在当今数字化时代,网络爬虫技术已成为数据获取的重要手段之一。本文将通过一个实际案例——采集51job招聘信息,详细介绍如何使用Python和Selenium框架实现数据采集。我们将从环境准备、网页结构分析、采集字段说明到爬虫实现步骤等方面展开,帮助读者快速掌握相关技术。
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本篇文章使用的是seleniunm接管已经打开的浏览器进行数据采集,原理不懂的可以看之前的技术博客 ( selenium接管已经打开的浏览器)
一、项目背景
51job是中国知名的招聘网站,提供了海量的职位信息。这些信息对于求职者和招聘者都具有重要价值。通过采集51job的招聘信息,我们可以进行数据分析、市场调研或为求职者提供决策支持。本文的目标是实现一个自动化采集程序,获取51job上特定关键词(如“大数据”)的职位信息,并将其保存为CSV文件。
二、环境准备
在开始项目之前,我们需要准备以下开发环境和工具:
-
Python环境
确保已安装Python(推荐3.8及以上版本)。可以通过以下命令安装必要的Python库:
pip install selenium pyautogui -
Selenium WebDriver
扫描二维码关注公众号,回复: 17634615 查看本文章
Selenium是一个用于自动化Web操作的工具,支持多种浏览器。本文使用Chrome浏览器,因此需要下载与浏览器版本匹配的ChromeDriver。下载地址:ChromeDriver - WebDriver for Chrome。下载后,将
chromedriver.exe放置在系统路径中或指定路径。 -
浏览器配置
为了方便调试,我们使用Selenium的远程调试功能。在启动Chrome浏览器时,添加以下启动参数:
chrome.exe --remote-debugging-port=9527这样,Selenium可以通过该端口连接到浏览器。
-
其他工具
-
Pyautogui:用于模拟鼠标操作,处理滑块验证码。
-
CSV:用于存储采集到的数据。
-
三、采集字段说明
在爬取51job的招聘信息时,我们主要关注以下字段:
-
岗位名称:招聘职位的名称。
-
岗位薪资:该职位的薪资范围。
-
岗位地区:工作地点。
-
岗位标签:与该职位相关的标签,如“五险一金”、“带薪年假”等。
