预训练规模
VIT预训练了三种不同参数规模的模型,分别是VIT-Base ,VIT-Large和VIT-Huge。其规模可具体见上图。
- 关键参数:
Layers表示Transformer Block的层数、Hidden size表示[batch_size, seq_len, d_model]中的d_model通道维度大小、MLP size表示MLP中最大的通道维度大小,Heads表示多头注意力中split的头数、Params表示参数量、Patch size表示划分的图像块大小。

在论文及实际使用中,我们常用VIT-size/patch_size的形式来表示该模型是在“什么规模”及“多大的patch尺寸”上预训练出来的。例如VIT-H/14 就表示该模型是在Huge规模上,用patch尺寸为14的数据做预训练的。
模型架构
Patchify、Position Embedding、Patch Drop、Pre Norm、Transformer Blocks、Post Norm、Classifier Head。
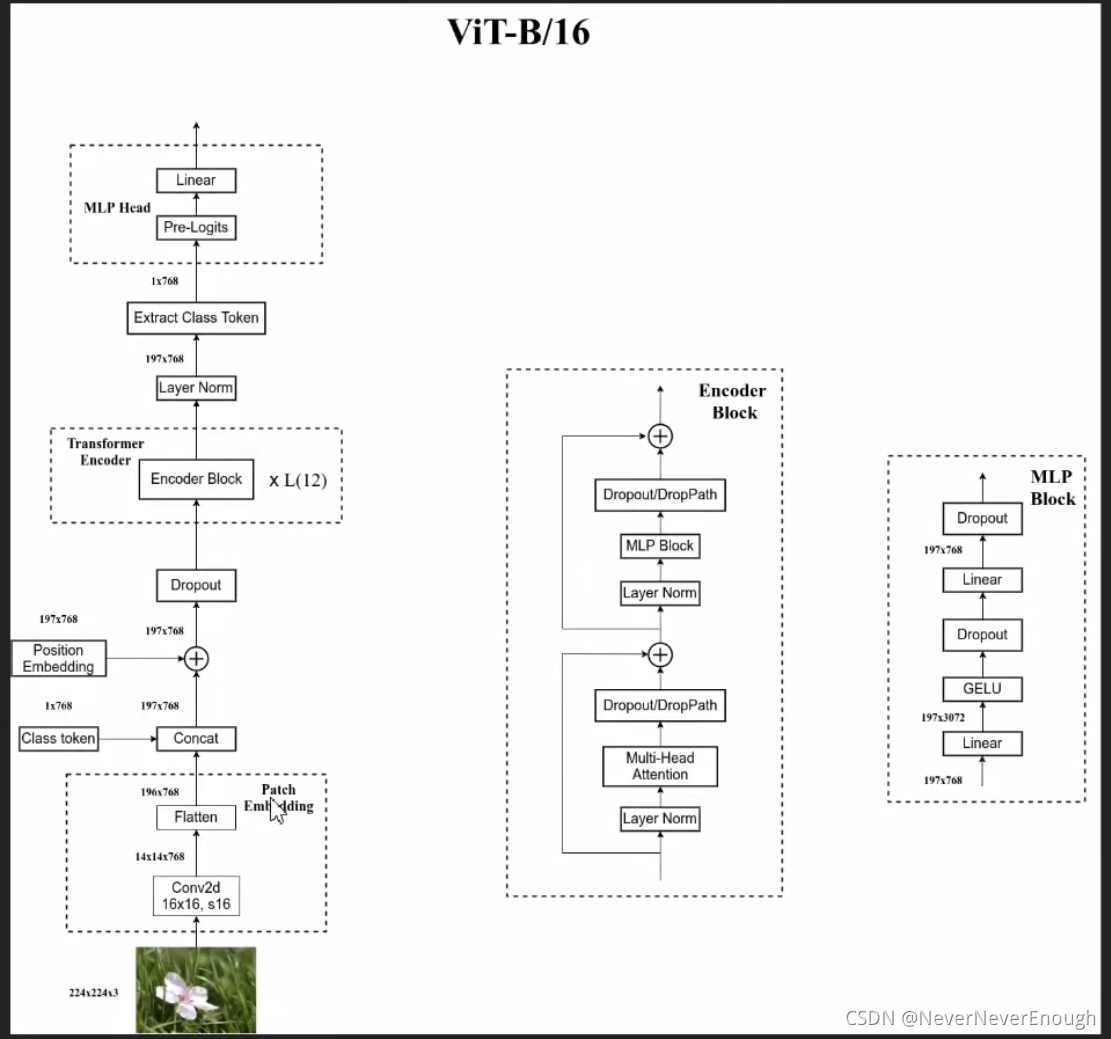
- Patchify:Conv2d将
[C,H,W]转换为[c,h,w],然后flatten为[B,L,C]。
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding
"""
output_fmt: Format
dynamic_img_pad: torch.jit.Final[bool]
def __init__(
self,
img_size: Optional[int] = 224,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
norm_layer: Optional[Callable] = None,
flatten: bool = True,
output_fmt: Optional[str] = None,
bias: bool = True,
strict_img_size: bool = True,
dynamic_img_pad: bool = False,
):
super().__init__()
self.patch_size = to_2tuple(patch_size)
self.img_size, self.grid_size, self.num_patches = self._init_img_size(img_size)
if output_fmt is not None:
self.flatten = False
self.output_fmt = Format(output_fmt)
else:
# flatten spatial dim and transpose to channels last, kept for bwd compat
self.flatten = flatten
self.output_fmt = Format.NCHW
self.strict_img_size = strict_img_size
self.dynamic_img_pad = dynamic_img_pad
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size, bias=bias)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def _init_img_size(self, img_size: Union[int, Tuple[int, int]]):
assert self.patch_size
if img_size is None:
return None, None, None
img_size = to_2tuple(img_size)
grid_size = tuple([s // p for s, p in zip(img_size, self.patch_size)])
num_patches = grid_size[0] * grid_size[1]
return img_size, grid_size, num_patches
def set_input_size(
self,
img_size: Optional[Union[int, Tuple[int, int]]] = None,
