导航
安装教程导航
Mamba 及 Vim 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(初版)- Linux 下 Mamba 安装问题参看本人博客:Mamba 环境安装踩坑问题汇总及解决方法(重置版)
- Windows 下 Mamba 的安装参看本人博客:Window 下Mamba 环境安装踩坑问题汇总及解决方法 (无需绕过selective_scan_cuda)
- Linux 下 Vim 安装问题参看本人博客:Linux 下 Vim 环境安装踩坑问题汇总及解决方法(重置版)
- Windows 下 Vim 安装问题参看本人博客:Window 下 Vim 环境安装踩坑问题汇总及解决方法
- Linux 下Vmamba 安装教程参看本人博客:Vmamba 安装教程(无需更改base环境中的cuda版本)
- Windows 下 VMamba的安装参看本人博客:Windows 下 VMamba 安装教程(无需更改base环境中的cuda版本且可加速)
- Windows下 Mamba2及高版本 causal_conv1d 安装参考本人博客:Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)
- Windows 下 Mamba / Vim / Vmamba 环境安装终极版参考本人博客:Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)
- (GPU算力12.0版本)Windows 下 Mamba / Vim / Vmamba 环境配置教程 参考本人博客:Windows 下 Mamba / Vim / Vmamba 环境配置安装教程(适用于5070,5080,5070Ti等GTX 50系显卡)
安装教程及安装包索引
不知道如何入手请先阅读新手索引:Linux / Windows 下 Mamba / Vim / Vmamba 安装教程及安装包索引
本系列教程已接入ima知识库,欢迎在ima小程序里进行提问!(如问题无法解决,安装问题 / 资源售后 / 论文合作想法请+文末vx)
背景
在之前的系列博客中已经实现了 Mamba / Vim / Vmamba 的完整体,随着英伟达2025年3月发布全新的 GeForce RTX 50系列 (5070,5080,5070Ti,5090等),很多同学购买到了这一代的GPU,它由 NVIDIA Blackwell RTX 架构和 DLSS 4 多帧生成技术驱动,GPU算力高达 12.0(算力查询参考:Your GPU Compute Capability),实测发现其需要的cuda及torch版本非常高,原来的博客环境无法兼容,甚至于这些源码的官方代码都无法兼容这么高的算力平台(最高只到9.0),因此再次更新编译,主要流程与之前博客 “Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)” 相似,但是会有非常多新问题。
本博客安装版本为:mamba_ssm-2.2.2 和 causal_conv1d-1.4.0,CUDA 版本为12.8,pytorch 版本为 2.8.0。
编译步骤
1. Windows 下前期环境准备
前期环境准备,类似本人原来博客 “Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)” ,但是由于 RTX 50系列 对 CUDA 版本的高要求,所以更改为 CUDA 版本为12.8,pytorch 版本为 2.8.0。
- 1.1 CUDA 准备
由于CUDA版本过高,原来的cuda-nvcc方法暂不支持,因此直接在主环境中安装CUDA12.8的驱动:
CUDA Toolkit 12.8 Downloads | NVIDIA Developer
- 1.2 pytorch 安装
由于 pytorch 2.8 的版本过高,没有稳定版,只能安装预览版。
首先新建虚拟环境:
conda create -n mamba python=3.10
conda activate mamba
# CUDA 12.8
pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/cu128
python -c "import torch; print(torch.cuda.is_available())" # 验证torch安装
由于上述过程比较慢,可以从官网直接下载 whl 到本地,然后直接安装:
torch-2.8.0.dev20250323,torchvision-0.22.0,(torchaudio-2.6.0,可选)
然后切换到whl所在目录,在虚拟环境下安装:
pip install torch-2.8.0.dev20250323+cu128-cp310-cp310-win_amd64.whl
pip install torchvision-0.22.0.dev20250321+cu128-cp310-cp310-win_amd64.whl
pip install torchaudio-2.6.0.dev20250325+cu128-cp310-cp310-win_amd64.whl # 可选