-
公司名字:招聘公司的名称。
-
公司行业:公司所属的行业。
-
公司规模:公司的员工规模。
-
公司类型:公司的类型,如“民营公司”、“外资公司”等。
-
HR活跃程度:HR的活跃程度,如“刚刚活跃”、“3天前活跃”等。
四、采集方式优缺点对比
以下是通过表格形式对 Selenium 接管已打开的浏览器采集、Requests 抓包采集(需要逆向 sign 和 cookies) 以及 直接使用 Selenium 采集 的优缺点进行详细对比:
| 特性/方法 | Selenium 接管浏览器采集 | Requests 抓包采集(逆向 sign 和 cookies) | 直接使用 Selenium 采集 |
|---|---|---|---|
| 启动速度 | 快(无需重新启动浏览器) | 极快(无需启动浏览器) | 较慢(需启动浏览器实例) |
| 资源消耗 | 低(复用已有浏览器) | 极低(仅发起 HTTP 请求) | 高(需模拟用户操作) |
| 动态页面支持 | 强(支持 JavaScript 渲染) | 强(动静态数据) | 强(支持 JavaScript 渲染) |
| 反爬能力 | 中(可绕过简单验证) | 高(需逆向工程) | 高(可处理复杂验证) |
| 调试效率 | 高(保留状态,无需重复登录) | 中(需逆向分析) | 低(每次运行需重新启动) |
| 安全性 | 低(可能涉及用户敏感信息) | 高(无浏览器状态) | 中(需注意反爬机制) |
| 代码复杂度 | 中(需配置调试端口) | 高(需逆向工程) | 中(需模拟用户操作) |
| 适用场景 | 需保留登录状态或调试效率高的场景 | 静态网页或 API 数据采集 | 动态页面、复杂交互操作 |
| 维护成本 | 低(复用已有浏览器) | 高(需定期更新逆向逻辑) | 高(需更新 WebDriver 和代码) |
| 易用性 | 中(需熟悉 Selenium 和调试模式) | 高(代码简洁) | 低(需熟悉 Selenium 操作) |
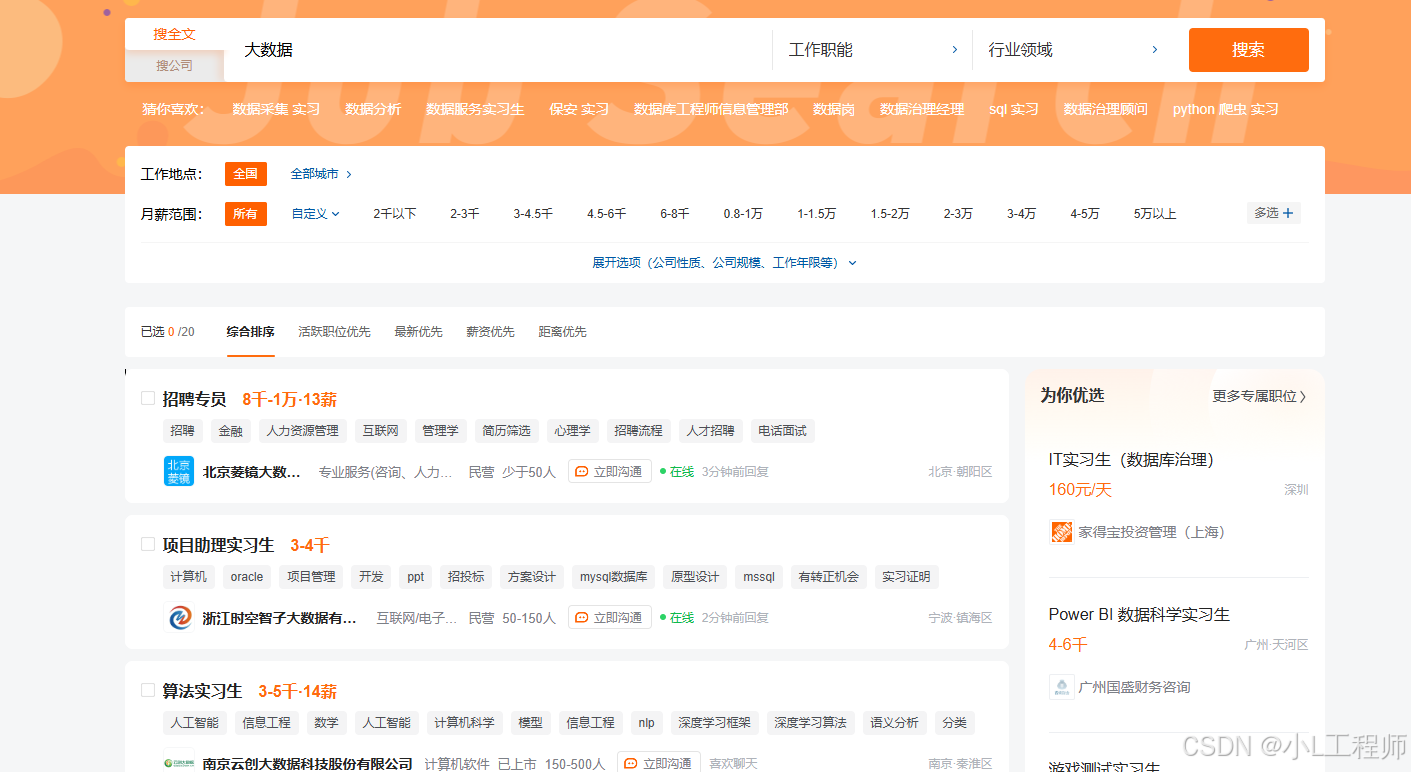
五、网页结构分析
在编写爬虫之前,我们需要对51job的网页结构进行分析,以便准确提取所需信息。
-
职位列表页面
职位搜索结果页面的URL格式为:
https://we.51job.com/pc/search?keyword=<关键词>例如,搜索“大数据”相关职位时,URL为:
