在房地产数据分析和研究中,获取真实的二手房市场数据是非常有价值的。本文将介绍如何使用Python爬虫技术从链家网获取广州市二手房数据,并进行可视化分析。
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
一、项目背景
随着房地产市场的不断发展,二手房交易在房地产市场中占据了重要地位。对于购房者来说,了解二手房的详细信息,如户型、面积、朝向、价格等,是做出合理购房决策的关键。对于房地产从业者、市场分析师以及相关研究人员而言,掌握大量的二手房源数据有助于进行市场趋势分析、房价走势预测以及投资机会评估等工作。
广州作为中国重要的经济中心和一线城市,其二手房市场活跃且复杂。链家作为知名的房地产中介品牌,其网站上发布的二手房信息具有较高的准确性和完整性,是获取广州二手房数据的重要渠道。因此,开发一个能够高效、准确采集广州链家二手房数据的爬虫项目具有重要的现实意义。
二、项目意义
(一)为购房者提供决策支持
通过采集和整理广州链家二手房的数据,购房者可以更全面地了解市场上的房源情况,包括不同区域的房价水平、户型分布、房屋朝向等信息。这些数据可以帮助购房者根据自身需求和预算,更精准地筛选出符合要求的房源,从而做出更明智的购房决策,避免盲目跟风或因信息不对称而做出错误选择。
(二)助力房地产市场分析
对于房地产市场分析师来说,大量的二手房数据是进行市场研究的基础。采集到的广州链家二手房数据可以用于分析不同区域的房价走势、供需关系、市场热度等。通过对这些数据的深度挖掘和分析,可以为房地产开发商提供市场趋势预测,帮助他们合理规划开发项目;为政策制定者提供数据支持,以便制定更加科学合理的房地产调控政策;为金融机构提供风险评估依据,优化贷款审批流程。
(三)促进房地产行业数字化转型
随着大数据、人工智能等技术在房地产行业的应用,房地产行业的数字化转型正在加速。通过爬虫技术采集二手房数据,可以为房地产企业积累大量的数据资产。这些数据可以进一步用于开发智能推荐系统、价格预测模型等应用,提升房地产企业的运营效率和服务质量,推动房地产行业的数字化、智能化发展。
三、前期准备
(一)依赖库的安装
requests 是一个非常流行的 HTTP 库,用于发送 HTTP 请求
parsel 是一个用于解析 HTML 和 XML 的库,基于 lxml 和 cssselect。它提供了方便的解析接口,支持 XPath 和 CSS 选择器。
pandas 是一个开源的数据分析和操作库,提供了强大的数据结构和数据分析工具
matplotlib 是一个用于创建静态、动画和交互式可视化的 Python 库
seaborn 是基于 matplotlib 的一个高级可视化库,提供了更多美观的图表样式
warnings 库是 Python 的标准库,用于处理警告信息。内置库
pip install requests parsel pandas matplotlib seaborn
