官方文档地址:
https://github.com/QwenLM/Qwen2.5-Omni/blob/main/README_CN.md#-docker
-
检查是否安装了 Anaconda/Miniconda:
-
打开 Anaconda Prompt(如果安装了 Anaconda)。
-
如果没有安装,请访问 Anaconda 官方网站 或 Miniconda 官方网站 下载并安装。
-
miniconda里只有conda和python,而anaconda里则集成了更多的科学计算库,这里我们已anaconda为例(请注意Anaconda下载包大约5G,接受不了就去下载miniconda,真的推荐Anaconda,因为后续你的miniconda里没的还是要下)
-
-
下载安装Anaconda
然后去你的邮箱里点击下载

https://www.anaconda.com/download/success
选择对应你操作系统的版本
下一步下一步
这里红线注意下!他不推荐我们在安装过程中,自动添加环境变量!但是我太懒了,所以我勾上
最后两个选项你没关,会出现这个,这个其实就是python生态的应用商店,关了就行了

安装完成后重新打开一个shell窗口,执行
conda --version看到
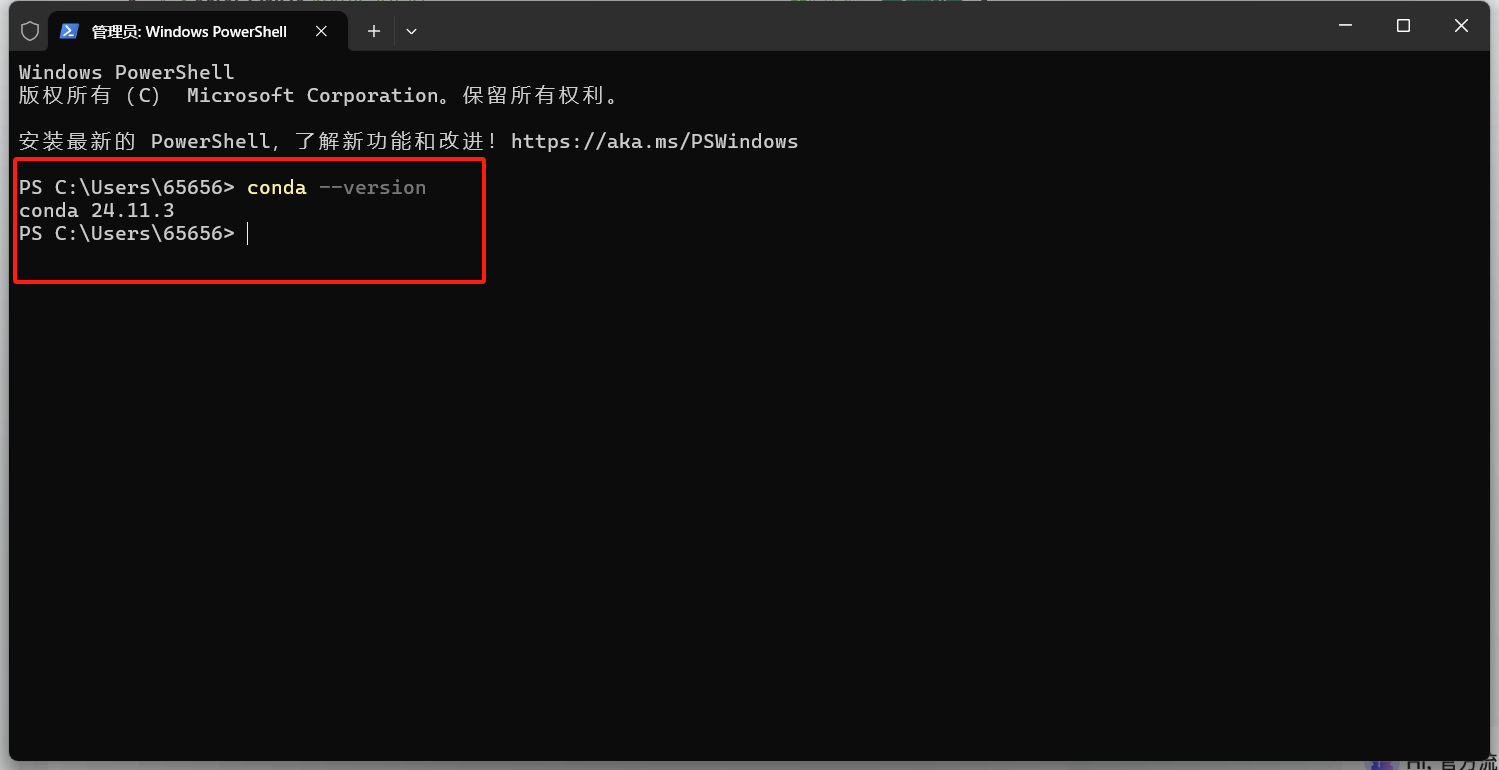
就说明安装成功了!