https://we.51job.com/pc/search?keyword=大数据
-
职位信息的HTML结构
每个职位信息以
<div class="joblist-item">的形式展示。以下是关键字段的HTML结构分析:-
岗位名称:
<div class="joblist-item-top">下的<span>标签。 -
岗位薪资:
<span class="sal shrink-0">。 -
岗位地区:
<div class="area">。 -
岗位标签:
<div class="tag">下的多个<span>标签。 -
公司名字:
<a class="cname text-cut">。 -
公司行业、类型、规模:
<div class="bl">下的多个<span>标签。 -
HR活跃程度:
<div class="tip shrink-0">。
-
-
分页结构
51job的职位搜索结果支持分页,每页显示一定数量的职位。翻页按钮的HTML结构为:
<button class="btn-next">下一页</button>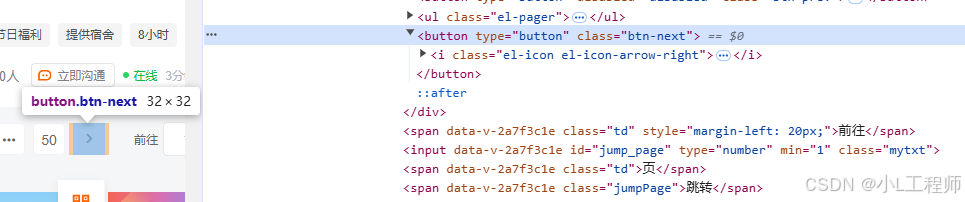
-
验证码处理
51job可能会在某些情况下弹出滑块验证码(采用接管的浏览器可以登录避免经常出现验证码)。为了应对这种情况,我们使用
pyautogui库模拟鼠标操作,完成滑块验证。
六、结果展示
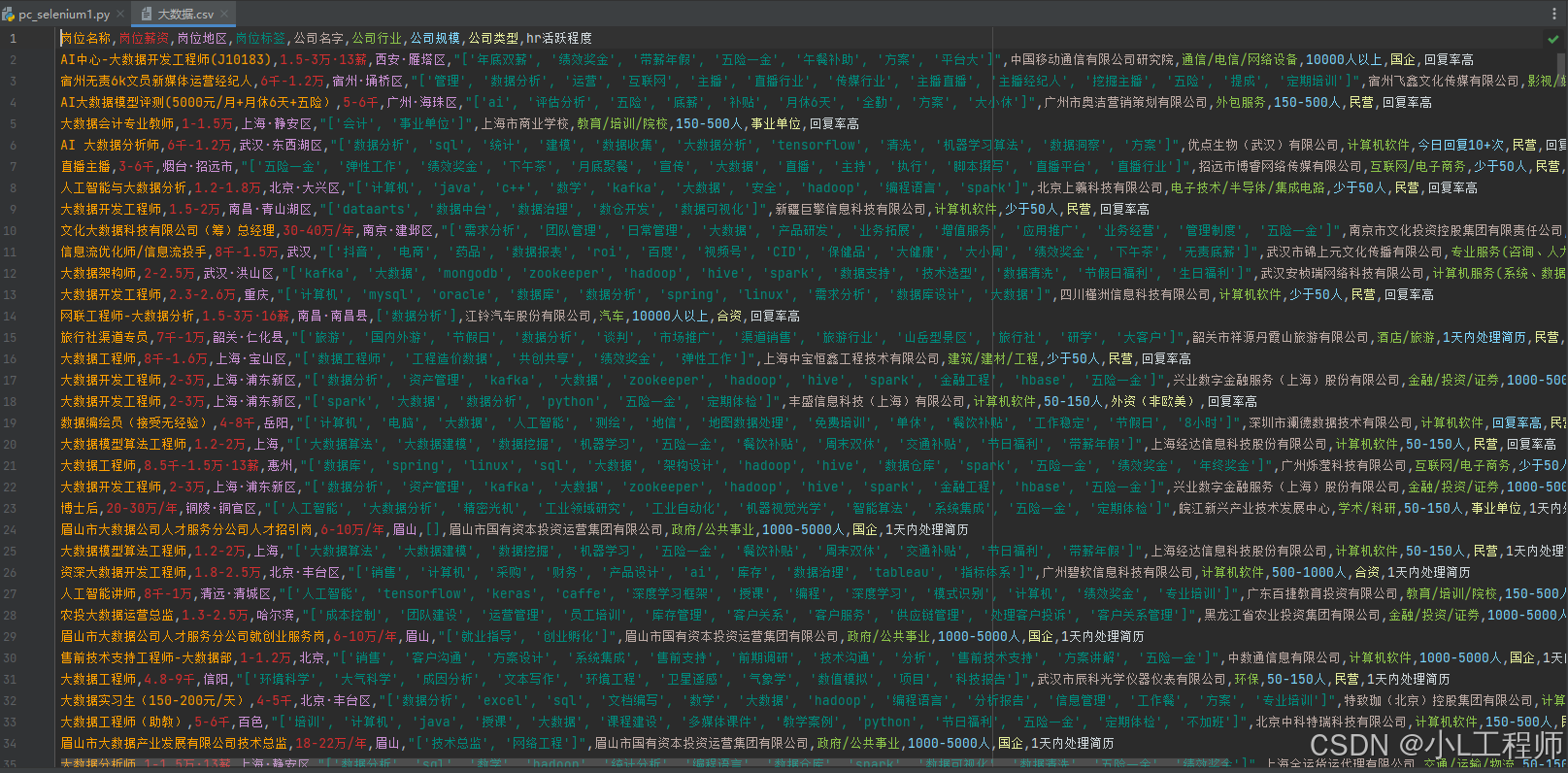
七、完整代码
(一)数据采集(爬虫)部分
<如果您对源码(爬虫+可视化)感兴趣(不白嫖)迪迦,可以在评论区留言(主页 \/)伪善,我会根据需求提供指导和帮助>
(二)可视化部分
1.岗位地域分布
from pyecharts import options as opts
from pyecharts.charts import Map
map_data = df['省份'].value_counts().reset_index().values.tolist()
map_chart = (
Map()
.add(
series_name="",
data_pair=map_data,
maptype="china",
is_map_symbol_show=False, # 禁用标记点
