文章目录
前言
亲爱的家人们,创作很不容易,若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力,谢谢大家!有问题请私信或联系邮箱:[email protected]
1、哈希表
定义:又称散列表,建立键 key与值value之间映射,实现高效元素查询。向哈希表中输入一个键 key ,在O(1)时间内获取对应值 value 。
例子:n个学生,每个学生都有“姓名”和“学号”两项数据。输入一个学号,返回对应姓名,采用哈希表实现。

性能对比:
数组和链表也实现查询功能。

1.1、哈希表操作
常见操作:初始化、查询操作、添加键值对和删除键值对等
/* 初始化哈希表 */
Map<Integer, String> map = new HashMap<>();
/* 添加操作 */
// 在哈希表中添加键值对 (key, value)
map.put(12836, "小哈");
map.put(15937, "小啰");
map.put(16750, "小算");
map.put(13276, "小法");
map.put(10583, "小鸭");
/* 查询操作 */
// 向哈希表中输入键 key ,得到值 value
String name = map.get(15937);
/* 删除操作 */
// 在哈希表中删除键值对 (key, value)
map.remove(10583);
常用的遍历方式:遍历键值对、遍历键和遍历值
/* 遍历哈希表 */
// 遍历键值对 key->value
for (Map.Entry <Integer, String> kv: map.entrySet()) {
System.out.println(kv.getKey() + " -> " + kv.getValue());
}
// 单独遍历键 key
for (int key: map.keySet()) {
System.out.println(key);
}
// 单独遍历值 value
for (String val: map.values()) {
System.out.println(val);
}
1.2、哈希表实现
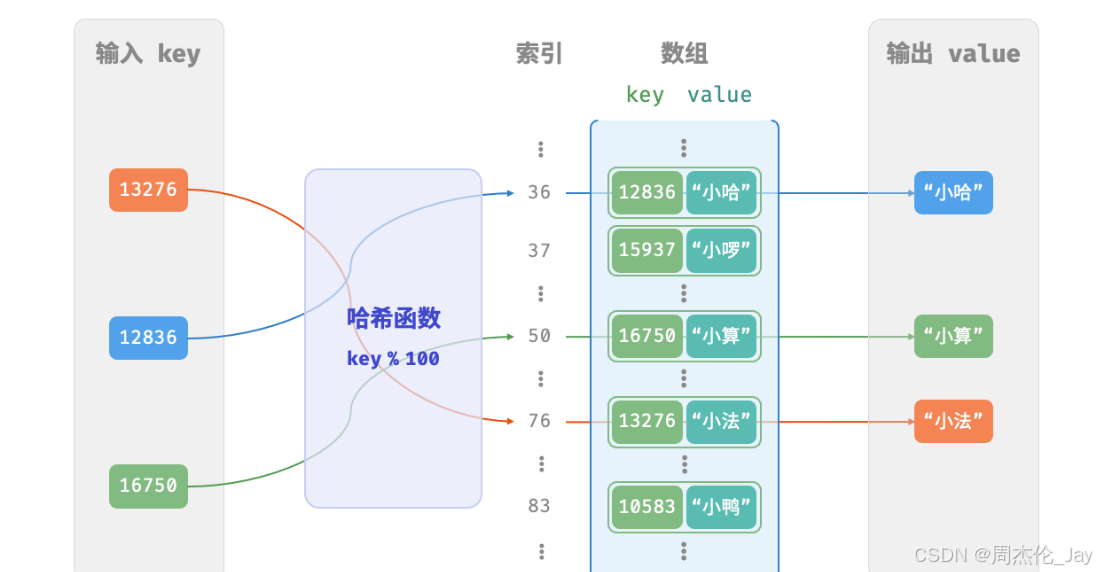
仅用一个数组来实现哈希表。在哈希表中,将数组中每个空位称为桶(bucket),每个桶可存储一个键值对。查询操作是找到key对应的桶,并在桶中获取 value 。
如何基 key定位对应桶是通过哈希函数实现。哈希函数作用是将一个较大输入空间映射到一个较小输出空间。在哈希表中,输入空间是所有 key ,输出空间是所有桶(数组索引)。输入一个 key ,通过哈希函数得到该key对应的键值对在数组中存储位置。
过程:
①通过某种哈希算法 hash() 计算得到哈希值。
②将哈希值对桶数量(数组长度)取模index = hash(key) % capacity,从而获取该key对应数组索引 index 。
③利用index在哈希表中访问对应桶获取 value 。
例子:设数组长度 capacity = 100、哈希算法 hash(key) = key ,易得哈希函数为 key % 100 。
/* 键值对 */
class Pair {
public int key;
public String val;
public Pair(int key, String val) {
this.key = key;
this.val = val;
}
}
/* 基于数组实现的哈希表 */
class ArrayHashMap {
private List<Pair> buckets;
public ArrayHashMap() {
// 初始化数组,包含 100 个桶
buckets = new ArrayList<>();
for (int i = 0; i < 100; i++) {
