None, "dtype": None}
super().__init__()
d_inner = int(ssm_ratio * d_model)
dt_rank = math.ceil(d_model / 16) if dt_rank == "auto" else dt_rank
self.forward = self.forwardv0
if seq:
self.forward = partial(self.forwardv0, seq=True)
if not force_fp32:
self.forward = partial(self.forwardv0, force_fp32=False)
# in proj ============================
self.in_proj = nn.Linear(d_model, d_inner * 2, bias=bias)
self.act: nn.Module = act_layer()
self.conv2d = nn.Conv2d(
in_channels=d_inner,
out_channels=d_inner,
groups=d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
)
# x proj ============================
self.x_proj = [
nn.Linear(d_inner, (dt_rank + d_state * 2), bias=False)
for _ in range(k_group)
]
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K, N, inner)
del self.x_proj
# dt proj, A, D ============================
self.A_logs, self.Ds, self.dt_projs_weight, self.dt_projs_bias = mamba_init.init_dt_A_D(
d_state, dt_rank, d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, k_group=4,
)
# out proj =======================================
self.out_norm = nn.LayerNorm(d_inner)
self.out_proj = nn.Linear(d_inner, d_model, bias=bias)
self.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()
def forwardv0(self, x: torch.Tensor, seq=False, force_fp32=True, **kwargs):
x = self.in_proj(x)
x, z = x.chunk(2, dim=-1) # (b, h, w, d)
z = self.act(z)
x = x.permute(0, 3, 1, 2).contiguous()
x = self.conv2d(x) # (b, d, h, w)
x = self.act(x)
selective_scan = partial(selective_scan_fn, backend="mamba")
B, D, H, W = x.shape
D, N = self.A_logs.shape
K, D, R = self.dt_projs_weight.shape
L = H * W
x_hwwh = torch.stack([x.view(B, -1, L), torch.transpose(x, dim0=2, dim1=3).contiguous().view(B, -1, L)], dim=1).view(B, 2, -1, L)
xs = torch.cat([x_hwwh, torch.flip(x_hwwh, dims=[-1])], dim=1) # (b, k, d, l)
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, self.x_proj_weight)
if hasattr(self, "x_proj_bias"):
x_dbl = x_dbl + self.x_proj_bias.view(1, K, -1, 1)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts, self.dt_projs_weight)
xs = xs.view(B, -1, L) # (b, k * d, l)
dts = dts.contiguous().view(B, -1, L) # (b, k * d, l)
Bs = Bs.contiguous() # (b, k, d_state, l)
Cs = Cs.contiguous() # (b, k, d_state, l)
As = -self.A_logs.float().exp() # (k * d, d_state)
Ds = self.Ds.float() # (k * d)
dt_projs_bias = self.dt_projs_bias.float().view(-1) # (k * d)
# assert len(xs.shape) == 3 and len(dts.shape) == 3 and len(Bs.shape) == 4 and len(Cs.shape) == 4
# assert len(As.shape) == 2 and len(Ds.shape) == 1 and len(dt_projs_bias.shape) == 1
to_fp32 = lambda *args: (_a.to(torch.float32) for _a in args)
if force_fp32:
xs, dts, Bs, Cs = to_fp32(xs, dts, Bs, Cs)
if seq:
out_y = []
for i in range(4):
yi = selective_scan(
xs.view(B, K, -1, L)[:, i], dts.view(B, K, -1, L)[:, i],
As.view(K, -1, N)[i], Bs[:, i].unsqueeze(1), Cs[:, i].unsqueeze(1), Ds.view(K, -1)[i],
delta_bias=dt_projs_bias.view(K, -1)[i],
delta_softplus=True,
).view(B, -1, L)
out_y.append(yi)
out_y = torch.stack(out_y, dim=1)
else:
out_y = selective_scan(
xs, dts,
As, Bs, Cs, Ds,
delta_bias=dt_projs_bias,
delta_softplus=True,
).view(B, K, -1, L)
assert out_y.dtype == torch.float
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), dim0=2, dim1=3).contiguous().view(B, -1, L)
y = out_y[:, 0] + inv_y[:, 0] + wh_y + invwh_y
y = y.transpose(dim0=1, dim1=2).contiguous() # (B, L, C)
y = self.out_norm(y).view(B, H, W, -1)
y = y * z
out = self.dropout(self.out_proj(y))
return out
# support: v01-v05; v051d,v052d,v052dc;
# postfix: _onsigmoid,_onsoftmax,_ondwconv3,_onnone;_nozact,_noz;_oact;_no32;
# history support: v2,v3;v31d,v32d,v32dc;
class SS2Dv2:
def __initv2__(
self,
# basic dims ===========
d_model=96,
d_state=16,
ssm_ratio=2.0,
dt_rank="auto",
act_layer=nn.SiLU,
# dwconv ===============
d_conv=3, # < 2 means no conv
conv_bias=True,
# ======================
dropout=0.0,
bias=False,
# dt init ==============
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
initialize="v0",
# ======================
forward_type="v2",
channel_first=False,
# ======================
**kwargs,
):
factory_kwargs = {
"device": None, "dtype": None}
super().__init__()
self.k_group = 4
self.d_model = int(d_model)
self.d_state = int(d_state)
self.d_inner = int(ssm_ratio * d_model)
self.dt_rank = int(math.ceil(self.d_model / 16) if dt_rank == "auto" else dt_rank)
self.channel_first = channel_first
self.with_dconv = d_conv > 1
Linear = Linear2d if channel_first else nn.Linear
self.forward = self.forwardv2
# tags for forward_type ==============================
checkpostfix = self.checkpostfix
self.disable_force32, forward_type = checkpostfix("_no32", forward_type)
self.oact, forward_type = checkpostfix("_oact", forward_type)
self.disable_z, forward_type = checkpostfix("_noz", forward_type)
self.disable_z_act, forward_type = checkpostfix("_nozact", forward_type)
self.out_norm, forward_type = self.get_outnorm(forward_type, self.d_inner, channel_first)
# forward_type debug =======================================
FORWARD_TYPES = dict(
v01=partial(self.forward_corev2, force_fp32=(not self.disable_force32), selective_scan_backend="mamba", scan_force_torch=True),
v02=partial(self.forward_corev2, force_fp32=(not self.disable_force32), selective_scan_backend="mamba"),
v03=partial(self.forward_corev2, force_fp32=(not self.disable_force32), selective_scan_backend="oflex"),
v04=partial(self.forward_corev2, force_fp32=False), # selective_scan_backend="oflex", scan_mode="cross2d"
v05=partial(self.forward_corev2, force_fp32=False, no_einsum=True), # selective_scan_backend="oflex", scan_mode="cross2d"
# ===============================
v051d=partial(self.forward_corev2, force_fp32=False, no_einsum=True, scan_mode="unidi"),
v052d=partial(self.forward_corev2, force_fp32=False, no_einsum=True, scan_mode="bidi"),
v052dc=partial(self.forward_corev2, force_fp32=False, no_einsum=True, scan_mode="cascade2d"),
v052d3=partial(self.forward_corev2, force_fp32=False, no_einsum=True, scan_mode=3), # debug
# ===============================
v2=partial(self.forward_corev2, force_fp32=(not self.disable_force32), selective_scan_backend="core"),
v3=partial(self.forward_corev2, force_fp32=False, selective_scan_backend="oflex"),
)
self.forward_core = FORWARD_TYPES.get(forward_type, None)
# in proj =======================================
d_proj = self.d_inner if self.disable_z else (self.d_inner * 2)
self.in_proj = Linear(self.d_model, d_proj, bias=bias)
self.act: nn.Module = act_layer()
# conv =======================================
if self.with_dconv:
self.conv2d = nn.Conv2d(
in_channels=self.d_inner,
out_channels=self.d_inner,
groups=self.d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
)
# x proj ============================
self.x_proj = [
nn.Linear(self.d_inner, (self.dt_rank + self.d_state * 2), bias=False)
for _ in range(self.k_group)
]
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K, N, inner)
del self.x_proj
# out proj =======================================
self.out_act = nn.GELU() if self.oact else nn.Identity()