python -c "import torch; print(torch.cuda.is_available())" # 验证torch安装
2. triton-windows 环境准备
配置参考本人之前博客 Windows 下安装 triton 教程 。主要是利用大佬的工作:triton-windows。triton 官方目前只支持Linux系统,之前系列博客中安装的 triton 包只是大佬强行打包,配置均在Linux下,无法实现triton 核心的 triton.jit 和 torch.compile 等功能,配置过程包括:
- 安装 MSVC 和 Windows SDK
- 修改环境变量
- vcredist 安装(可选)
注意,triton-windows 所在github上发布的triton-windows的whl版本目前(截至20250331)没有更高的支持 50系列的 3.3.0 以上版本,但是在 pypi 上发现有 3.3.0 版本,项目地址为:https://pypi.org/project/triton-windows/,我们直接安装它的最新(截至20250331)编译版本 3.3.0a0.post17:
pip install triton-windows==3.3.0a0.post17
或者直接下载 triton_windows-3.3.0a0.post17-cp310-cp310-win_amd64.whl 安装。
实测其他旧版本会在 Mamba2 里面报错,后文会提到。
3. Mamba 编译
- 3.1 从源码编译causal-conv1d 1.4.0 版本
步骤还是参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”,由于在主环境里安装了cuda12.8 的全部核心,因此可以直接从源码编译,下载工程文件(笔者使用的源码版本是1.4.0),即
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
修改源码文件,参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”。
修改 setup.py 文件,将
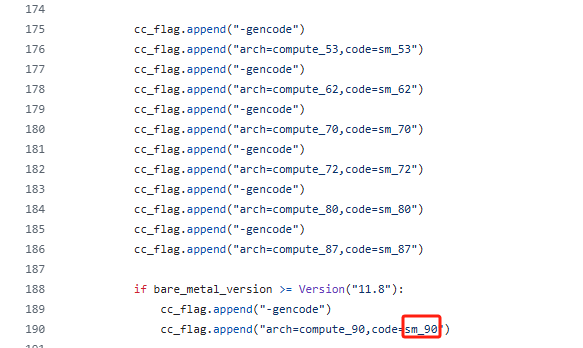
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_90,code=sm_90")
改为:
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_120,code=sm_120")
然后执行编译:
set CAUSAL_CONV1D_FORCE_BUILD=TRUE # 也可修改setup.py相应位置
pip install .
成功编译之后,会在相应虚拟环境中(xxx\conda\envs\xxx\Lib\site-packages\)产生 causal_conv1d_cuda.cp310-win_amd64.pyd 文件,此文件对应 causal_conv1d_cuda 包。
官方没有编译好的适用于Windows版本的 whl,因此需要用上述步骤来手动编译。笔者编译好了 Windows 下的 (cuda12.8)causal-conv1d-1.4.0-cp310-cp310-win-amd64.whl 或者 优惠地址,亦可直接下载安装(只适用于torch 2.8,cuda12.8,python 3.10,GPU算力12.0)。(不要急着下,先看完,后面还有全家桶)
pip install causal_conv1d-1.4.0-cp310-cp310-win_amd64.whl
- 3.2 从源码编译 mamba-ssm2.2.2 版本
步骤还是参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”,下载工程文件(笔者使用的源码版本是2.2.2),即
git clone https://github.com/state-spaces/mamba.git
cd mamba
修改源码文件,参考本人原来博客 “Windows 下Mamba2 环境安装问题记录及解决方法(causal_conv1d=1.4.0)”。
修改 setup.py 文件,将
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_90,code=sm_90")
改为:
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_120,code=sm_120")
将 文件 pyproject.toml 里面 triton 改成 triton-windows。
然后执行编译:
set MAMBA_FORCE_BUILD=TRUE # 也可修改setup.py第40行
pip install . --no-build-isolation
编译成功后,在虚拟环境中(xxx\conda\envs\xxx\Lib\site-packages\)产生了 selective_scan_cuda.cp310-win-amd64.pyd 文件,此文件对应 selective_scan_cuda 包。