buckets.add(null);
}
}
/* 哈希函数 */
private int hashFunc(int key) {
int index = key % 100;
return index;
}
/* 查询操作 */
public String get(int key) {
int index = hashFunc(key);
Pair pair = buckets.get(index);
if (pair == null)
return null;
return pair.val;
}
/* 添加操作 */
public void put(int key, String val) {
Pair pair = new Pair(key, val);
int index = hashFunc(key);
buckets.set(index, pair);
}
/* 删除操作 */
public void remove(int key) {
int index = hashFunc(key);
// 置为 null ,代表删除
buckets.set(index, null);
}
/* 获取所有键值对 */
public List<Pair> pairSet() {
List<Pair> pairSet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
pairSet.add(pair);
}
return pairSet;
}
/* 获取所有键 */
public List<Integer> keySet() {
List<Integer> keySet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
keySet.add(pair.key);
}
return keySet;
}
/* 获取所有值 */
public List<String> valueSet() {
List<String> valueSet = new ArrayList<>();
for (Pair pair : buckets) {
if (pair != null)
valueSet.add(pair.val);
}
return valueSet;
}
/* 打印哈希表 */
public void print() {
for (Pair kv : pairSet()) {
System.out.println(kv.key + " -> " + kv.val);
}
}
}
2、哈希冲突
哈希函数输入空间远大于输出空间,理论上哈希冲突不可避免。
哈希冲突会导致查询结果错误,严重影响哈希表可用性。为解决该问题,每当遇到哈希冲突时,进行哈希表扩容,直至冲突消失为止。此方法简单粗暴且有效,但效率太低,哈希表扩容需要进行大量数据搬运与哈希值计算。
为了提升效率,采用以下策略。
改良哈希表数据结构,使得哈希表在出现哈希冲突时正常工作。
仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
哈希表结构改良方法主要包括“链式地址”和“开放寻址”。
2.1、链式地址
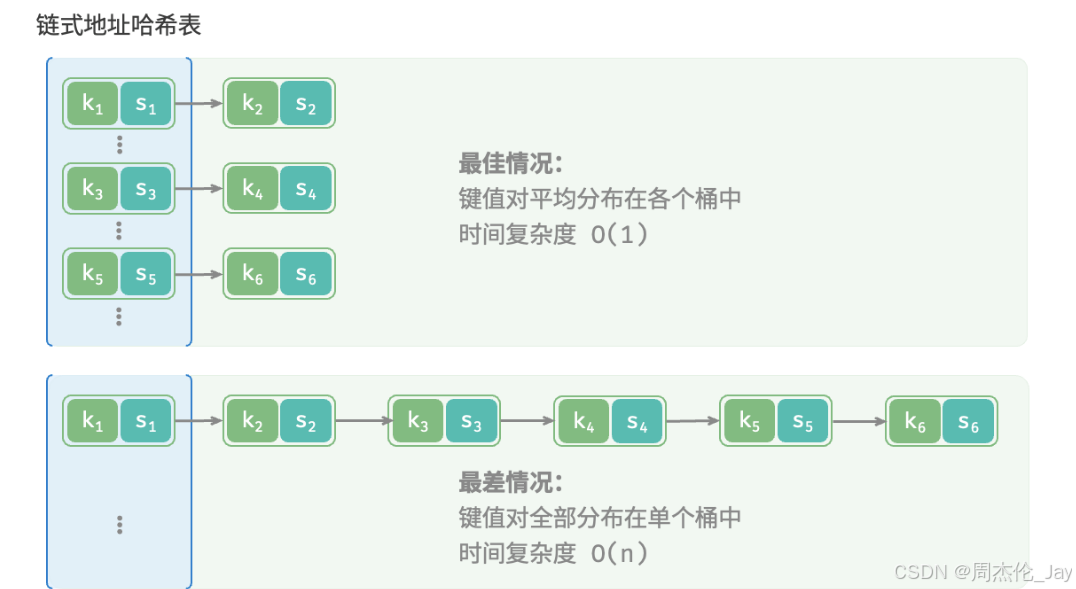
在原始哈希表中,每个桶仅能存储一个键值对。链式地址(separate chaining)将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。
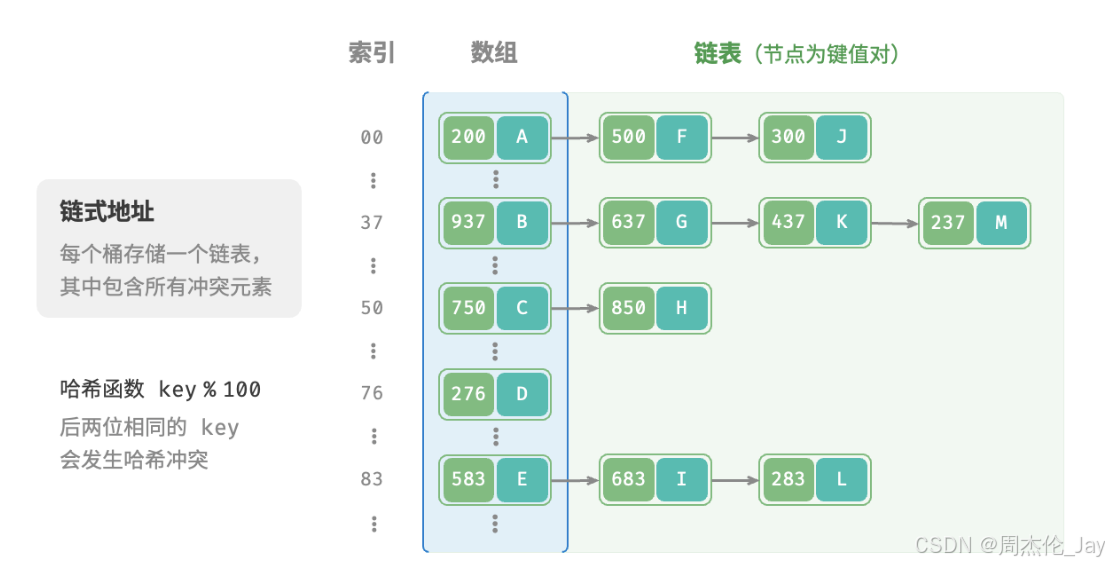
基于链式地址实现哈希表的操作方法发生以下变化:
查询元素:输入key ,经过哈希函数得到桶索引,访问链表头节点,然后遍历链表并对比 key以查找目标键值对。
添加元素:通过哈希函数访问链表头节点,然后将节点(键值对)添加到链表中。
删除元素:根据哈希函数结果访问链表头部,接着遍历链表以查找目标节点并将其删除。