(二)验证库安装
在安装完所有依赖库后,建议在 Python 环境中验证这些库是否安装成功。若未发生报错即是成功安装。
import requests
import parsel
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
print("所有依赖库安装成功!")四、数据采集分析
(一)采集字段
| 数据类别 | 具体字段 | 说明 |
|---|---|---|
| 房源基本信息 | 标题 | 二手房的标题描述 |
| 小区名称 | 房源所在小区名称 | |
| 所在区域 | 行政区或商圈位置(如天河区、越秀区等) | |
| 价格信息 | 总价(万元) | 房源总售价(单位:万元) |
| 单价 | 每平方米价格(元/㎡) | |
| 房屋属性 | 户型 | 如"3室1厅"、"2室2厅"等 |
| 面积 | 建筑面积(单位:平方米) | |
| 朝向 | 房屋朝向(如"南"、"南北通透"等) | |
| 装修 | 装修程度(精装、简装、毛坯等) | |
| 楼层 | 所在楼层及总楼层(如"低层/6层") | |
| 建房年份 | 建筑年代(如"2005年建") | |
| 市场热度 | 关注人数 | 近期关注该房源的人数统计 |
| 发布时间 | 房源信息发布时间(如"7天前发布") | |
| 扩展信息 | 详情页链接 | 房源详细信息的独立页面URL |
(二)目标网站分析
目标网址: 广州链家二手房
对于链家,目前采集多页的话需要登录(不登陆第五页就自动跳转到登录页面),request发包的话可以跳过逆向登录,然后进行会话的维持。但是为了方便,可以简单的登录后获取cookie字段中的 lianjia_token 的这个值即可。如代码所示:
cookies = {
"lianjia_token": , # 填入登录后的该值
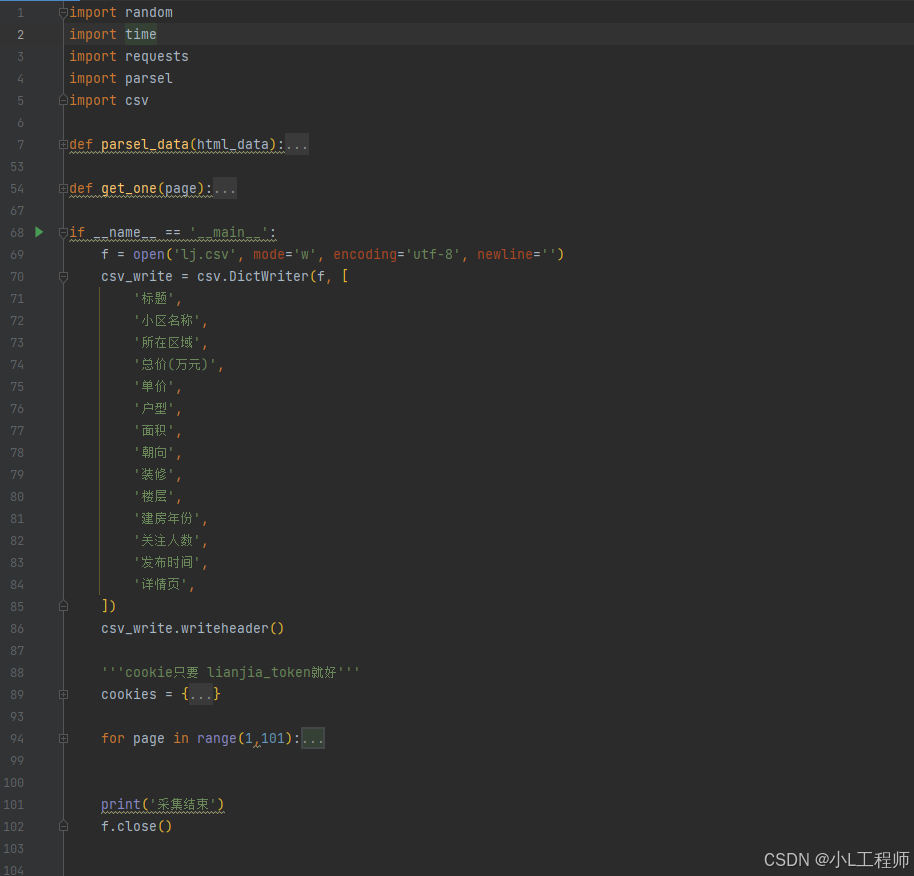
}(三)采集步骤
1. 首先采集所有房源的 li 标签,然后再跳过循环进行单个的数据解析
lis = parsel_txt.xpath('//ul[@class="sellListContent"]/li')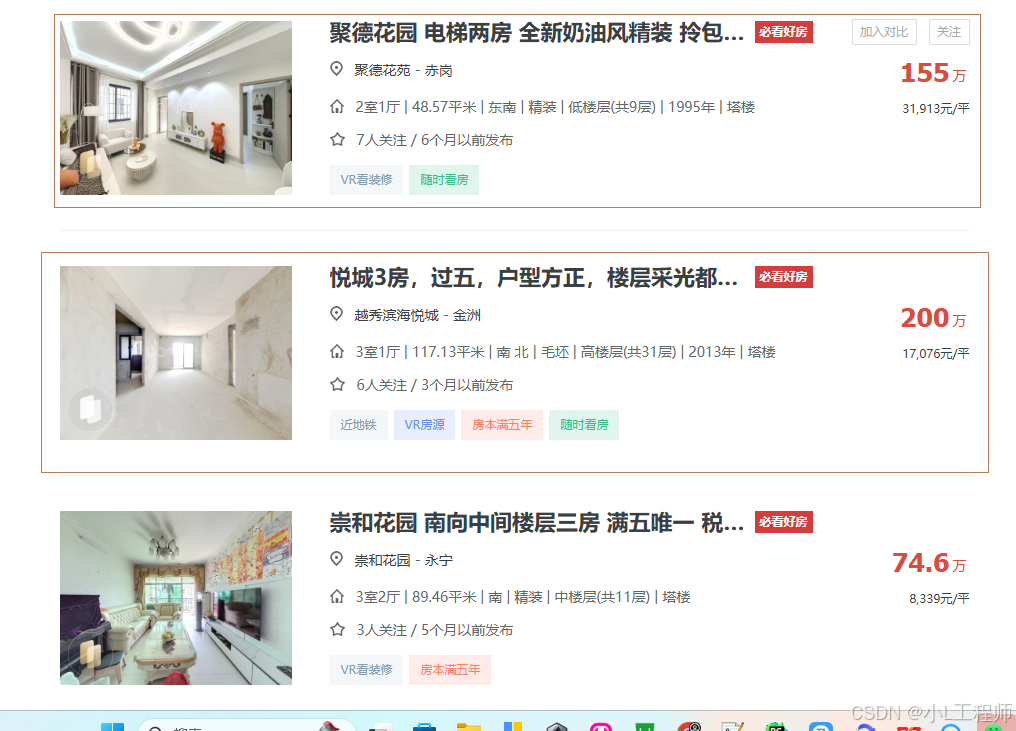
2.对单个整体的li标签进行数据的提取,获取标题,小区名称。所在区域,总价,单价等等字段的信息
for li in lis:
'''编写数据解析语法,进行数据的提取'''
dic = {
'标题':title,
'小区名称':Community_name,
'所在区域':region,
'总价(万元)':totalprice,
'单价':unitPrice,
'户型':house_type,
'面积':house_area,