创建conda环境
conda create -n Qwen2.5-Omni python=3.12会看到这么一大坨,不要被吓到,下载依赖而已,输入y就完事了,虚拟环境,别担心
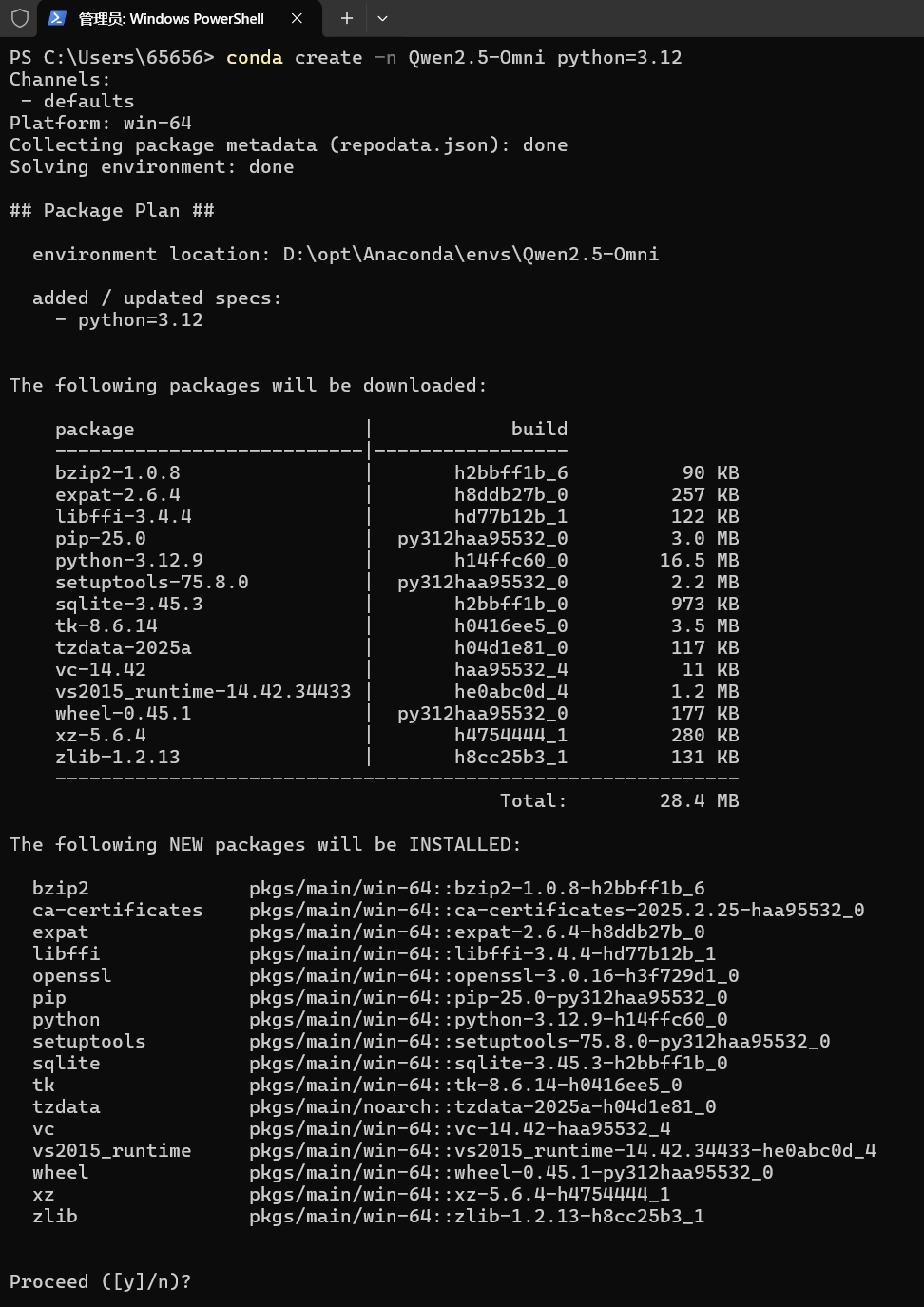
等待安装完成,其实他已经提示你怎么进入这个虚拟环境了
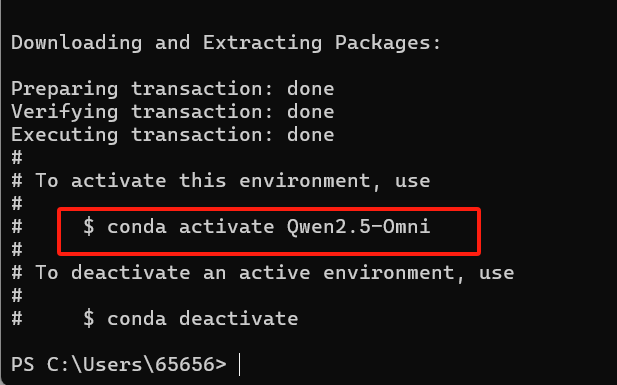
激活
conda activate Qwen2.5-Omni验证环境激活情况
conda info --envs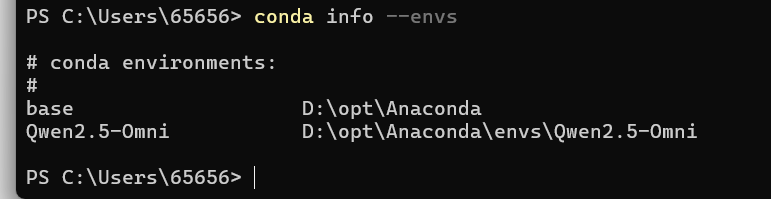
在我们虚拟环境中开始安装相关依赖包
记得临时禁用下git的ssl,不然会报错