笔者编译好了 Windows 下的 (cuda12.8)mamba_ssm-2.2.2-cp310-cp310-win_amd64.whl 或者 【优惠地址 】以及 【全家桶csdn】,【全家桶优惠】,亦可直接下载安装(只适用于torch 2.8,cuda12.8,python 3.10,GPU算力12.0)。
pip install mamba_ssm-2.2.2-cp310-cp310-win_amd64.whl
- 3.3 Mamba 环境运行验证
参考官方的 readme 文件,运行以下示例:
import torch
from mamba_ssm import Mamba
from mamba_ssm import Mamba2
batch, length, dim = 2, 64, 16
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=16, # SSM state expansion factor
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
y = model(x)
assert y.shape == x.shape
print('Mamba:', x.shape)
batch, length, dim = 2, 64, 256
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba2(
# This module uses roughly 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=64, # SSM state expansion factor, typically 64 or 128
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
y = model(x)
assert y.shape == x.shape
print('Mamba2:', x.shape)
正常输出结果无报错。
4. Windows 下 Vim 的安装
- 4.1 从源码编译causal-conv1d 1.1.1 版本
Vim 官方代码仓给的 causal-conv1d 源码有误,过于老旧且不兼容,causal-conv1d版本应≥1.1.0,其他部分还是参考原来的博客 Window 下 Vim 环境安装踩坑问题汇总及解决方法,我们这里采用1.1.1 版本:
git clone https://github.com/Dao-AILab/causal-conv1d.git
cd causal-conv1d
git checkout v1.1.1
也可以直接从 github 里面下载 1.1.1 版本的源码。
然后修改 setup.py 文件,将
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_90,code=sm_90")
改为:
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_120,code=sm_120")
然后执行编译:
set CAUSAL_CONV1D_FORCE_BUILD=TRUE # 也可修改setup.py相应位置
pip install .
成功编译之后,会在相应虚拟环境中(xxx\conda\envs\xxx\Lib\site-packages\)产生 causal_conv1d_cuda.cp310-win_amd64.pyd 文件,此文件对应 causal_conv1d_cuda 包。
笔者编译好了 Windows 下的 (cuda12.8)causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl 或者 优惠地址 ,亦可直接下载安装(只适用于torch 2.8,cuda12.8,python 3.10,GPU算力12.0)。
pip install causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl
- 4.2 从源码编译 mamba-ssm 1.1.1 版本
Vim 官方对 mamba-ssm 的源码进行了修改,所以其与原版有不同,可以直接强行利用Vim的源码进行编译,参考原来的博客 Window 下 Vim 环境安装踩坑问题汇总及解决方法。
此外,需要修改 Vim-main\mamba-1p1p1 下的setup.py 文件,将
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_90,code=sm_90")
改为:
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_120,code=sm_120")
同时将末尾 install_requires 里面的 triton 改成 triton-windows。
然后执行编译:
set MAMBA_FORCE_BUILD=TRUE # 也可修改setup.py第40行
pip install .