self.out_proj = Linear(self.d_inner, self.d_model, bias=bias)
self.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()
if initialize in ["v0"]:
self.A_logs, self.Ds, self.dt_projs_weight, self.dt_projs_bias = mamba_init.init_dt_A_D(
self.d_state, self.dt_rank, self.d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, k_group=self.k_group,
)
elif initialize in ["v1"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((self.k_group * self.d_inner)))
self.A_logs = nn.Parameter(torch.randn((self.k_group * self.d_inner, self.d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_weight = nn.Parameter(0.1 * torch.randn((self.k_group, self.d_inner, self.dt_rank))) # 0.1 is added in 0430
self.dt_projs_bias = nn.Parameter(0.1 * torch.randn((self.k_group, self.d_inner))) # 0.1 is added in 0430
elif initialize in ["v2"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((self.k_group * self.d_inner)))
self.A_logs = nn.Parameter(torch.zeros((self.k_group * self.d_inner, self.d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_weight = nn.Parameter(0.1 * torch.rand((self.k_group, self.d_inner, self.dt_rank)))
self.dt_projs_bias = nn.Parameter(0.1 * torch.rand((self.k_group, self.d_inner)))
def forward_corev2(
self,
x: torch.Tensor=None,
# ==============================
force_fp32=False, # True: input fp32
# ==============================
ssoflex=True, # True: input 16 or 32 output 32 False: output dtype as input
no_einsum=False, # replace einsum with linear or conv1d to raise throughput
# ==============================
selective_scan_backend = None,
# ==============================
scan_mode = "cross2d",
scan_force_torch = False,
# ==============================
**kwargs,
):
# assert selective_scan_backend in [None, "oflex", "mamba", "torch"]
_scan_mode = dict(cross2d=0, unidi=1, bidi=2, cascade2d=-1).get(scan_mode, None) if isinstance(scan_mode, str) else scan_mode # for debug
assert isinstance(_scan_mode, int)
delta_softplus = True
out_norm = self.out_norm
channel_first = self.channel_first
to_fp32 = lambda *args: (_a.to(torch.float32) for _a in args)
B, D, H, W = x.shape
N = self.d_state
K, D, R = self.k_group, self.d_inner, self.dt_rank
L = H * W
def selective_scan(u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=True):
return selective_scan_fn(u, delta, A, B, C, D, delta_bias, delta_softplus, ssoflex, backend=selective_scan_backend)
if _scan_mode == -1:
x_proj_bias = getattr(self, "x_proj_bias", None)
def scan_rowcol(
x: torch.Tensor,
proj_weight: torch.Tensor,
proj_bias: torch.Tensor,
dt_weight: torch.Tensor,
dt_bias: torch.Tensor, # (2*c)
_As: torch.Tensor, # As = -torch.exp(A_logs.to(torch.float))[:2,] # (2*c, d_state)
_Ds: torch.Tensor,
width = True,
):
# x: (B, D, H, W)
# proj_weight: (2 * D, (R+N+N))
XB, XD, XH, XW = x.shape
if width:
_B, _D, _L = XB * XH, XD, XW
xs = x.permute(0, 2, 1, 3).contiguous()
else:
_B, _D, _L = XB * XW, XD, XH
xs = x.permute(0, 3, 1, 2).contiguous()
xs = torch.stack([xs, xs.flip(dims=[-1])], dim=2) # (B, H, 2, D, W)
if no_einsum:
x_dbl = F.conv1d(xs.view(_B, -1, _L), proj_weight.view(-1, _D, 1), bias=(proj_bias.view(-1) if proj_bias is not None else None), groups=2)
dts, Bs, Cs = torch.split(x_dbl.view(_B, 2, -1, _L), [R, N, N], dim=2)
dts = F.conv1d(dts.contiguous().view(_B, -1, _L), dt_weight.view(2 * _D, -1, 1), groups=2)
else:
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, proj_weight)
if x_proj_bias is not None:
x_dbl = x_dbl + x_proj_bias.view(1, 2, -1, 1)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts, dt_weight)
xs = xs.view(_B, -1, _L)
dts = dts.contiguous().view(_B, -1, _L)
As = _As.view(-1, N).to(torch.float)
Bs = Bs.contiguous().view(_B, 2, N, _L)
Cs = Cs.contiguous().view(_B, 2, N, _L)
Ds = _Ds.view(-1)
delta_bias = dt_bias.view(-1).to(torch.float)
if force_fp32:
xs = xs.to(torch.float)
dts = dts.to(xs.dtype)
Bs = Bs.to(xs.dtype)
Cs = Cs.to(xs.dtype)
ys: torch.Tensor = selective_scan(
xs, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus
).view(_B, 2, -1, _L)
return ys
As = -self.A_logs.to(torch.float).exp().view(4, -1, N)
x = F.layer_norm(x.permute(0, 2, 3, 1), normalized_shape=(int(x.shape[1]),)).permute(0, 3, 1, 2).contiguous() # added0510 to avoid nan
y_row = scan_rowcol(
x,
proj_weight = self.x_proj_weight.view(4, -1, D)[:2].contiguous(),
proj_bias = (x_proj_bias.view(4, -1)[:2].contiguous() if x_proj_bias is not None else None),
dt_weight = self.dt_projs_weight.view(4, D, -1)[:2].contiguous(),
dt_bias = (self.dt_projs_bias.view(4, -1)[:2].contiguous() if self.dt_projs_bias is not None else None),
_As = As[:2].contiguous().view(-1, N),
_Ds = self.Ds.view(4, -1)[:2].contiguous().view(-1),
width=True,
).view(B, H, 2, -1, W).sum(dim=2).permute(0, 2, 1, 3) # (B,C,H,W)
y_row = F.layer_norm(y_row.permute(0, 2, 3, 1), normalized_shape=(int(y_row.shape[1]),)).permute(0, 3, 1, 2).contiguous() # added0510 to avoid nan
y_col = scan_rowcol(
y_row,
proj_weight = self.x_proj_weight.view(4, -1, D)[2:].contiguous().to(y_row.dtype),
proj_bias = (x_proj_bias.view(4, -1)[2:].contiguous().to(y_row.dtype) if x_proj_bias is not None else None),
dt_weight = self.dt_projs_weight.view(4, D, -1)[2:].contiguous().to(y_row.dtype),
dt_bias = (self.dt_projs_bias.view(4, -1)[2:].contiguous().to(y_row.dtype) if self.dt_projs_bias is not None else None),
_As = As[2:].contiguous().view(-1, N),
_Ds = self.Ds.view(4, -1)[2:].contiguous().view(-1),
width=False,
).view(B, W, 2, -1, H).sum(dim=2).permute(0, 2, 3, 1)
y = y_col
else:
x_proj_bias = getattr(self, "x_proj_bias", None)
xs = cross_scan_fn(x, in_channel_first=True, out_channel_first=True, scans=_scan_mode, force_torch=scan_force_torch)
if no_einsum:
x_dbl = F.conv1d(xs.view(B, -1, L), self.x_proj_weight.view(-1, D, 1), bias=(x_proj_bias.view(-1) if x_proj_bias is not None else None), groups=K)
dts, Bs, Cs = torch.split(x_dbl.view(B, K, -1, L), [R, N, N], dim=2)
if hasattr(self, "dt_projs_weight"):
dts = F.conv1d(dts.contiguous().view(B, -1, L), self.dt_projs_weight.view(K * D, -1, 1), groups=K)
else:
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, self.x_proj_weight)
if x_proj_bias is not None:
x_dbl = x_dbl + x_proj_bias.view(1, K, -1, 1)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
if hasattr(self, "dt_projs_weight"):
dts = torch.einsum("b k r l, k d r -> b k d l", dts, self.dt_projs_weight)
xs = xs.view(B, -1, L)
dts = dts.contiguous().view(B, -1, L)
As = -self.A_logs.to(torch.float).exp() # (k * c, d_state)
Ds = self.Ds.to(torch.float) # (K * c)
Bs = Bs.contiguous().view(B, K, N, L)
Cs = Cs.contiguous().view(B, K, N, L)
delta_bias = self.dt_projs_bias.view(-1).to(torch.float)
if force_fp32:
xs, dts, Bs, Cs = to_fp32(xs, dts, Bs, Cs)
ys: torch.Tensor = selective_scan(
xs, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus
).view(B, K, -1, H, W)
y: torch.Tensor = cross_merge_fn(ys, in_channel_first=True, out_channel_first=True, scans=_scan_mode, force_torch=scan_force_torch)
if getattr(self, "__DEBUG__", False):
setattr(self, "__data__", dict(