git config --global http.sslVerify falsepip uninstall transformers
pip install git+https://github.com/huggingface/transformers@f742a644ca32e65758c3adb36225aef1731bd2a8
pip install acceleratepip install qwen-omni-utils[decord]pip install modelscope这里会用到git,没的话自己下个安装,下一步下一步就完事了,年轻人胆子大一点儿
记得红线里勾上,省的配环境变量了
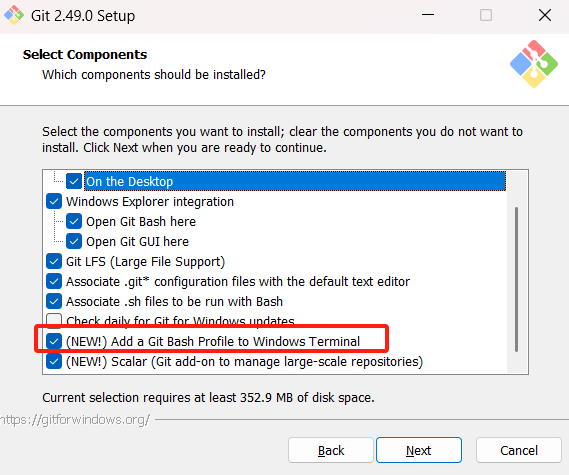
等待都安装完毕即可!
