什么是贝叶斯
贝叶斯算法是一种基于贝叶斯定理的统计学习方法,通过结合先验知识和观测数据来更新对事件发生概率的估计,广泛应用于机器学习、数据挖掘、自然语言处理等领域。
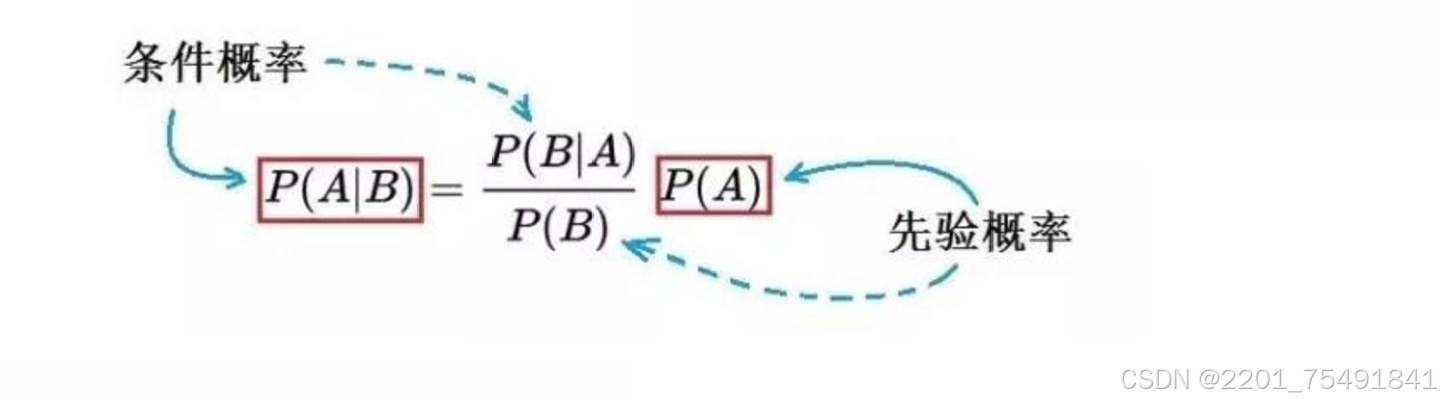
贝叶斯定理的核心,即
其中
是先验概率,表示在没有观测到新数据之前对事件A发生概率的初始估计
是B事件发生的概率
是后验概率,表示在B事件发生的条件下A事件发生的概率
表示在A事件发生条件下B事件发生的概率
先验概率是在未考虑新证据前基于经验或主观判断对事件发生概率的初始估计
后验概率是在观察到新证据后利用先验概率和新信息对事件发生概率进行重新计算得出的概率。
主要作用
在机器学习中,贝叶斯算法主要用于分类和概率估计任务。例如,在文本分类中,将文档属于某个类别的概率作为先验概率,通过分析文档中的词出现的频率等特征来计算似然函数,进而得出文档属于各个类别的后验概率,将文档分类到后验概率最大的类别中。
算法优缺点
优点
贝叶斯算法在小样本数据情况下也能有较好的表现,能有效利用先验知识,对数据中的噪声有一定的鲁棒性,并且可以处理具有不确定性的数据。
缺点
若先验概率假设不准确或与实际数据分布差异较大,会影响算法性能;对于高维数据和复杂的模型结构,计算后验概率可能会非常复杂,导致计算成本较高。
贝叶斯举例
在一个学校里面,男生占60%,女生占40%,男生100%穿长裤,女生50%穿长裤,50%穿裙子
此时迎面走来一个穿长裤的学生,判断这个穿长裤的学生是女生的概率
实质:穿长裤的是女生的概率=女生中穿长裤的人数/穿长裤的总人数
假设:男生--A 女生--B 穿长裤--C
则P(B|C)=P(B)*P(C|B)/P(C)
代码实例
下面我们来通过代码实现一个基于朴素贝叶斯分类器的垃圾邮件分类任务
代码实现
#导入相应的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
from sklearn.preprocessing import MinMaxScaler
#可视化混淆矩阵
