
0.前言
当系统监控面板的红色警报第三次闪烁时,技术总监老张的咖啡杯悬在了半空。这个承载着千万用户的电商平台,订单表数据量已突破2.5亿条,每秒5000次的查询请求让数据库服务器发出不堪重负的嗡鸣。此时,我们面对的不仅是技术挑战,更像是在高速公路上给飞驰的汽车更换发动机——分库分表就是这场精密手术的核心器械。
1.分库分表的使用场景
-
数据量过大:单表数据超过 5000万行,索引层级过深,查询效率显著下降。
-
并发压力高:单实例写入QPS超过 2000,或磁盘IO接近瓶颈(如SSD IOPS达80%)。
-
业务扩展需求:需要支持水平扩展,避免垂直扩容成本过高。
2.拆分存储的技术选型
关于拆分存储常用的技术解决方案,市面上目前主要分为 4 种:MySQL 的分区技术、NoSQL、NewSQL、基于 MySQL 的分表分库。
1.MySQL的分区技术
MySQL 的分区主要在文件存储层做文章,它可以将一张表的不同行存放在不同存储文件中,这对使用者来说比较透明。
不使用它的原因有以下3点:
-
MySQL 的实例只有一个,它仅仅分摊了存储,无法分摊请求负载。
-
正是因为 MySQL 的分区对用户透明,所以用户在实际操作时往往不太注意,使得跨分区操作严重影响系统性能。
-
当然,MySQL 还有一些其他限制,比如不支持 query cache、位操作表达式等。
2.NoSQL(MongoDB)
比较典型的 NoSQL 数据库就是 MongoDB 。MongoDB 的分片功能从并发性和数据量这两个角度已经能满足一般大数据量的需求,但是还需要注意以下几点问题。
-
约束考量: MongoDB 不是关系型数据库而是文档型数据库,它的每一行记录都是一个结构灵活可变的 JSON,比如存储非常重要的订单数据时,我们就不能使用 MongoDB,因为订单数据必须使用强约束的关系型数据库进行存储。
-
业务功能考量: 多年来,事务、锁、SQL、表达式等千奇百怪的操作都在 MySQL 身上一一验证过, MySQL 可以说是久经考验,因此在功能上 MySQL 能满足我们所有的业务需求,MongoDB 却不能,且大部分的 NoSQL 也存在类似问题。
3.NewSQL(如 TiDB)
NewSQL 技术还比较新,我们曾经想在一些不重要的数据中使用 NewSQL(比如 TiDB),但从稳定性和功能扩展性两方面考量后,最终没有使用。
4.基于 MySQL 的分表分库
分表是将一份大的表数据拆分存放至多个结构一样的拆分表;分库就是将一个大的数据库拆分成多个结构一样的小库。
而市面上常用的中间件分为 2 类:Proxy 模式、Client 模式。
-
Proxy 模式:把 SQL 组合、数据库路由、执行结果合并等功能全部存放在一个代理服务中,而与分表分库相关的处理逻辑全部存放在另外的服务中,这种设计模式的优点是对业务代码无侵入,业务只需要关注自身业务逻辑即可。
-
Client 模式:把分表分库相关逻辑存放在客户端,一般客户端的应用会引用一个 jar,然后在 jar 中处理 SQL 组合、数据库路由、执行结果合并等相关功能。
3. Client 模式基于 Sharding-JDBC 来实现分表分库
在落实分表分库解决方案时,我们需要考虑 以下几个要点。
1. 使用什么字段作为分片键?
选择字段作为分片键时,我们一般需要考虑三点要求:数据尽量均匀分布在不同表或库、跨库查询操作尽可能少、这个字段的值不会变。
2. 分片的策略是什么?
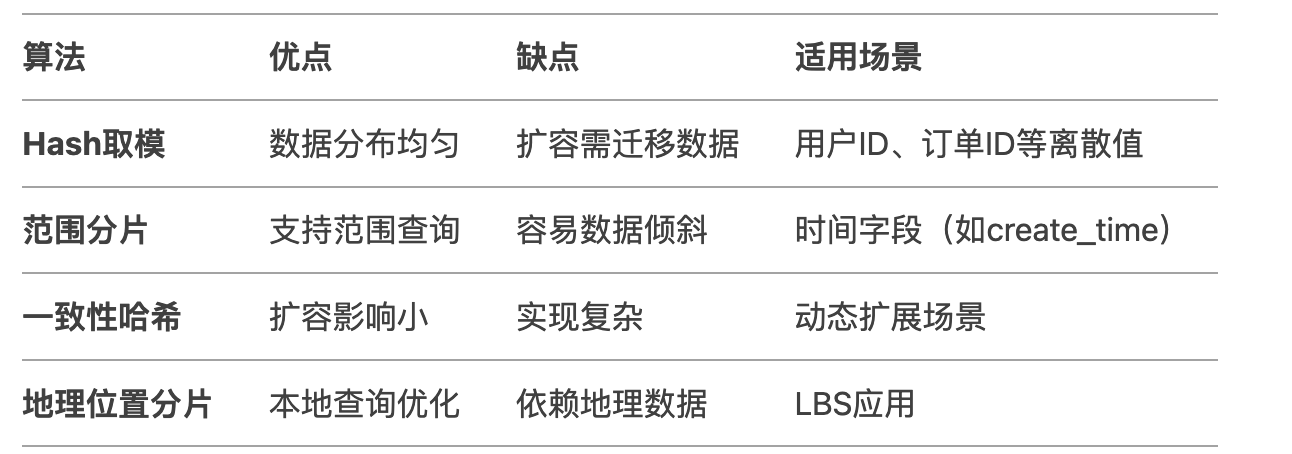
目前,市面上通用的分片策略如下:
3.数据迁移方案
双写方案:
-
新写入数据同时写入旧库和新分片库。
-
使用数据同步工具(如Canal)将历史数据迁移到新库。
-
迁移完成后切换读流量到新库。
停机迁移:
-
停服后通过 mysqldump 导出数据。
-
按分片规则导入到新库。
-
修改应用配置指向新库后恢复服务。
4. 未来的扩容方案是什么?
随着业务的发展,如果原来的分片设计已经无法满足日益增长的数据需求,我们就需要考虑扩容了,扩容方案主要依赖以下两点。
-
分片策略是否可以让新表数据的迁移源只是 1 个旧表,而不是多个旧表,这就是前面我们建议使用 2 的 N 次方分表的原因;
-
数据迁移:我们需要把旧分片的数据迁移到新的分片上。
5.分布式事务
跨库更新时如何保证ACID。通过Seata AT模式:全局锁实现最终一致性。
6.全局ID生成
-
Snowflake算法:64位结构(时间戳+机器ID+序列号)。
-
数据库号段:每次从数据库获取一批ID(如美团的Leaf)。
-
Redis INCR:利用Redis原子操作生成ID。
4.最后
分库分表的本质是 用架构复杂度换取性能和扩展性,需结合业务特点选择分片策略。建议优先使用成熟的中间件(如ShardingSphere),重点解决分片键选择、ID生成、跨分片查询等核心问题。对于中小团队,可先尝试单库分表,再逐步过渡到多库分表。