patch_size: Optional[Union[int, Tuple[int, int]]] = None,
):
new_patch_size = None
if patch_size is not None:
new_patch_size = to_2tuple(patch_size)
if new_patch_size is not None and new_patch_size != self.patch_size:
with torch.no_grad():
new_proj = nn.Conv2d(
self.proj.in_channels,
self.proj.out_channels,
kernel_size=new_patch_size,
stride=new_patch_size,
bias=self.proj.bias is not None,
)
new_proj.weight.copy_(resample_patch_embed(self.proj.weight, new_patch_size, verbose=True))
if self.proj.bias is not None:
new_proj.bias.copy_(self.proj.bias)
self.proj = new_proj
self.patch_size = new_patch_size
img_size = img_size or self.img_size
if img_size != self.img_size or new_patch_size is not None:
self.img_size, self.grid_size, self.num_patches = self._init_img_size(img_size)
def feat_ratio(self, as_scalar=True) -> Union[Tuple[int, int], int]:
if as_scalar:
return max(self.patch_size)
else:
return self.patch_size
def dynamic_feat_size(self, img_size: Tuple[int, int]) -> Tuple[int, int]:
""" Get grid (feature) size for given image size taking account of dynamic padding.
NOTE: must be torchscript compatible so using fixed tuple indexing
"""
if self.dynamic_img_pad:
return math.ceil(img_size[0] / self.patch_size[0]), math.ceil(img_size[1] / self.patch_size[1])
else:
return img_size[0] // self.patch_size[0], img_size[1] // self.patch_size[1]
def forward(self, x):
B, C, H, W = x.shape
if self.img_size is not None:
if self.strict_img_size:
_assert(H == self.img_size[0], f"Input height ({H}) doesn't match model ({self.img_size[0]}).")
_assert(W == self.img_size[1], f"Input width ({W}) doesn't match model ({self.img_size[1]}).")
elif not self.dynamic_img_pad:
_assert(
H % self.patch_size[0] == 0,
f"Input height ({H}) should be divisible by patch size ({self.patch_size[0]})."
)
_assert(
W % self.patch_size[1] == 0,
f"Input width ({W}) should be divisible by patch size ({self.patch_size[1]})."