链式地址存在以下局限性:
占用空间增大:链表包含节点指针,相比数组更加耗费内存空间。
查询效率降低:需要线性遍历链表来查找对应元素。
/* 链式地址哈希表 */
class HashMapChaining {
int size; // 键值对数量
int capacity; // 哈希表容量
double loadThres; // 触发扩容的负载因子阈值
int extendRatio; // 扩容倍数
List<List<Pair>> buckets; // 桶数组
/* 构造方法 */
public HashMapChaining() {
size = 0;
capacity = 4;
loadThres = 2.0 / 3.0;
extendRatio = 2;
buckets = new ArrayList<>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.add(new ArrayList<>());
}
}
/* 哈希函数 */
int hashFunc(int key) {
return key % capacity;
}
/* 负载因子 */
double loadFactor() {
return (double) size / capacity;
}
/* 查询操作 */
String get(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// 遍历桶,若找到 key ,则返回对应 val
for (Pair pair : bucket) {
if (pair.key == key) {
return pair.val;
}
}
// 若未找到 key ,则返回 null
return null;
}
/* 添加操作 */
void put(int key, String val) {
// 当负载因子超过阈值时,执行扩容
if (loadFactor() > loadThres) {
extend();
}
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// 遍历桶,若遇到指定 key ,则更新对应 val 并返回
for (Pair pair : bucket) {
if (pair.key == key) {
pair.val = val;
return;
}
}
// 若无该 key ,则将键值对添加至尾部
Pair pair = new Pair(key, val);
bucket.add(pair);
size++;
}
/* 删除操作 */
void remove(int key) {
int index = hashFunc(key);
List<Pair> bucket = buckets.get(index);
// 遍历桶,从中删除键值对
for (Pair pair : bucket) {
if (pair.key == key) {
bucket.remove(pair);
size--;
break;
}
}
}
/* 扩容哈希表 */
void extend() {
// 暂存原哈希表
List<List<Pair>> bucketsTmp = buckets;
// 初始化扩容后的新哈希表
capacity *= extendRatio;
buckets = new ArrayList<>(capacity);
for (int i = 0; i < capacity; i++) {
buckets.add(new ArrayList<>());
}
size = 0;
// 将键值对从原哈希表搬运至新哈希表
for (List<Pair> bucket : bucketsTmp) {
for (Pair pair : bucket) {
put(pair.key, pair.val);