A_logs=self.A_logs, Bs=Bs, Cs=Cs, Ds=Ds,
us=xs, dts=dts, delta_bias=delta_bias,
ys=ys, y=y, H=H, W=W,
))
y = y.view(B, -1, H, W)
if not channel_first:
y = y.view(B, -1, H * W).transpose(dim0=1, dim1=2).contiguous().view(B, H, W, -1) # (B, L, C)
y = out_norm(y)
return y.to(x.dtype)
def forwardv2(self, x: torch.Tensor, **kwargs):
x = self.in_proj(x)
if not self.disable_z:
x, z = x.chunk(2, dim=(1 if self.channel_first else -1)) # (b, h, w, d)
if not self.disable_z_act:
z = self.act(z)
if not self.channel_first:
x = x.permute(0, 3, 1, 2).contiguous()
if self.with_dconv:
x = self.conv2d(x) # (b, d, h, w)
x = self.act(x)
y = self.forward_core(x)
y = self.out_act(y)
if not self.disable_z:
y = y * z
out = self.dropout(self.out_proj(y))
return out
@staticmethod
def get_outnorm(forward_type="", d_inner=192, channel_first=True):
def checkpostfix(tag, value):
ret = value[-len(tag):] == tag
if ret:
value = value[:-len(tag)]
return ret, value
LayerNorm = LayerNorm2d if channel_first else nn.LayerNorm
out_norm_none, forward_type = checkpostfix("_onnone", forward_type)
out_norm_dwconv3, forward_type = checkpostfix("_ondwconv3", forward_type)
out_norm_cnorm, forward_type = checkpostfix("_oncnorm", forward_type)
out_norm_softmax, forward_type = checkpostfix("_onsoftmax", forward_type)
out_norm_sigmoid, forward_type = checkpostfix("_onsigmoid", forward_type)
out_norm = nn.Identity()
if out_norm_none:
out_norm = nn.Identity()
elif out_norm_cnorm:
out_norm = nn.Sequential(
LayerNorm(d_inner),
(nn.Identity() if channel_first else Permute(0, 3, 1, 2)),
nn.Conv2d(d_inner, d_inner, kernel_size=3, padding=1, groups=d_inner, bias=False),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
)
elif out_norm_dwconv3:
out_norm = nn.Sequential(
(nn.Identity() if channel_first else Permute(0, 3, 1, 2)),
nn.Conv2d(d_inner, d_inner, kernel_size=3, padding=1, groups=d_inner, bias=False),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
)
elif out_norm_softmax:
out_norm = SoftmaxSpatial(dim=(-1 if channel_first else 1))
elif out_norm_sigmoid:
out_norm = nn.Sigmoid()
else:
out_norm = LayerNorm(d_inner)
return out_norm, forward_type
@staticmethod
def checkpostfix(tag, value):
ret = value[-len(tag):] == tag
if ret:
value = value[:-len(tag)]
return ret, value
# support: xv1a,xv2a,xv3a;
# postfix: _cpos;_ocov;_ocov2;_ca,_ca1;_act;_mul;_onsigmoid,_onsoftmax,_ondwconv3,_onnone;
class SS2Dv3:
def __initxv__(
self,
# basic dims ===========
d_model=96,
d_state=16,
ssm_ratio=2.0,
dt_rank="auto",
# dwconv ===============
d_conv=3, # < 2 means no conv
conv_bias=True,
# ======================
dropout=0.0,
bias=False,
# dt init ==============
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
initialize="v0",
# ======================
forward_type="v2",
channel_first=False,
# ======================
**kwargs,
):
super().__init__()
d_inner = int(ssm_ratio * d_model)
dt_rank = math.ceil(d_model / 16) if dt_rank == "auto" else dt_rank
self.channel_first = channel_first
self.d_state = d_state
self.dt_rank = dt_rank
self.d_inner = d_inner
k_group = 4
self.with_dconv = d_conv > 1
Linear = Linear2d if channel_first else nn.Linear
self.forward = self.forwardxv
# tags for forward_type ==============================
checkpostfix = SS2Dv2.checkpostfix
self.out_norm, forward_type = SS2Dv2.get_outnorm(forward_type, d_inner, channel_first)
self.omul, forward_type = checkpostfix("_mul", forward_type)
self.oact, forward_type = checkpostfix("_act", forward_type)
self.f_omul = nn.Identity() if self.omul else None
self.out_act = nn.GELU() if self.oact else nn.Identity()
mode = forward_type[:4]
assert mode in ["xv1a", "xv2a", "xv3a"]
self.forward = partial(self.forwardxv, mode=mode)
self.dts_dim = dict(xv1a=self.dt_rank, xv2a=self.d_inner, xv3a=4 * self.dt_rank)[mode]
d_inner_all = d_inner + self.dts_dim + 8 * d_state
self.in_proj = Linear(d_model, d_inner_all, bias=bias)
# conv =======================================
self.cpos = False
self.iconv = False
self.oconv = False
self.oconv2 = False
if self.with_dconv:
cact, forward_type = checkpostfix("_ca", forward_type)
cact1, forward_type = checkpostfix("_ca1", forward_type)
self.cact = nn.SiLU() if cact else nn.Identity()
self.cact = nn.GELU() if cact1 else self.cact
self.oconv2, forward_type = checkpostfix("_ocov2", forward_type)
self.oconv, forward_type = checkpostfix("_ocov", forward_type)
self.cpos, forward_type = checkpostfix("_cpos", forward_type)
self.iconv = (not self.oconv) and (not self.oconv2)
if self.iconv:
self.conv2d = nn.Conv2d(
in_channels=d_model,
out_channels=d_model,
groups=d_model,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
)
if self.oconv:
self.oconv2d = nn.Conv2d(
in_channels=d_inner,
out_channels=d_inner,
groups=d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
)
if self.oconv2:
self.conv2d = nn.Conv2d(
in_channels=d_inner_all,
out_channels=d_inner_all,
groups=d_inner_all,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
)
# out proj =======================================
self.out_proj = Linear(d_inner, d_model, bias=bias)
self.dropout = nn.Dropout(dropout) if dropout > 0.0 else nn.Identity()
if initialize in ["v0"]:
self.A_logs, self.Ds, self.dt_projs_weight, self.dt_projs_bias = mamba_init.init_dt_A_D(
d_state, dt_rank, d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, k_group=4,
)
elif initialize in ["v1"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((k_group * d_inner)))
self.A_logs = nn.Parameter(torch.randn((k_group * d_inner, d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_weight = nn.Parameter(torch.randn((k_group, d_inner, dt_rank)))
self.dt_projs_bias = nn.Parameter(torch.randn((k_group, d_inner)))
elif initialize in ["v2"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((k_group * d_inner)))
self.A_logs = nn.Parameter(torch.zeros((k_group * d_inner, d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_weight = nn.Parameter(0.1 * torch.rand((k_group, d_inner, dt_rank)))
self.dt_projs_bias = nn.Parameter(0.1 * torch.rand((k_group, d_inner)))
if forward_type.startswith("xv2"):
del self.dt_projs_weight
self.dt_projs_weight = None
def forwardxv(self, x: torch.Tensor, **kwargs):
B, (H, W) = x.shape[0], (x.shape[2:4] if self.channel_first else x.shape[1:3])
L = H * W
force_fp32 = False
delta_softplus = True
out_norm = self.out_norm
to_dtype = True
to_fp32 = lambda *args: (_a.to(torch.float32) for _a in args)
def selective_scan(u, delta, A, B, C, D, delta_bias, delta_softplus):
return selective_scan_fn(u, delta, A, B, C, D, delta_bias, delta_softplus, oflex=True, backend=None)
if self.iconv:
x = self.cact(self.conv2d(x)) # (b, d, h, w)
elif self.cpos:
x = x + self.conv2d(x) # (b, d, h, w)
x = self.in_proj(x)
if self.oconv2:
x = self.conv2d(x) # (b, d, h, w)
us, dts, Bs, Cs = x.split([self.d_inner, self.dts_dim, 4 * self.d_state, 4 * self.d_state], dim=(1 if self.channel_first else -1))
_us = us
# Bs, Cs = Bs.view(B, H, W, 4, -1), Cs.view(B, H, W, 4, -1)
# Bs, Cs = Bs.view(B, 4, -1, H, W), Cs.view(B, 4, -1, H, W)
us = cross_scan_fn(us.contiguous(), in_channel_first=self.channel_first, out_channel_first=True).view(B, -1, L)