编译成功后,在虚拟环境中(xxx\conda\envs\xxx\Lib\site-packages\)产生了 selective_scan_cuda.cp310-win-amd64.pyd 文件,此文件对应 selective_scan_cuda 包,其包含 Vim 的库,但是显示的还是 mamba_ssm。
本人编译好的Windows 下的适用于Vim的whl 也有:(Vim)(cuda12.8)mamba-ssm-1.1.1-cp310-cp310-win-amd64.whl (只适用于torch 2.8,cuda12.8,python 3.10,GPU算力12.0)或者 优惠地址 以及 【全家桶csdn】,【全家桶优惠】。利用 whl 安装命令为:
pip install mamba_ssm-1.1.1-cp310-cp310-win_amd64.whl --no-dependencies causal_conv1d
- 4.3 Vim 环境运行验证
环境运行验证见 Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)。
5. Windows 下 Vmamba 的安装
此处的编译依旧参考原来的博客:Windows 下 VMamba 安装教程(无需更改base环境中的cuda版本且可加速) 。
下载好 Vmamba 官方的源码,用 git 下载方式如下:
git clone https://github.com/MzeroMiko/VMamba.git
cd VMamba
然后参考原来的博客修改源码。
Vmamba 里面新版的 setup.py 已经考虑了不同的算力,直接是:
cc_flag.append(f"-arch=sm_{
get_compute_capability()}")
如果你不放心,可以把这行注释掉,然后改为:
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_120,code=sm_120")
如果需要 core,在 setup.py 选用的模式改为
MODES = ["core", "oflex"]
最后执行编译。
Win 下面编译好的 whl (只适用于torch 2.8,cuda12.8,python 3.10,GPU算力12.0)为:(cuda12.8)selective-scan-0.0.2-cp310-cp310-win-amd64.whl(包含core) 或者 mbd优惠地址。
环境运行验证见 Windows 下Mamba2 / Vim / Vmamba 环境安装问题记录及解决方法终极版(无需绕过triton)。
出现的问题
1. ERROR: No matching distribution found for triton
在编译 vim 或者 mamba 时,出现:
ERROR: Could not find a version that satisfies the requirement triton (from mamba-ssm) (from versions: none)
ERROR: No matching distribution found for triton
如图示:

这是因为我们此时安装的是 triton-windows,因此需要把 triton 改成 triton-windows。
对于 mamba2 以下版本的源码(Vim 就是改的 mamba1.1.1),修改 setup.py 末尾 install_requires 里面的 triton 改成 triton-windows。
对于 mamba2 及以上版本的源码,将 文件 pyproject.toml 里面 triton 改成 triton-windows。
2. Assertion failed: false && “computeCapability not supported”
验证 Mamba2 的时候,出现报错:
Assertion failed: false && "computeCapability not supported", file C:\triton\lib\Dialect\TritonGPU\Transforms\AccelerateMatmul.cpp, line 40
File "C:\ProgramData\anaconda3\envs\vmamba\lib\site-packages\triton\backends\nvidia\compiler.py", line 311, in make_ttgir
pm.run(mod)
RuntimeError: PassManager::run failed
如图示:
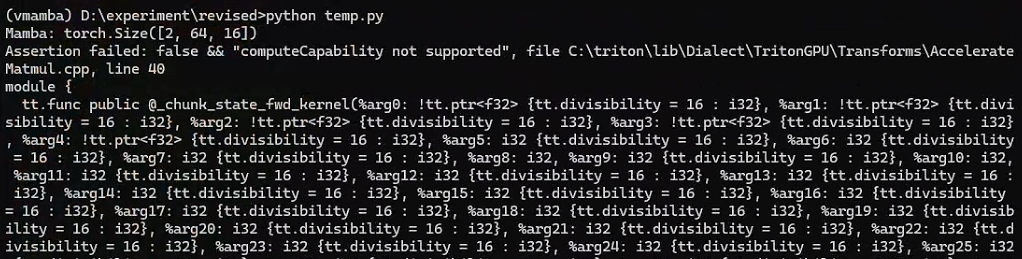
这里的原因是安装的 triton-windows 版本还暂不支持算力12.0 以上的GPU,参考:triton/issues/6087,检查发现此时安装的版本是 triton_windows-3.3.0a0.post11。安装比较新的版本 triton_windows-3.3.0a0.post17 即可解决该问题。
后记
本博客只针对 GPU算力为12.0 的电脑,其他普通算力的还是参考之前的博客。有意思的是,即使是 Mamba 官方,其源码里支持的GPU算力最高还是 9.0(截至20250331):
因此在Linux 平台,仍需要自己手动编译,官方没有现成的whl安装包,Linux下编译不需要动源码,只需要类似修改 setup.py 文件。