}
}
}
/* 打印哈希表 */
void print() {
for (List<Pair> bucket : buckets) {
List<String> res = new ArrayList<>();
for (Pair pair : bucket) {
res.add(pair.key + " -> " + pair.val);
}
System.out.println(res);
}
}
}
2.2、开放寻址
不引入额外数据结构,通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测和多次哈希。
2.2.1、线性探测
线性探测采用固定步长线性搜索来进行探测,其操作方法与普通哈希表有所不同。
插入元素:通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为1 ),直至找到空桶,将元素插入其中。
查找元素:若发现哈希冲突,则使用相同步长向后进行线性遍历,直到找到对应元素,返回 value 即可;如果遇到空桶,说明目标元素不在哈希表中,返回 None 。

线性探测容易产生“聚集现象”:数组中连续被占用位置越长,连续位置发生哈希冲突可能性越大,从而进一步促使该位置聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
注意:不能在开放寻址哈希表中直接删除元素。删除元素会在数组内产生一个空桶 None ,而当查询元素时,线性探测到该空桶就会返回,在该空桶之下元素都无法再被访问到,程序可能误判这些元素不存在。
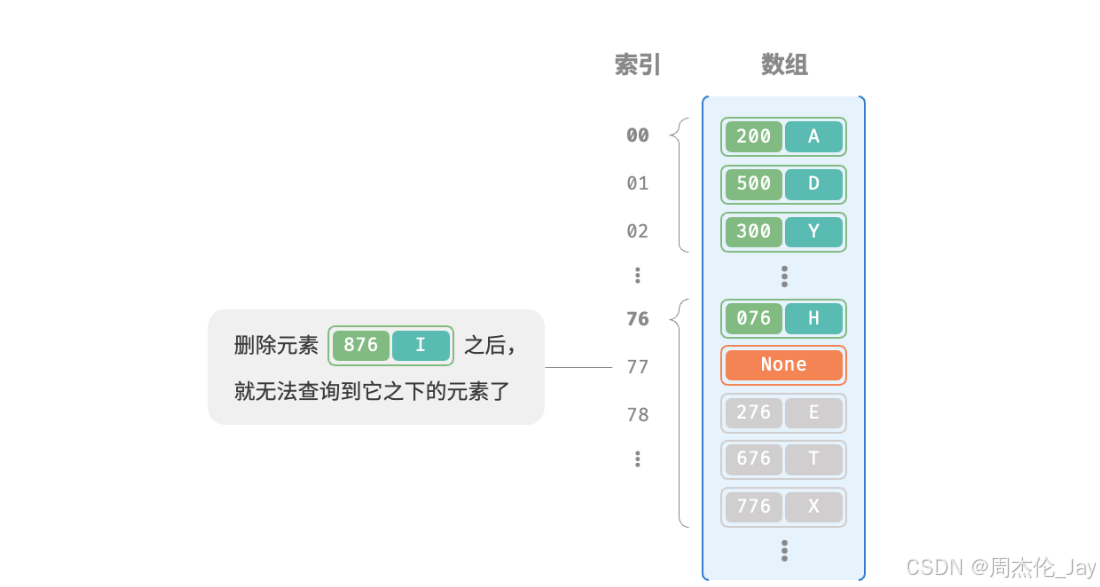
为解决该问题,我采用懒删除机制:不直接从哈希表中移除元素,利用一个常量 TOMBSTONE 来标记这个桶。在该机制下,None 和 TOMBSTONE都代表空桶,都放置键值对。不同的是线性探测到 TOMBSTONE 时应该继续遍历,其之下可能还存在键值对。
然而,懒删除可能会加速哈希表的性能退化。每次删除操作都会产生一个删除标记,随着TOMBSTONE增加,搜索时间也会增加,线性探测可能需要跳过多个 TOMBSTONE 才能找到目标元素。
考虑在线性探测中记录遇到的首个 TOMBSTONE 的索引,并将搜索到的目标元素与该 TOMBSTONE 交换位置。好处是当每次查询或添加元素时,元素会被移动至距离理想位置(探测起始点)更近的桶,从而优化查询效率。
/* 开放寻址哈希表 */
class HashMapOpenAddressing {
private int size; // 键值对数量
private int capacity = 4; // 哈希表容量
private final double loadThres = 2.0 / 3.0; // 触发扩容的负载因子阈值
private final int extendRatio = 2; // 扩容倍数
private Pair[] buckets; // 桶数组
private final Pair TOMBSTONE = new Pair(-1, "-1"); // 删除标记
/* 构造方法 */
public HashMapOpenAddressing() {
size = 0;
buckets = new Pair[capacity];
}
/* 哈希函数 */
private int hashFunc(int key) {
return key % capacity;
}
/* 负载因子 */
private double loadFactor() {
return (double) size / capacity;
}
/* 搜索 key 对应的桶索引 */
private int findBucket(int key) {
int index = hashFunc(key);
int firstTombstone = -1;