Bs = cross_scan_fn(Bs.contiguous(), in_channel_first=self.channel_first, out_channel_first=True, one_by_one=True).view(B, 4, -1, L)
Cs = cross_scan_fn(Cs.contiguous(), in_channel_first=self.channel_first, out_channel_first=True, one_by_one=True).view(B, 4, -1, L)
dts = cross_scan_fn(dts.contiguous(), in_channel_first=self.channel_first, out_channel_first=True, one_by_one=(self.dts_dim == 4 * self.dt_rank)).view(B, L, -1)
if self.dts_dim == self.dt_rank:
dts = F.conv1d(dts, self.dt_projs_weight.view(4 * self.d_inner, self.dt_rank, 1), None, groups=4)
elif self.dts_dim == 4 * self.dt_rank:
dts = F.conv1d(dts, self.dt_projs_weight.view(4 * self.d_inner, self.dt_rank, 1), None, groups=4)
As = -self.A_logs.to(torch.float).exp() # (k * c, d_state)
Ds = self.Ds.to(torch.float) # (K * c)
delta_bias = self.dt_projs_bias.view(-1).to(torch.float) # (K * c)
if force_fp32:
us, dts, Bs, Cs = to_fp32(us, dts, Bs, Cs)
ys: torch.Tensor = selective_scan(
us, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus
).view(B, 4, -1, H, W)
y: torch.Tensor = cross_merge_fn(ys.contiguous(), in_channel_first=self.channel_first, out_channel_first=True)
y = y.view(B, -1, H, W) if self.channel_first else y.view(B, H, W, -1)
y = out_norm(y)
if getattr(self, "__DEBUG__", False):
setattr(self, "__data__", dict(
A_logs=self.A_logs, Bs=Bs, Cs=Cs, Ds=Ds,
us=us, dts=dts, delta_bias=delta_bias,
ys=ys, y=y,
))
y = (y.to(x.dtype) if to_dtype else y)
y = self.out_act(y)
if self.omul:
y = y * _us
if self.oconv:
y = y + self.cact(self.oconv2d(_us))
out = self.dropout(self.out_proj(y))
return out
# mamba2 support ================================
class SS2Dm0:
def __initm0__(
self,
# basic dims ===========
d_model=96,
d_state=16, # now with mamba2, dstate should be bigger...
ssm_ratio=2.0,
dt_rank="auto",
act_layer=nn.GELU,
# dwconv ===============
d_conv=3, # < 2 means no conv
conv_bias=True,
# ======================
dropout=0.0,
bias=False,
# dt init ==============
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
initialize="v2",
# ======================
forward_type="m0",
# ======================
with_initial_state=False,
# ======================
**kwargs,
):
factory_kwargs = {
"device": None, "dtype": None}
super().__init__()
d_inner = int(ssm_ratio * d_model)
dt_rank = math.ceil(d_model / 16) if dt_rank == "auto" else dt_rank
assert d_inner % dt_rank == 0
self.with_dconv = d_conv > 1
Linear = nn.Linear
self.forward = self.forwardm0
# tags for forward_type ==============================
checkpostfix = SS2Dv2.checkpostfix
self.disable_force32, forward_type = checkpostfix("_no32", forward_type)
self.oact, forward_type = checkpostfix("_oact", forward_type)
self.disable_z, forward_type = checkpostfix("_noz", forward_type)
self.disable_z_act, forward_type = checkpostfix("_nozact", forward_type)
self.out_norm, forward_type = SS2Dv2.get_outnorm(forward_type, d_inner, False)
# forward_type debug =======================================
FORWARD_TYPES = dict(
m0=partial(self.forward_corem0, force_fp32=False, dstate=d_state),
)
self.forward_core = FORWARD_TYPES.get(forward_type, None)
k_group = 4
# in proj =======================================
d_proj = d_inner if self.disable_z else (d_inner * 2)
self.in_proj = Linear(d_model, d_proj, bias=bias)
self.act: nn.Module = act_layer()
# conv =======================================
if self.with_dconv:
self.conv2d = nn.Sequential(
Permute(0, 3, 1, 2),
nn.Conv2d(
in_channels=d_inner,
out_channels=d_inner,
groups=d_inner,
bias=conv_bias,
kernel_size=d_conv,
padding=(d_conv - 1) // 2,
**factory_kwargs,
),
Permute(0, 2, 3, 1),
)
# x proj ============================
self.x_proj = [
nn.Linear(d_inner, (dt_rank + d_state * 2), bias=False)
for _ in range(k_group)
]
self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0)) # (K, N, inner)
del self.x_proj
# out proj =======================================
self.out_act = nn.GELU() if self.oact else nn.Identity()
self.out_proj = Linear(d_inner, d_model, bias=bias)
self.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()
if initialize in ["v1"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((k_group, dt_rank, int(d_inner // dt_rank))))
self.A_logs = nn.Parameter(torch.randn((k_group, dt_rank))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_bias = nn.Parameter(0.1 * torch.randn((k_group, dt_rank))) # 0.1 is added in 0430
elif initialize in ["v2"]:
# simple init dt_projs, A_logs, Ds
self.Ds = nn.Parameter(torch.ones((k_group, dt_rank, int(d_inner // dt_rank))))
self.A_logs = nn.Parameter(torch.zeros((k_group, dt_rank))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1
self.dt_projs_bias = nn.Parameter(0.1 * torch.rand((k_group, dt_rank)))
# init state ============================
self.initial_state = None
if with_initial_state:
self.initial_state = nn.Parameter(torch.zeros((1, k_group * dt_rank, int(d_inner // dt_rank), d_state)), requires_grad=False)
def forward_corem0(
self,
x: torch.Tensor=None,
# ==============================
force_fp32=False, # True: input fp32
chunk_size = 64,
dstate = 64,
# ==============================
selective_scan_backend = None,
scan_mode = "cross2d",
scan_force_torch = False,
# ==============================
**kwargs,
):
assert scan_mode in ["unidi", "bidi", "cross2d"]
assert selective_scan_backend in [None, "triton", "torch"]
x_proj_bias = getattr(self, "x_proj_bias", None)
to_fp32 = lambda *args: (_a.to(torch.float32) for _a in args)
N = dstate
B, H, W, RD = x.shape
K, R = self.A_logs.shape
K, R, D = self.Ds.shape
assert RD == R * D
L = H * W
KR = K * R
_scan_mode = dict(cross2d=0, unidi=1, bidi=2, cascade2d=3)[scan_mode]
initial_state = None
if self.initial_state is not None:
assert self.initial_state.shape[-1] == dstate
initial_state = self.initial_state.detach().repeat(B, 1, 1, 1)
xs = cross_scan_fn(x.view(B, H, W, RD), in_channel_first=False, out_channel_first=False, scans=_scan_mode, force_torch=scan_force_torch) # (B, H, W, 4, D)
x_dbl = torch.einsum("b l k d, k c d -> b l k c", xs, self.x_proj_weight)
if x_proj_bias is not None:
x_dbl = x_dbl + x_proj_bias.view(1, -1, K, 1)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=3)
xs = xs.contiguous().view(B, L, KR, D)
dts = dts.contiguous().view(B, L, KR)
Bs = Bs.contiguous().view(B, L, K, N)
Cs = Cs.contiguous().view(B, L, K, N)
if force_fp32:
xs, dts, Bs, Cs = to_fp32(xs, dts, Bs, Cs)
As = -self.A_logs.to(torch.float).exp().view(KR)
Ds = self.Ds.to(torch.float).view(KR, D)
dt_bias = self.dt_projs_bias.view(KR)
if force_fp32:
xs, dts, Bs, Cs = to_fp32(xs, dts, Bs, Cs)
ys, final_state = selective_scan_chunk_fn(
xs, dts, As, Bs, Cs, chunk_size=chunk_size, D=Ds, dt_bias=dt_bias,
initial_states=initial_state, dt_softplus=True, return_final_states=True,
backend=selective_scan_backend,
)
y: torch.Tensor = cross_merge_fn(ys.view(B, H, W, K, RD), in_channel_first=False, out_channel_first=False, scans=_scan_mode, force_torch=scan_force_torch)