下载模型
modelscope download 'Qwen/Qwen2.5-Omni-7B' --local_dir 'D:\model\Qwen2.5-Omni'等待下载完成
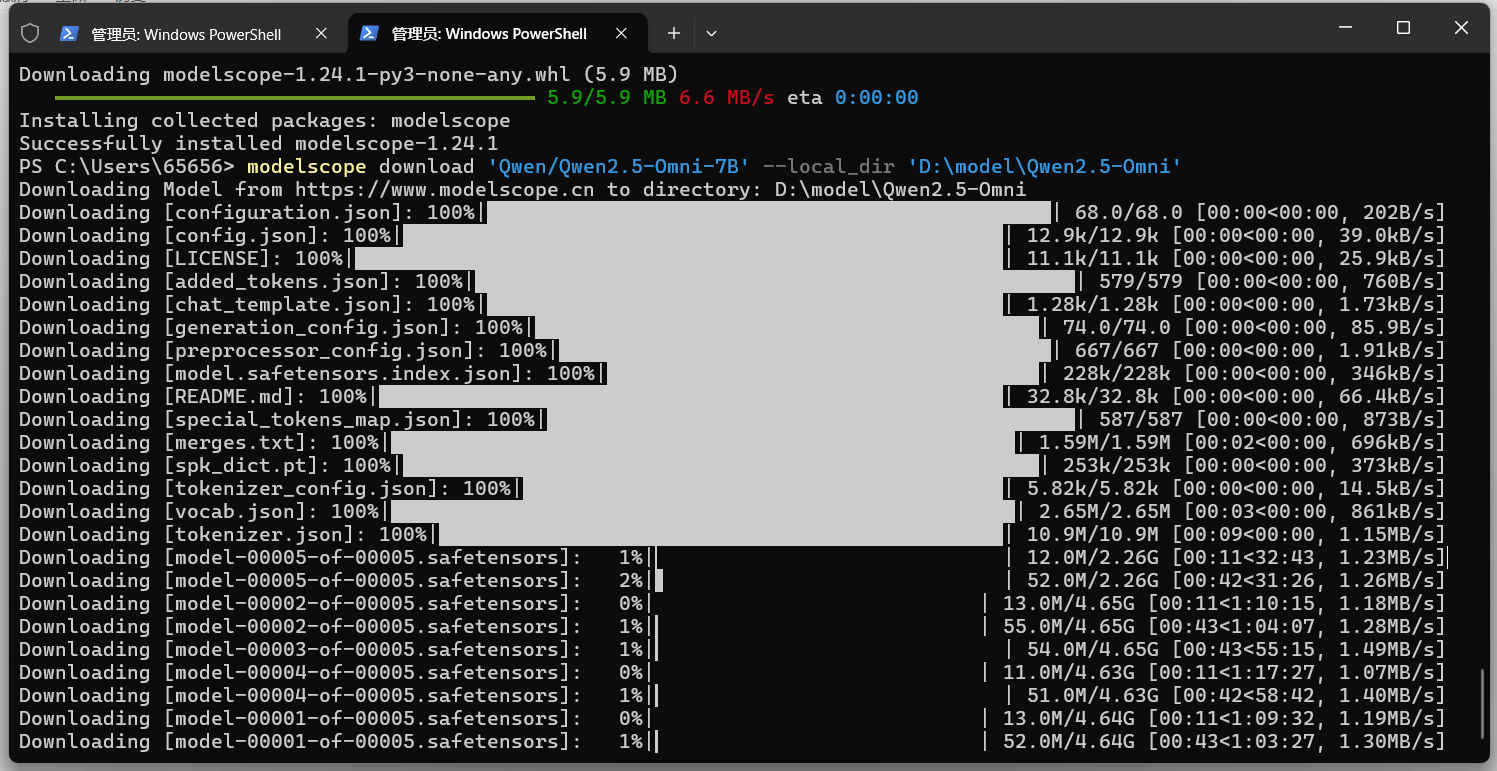
记得安装ffmpeg,不管是大模型还是其他视频,音频转文本程序都需要
https://ffmpeg.org/download.html
安装请参考
https://blog.csdn.net/Natsuago/article/details/143231558