// 线性探测,当遇到空桶时跳出
while (buckets[index] != null) {
// 若遇到 key ,返回对应的桶索引
if (buckets[index].key == key) {
// 若之前遇到了删除标记,则将键值对移动至该索引处
if (firstTombstone != -1) {
buckets[firstTombstone] = buckets[index];
buckets[index] = TOMBSTONE;
return firstTombstone; // 返回移动后的桶索引
}
return index; // 返回桶索引
}
// 记录遇到的首个删除标记
if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {
firstTombstone = index;
}
// 计算桶索引,越过尾部则返回头部
index = (index + 1) % capacity;
}
// 若 key 不存在,则返回添加点的索引
return firstTombstone == -1 ? index : firstTombstone;
}
/* 查询操作 */
public String get(int key) {
// 搜索 key 对应的桶索引
int index = findBucket(key);
// 若找到键值对,则返回对应 val
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
return buckets[index].val;
}
// 若键值对不存在,则返回 null
return null;
}
/* 添加操作 */
public void put(int key, String val) {
// 当负载因子超过阈值时,执行扩容
if (loadFactor() > loadThres) {
extend();
}
// 搜索 key 对应的桶索引
int index = findBucket(key);
// 若找到键值对,则覆盖 val 并返回
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index].val = val;
return;
}
// 若键值对不存在,则添加该键值对
buckets[index] = new Pair(key, val);
size++;
}
/* 删除操作 */
public void remove(int key) {
// 搜索 key 对应的桶索引
int index = findBucket(key);
// 若找到键值对,则用删除标记覆盖它
if (buckets[index] != null && buckets[index] != TOMBSTONE) {
buckets[index] = TOMBSTONE;
size--;
}
}
/* 扩容哈希表 */
private void extend() {
// 暂存原哈希表
Pair[] bucketsTmp = buckets;
// 初始化扩容后的新哈希表
capacity *= extendRatio;
buckets = new Pair[capacity];
size = 0;
// 将键值对从原哈希表搬运至新哈希表
for (Pair pair : bucketsTmp) {
if (pair != null && pair != TOMBSTONE) {
put(pair.key, pair.val);
}
}
}
/* 打印哈希表 */
public void print() {
for (Pair pair : buckets) {
if (pair == null) {
System.out.println("null");
} else if (pair == TOMBSTONE) {
