1. 这些名词是什么,为什么需要?
1.1. 从 for 循环到迭代器
传统迭代的局限性
假设有一个需求:遍历一个包含1亿个元素的序列,如果用传统列表实现:
# 传统列表存储(内存灾难)
nums = [x for x in range(100_000_000)] # 立即生成所有元素,占用约800MB内存
for num in nums:
print(num)问题:列表一次性加载全部数据到内存,导致内存爆炸!
而迭代器(Iterator)通过 __next__() 按需生成元素,但需要手动实现:
class RangeIterator:
def __init__(self, start, end):
self.current = start
self.end = end
def __iter__(self):
return self
def __next__(self):
if self.current >= self.end:
raise StopIteration
value = self.current
self.current += 1
return value
# 使用迭代器(内存占用≈0,每次只存一个数)
nums_iter = RangeIterator(0, 100_000_000)
for num in nums_iter:
print(num)虽然迭代器解决了内存问题,但需要开发者手动编写 __next__ 逻辑,代码冗长。
2. 为什么需要生成器?从内存效率到语法简化
假设需要生成 1亿个随机数:
方法1:传统 for 循环
import random
import sys
def get_random_list(n):
return [random.randint(0, 100) for _ in range(n)]
data_list = get_random_list(100_000_000)
print(sys.getsizeof(data_list)) # 835,128,600 字节(835MB)方法2:生成器
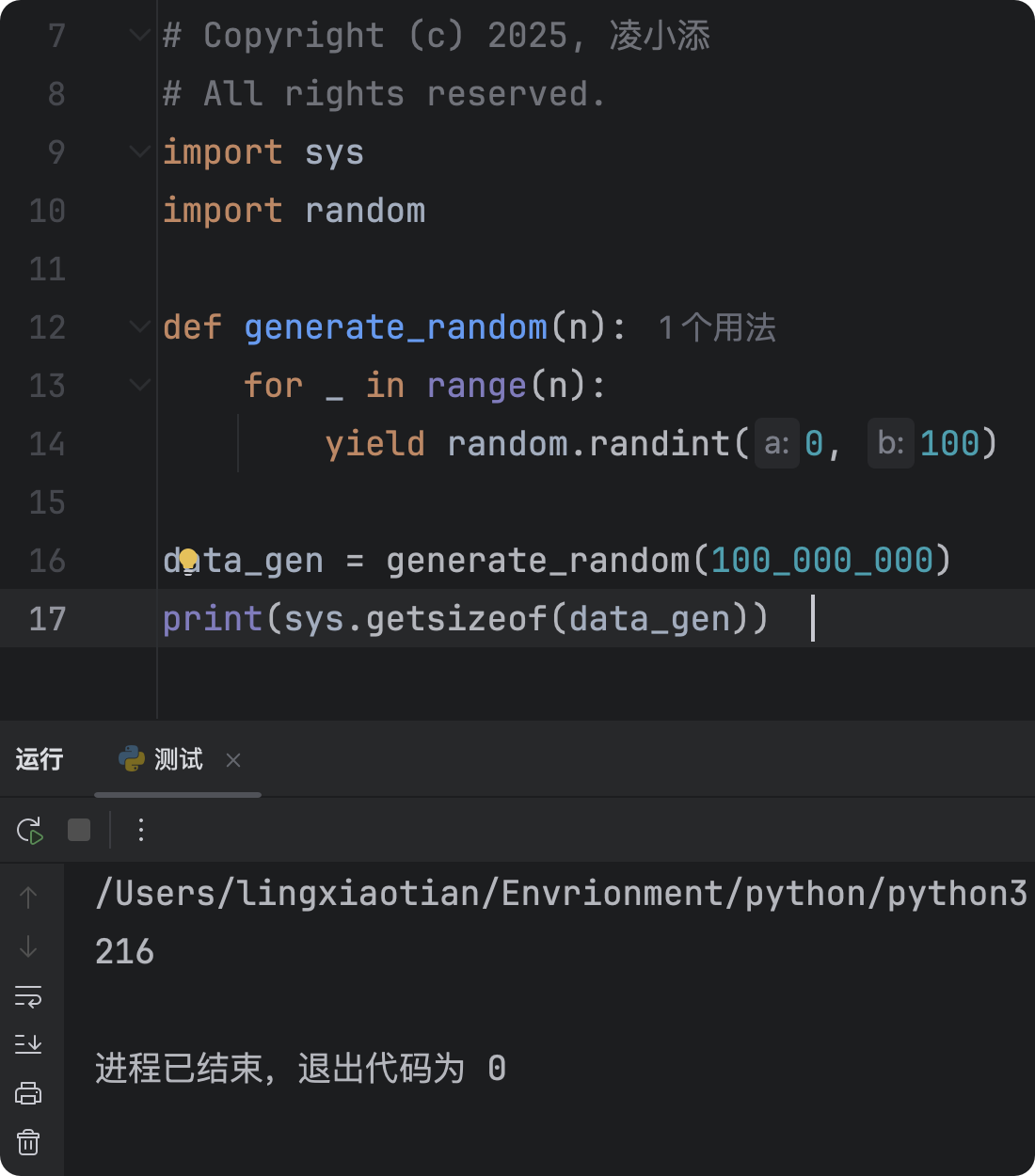
import random
import sys
def generate_random(n):
for _ in range(n):
yield random.randint(0, 100)
data_gen = generate_random(100_000_000)
print(sys.getsizeof(data_gen)) # 仅 216 字节(0.2KB)我们可以看到,使用生成器的内存占用极大的缩小了!