'朝向':house_face,
'装修':house_decoration,
'楼层':house_floor,
'建房年份':house_year,
'关注人数':followers_num,
'发布时间':put_time,
'详情页':info_url,
}3.数据的保存
##csv保存
f = open('lj.csv', mode='w', encoding='utf-8', newline='')
csv_write = csv.DictWriter(f, [
'标题',
'小区名称',
'所在区域',
'总价(万元)',
'单价',
'户型',
'面积',
'朝向',
'装修',
'楼层',
'建房年份',
'关注人数',
'发布时间',
'详情页',
])
csv_write.writeheader()
dic = {
'标题':title,
'小区名称':Community_name,
'所在区域':region,
'总价(万元)':totalprice,
'单价':unitPrice,
'户型':house_type,
'面积':house_area,
'朝向':house_face,
'装修':house_decoration,
'楼层':house_floor,
'建房年份':house_year,
'关注人数':followers_num,
'发布时间':put_time,
'详情页':info_url,
}
csv_write.writerow(dic)# 数据库保存
def insert():
sql_format = """
insert into douban1_top250(title, Community_name, region, totalprice, unitPrice等等,自行添加)
values ('%s', '%s', '%s', '%s', '%s');
"""
cursor.execute(sql_format % (title, Community_name, region, totalprice, unitPrice等等,自行添加))
connection.commit()
# 连接数据库
connection = pymysql.connect(
host='localhost',
user='root', # 替换为你的MySQL用户名
password='', # 替换为你的MySQL密码
database='qd_test1', # 替换为你的数据库名
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
try:
with connection.cursor() as cursor:
#######先创建表##############
cursor.execute("""