System.out.println("TOMBSTONE");
} else {
System.out.println(pair.key + " -> " + pair.val);
}
}
}
}
2.2.2、平方探测
平方探测与线性探测类似,都是开放寻址的常见策略之一。当发生冲突时,平方探测不是简单地跳过一个固定的步数,而是跳过“探测次数的平方”的步数,即1、4、9步。
优势:
平方探测通过跳过探测次数平方的距离,试图缓解线性探测聚集效应。
平方探测会跳过更大的距离来寻找空位置,有助于数据分布得更加均匀。
缺点:
仍然存在聚集现象,即某些位置比其他位置更容易被占用。
由于平方的增长,平方探测可能不会探测整个哈希表,这意味着即使哈希表中有空桶,平方探测也可能无法访问。
2.2.3、多次哈希
多次哈希方法使用多个哈希函数进行探测。
插入元素:若哈希函数1 出现冲突,则尝试哈希函数2,以此类推,直到找到空位后插入元素。
查找元素:在相同的哈希函数顺序下进行查找,直到找到目标元素时返回;若遇到空位或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回 None 。
与线性探测相比,多次哈希方法不易产生聚集,但多个哈希函数会带来额外的计算量。
3、哈希算法
开放寻址和链式地址:只能保证哈希表可以在发生冲突时正常工作,而无法减少哈希冲突的发生。如果哈希冲突过于频繁,哈希表的性能则会急剧劣化。
为降低哈希冲突发生概率,在哈希算法 hash() 设计上进行解决。
3.1、哈希算法目标
为实现“既快又稳”哈希表数据结构,哈希算法特点:
确定性:对于相同输入,哈希算法应始终产生相同输出。确保哈希表可靠。
效率高:计算哈希值过程应该足够快。计算开销越小,哈希表实用性越高。
均匀分布:哈希算法应使得键值对均匀分布在哈希表中。分布越均匀,哈希冲突概率就越低。
3.2、哈希算法设计
加法哈希:对输入的每个字符的 ASCII 码进行相加,将得到的总和作为哈希值。
乘法哈希:利用乘法的不相关性,每轮乘以一个常数,将各个字符的 ASCII 码累积到哈希值中。
异或哈希:将输入数据的每个元素通过异或操作累积到一个哈希值中。
旋转哈希:将每个字符的 ASCII 码累积到一个哈希值中,每次累积之前都会对哈希值进行旋转操作。
/* 加法哈希 */
int addHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = (hash + (int) c) % MODULUS;
}
return (int) hash;
}
/* 乘法哈希 */
int mulHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = (31 * hash + (int) c) % MODULUS;
}
return (int) hash;
}
/* 异或哈希 */
int xorHash(String key) {
int hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash ^= (int) c;
}
return hash & MODULUS;
}
/* 旋转哈希 */
int rotHash(String key) {
long hash = 0;
final int MODULUS = 1000000007;
for (char c : key.toCharArray()) {
hash = ((hash << 4) ^ (hash >> 28) ^ (int) c) % MODULUS;
}
return (int) hash;
}
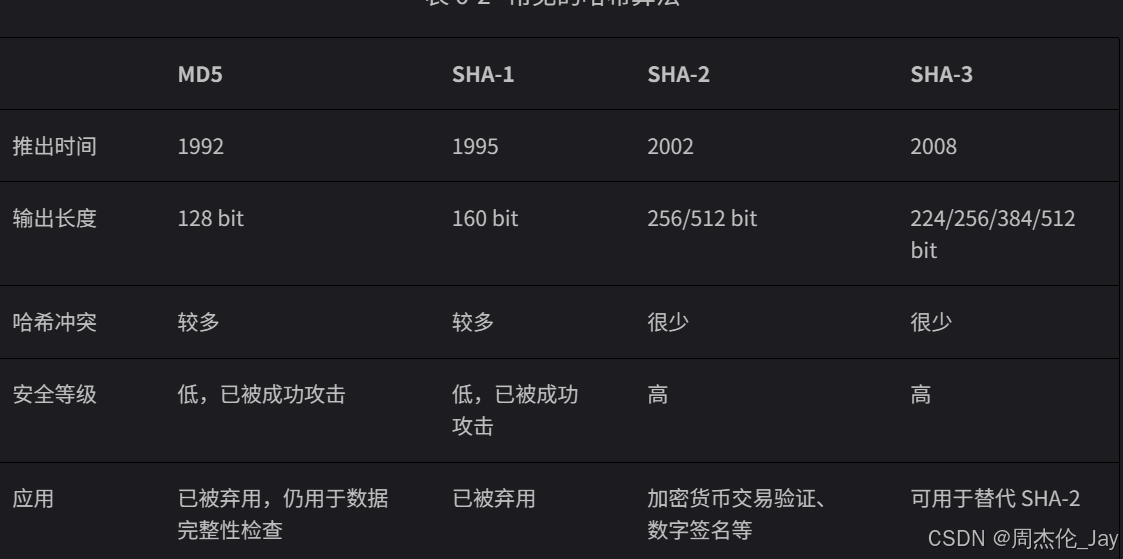
3.3、常见哈希算法
一些标准哈希算法,例如 MD5、SHA-1、SHA-2 和 SHA-3 等。可将任意长度输入数据映射到恒定长度的哈希值。