def cm_plot(y,p):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm=confusion_matrix(y,p)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
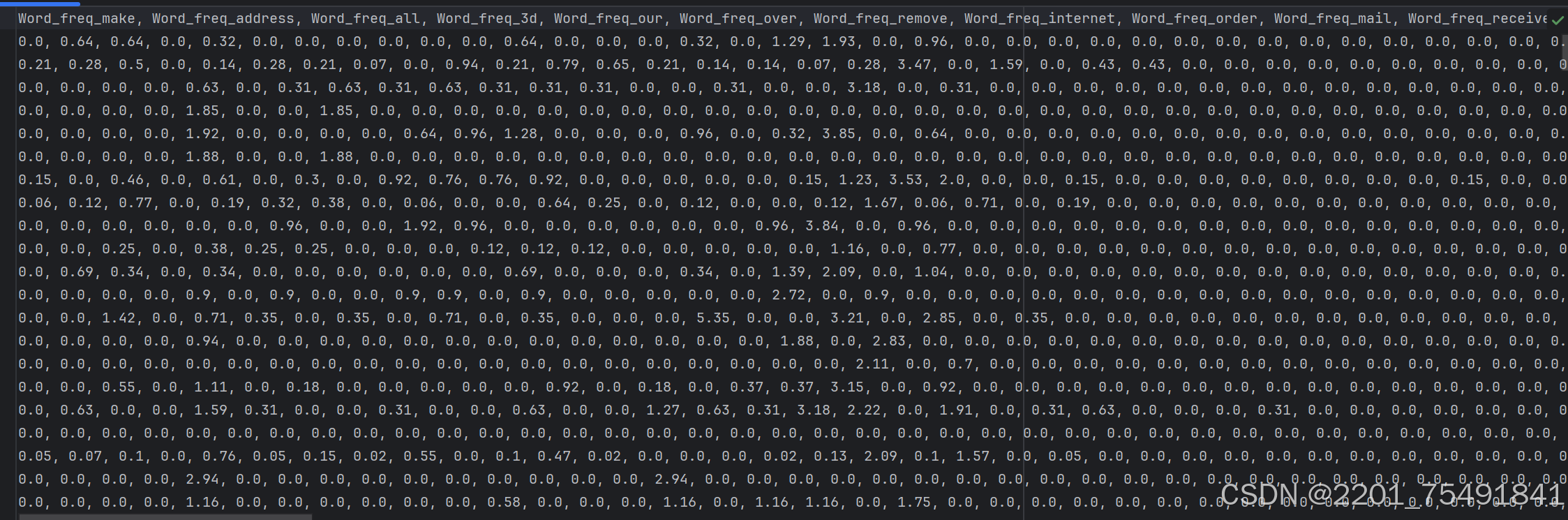
#读取数据
data=pd.read_csv('spambase.csv')
#数据归一化处理
scaler = MinMaxScaler()
data[' Capital_run_length_total']=scaler.fit_transform(data[[' Capital_run_length_total']])
data[' Capital_run_length_longest']=scaler.fit_transform(data[[' Capital_run_length_longest']])
#划分特征和标签
x=data.iloc[:,:-1]
y=data.iloc[:,-1]
#划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=10)
#创建贝叶斯模型
classifier=MultinomialNB(alpha=1)
#模型训练
classifier.fit(x_train,y_train)
#用训练好的模型对训练集自测
train_predicted=classifier.predict(x_train)
#对测试集进行预测
test_predicted=classifier.predict(x_test)
#绘制混淆矩阵
# cm_plot(y_train,train_predicted).show()
# cm_plot(y_test,test_predicted).show()
#打印分类报告
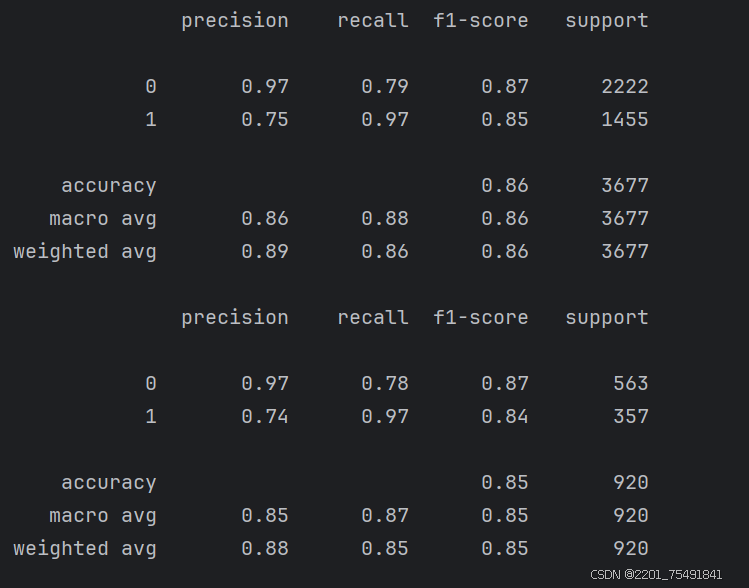
print(metrics.classification_report(y_train,train_predicted))
print(metrics.classification_report(y_test,test_predicted))打印输出结果