label_opts=opts.LabelOpts(is_show=True, font_size=8), # 调整省份字体大小
)
.set_global_opts(
title_opts=opts.TitleOpts(title="岗位地域分布地图"),
visualmap_opts=opts.VisualMapOpts(
is_piecewise=True, # 分段显示
pieces=[
{"min": 100, "label": "100+", "color": "#CD5C5C"},
{"min": 50, "max": 99, "label": "50-99", "color": "#F08080"},
{"min": 1, "max": 49, "label": "1-49", "color": "#FFA07A"},
{"min": 0, "max": 0, "label": "0", "color": "#FFFFFF"},
],
),
)
)
map_chart.render_notebook()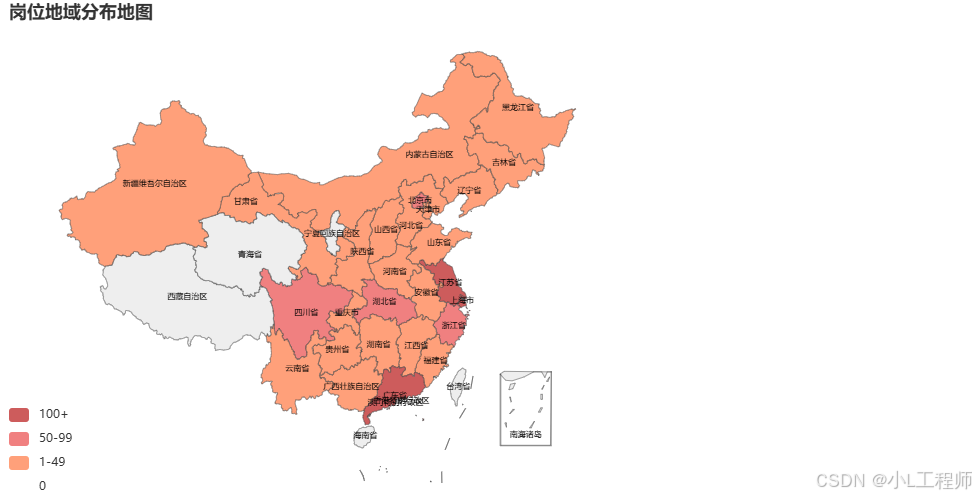
2.企业规模占比分布
size_counts = df['公司规模1'].value_counts()
sns.set_theme(style="whitegrid",rc={
"font.sans-serif": ["SimHei"], # 设置字体为黑体
"axes.unicode_minus": False, # 正确显示负号
"font.family": "sans-serif" # 设置字体族为 sans-serif
})
plt.figure(figsize=(8, 8))
plt.pie(
size_counts,
labels=size_counts.index,
autopct='%1.1f%%',
startangle=90,
colors=sns.color_palette("pastel"),
wedgeprops={'edgecolor': 'white', 'linewidth': 1.5},
textprops={'fontsize': 12, 'color': 'black'}
)
plt.title("企业规模占比分布", fontsize=16, fontweight='bold', pad=20)