2. 迭代器详解
2.1. 迭代器(Iterator)概念
在Python中,迭代器是实现数据序列遍历的核心机制。它提供了一种统一的方式,按需逐个访问集合中的元素,而无需提前将所有数据加载到内存中。
核心功能:
- 惰性求值(Lazy Evaluation):仅在需要时生成元素。
- 单向遍历:元素只能顺序访问,不可回退或重复遍历。
设计目的:
- 解决大规模数据场景下的内存效率问题。
- 提供统一的遍历接口(如
for循环、next()函数)。
可以将迭代器理解为一种更高级的遍历方式,就像在吃自助餐时:
- 所有菜品已摆在餐台上(数据已存在)
- 你拿餐盘按顺序取餐(遍历)
- 不能把吃掉的鸡腿放回去(不可逆)
2.2. 迭代器协议(Iterator Protocol)
迭代器必须实现两个核心方法:
__iter__()
• 返回迭代器自身(即 self)。
class MyIterator:
def __iter__(self):
return self__next__()
• 返回下一个元素,无元素时抛出 StopIteration。
class CountUp:
def __init__(self, limit):
self.limit = limit
self.current = 0
def __iter__(self):
return self
def __next__(self):
if self.current >= self.limit:
raise StopIteration
self.current += 1
return self.current - 1
# 使用自定义迭代器
counter = CountUp(3)
print(next(counter)) # 0
print(next(counter)) # 12.3. 迭代器与可迭代对象的区别
可迭代对象(Iterable):
• 定义:任何实现了 __iter__() 方法 或 __getitem__() 方法的对象。
• 常见类型:列表、元组、字符串、字典、文件对象等。
• 核心功能:能够被 for 循环遍历。
my_list = [1, 2, 3]
print(hasattr(my_list, "__iter__")) # True → 是 Iterable迭代器(Iterator):
• 定义:实现了 __next__() 方法的对象(必须返回下一个元素,无元素时抛出 StopIteration)。
• 核心功能:通过 next() 函数逐步获取元素。
my_iter = iter([1, 2, 3])
print(next(my_iter)) # 1
print(next(my_iter)) # 2关系:
• 迭代器一定是可迭代对象(迭代器需实现 __iter__(),通常返回自身)。
• 可迭代对象不一定是迭代器(如列表不是迭代器,但可以通过 iter() 转换)。
2.4. 迭代器的优势
内存高效性
• 传统列表:一次性加载所有元素,占用内存与数据量成正比。
• 迭代器:按需生成元素,内存占用固定(仅保存当前状态)。
# 处理1GB文件,逐行读取
with open("huge_file.txt", "r") as f:
for line in f: # 文件对象本身是迭代器
process(line) # 仅单行驻留内存延迟计算(Lazy Evaluation)
• 仅在需要时计算元素,适用于无限序列或复杂计算。
# 生成无限偶数序列
class InfiniteEvens:
def __init__(self):
self.current = 0
def __iter__(self):
return self
def __next__(self):
value = self.current
self.current += 2
return value
evens = InfiniteEvens()
print(next(evens)) # 0
print(next(evens)) # 2通用性
• 任何可迭代对象均可通过 iter() 转换为迭代器,统一遍历接口。
my_dict = {"a": 1, "b": 2}
dict_iter = iter(my_dict) # 获取字典键的迭代器
print(next(dict_iter)) # 'a'2.5. 迭代器的限制
单向性:
迭代器只能向前移动,无法回退或重置。
my_iter = iter([1, 2, 3])
print(next(my_iter)) # 1
print(next(my_iter)) # 2
# 无法回到1,除非重新创建迭代器一次性消费:
迭代器遍历结束后,再次调用 next() 会永久触发 StopIteration。
my_iter = iter([1, 2])
print(next(my_iter)) # 1
print(next(my_iter)) # 2
print(next(my_iter)) # ❌ StopIteration无法随机访问:
迭代器不像列表,并不支持下标操作(如 my_iter[0]),只能顺序访问。
2.6. 迭代器的实际应用场景