if getattr(self, "__DEBUG__", False):
setattr(self, "__data__", dict(
A_logs=self.A_logs, Bs=Bs, Cs=Cs, Ds=self.Ds,
us=xs, dts=dts, delta_bias=self.dt_projs_bias,
initial_state=self.initial_state, final_satte=final_state,
ys=ys, y=y, H=H, W=W,
))
if self.initial_state is not None:
self.initial_state = nn.Parameter(final_state.detach().sum(0, keepdim=True), requires_grad=False)
y = self.out_norm(y.view(B, H, W, -1))
return y.to(x.dtype)
def forwardm0(self, x: torch.Tensor, **kwargs):
x = self.in_proj(x)
if not self.disable_z:
x, z = x.chunk(2, dim=(1 if self.channel_first else -1)) # (b, h, w, d)
if not self.disable_z_act:
z = self.act(z)
if self.with_dconv:
x = self.conv2d(x) # (b, d, h, w)
x = self.act(x)
y = self.forward_core(x)
y = self.out_act(y)
if not self.disable_z:
y = y * z
out = self.dropout(self.out_proj(y))
return out
class SS2D(nn.Module, SS2Dv0, SS2Dv2, SS2Dv3, SS2Dm0):
def __init__(
self,
# basic dims ===========
d_model=96,
d_state=16,
ssm_ratio=2.0,
dt_rank="auto",
act_layer=nn.SiLU,
# dwconv ===============
d_conv=3, # < 2 means no conv
conv_bias=True,
# ======================
dropout=0.0,
bias=False,
# dt init ==============
dt_min=0.001,
dt_max=0.1,
dt_init="random",
dt_scale=1.0,
dt_init_floor=1e-4,
initialize="v0",
# ======================
forward_type="v2",
channel_first=False,
# ======================
**kwargs,
):
nn.Module.__init__(self)
kwargs.update(
d_model=d_model, d_state=d_state, ssm_ratio=ssm_ratio, dt_rank=dt_rank,
act_layer=act_layer, d_conv=d_conv, conv_bias=conv_bias, dropout=dropout, bias=bias,
dt_min=dt_min, dt_max=dt_max, dt_init=dt_init, dt_scale=dt_scale, dt_init_floor=dt_init_floor,
initialize=initialize, forward_type=forward_type, channel_first=channel_first,
)
if forward_type in ["v0", "v0seq"]:
self.__initv0__(seq=("seq" in forward_type), **kwargs)
elif forward_type.startswith("xv"):
self.__initxv__(**kwargs)
elif forward_type.startswith("m"):
self.__initm0__(**kwargs)
else:
self.__initv2__(**kwargs)
# =====================================================
class VSSBlock(nn.Module):
def __init__(
self,
hidden_dim: int = 0,
drop_path: float = 0,
norm_layer: nn.Module = nn.LayerNorm,
channel_first=False,
# =============================
ssm_d_state: int = 16,
ssm_ratio=2.0,
ssm_dt_rank: Any = "auto",
ssm_act_layer=nn.SiLU,
ssm_conv: int = 3,
ssm_conv_bias=True,
ssm_drop_rate: float = 0,
ssm_init="v0",
forward_type="v2",
# =============================
mlp_ratio=4.0,
mlp_act_layer=nn.GELU,
mlp_drop_rate: float = 0.0,
gmlp=False,
# =============================
use_checkpoint: bool = False,
post_norm: bool = False,
# =============================
_SS2D: type = SS2D,
**kwargs,
):
super().__init__()
self.ssm_branch = ssm_ratio > 0
self.mlp_branch = mlp_ratio > 0
self.use_checkpoint = use_checkpoint
self.post_norm = post_norm
if self.ssm_branch:
self.norm = norm_layer(hidden_dim)
self.op = _SS2D(
d_model=hidden_dim,
d_state=ssm_d_state,
ssm_ratio=ssm_ratio,
dt_rank=ssm_dt_rank,
act_layer=ssm_act_layer,
# ==========================
d_conv=ssm_conv,
conv_bias=ssm_conv_bias,
# ==========================
dropout=ssm_drop_rate,
# bias=False,
# ==========================
# dt_min=0.001,
# dt_max=0.1,
# dt_init="random",
# dt_scale="random",
# dt_init_floor=1e-4,
initialize=ssm_init,
# ==========================
forward_type=forward_type,
channel_first=channel_first,
)
self.drop_path = DropPath(drop_path)
if self.mlp_branch:
_MLP = Mlp if not gmlp else gMlp
self.norm2 = norm_layer(hidden_dim)
mlp_hidden_dim = int(hidden_dim * mlp_ratio)
self.mlp = _MLP(in_features=hidden_dim, hidden_features=mlp_hidden_dim, act_layer=mlp_act_layer, drop=mlp_drop_rate, channels_first=channel_first)
def _forward(self, input: torch.Tensor):
x = input
if self.ssm_branch:
if self.post_norm:
x = x + self.drop_path(self.norm(self.op(x)))
else:
x = x + self.drop_path(self.op(self.norm(x)))
if self.mlp_branch:
if self.post_norm:
x = x + self.drop_path(self.norm2(self.mlp(x))) # FFN
else:
x = x + self.drop_path(self.mlp(self.norm2(x))) # FFN
return x
def forward(self, input: torch.Tensor):
if self.use_checkpoint:
return checkpoint.checkpoint(self._forward, input)
else:
return self._forward(input)
class VSSM(nn.Module):
def __init__(
self,
patch_size=4,
in_chans=3,
num_classes=1000,
depths=[2, 2, 9, 2],
dims=[96, 192, 384, 768],
# =========================
ssm_d_state=16,
ssm_ratio=2.0,
ssm_dt_rank="auto",
ssm_act_layer="silu",
ssm_conv=3,
ssm_conv_bias=True,
ssm_drop_rate=0.0,
ssm_init="v0",
forward_type="v2",
# =========================
mlp_ratio=4.0,
mlp_act_layer="gelu",
mlp_drop_rate=0.0,
gmlp=False,
# =========================
drop_path_rate=0.1,
patch_norm=True,
norm_layer="LN", # "BN", "LN2D"
downsample_version: str = "v2", # "v1", "v2", "v3"
patchembed_version: str = "v1", # "v1", "v2"
use_checkpoint=False,
# =========================
posembed=False,
imgsize=224,
_SS2D=SS2D,
# =========================
**kwargs,
):
super().__init__()
self.channel_first = (norm_layer.lower() in ["bn", "ln2d"])
self.num_classes = num_classes
self.num_layers = len(depths)
if isinstance(dims, int):
dims = [int(dims * 2 ** i_layer) for i_layer in range(self.num_layers)]
self.num_features = dims[-1]
self.dims = dims
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
_NORMLAYERS = dict(
ln=nn.LayerNorm,
ln2d=LayerNorm2d,
bn=nn.BatchNorm2d,
)
_ACTLAYERS = dict(
silu=nn.SiLU,
gelu=nn.GELU,
relu=nn.ReLU,
sigmoid=nn.Sigmoid,
)
norm_layer: nn.Module = _NORMLAYERS.get(norm_layer.lower(), None)
ssm_act_layer: nn.Module = _ACTLAYERS.get(ssm_act_layer.lower(), None)
mlp_act_layer: nn.Module = _ACTLAYERS.get(mlp_act_layer.lower(), None)
self.pos_embed = self._pos_embed(dims[0], patch_size, imgsize) if posembed else None
_make_patch_embed = dict(
v1=self._make_patch_embed,
v2=self._make_patch_embed_v2,
).get(patchembed_version, None)
self.patch_embed = _make_patch_embed(in_chans, dims[0], patch_size, patch_norm, norm_layer, channel_first=self.channel_first)
_make_downsample = dict(
v1=PatchMerging2D,
v2=self._make_downsample,
v3=self._make_downsample_v3,
none=(lambda *_, **_k: None),
).get(downsample_version, None)
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
downsample = _make_downsample(
self.dims[i_layer],
self.dims[i_layer + 1],
norm_layer=norm_layer,
channel_first=self.channel_first,
) if (i_layer < self.num_layers - 1) else nn.Identity()
self.layers.append(self._make_layer(
dim = self.dims[i_layer],
drop_path = dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
use_checkpoint=use_checkpoint,
norm_layer=norm_layer,
downsample=downsample,
channel_first=self.channel_first,
# =================
ssm_d_state=ssm_d_state,
ssm_ratio=ssm_ratio,
ssm_dt_rank=ssm_dt_rank,
ssm_act_layer=ssm_act_layer,
ssm_conv=ssm_conv,
ssm_conv_bias=ssm_conv_bias,
ssm_drop_rate=ssm_drop_rate,
ssm_init=ssm_init,
forward_type=forward_type,
# =================
mlp_ratio=mlp_ratio,
mlp_act_layer=mlp_act_layer,
mlp_drop_rate=mlp_drop_rate,
gmlp=gmlp,
# =================
_SS2D=_SS2D,
))
self.classifier = nn.Sequential(OrderedDict(