CREATE TABLE IF NOT EXISTS `douban1_top250` (
`id` INT AUTO_INCREMENT PRIMARY KEY,
`movie_name` VARCHAR(255) NOT NULL,
`movie_score` VARCHAR(50) NOT NULL,
`movie_time` VARCHAR(50) NOT NULL,
`movie_area` VARCHAR(100) NOT NULL,
`movie_type` VARCHAR(100) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
""")
insert()
finally:
cursor.close() # 先关闭游标
connection.close() # 然后关闭数据库连接
f.close()(四)结果展示

(一)采集字段
五、完整代码
(一)数据采集(爬虫)部分代码
<如果您对源码(爬虫+可视化)感兴趣(不白嫖)迪迦,可以在评论区留言(主页 \/)伪善,我会根据需求提供指导和帮助>
(二)可视化代码
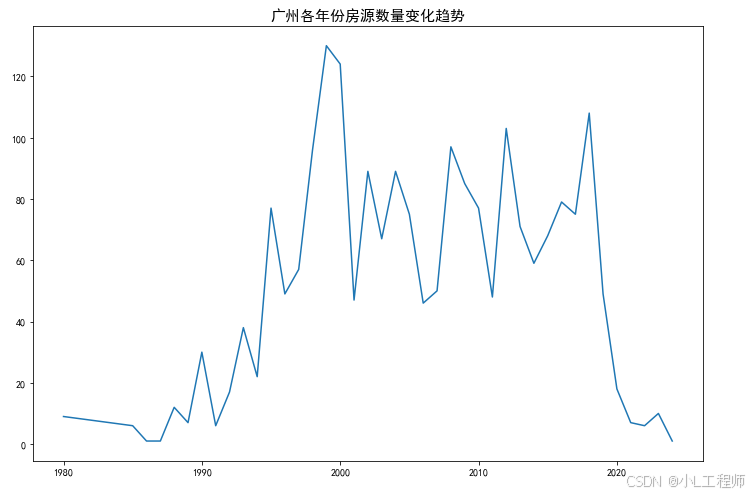
1 广州各年份房源数量变化趋势
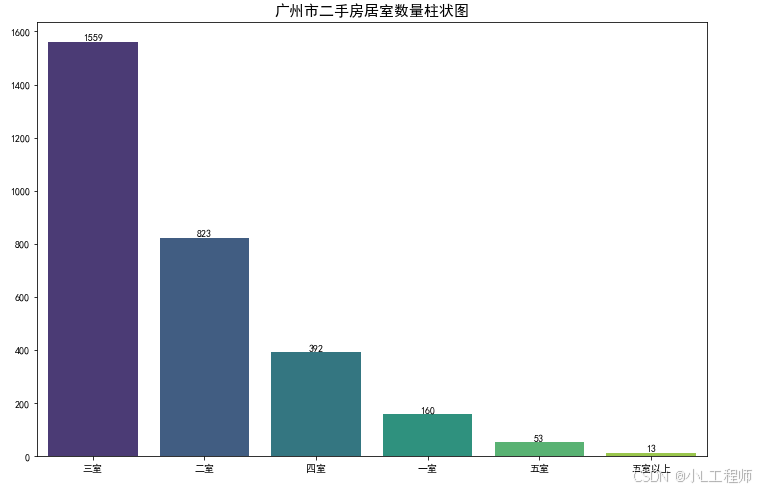
2.广州市二手房居室数量柱状图
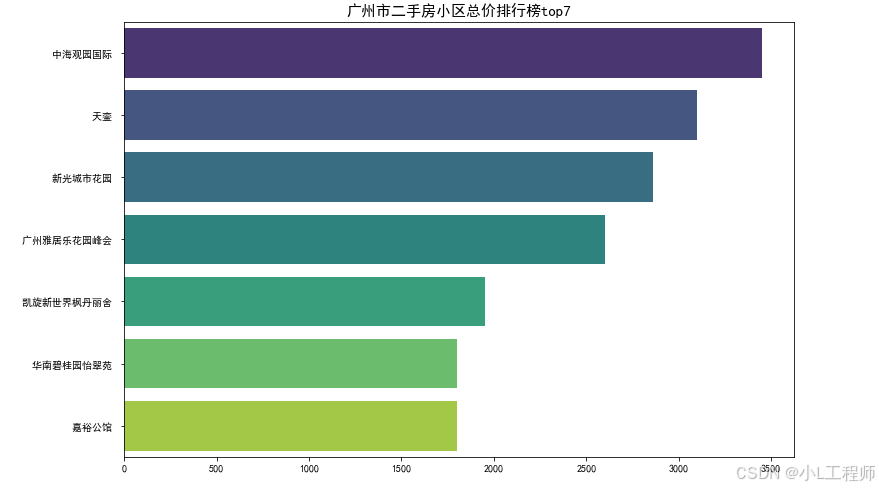
3 广州市二手房小区单价排行榜top7
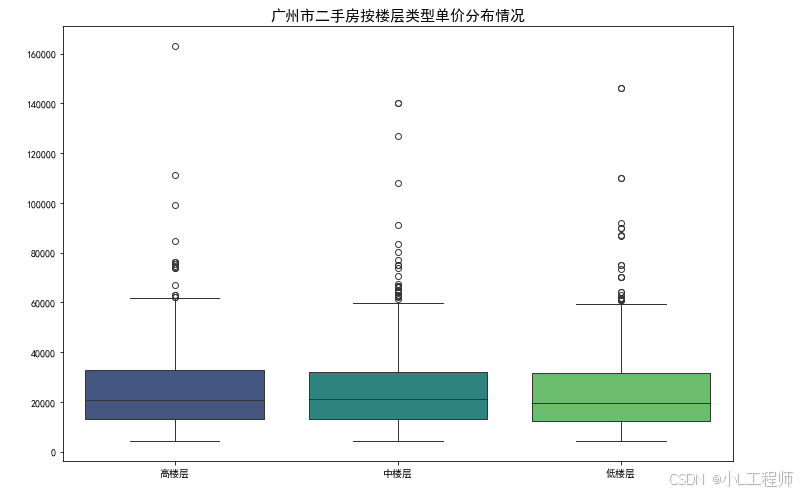
4 广州市二手房按楼层类型单价分布情况
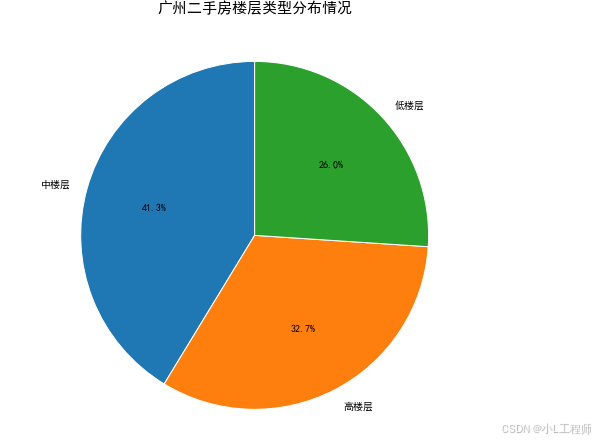
5 广州二手房楼层类型分布情况
6 标题词云

(三) 可视化代码
'''可视化1'''
year_df = df['建房年份'].value_counts().reset_index().sort_values(by='index')
year_df.columns=['建房年份','数量']
plt.figure(figsize=(12,8))
sns.lineplot(data=year_df,x='建房年份',y='数量')
plt.title('广州各年份房源数量变化趋势',fontsize=15)
plt.xlabel('')
plt.ylabel('')
plt.show()
'''可视化2'''
room_df = df['居室数量'].value_counts().reset_index()
plt.figure(figsize=(12,8))
sns.barplot(data=room_df,x='index',y='居室数量',palette='viridis')
for index, row in room_df.iterrows():