处理大规模数据:
逐行读取文件、数据库查询结果分批处理。
def read_batches(file_path, batch_size=1000):
with open(file_path, "r") as f:
batch = []
for line in f:
batch.append(line.strip())
if len(batch) == batch_size:
yield batch
batch = []
if batch: # 处理剩余数据
yield batch
# 分批处理100万行日志
for batch in read_batches("large_log.txt"):
process_batch(batch)构建数据管道:
将多个迭代器组合,实现数据流水线处理。
def filter_positive(numbers):
for n in numbers:
if n > 0:
yield n
def square(numbers):
for n in numbers:
yield n ** 2
# 组合迭代器
data = [-2, 3, 0, 5]
pipeline = square(filter_positive(data))
print(list(pipeline)) # [9, 25]与生成器协同工作
生成器是迭代器的语法糖,简化迭代器创建,文章稍后会介绍什么是生成器。
# 生成器函数自动实现迭代器协议
def fibonacci(limit):
a, b = 0, 1
while a < limit:
yield a
a, b = b, a + b
fib_iter = fibonacci(10)
print(next(fib_iter)) # 02.7. 何时使用迭代器?
| 场景 |
使用迭代器 |
使用列表 |
| 数据量极大(如GB级文件) |
✅ |
❌(内存溢出) |
| 只需单次遍历 |
✅ |
⚠️(可能浪费内存) |
| 需要惰性求值(如无限序列) |
✅ |
❌(无法表示无限) |
| 需多次随机访问元素 |
❌ |
✅ |
迭代器是 python 的高级语法,掌握后可显著提升代码性能和资源利用率,尤其在大数据、流式处理场景中不可或缺。
3. 生成器详解
3.1. 生成器概念
生成器(Generator)是Python中实现惰性求值的强大工具,它通过yield关键字动态生成数据而非一次性加载全部内容,特别适合处理大规模数据、无限序列和异步任务。
生成器是特殊迭代器,其核心特征是通过yield实现暂停与恢复执行的机制。
它自动满足迭代器协议(需实现 __iter__ 和 __next__ 方法),但语法比普通迭代器更简洁。
特性:
• 惰性求值(Lazy Evaluation):仅在需要时生成值,避免爆内存。
• 状态保存:每次yield暂停时保留局部变量和执行位置,下次从断点继续。
与普通函数比较:
| 维度 |
普通函数 |
生成器 |
| 返回值 |
|
|
| 内存占用 |
数据全加载至内存 |
仅保存当前状态,内存极低 |
| 适用场景 |
小数据集、需多次访问 |
大数据、流式处理、无限序列 |
3.2. 生成器的创建方式
生成器函数:
• 语法:通过def定义,函数体内包含至少一个yield语句。
• 示例:斐波那契数列生成器
def fibonacci(limit):
a, b = 0, 1
while a < limit:
yield a
a, b = b, a + b调用生成器函数时返回生成器对象,代码执行到 yield 时暂停并返回值。
生成器表达式:
• 语法:类似列表推导式,但用()包裹,按需生成值。
• 示例:
squares = (x**2 for x in range(10)) # 生成器表达式与列表推导式[x**2 for x in range(10)]相比,内存占用大幅降低。
3.3. 生成器的工作原理
- 执行流程
• 初始化:调用生成器函数返回生成器对象,代码不立即执行。
• 首次next():从函数起点执行到第一个yield,返回右侧值并暂停。
• 后续next():从上次暂停处继续执行,直到下一个yield或结束。
• 终止:函数执行完毕或调用.close()时触发StopIteration。 - 状态保存机制
生成器通过栈帧(Stack Frame)保存局部变量(如a, b在斐波那契生成器中)和程序计数器(执行位置),实现断点续传。 - 每次调用
next(),生成器从上次的yield处恢复,保留所有局部变量:
def stateful_generator():
x = 0
yield x # 第一次 next() 返回0,暂停在此处
x += 10
yield x # 第二次 next() 返回10,暂停
x *= 2
yield x # 第三次 next() 返回20
gen = stateful_generator()
print(next(gen)) # 0
print(next(gen)) # 10
print(next(gen)) # 203.4. 生成器的典型应用场景
处理超大规模数据
示例:逐行读取文件,避免一次性加载10GB日志文件。