plt.show()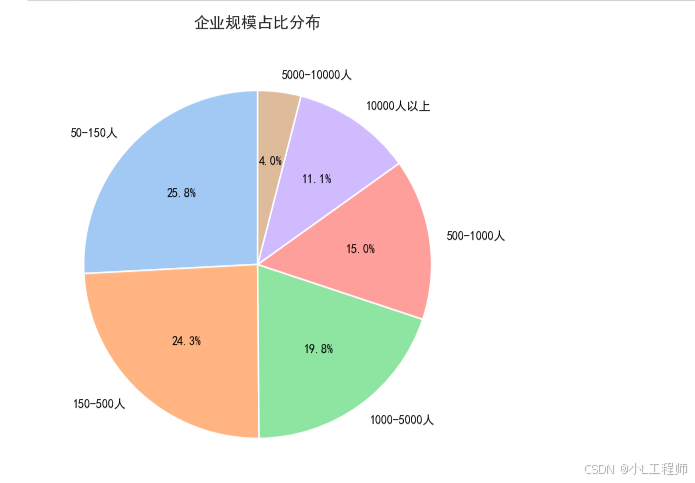
3.企业类型占比分布
size_counts = df['公司类型'].value_counts()
size_percentage = size_counts / size_counts.sum() * 100
# 找出占比小于 2% 的类别
small_categories = size_percentage[size_percentage < 2].index
# 将占比小于 2% 的类别合并为“其他”
size_counts['其他'] = size_counts[small_categories].sum()
size_counts = size_counts.drop(small_categories)
sns.set_theme(style="whitegrid", rc={
"font.sans-serif": ["SimHei"], # 设置字体为黑体
"axes.unicode_minus": False, # 正确显示负号
"font.family": "sans-serif" # 设置字体族为 sans-serif
})
plt.figure(figsize=(15, 10))
plt.pie(
size_counts,
labels=size_counts.index,
autopct='%1.1f%%', # 显示百分比
startangle=90, # 起始角度
colors=sns.color_palette("pastel"),
wedgeprops={'edgecolor': 'white', 'linewidth': 1.5},
textprops={'fontsize': 12, 'color': 'black'}
)
plt.title("企业类型占比分布", fontsize=16, fontweight='bold', pad=20)
plt.show()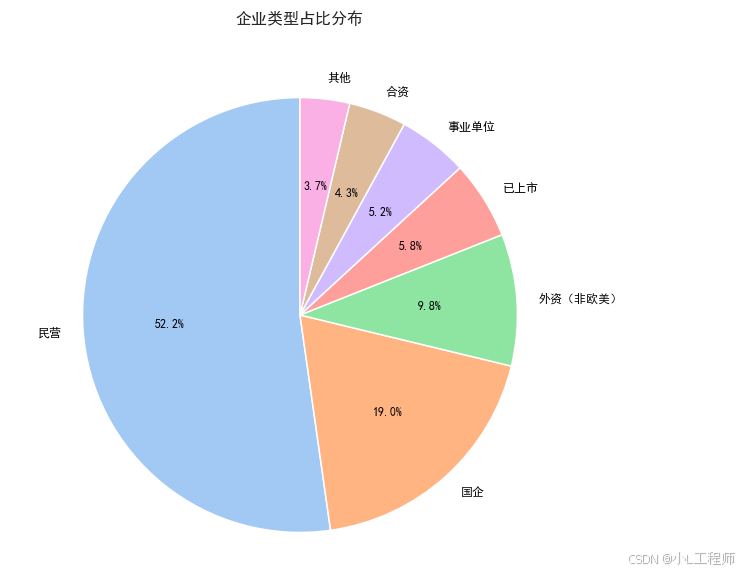
4.HR活跃程度统计分析
value_counts = df['hr活跃程度1'].value_counts()
plt.figure(figsize=(8, 6)) # 设置图形大小
sns.barplot(x=value_counts.index, y=value_counts.values, palette='viridis')