plt.text(row.name, row['居室数量'], str(row['居室数量']), ha='center', va='bottom', fontsize=10)
plt.title('广州市二手房居室数量柱状图',fontsize=15)
plt.xlabel('')
plt.ylabel('')
plt.show()
'''可视化3'''
df_top7 = df.groupby('小区名称')['总价(万元)'].mean().reset_index().sort_values(by='总价(万元)',ascending=False)[:7]
plt.figure(figsize=(12,8))
sns.barplot(data=df_top7,x='总价(万元)',y='小区名称',palette='viridis')
plt.title('广州市二手房小区总价排行榜top7',fontsize=15)
plt.xlabel('')
plt.ylabel('')
plt.show()
'''可视化4'''
plt.figure(figsize=(12,8))
sns.boxplot(data=df,x='楼层类型',y='单价',palette='viridis')
plt.title('广州市二手房按楼层类型单价分布情况',fontsize=15)
plt.xlabel('')
plt.ylabel('')
plt.show()
'''可视化5'''
floor_df = df['楼层类型'].value_counts().reset_index()
floor_df.columns=['楼层类型','数量']
plt.figure(figsize=(8, 8))
plt.pie(floor_df['数量'], labels=floor_df['楼层类型'], autopct='%1.1f%%', startangle=90, wedgeprops=dict(edgecolor='w'))
plt.title('广州二手房楼层类型分布情况', fontsize=15)
plt.show()
'''可视化6'''
from wordcloud import WordCloud
text = ' '.join(df['标题'])
wordcloud = WordCloud(
width=800, # 宽度
height=400, # 高度
background_color='white', # 背景颜色
max_words=100, # 最大显示的词数
font_path='simhei.ttf' # 字体文件
).generate(text)
plt.figure(figsize=(12, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()