norm=norm_layer(self.num_features), # B,H,W,C
permute=(Permute(0, 3, 1, 2) if not self.channel_first else nn.Identity()),
avgpool=nn.AdaptiveAvgPool2d(1),
flatten=nn.Flatten(1),
head=nn.Linear(self.num_features, num_classes),
))
self.apply(self._init_weights)
@staticmethod
def _pos_embed(embed_dims, patch_size, img_size):
patch_height, patch_width = (img_size // patch_size, img_size // patch_size)
pos_embed = nn.Parameter(torch.zeros(1, embed_dims, patch_height, patch_width))
trunc_normal_(pos_embed, std=0.02)
return pos_embed
def _init_weights(self, m: nn.Module):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
# used in building optimizer
@torch.jit.ignore
def no_weight_decay(self):
return {
"pos_embed"}
# used in building optimizer
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {
}
@staticmethod
def _make_patch_embed(in_chans=3, embed_dim=96, patch_size=4, patch_norm=True, norm_layer=nn.LayerNorm, channel_first=False):
# if channel first, then Norm and Output are both channel_first
return nn.Sequential(
nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size, bias=True),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
(norm_layer(embed_dim) if patch_norm else nn.Identity()),
)
@staticmethod
def _make_patch_embed_v2(in_chans=3, embed_dim=96, patch_size=4, patch_norm=True, norm_layer=nn.LayerNorm, channel_first=False):
# if channel first, then Norm and Output are both channel_first
stride = patch_size // 2
kernel_size = stride + 1
padding = 1
return nn.Sequential(
nn.Conv2d(in_chans, embed_dim // 2, kernel_size=kernel_size, stride=stride, padding=padding),
(nn.Identity() if (channel_first or (not patch_norm)) else Permute(0, 2, 3, 1)),
(norm_layer(embed_dim // 2) if patch_norm else nn.Identity()),
(nn.Identity() if (channel_first or (not patch_norm)) else Permute(0, 3, 1, 2)),
nn.GELU(),
nn.Conv2d(embed_dim // 2, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
(norm_layer(embed_dim) if patch_norm else nn.Identity()),
)
@staticmethod
def _make_downsample(dim=96, out_dim=192, norm_layer=nn.LayerNorm, channel_first=False):
# if channel first, then Norm and Output are both channel_first
return nn.Sequential(
(nn.Identity() if channel_first else Permute(0, 3, 1, 2)),
nn.Conv2d(dim, out_dim, kernel_size=2, stride=2),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
norm_layer(out_dim),
)
@staticmethod
def _make_downsample_v3(dim=96, out_dim=192, norm_layer=nn.LayerNorm, channel_first=False):
# if channel first, then Norm and Output are both channel_first
return nn.Sequential(
(nn.Identity() if channel_first else Permute(0, 3, 1, 2)),
nn.Conv2d(dim, out_dim, kernel_size=3, stride=2, padding=1),
(nn.Identity() if channel_first else Permute(0, 2, 3, 1)),
norm_layer(out_dim),
)
@staticmethod
def _make_layer(
dim=96,
drop_path=[0.1, 0.1],
use_checkpoint=False,
norm_layer=nn.LayerNorm,
downsample=nn.Identity(),
channel_first=False,
# ===========================
ssm_d_state=16,
ssm_ratio=2.0,
ssm_dt_rank="auto",
ssm_act_layer=nn.SiLU,
ssm_conv=3,
ssm_conv_bias=True,
ssm_drop_rate=0.0,
ssm_init="v0",
forward_type="v2",
# ===========================
mlp_ratio=4.0,
mlp_act_layer=nn.GELU,
mlp_drop_rate=0.0,
gmlp=False,
# ===========================
_SS2D=SS2D,
**kwargs,
):
# if channel first, then Norm and Output are both channel_first
depth = len(drop_path)
blocks = []
for d in range(depth):
blocks.append(VSSBlock(
hidden_dim=dim,
drop_path=drop_path[d],
norm_layer=norm_layer,
channel_first=channel_first,
ssm_d_state=ssm_d_state,
ssm_ratio=ssm_ratio,
ssm_dt_rank=ssm_dt_rank,
ssm_act_layer=ssm_act_layer,
ssm_conv=ssm_conv,
ssm_conv_bias=ssm_conv_bias,
ssm_drop_rate=ssm_drop_rate,
ssm_init=ssm_init,
forward_type=forward_type,
mlp_ratio=mlp_ratio,
mlp_act_layer=mlp_act_layer,
mlp_drop_rate=mlp_drop_rate,
gmlp=gmlp,
use_checkpoint=use_checkpoint,
_SS2D=_SS2D,
))
return nn.Sequential(OrderedDict(
blocks=nn.Sequential(*blocks,),
downsample=downsample,
))
def forward(self, x: torch.Tensor):
x = self.patch_embed(x)
if self.pos_embed is not None:
pos_embed = self.pos_embed.permute(0, 2, 3, 1) if not self.channel_first else self.pos_embed
x = x + pos_embed
for layer in self.layers:
x = layer(x)
x = self.classifier(x)
return x
def flops(self, shape=(3, 224, 224), verbose=True):
# shape = self.__input_shape__[1:]
supported_ops={
"aten::silu": None, # as relu is in _IGNORED_OPS
"aten::neg": None, # as relu is in _IGNORED_OPS
"aten::exp": None, # as relu is in _IGNORED_OPS
"aten::flip": None, # as permute is in _IGNORED_OPS
# "prim::PythonOp.CrossScan": None,
# "prim::PythonOp.CrossMerge": None,
"prim::PythonOp.SelectiveScanCuda": partial(selective_scan_flop_jit, backend="prefixsum", verbose=verbose),
}
model = copy.deepcopy(self)
model.cuda().eval()
input = torch.randn((1, *shape), device=next(model.parameters()).device)
params = parameter_count(model)[""]
Gflops, unsupported = flop_count(model=model, inputs=(input,), supported_ops=supported_ops)
del model, input
return sum(Gflops.values()) * 1e9
return f"params {
params} GFLOPs {
sum(Gflops.values())}"
# used to load ckpt from previous training code
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs):
def check_name(src, state_dict: dict = state_dict, strict=False):
if strict:
if prefix + src in list(state_dict.keys()):
return True
else:
key = prefix + src
for k in list(state_dict.keys()):
if k.startswith(key):
return True
return False
def change_name(src, dst, state_dict: dict = state_dict, strict=False):
if strict:
if prefix + src in list(state_dict.keys()):
state_dict[prefix + dst] = state_dict[prefix + src]
state_dict.pop(prefix + src)
else:
key = prefix + src
for k in list(state_dict.keys()):
if k.startswith(key):
new_k = prefix + dst + k[len(key):]
state_dict[new_k] = state_dict[k]
state_dict.pop(k)
if check_name("pos_embed", strict=True):
srcEmb: torch.Tensor = state_dict[prefix + "pos_embed"]
state_dict[prefix + "pos_embed"] = F.interpolate(srcEmb.float(), size=self.pos_embed.shape[2:4], align_corners=False, mode="bicubic").to(srcEmb.device)
change_name("patch_embed.proj", "patch_embed.0")
change_name("patch_embed.norm", "patch_embed.2")
for i in range(100):
for j in range(100):
change_name(f"layers.{
i}.blocks.{
j}.ln_1", f"layers.{
i}.blocks.{
j}.norm")
change_name(f"layers.{
i}.blocks.{
j}.self_attention", f"layers.{
i}.blocks.{
j}.op")
change_name("norm", "classifier.norm")
change_name("head", "classifier.head")
return super()._load_from_state_dict(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
# compatible with openmmlab
class Backbone_VSSM(VSSM):
def __init__(self, out_indices=(0, 1, 2, 3), pretrained=None, norm_layer="ln", **kwargs):
kwargs.update(norm_layer=norm_layer)
super().__init__(**kwargs)
self.channel_first = (norm_layer.lower() in ["bn", "ln2d"])
_NORMLAYERS = dict(
ln=nn.LayerNorm,
ln2d=LayerNorm2d,
bn=nn.BatchNorm2d,
)
norm_layer: nn.Module = _NORMLAYERS.get(norm_layer.lower(), None)
self.out_indices = out_indices
for i in out_indices:
layer = norm_layer(self.dims[i])