)
if self.dynamic_img_pad:
pad_h = (self.patch_size[0] - H % self.patch_size[0]) % self.patch_size[0]
pad_w = (self.patch_size[1] - W % self.patch_size[1]) % self.patch_size[1]
x = F.pad(x, (0, pad_w, 0, pad_h))
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # NCHW -> NLC
elif self.output_fmt != Format.NCHW:
x = nchw_to(x, self.output_fmt)
x = self.norm(x)
return x
- Position Embedding:使用
learnable的绝对位置编码,直接加在token序列上。
embed_len = num_patches if no_embed_class else num_patches + self.num_prefix_tokens
if not pos_embed or pos_embed == 'none':
self.pos_embed = None
else:
self.pos_embed = nn.Parameter(torch.randn(1, embed_len, embed_dim) * .02)
def _pos_embed(self, x: torch.Tensor) -> torch.Tensor:
if self.pos_embed is None:
return x.view(x.shape[0], -1, x.shape[-1])
if self.dynamic_img_size:
B, H, W, C = x.shape
pos_embed = resample_abs_pos_embed(
self.pos_embed,
(H, W),
num_prefix_tokens=0 if self.no_embed_class else self.num_prefix_tokens,
)
x = x.view(B, -1, C)
else:
pos_embed = self.pos_embed
to_cat = []
if self.cls_token is not None:
to_cat.append(self.cls_token.expand(x.shape[0], -1, -1))
if self.reg_token is not None:
to_cat.append(self.reg_token.expand(x.shape[0], -1, -1))
if self.no_embed_class:
# deit-3, updated JAX (big vision)
# position embedding does not overlap with class token, add then concat
x = x + pos_embed
if to_cat:
x = torch.cat(to_cat + [x], dim=1)
else:
# original timm, JAX, and deit vit impl
# pos_embed has entry for class token, concat then add
if to_cat:
x = torch.cat(to_cat + [x], dim=1)
x = x + pos_embed
return self.pos_drop(x)
- PatchDrop:按照概率随机丢弃(
除了cls token之外)patch token。
class PatchDropout(nn.Module):
"""
https://arxiv.org/abs/2212.00794 and https://arxiv.org/pdf/2208.07220
"""
return_indices: torch.jit.Final[bool]
def __init__(
self,
prob: float = 0.5,
num_prefix_tokens: int = 1,
ordered: bool = False,
return_indices: bool = False,
):
super().__init__()
assert 0 <= prob < 1.
self.prob = prob
self.num_prefix_tokens = num_prefix_tokens # exclude CLS token (or other prefix tokens)
self.ordered = ordered
self.return_indices = return_indices
def forward(self, x) -> Union[torch.Tensor, Tuple[torch.Tensor, Optional[torch.Tensor]]]:
if not self.training or self.prob == 0.:
if self.return_indices:
return x, None
return x
if self.num_prefix_tokens:
prefix_tokens, x = x[:, :self.num_prefix_tokens], x[:, self.num_prefix_tokens:]
else:
prefix_tokens = None
B = x.shape[0]
L = x.shape[1]
num_keep = max(1, int(L * (1. - self.prob)))
keep_indices = torch.argsort(torch.randn(B, L, device=x.device), dim=-1)[:, :num_keep]
if self.ordered:
# NOTE does not need to maintain patch order in typical transformer use,
# but possibly useful for debug / visualization
keep_indices = keep_indices.sort(dim=-1)[0]
x = x.gather(1, keep_indices.unsqueeze(-1).expand((-1, -1) + x.shape[2:]))
if prefix_tokens is not None:
x = torch.cat((prefix_tokens, x), dim=1)
if self.return_indices:
return x, keep_indices
return x
- Pre Norm 和 Post Norm:都是对tokens进行归一化
_NORM_MAP = dict(
batchnorm=nn.BatchNorm2d,
batchnorm2d=nn.BatchNorm2d,
batchnorm1d=nn.BatchNorm1d,
groupnorm=GroupNorm,
groupnorm1=GroupNorm1,
layernorm=LayerNorm,
layernorm2d=LayerNorm2d,
rmsnorm=RmsNorm,
rmsnorm2d=RmsNorm2d,
frozenbatchnorm2d=FrozenBatchNorm2d,
)
- Transformer Blocks:顺序执行即可
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.Sequential(*[
block_fn(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_norm=qk_norm,