执行官方演示代码
import soundfile as sf
from transformers import Qwen2_5OmniModel, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# default: Load the model on the available device(s)
model = Qwen2_5OmniModel.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = Qwen2_5OmniModel.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=True)
inputs = processor(text=text, audios=audios, images=images, videos=videos, return_tensors="pt", padding=True)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)这个阶段是下载和读代码
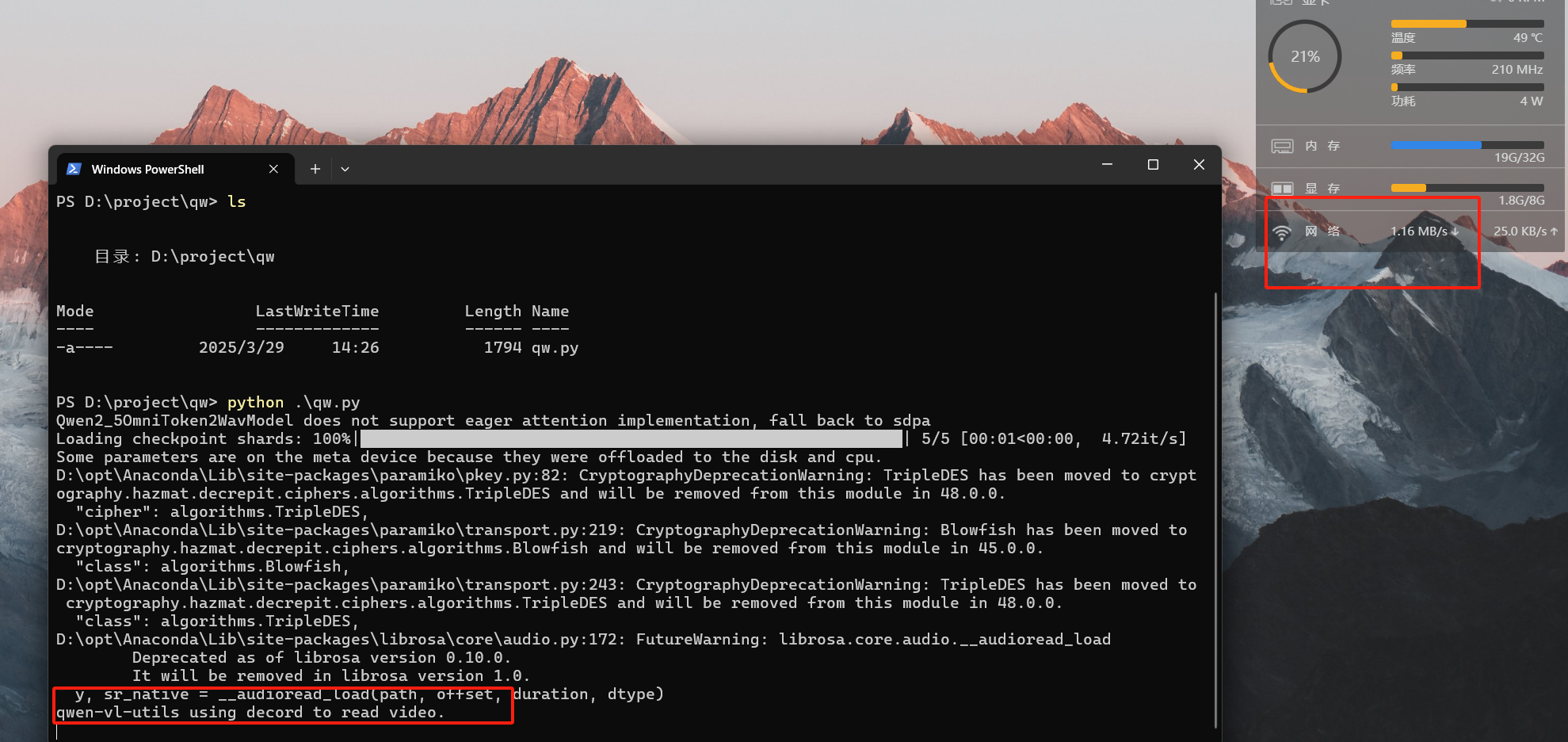
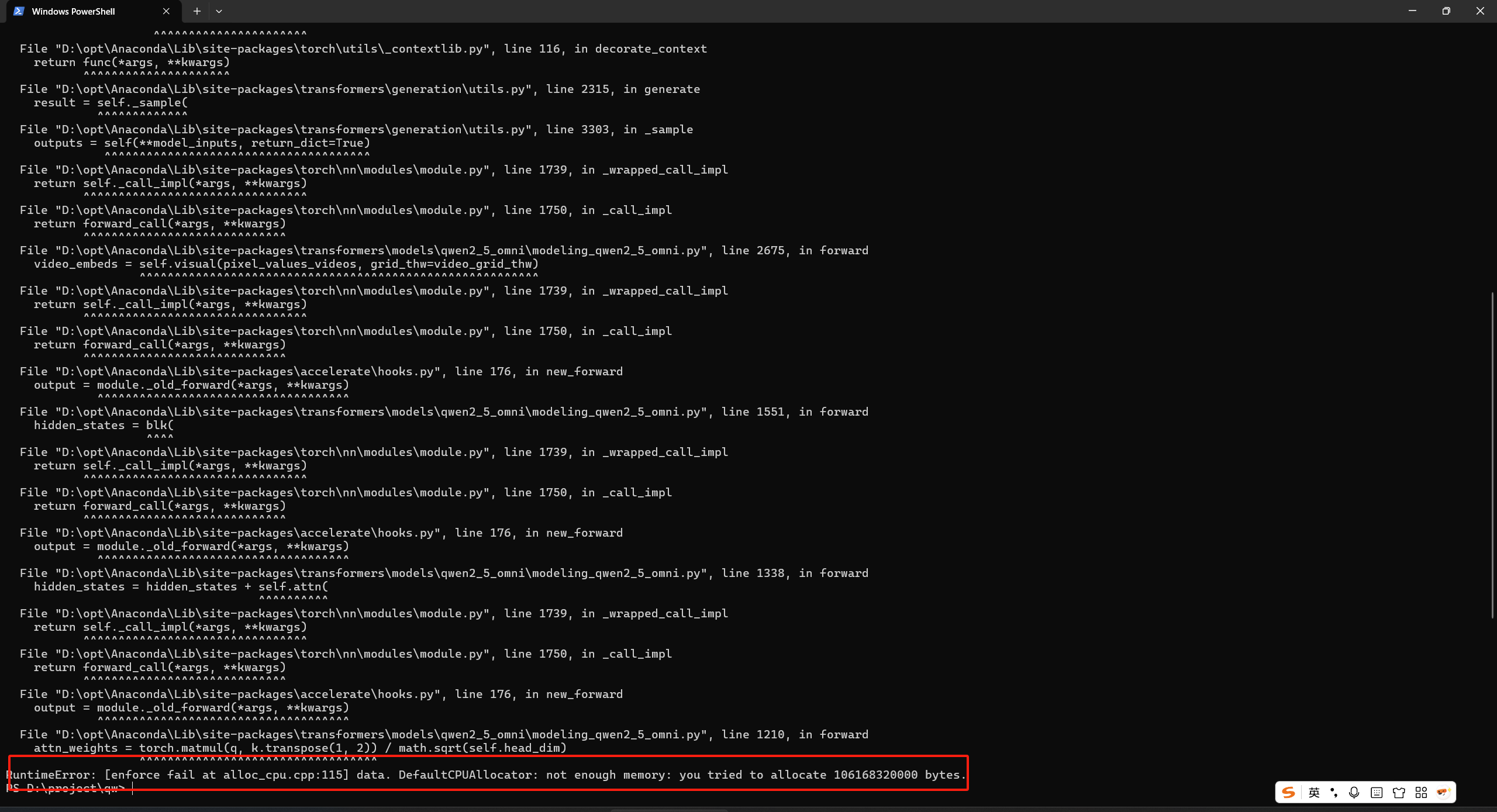
下载完成,cpu开始启动模型分析视频
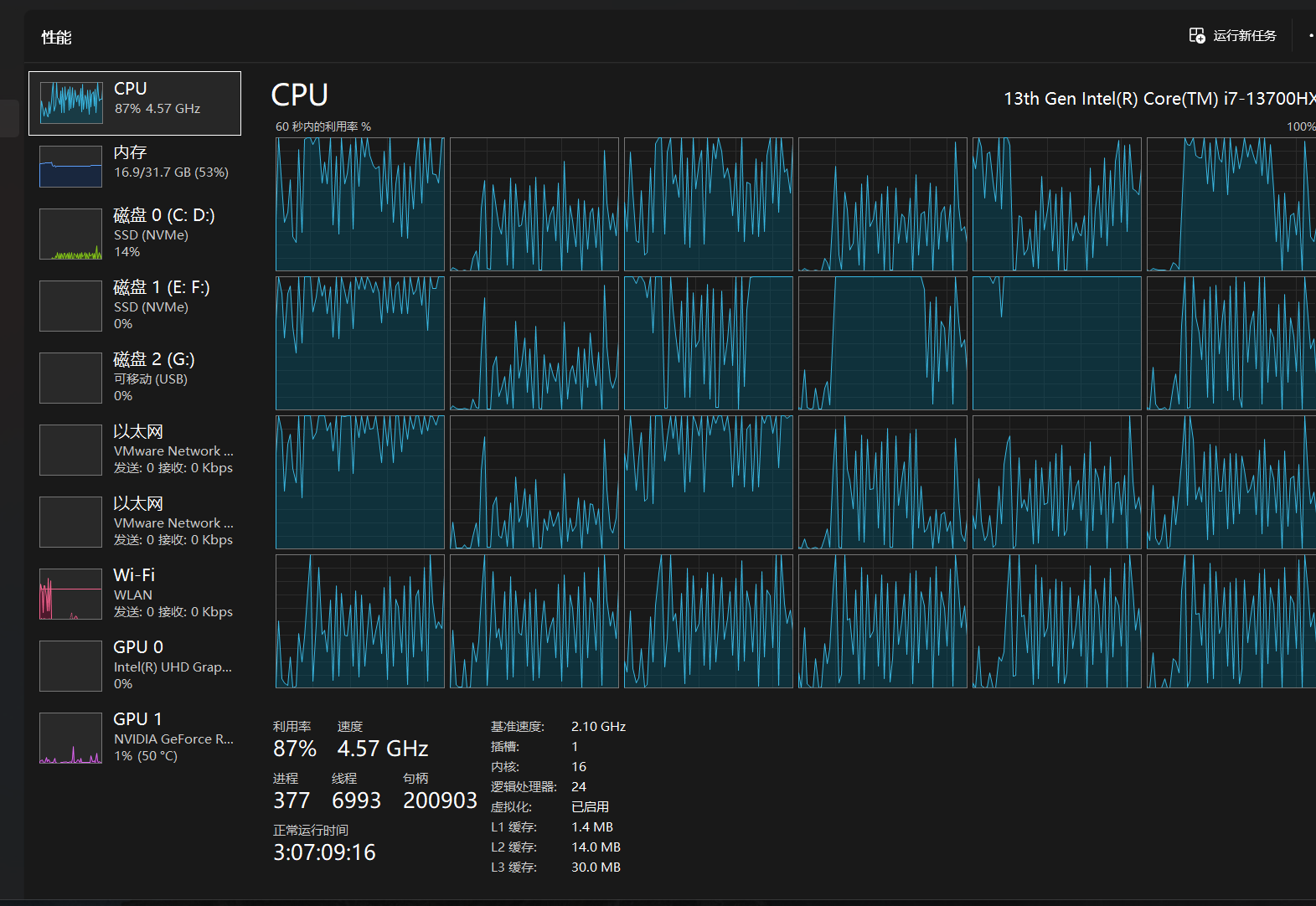
因为内存不足报错了!其实是c盘也快满了!