layer_name = f'outnorm{
i}'
self.add_module(layer_name, layer)
del self.classifier
self.load_pretrained(pretrained)
def load_pretrained(self, ckpt=None, key="model"):
if ckpt is None:
return
try:
_ckpt = torch.load(open(ckpt, "rb"), map_location=torch.device("cpu"))
print(f"Successfully load ckpt {
ckpt}")
incompatibleKeys = self.load_state_dict(_ckpt[key], strict=False)
print(incompatibleKeys)
except Exception as e:
print(f"Failed loading checkpoint form {
ckpt}: {
e}")
def forward(self, x):
def layer_forward(l, x):
x = l.blocks(x)
y = l.downsample(x)
return x, y
x = self.patch_embed(x)
outs = []
for i, layer in enumerate(self.layers):
o, x = layer_forward(layer, x) # (B, H, W, C)
if i in self.out_indices:
norm_layer = getattr(self, f'outnorm{
i}')
out = norm_layer(o)
if not self.channel_first:
out = out.permute(0, 3, 1, 2)
outs.append(out.contiguous())
if len(self.out_indices) == 0:
return x
return outs
# =====================================================
def vanilla_vmamba_tiny():
return VSSM(
depths=[2, 2, 9, 2], dims=96, drop_path_rate=0.2,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=16, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=True, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v0",
mlp_ratio=0.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v1", patchembed_version="v1",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vanilla_vmamba_small():
return VSSM(
depths=[2, 2, 27, 2], dims=96, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=16, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=True, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v0",
mlp_ratio=0.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v1", patchembed_version="v1",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vanilla_vmamba_base():
return VSSM(
depths=[2, 2, 27, 2], dims=128, drop_path_rate=0.6,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=16, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=True, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v0",
mlp_ratio=0.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v1", patchembed_version="v1",
use_checkpoint=False, posembed=False, imgsize=224,
)
# =====================================================
def vmamba_tiny_s2l5(channel_first=True):
return VSSM(
depths=[2, 2, 5, 2], dims=96, drop_path_rate=0.2,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_small_s2l15(channel_first=True):
return VSSM(
depths=[2, 2, 15, 2], dims=96, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_base_s2l15(channel_first=True):
return VSSM(
depths=[2, 2, 15, 2], dims=128, drop_path_rate=0.6,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=2.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
# =====================================================
def vmamba_tiny_s1l8(channel_first=True):
return VSSM(
depths=[2, 2, 8, 2], dims=96, drop_path_rate=0.2,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_small_s1l20(channel_first=True):
return VSSM(
depths=[2, 2, 20, 2], dims=96, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_base_s1l20(channel_first=True):
return VSSM(
depths=[2, 2, 20, 2], dims=128, drop_path_rate=0.5,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=1, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="silu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v0", forward_type="v05_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer=("ln2d" if channel_first else "ln"),
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
# mamba2 support =====================================================
# FLOPS count do not work now for mamba2!
def vmamba_tiny_m2():
return VSSM(
depths=[2, 2, 4, 2], dims=96, drop_path_rate=0.2,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=64, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="gelu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v2", forward_type="m0_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_small_m2():
return VSSM(
depths=[2, 2, 12, 2], dims=96, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=64, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="gelu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v2", forward_type="m0_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
def vmamba_base_m2():
return VSSM(
depths=[2, 2, 12, 2], dims=128, drop_path_rate=0.3,
patch_size=4, in_chans=3, num_classes=1000,
ssm_d_state=64, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="gelu",
ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
ssm_init="v2", forward_type="m0_noz",
mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
patch_norm=True, norm_layer="ln",
downsample_version="v3", patchembed_version="v2",
use_checkpoint=False, posembed=False, imgsize=224,
)
# if __name__ == "__main__":
# model_ref = vmamba_tiny_s1l8()
#
# model = VSSM(
# depths=[2, 2, 4, 2], dims=96, drop_path_rate=0.2,
# patch_size=4, in_chans=3, num_classes=1000,
# ssm_d_state=64, ssm_ratio=1.0, ssm_dt_rank="auto", ssm_act_layer="gelu",
# ssm_conv=3, ssm_conv_bias=False, ssm_drop_rate=0.0,
# ssm_init="v2", forward_type="m0_noz",
# mlp_ratio=4.0, mlp_act_layer="gelu", mlp_drop_rate=0.0, gmlp=False,
# patch_norm=True, norm_layer="ln",
# downsample_version="v3", patchembed_version="v2",
# use_checkpoint=False, posembed=False, imgsize=224,
# )
# print(parameter_count(model)[""])
# # print(model.flops()) # wrong
# model.cuda().train()
# model_ref.cuda().train()
#
# def bench(model):
# import time
# inp = torch.randn((128, 3, 224, 224)).cuda()
# for _ in range(30):
# model(inp)
# torch.cuda.synchronize()
# tim = time.time()
# for _ in range(30):
# model(inp)
# torch.cuda.synchronize()
# tim1 = time.time() - tim
#
# for _ in range(30):
# model(inp).sum().backward()
# torch.cuda.synchronize()
# tim = time.time()
# for _ in range(30):
# model(inp).sum().backward()
# torch.cuda.synchronize()
# tim2 = time.time() - tim
#
# return tim1 / 30, tim2 / 30
#
# print(bench(model_ref))
# print(bench(model))
#
# breakpoint()
if __name__ == '__main__':
device = torch.device("cuda:0")
hidden_dim = 3
network = VSSM(hidden_dim).to('cuda:0')
input_image = torch.randn(1, 3, 224, 224)
input_image = input_image.to(device)
output = network(input_image)
print("Output shape:", output.shape)
运行无报错即可。

出现的问题
1. 出现 fatal error C1083: 无法打开包括文件: “nv/target”'
具体来说出现以下报错
D:\software\Anaconda\envs\mamba\include\cuda_fp16.h(4100): fatal error C1083: 无法打开包括文件: “nv/target”: No such file or directory
即出现
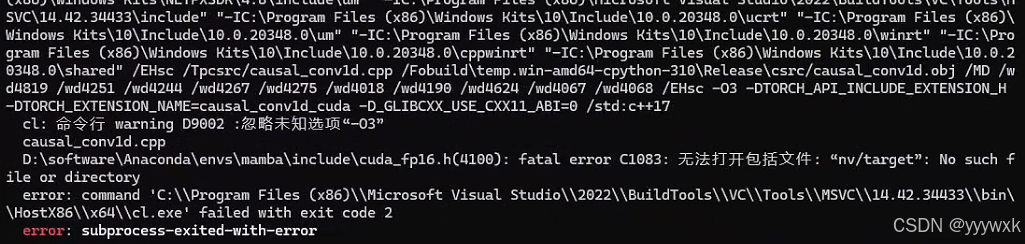
说明其中环境中缺少 CUDA C++ 核心计算库 (CUDA C++ Core Libraries, CCCL),解决方法即为:
conda install nvidia/label/cuda-12.4.0::cuda-cccl
2. 出现 module 'triton.language.math' has no attribute 'log1p'
验证 Vmamba 时出现以下报错:

即出现报错 AttributeError: module 'triton.language.math' has no attribute 'log1p'. Did you mean: 'log2'?:
File "D:\Anaconda\envs\Vmamba\lib\site-packages\triton\runtime\jit.py", line 117, in visit_Attribute
return getattr(lhs, node.attr)
AttributeError: module 'triton.language.math' has no attribute 'log1p'. Did you mean: 'log2'?