init_values=init_values,
proj_drop=proj_drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
act_layer=act_layer,
mlp_layer=mlp_layer,
)
for i in range(depth)])
- Classifier Head:由
Pool(可选的)、FC Norm(和Transformer的Post Norm不能同时使用)、Head Drop、Linear组成。最终的Linear将特征向量映射到类别数(num_classes),即logits,用于分类。
# Classifier Head
if global_pool == 'map':
self.attn_pool = AttentionPoolLatent(
self.embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
norm_layer=norm_layer,
)
else:
self.attn_pool = None
self.fc_norm = norm_layer(embed_dim) if final_norm and use_fc_norm else nn.Identity()
self.head_drop = nn.Dropout(drop_rate)
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
AttentionPoolLatent 是一个Residual Attention Block,如果进行pool的话,在最后有2种模式:(1)取出cls token;(2)avg pool所有 tokens。
class AttentionPoolLatent(nn.Module):
""" Attention pooling w/ latent query
"""
fused_attn: torch.jit.Final[bool]
def __init__(
self,
in_features: int,
out_features: int = None,
embed_dim: int = None,
num_heads: int = 8,
feat_size: Optional[int] = None,
mlp_ratio: float = 4.0,
qkv_bias: bool = True,
qk_norm: bool = False,
latent_len: int = 1,
latent_dim: int = None,
pos_embed: str = '',
pool_type: str = 'token',
norm_layer: Optional[nn.Module] = None,
drop: float = 0.0,
):
super().__init__()
embed_dim = embed_dim or in_features
out_features = out_features or in_features
assert embed_dim % num_heads == 0
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.feat_size = feat_size
self.scale = self.head_dim ** -0.5
self.pool = pool_type
self.fused_attn = use_fused_attn()
if pos_embed == 'abs':
assert feat_size is not None
self.pos_embed = nn.Parameter(torch.zeros(feat_size, in_features))
else:
self.pos_embed = None
self.latent_dim = latent_dim or embed_dim
self.latent_len = latent_len
self.latent = nn.Parameter(torch.zeros(1, self.latent_len, embed_dim))
self.q = nn.Linear(embed_dim, embed_dim, bias=qkv_bias)
self.kv = nn.Linear(embed_dim, embed_dim * 2, bias=qkv_bias)
self.q_norm = norm_layer(self.head_dim) if qk_norm else nn.Identity()
self.k_norm = norm_layer(self.head_dim) if qk_norm else nn.Identity()
self.proj = nn.Linear(embed_dim, embed_dim)
self.proj_drop = nn.Dropout(drop)
self.norm = norm_layer(out_features) if norm_layer is not None else nn.Identity()
self.mlp = Mlp(embed_dim, int(embed_dim * mlp_ratio))
self.init_weights()
def init_weights(self):
if self.pos_embed is not None:
trunc_normal_tf_(self.pos_embed, std=self.pos_embed.shape[1] ** -0.5)
trunc_normal_tf_(self.latent, std=self.latent_dim ** -0.5)
def forward(self, x):
B, N, C = x.shape
if self.pos_embed is not None:
# FIXME interpolate
x = x + self.pos_embed.unsqueeze(0).to(x.dtype)
q_latent = self.latent.expand(B, -1, -1)
q = self.q(q_latent).reshape(B, self.latent_len, self.num_heads, self.head_dim).transpose(1, 2)
kv = self.kv(x).reshape(B, N, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
k, v = kv.unbind(0)
q, k = self.q_norm(q), self.k_norm(k)
if self.fused_attn:
x = F.scaled_dot_product_attention(q, k, v)
else:
q = q * self.scale
attn = q @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
x = attn @ v
x = x.transpose(1, 2).reshape(B, self.latent_len, C)
x = self.proj(x)
x = self.proj_drop(x)
x = x + self.mlp(self.norm(x))
# optional pool if latent seq_len > 1 and pooled output is desired
if self.pool == 'token':
x = x[:, 0]
elif self.pool == 'avg':
x = x.mean(1)
return x