def read_giant_log(filename):
with open(filename, "r") as f:
for line in f: # 文件对象本身是迭代器
if "ERROR" in line:
yield line.strip()
# 使用生成器逐行处理
for error_line in read_giant_log("server.log"):
send_alert(error_line) # 假设这是一个发送报警的函数生成无限序列
示例:实时传感器数据流、唯一ID生成器。
def infinite_counter():
count = 0
while True:
yield count
count += 1构建数据管道(Pipeline)
链式处理:将多个生成器串联,实现数据清洗、转换和过滤。
def filter_even(numbers):
for num in numbers:
if num % 2 == 0: yield num
pipeline = filter_even(infinite_counter())协程与异步编程
双向通信:通过.send(value)向生成器发送数据,实现轻量级协程。
def coroutine():
total = 0
while True:
value = yield total
total += value3.5. 生成器的高级用法
1. 控制方法
• .send(value):向生成器注入数据,需先调用next()启动。
• .throw(exc):在生成器内部抛出指定异常,用于错误处理。
• .close():强制终止生成器,释放资源。
2. 生成器委派(yield from)
• 语法:简化嵌套生成器的调用,实现任务委派。
def sub_generator():
yield "子生成器"
def main_generator():
yield from sub_generator()3. 上下文管理器
• 示例:自动管理资源(如数据库连接)。
@contextmanager
def db_connection(conn_str):
conn = connect(conn_str)
try:
yield conn
finally:
conn.close()4. 生成器的高级控制:send()、throw()、close()
用 .send() 实现双向通信,生成器可以通过 yield 接收外部传入的值:
def interactive_gen():
print("Ready to receive...")
while True:
received = yield "Please send data" # yield 表达式
print(f"Received: {received}")
gen = interactive_gen()
print(next(gen)) # 输出 "Ready..." → 返回 "Please send data"
print(gen.send("Hello")) # 输出 "Received: Hello" → 返回 "Please send data"
print(gen.send(123)) # 输出 "Received: 123" → 返回 "Please send data"关键点:
- 首次必须用
next()或.send(None)启动生成器。 send(value)将值注入到生成器内部,赋值给received。
用 .throw() 注入异常
在生成器内部抛出指定异常:
def exception_demo():
try:
yield "Start"
except ValueError:
yield "Error handled"
gen = exception_demo()
print(next(gen)) # 输出 "Start"
print(gen.throw(ValueError)) # 输出 "Error handled"用 .close() 终止生成器
def infinite():
try:
while True:
yield "Running..."
except GeneratorExit:
print("Generator cleaned up")
gen = infinite()
print(next(gen)) # "Running..."
gen.close() # 触发 GeneratorExit,输出 "Generator cleaned up"3.6. 常见问题解答
- 生成器与列表的区别?
生成器按需生成值,内存极低;列表一次性存储所有数据,适合多次访问。 - 生成器能否多次迭代?
不能,每次迭代后会耗尽,需重新创建生成器对象。 - 如何提前终止生成器?
调用.close()或通过.throw(GeneratorExit)触发终止。
生成器通过yield实现了惰性求值与状态保存,是处理大数据、构建流式管道和实现协程的核心工具。其核心优势在于内存高效性和代码简洁性,适用于文件处理、实时数据流和异步任务等场景。掌握生成器的高级用法(如双向通信和委派),可显著提升代码性能和可维护性。