plt.title('HR活跃程度统计分析', fontsize=16)
plt.xlabel('')
plt.ylabel('')
plt.show()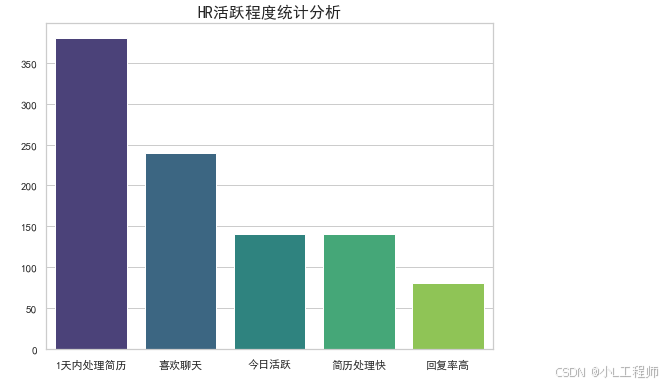
5.企业数量Top 7
top_7 = df['公司名字'].value_counts().head(7)
plt.figure(figsize=(15, 6))
sns.barplot(x=top_7.values, y=top_7.index, palette='viridis')
plt.title('企业数量Top 7', fontsize=16)
plt.xlabel('',)
plt.ylabel('',)
# plt.yticks(rotation=15, fontsize=12)
plt.show()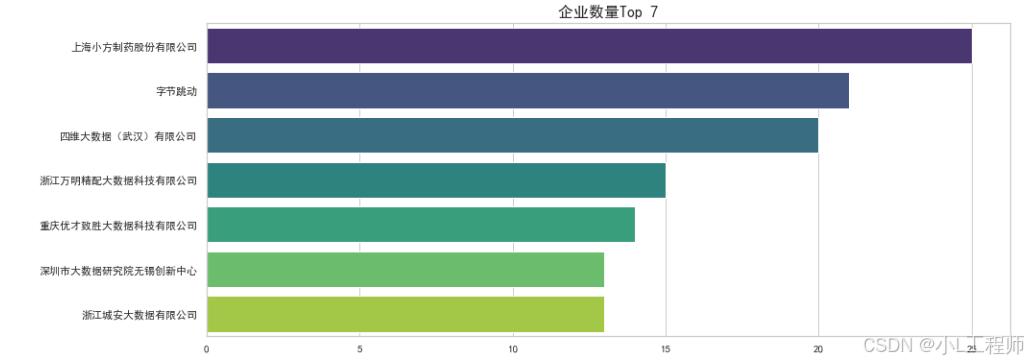
6.岗位标签词云
from wordcloud import WordCloud
import jieba
df['岗位标签1'] = df['岗位标签'].apply(lambda x: ' '.join(eval(x)))
all_text = ' '.join(df['岗位标签1'])
# 使用 jieba 进行分词
words = jieba.lcut(all_text)
all_text = ' '.join(words)
# 创建词云对象
wordcloud = WordCloud(
font_path='simhei.ttf', # 设置字体路径(支持中文)
width=800,
height=600,
background_color='white', # 设置背景颜色
max_words=100, # 设置最多显示的词数
min_font_size=10, # 设置最小字体大小
max_font_size=100, # 设置最大字体大小
random_state=42 # 设置随机种子
).generate(all_text)
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off') # 关闭坐标轴
plt.title('', fontsize=16)
plt.show()