原因是 log1p 是triton 2 版本里的函数,在triton 3 版本里面已经删除了。
暂时的解决方法是注释掉 print(model.flops()) # wrong 这一句,绕开所有与其有关的函数。
3. 出现 selective_scan_backend 有关的 AssertionError
即

具体为:
File "D:\pycharm\VMamba-main\classification\models\vmamba.py", line 659, in forwardv2
y = self.forward_core(x)
File "D:\pycharm\VMamba-main\classification\models\vmamba.py", line 509, in forward_corev2
assert selective_scan_backend in [None, "oflex", "mamba", "torch"]
AssertionError
解决方法是在这个list增加一个 “core” 即 assert selective_scan_backend in [None, "oflex", "mamba", "torch", "core"] 或者直接注释掉。
4. RuntimeError:CUDA error:no kernel image is available
正常安装 Vmamba 后出现以下报错:
RuntimeError:CUDA error:no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so ther stacktrace below might be incorrect.
这是一个常见的算力不匹配的错误,在之前的博客 VMamba 安装教程(无需更改base环境中的cuda版本) 里的 13 有解释及解决方法。需要修改 kernels/ selective_scan 里面的 setup.py 文件并重新编译。算力查询参考:Your GPU Compute Capability。
应部分同学需求,通用算力版(cuda12.4)重新编译好的 whl (只适用于torch 2.4,cuda12.4,python 3.10,GPU算力6.0-9.0)为:通用算力版(cuda12.4)selective-scan-0.0.2-cp310-cp310-win-amd64.whl(包含core) 或者 mbd优惠地址,相应生成的selective_scan_cuda_core 模块为:selective-scan-cuda-core.cp310-win-amd64.pyd;selective-scan-cuda-oflex.cp310-win-amd64.pyd。
5. ImportError: DLL load failed
有的同学在安装好之后发现出现了以下报错:
ImportError: DLL load failed while importing causal_conv1d_cuda: 找不到指定的程序。
或者是
ImportError: DLL load failed while importing selective_scan_cuda: 找不到指定的程序。
虽然在虚拟环境的相应位置中,已经生成了 causal_conv1d_cuda.cp310-win-amd64.pyd 和 selective_scan_cuda.cp310-win-amd64.pyd 但是还是无法导入调用。
在Vmamba下也类似,这种情况在之前系列博客【Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)】已经讲过多次,百分百为 python、torch 或者 cuda 版本和我的博客版本不一致。(也检查一下的所下载的包介绍里的cuda版本,因为本人编译过的版本很多)
CUDA版本需要检查:
nvcc -V
python -c "import torch.utils.cpp_extension; print(torch.utils.cpp_extension.CUDA_HOME)"
确保其输出的是正确的版本或位置。尤其是要保证第二句命令输出的位置是正确的。
在 Win 下,则使用 where nvcc 虚拟环境正确的路径(路径到bin之前,不包括 bin\nvcc),把系统环境变量里的 CUDA_PATH 修改为该路径。或者在base环境里也装这个cuda内核版本(去nvidia官网下载安装包,譬如12以上的版本可以自动配置环境变量)。
反正需要保证识别到的cuda版本是对的。
从【Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)】检测到的dll依赖项来看,它需要的依赖项为: torch_cpu.dll/torch_python.dll (torch版本)、python310.dll (python 版本)、c10.dll/c10_cuda.dll (cuda版本,12.4 下面不是这个名字,此处是11.8的示例)。
虚拟环境下,torch的dll位置是:xxx\envs\xxx\Lib\site-packages\torch\lib
6. 算力12.0 GPU版本 (20250330更新)
本人在编译前面的安装包时已经囊括了算力 6.0~9.0 的GPU型号,但是随着英伟达的更新,出现了 GeForce RTX 5070,5070Ti,5080,以及5090等算力高达 12.0 的GPU。即使是 Mamba 官方也最高只考虑到了算力 9.0 的显卡。
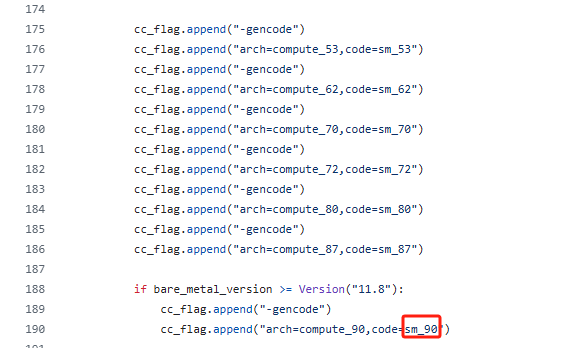
需要在 setup.py 这个地方再加入
cc_flag.append("-gencode")
cc_flag.append("arch=compute_120,code=sm_120")
然后再手动编译。
否则在高算力GPU下,可能会出现前述的 RuntimeError:CUDA error:no kernel image is available 的问题。
或者出现显卡与PyTorch 不兼容的情况,输出 nvrtc: error: invalid value for --gpu-architecture (-arch):
UserWarning:
NVIDIA GeForce RTX 5070 Ti with CUDA capability sm_120 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 sm_80 sm_86 sm_90 compute_37.
If you want to use the NVIDIA GeForce RTX 5070 Ti GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
......
nvrtc: error: invalid value for --gpu-architecture (-arch)

这个版本的同学请直接移步::Windows 下 Mamba / Vim / Vmamba 环境配置安装教程(适用于5070,5080,5070Ti等GTX 50系显卡)
7. Mamba2 出现 IndexError: invalid map<K, T> key 或者 IndexError: map::at (20250401更新)
评论区有同学运行 mamba2 时出现 triton 报错:
stages["llir"] = lambda src, metadata: self.make_llir(src, metadata, options, self.capability)
File "E:\miniconda3\envs\mamba2\lib\site-packages\triton\backends\nvidia\compiler.py", line 222, in make_llir
pm.run(mod)
IndexError: invalid map<K, T> key
以及出现问题:
File "/samba/network-storage/toshiba/cache/envs/mamba-env/lib/python3.10/site-packages/triton/compiler/backends/cuda.py", line 173, in make_llir
ret = translate_triton_gpu_to_llvmir(src, capability, tma_infos, runtime.TARGET.NVVM)
IndexError: map::at
经过大家的验证(感谢 姓蔡小朋友 ,何成暮雨912),发现是 triton 在 Turing 架构的显卡上的bug,解决方案参考:Mamba-2: IndexError: map::at。
同样问题的issue在triton仓库中也有(例如:triton-lang/triton#4813、triton-lang/triton#3011)。Triton 似乎没有正确处理TF32张量核心乘法不被像Turing这样的架构支持的情况(Turing只支持fp16)。
根据triton/README.md,可以通过设置TRITON_F32_DEFAULT环境变量来控制张量核心乘法的默认输入精度。即在调用triton之前,在代码的开头设置:
import os
os.environ["TRITON_F32_DEFAULT"] = "ieee"
Turing(图灵)架构(2018)的显卡1(即受此问题影响的显卡)主要有:
- GeForce RTX 20系列:RTX 2080 Ti、RTX 2070、RTX 2060。
- Titan RTX:高端消费级显卡。
- Quadro RTX系列:如Quadro RTX 8000,Tesla T4 用于专业图形工作站。
- 中低端显卡:GeForce GTX 1650等
后记
经过系列迭代以及与各位大佬的努力,最终实现了在 Windows 上正常运行 Mamba (含Mamba2)、Vision Mamba(Vim)以及 Vmamba,从最初需要绕过 causal-conv1d-cuda / selective-scan-cuda 的编译(Mamba 官方未考虑Windows下运行),再到需要绕过所有的 Triton 包(Triton 官方只有Linux版),到现在不需要绕过任何东西实现不输Linux的速度,本系列画上了一个比较圆满的句号。其中遇到的所有问题均已记录至本系列博客中,系列博客中已提到的问题请不要重复提问。