在自动化测试领域,Selenium 无疑是王者般的存在。然而,传统的 Selenium 脚本通常需要从头启动浏览器,这在实际应用中可能会带来一些不便。例如,当我们需要调试脚本时,每次运行脚本都需要重新登录网站,这无疑会浪费大量时间。那么,有没有办法让 Selenium 接管已经打开的浏览器,从而避免重复登录等操作呢?答案是肯定的!本文将详细介绍如何使用 Selenium 接管已经打开的 Chrome 浏览器,并对比其与直接使用 ChromeDriver 的优缺点,最后探讨其实际应用场景。
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!

一、Selenium 接管已经打开的 Chrome 浏览器
1. 环境准备
-
安装 Chrome 浏览器:确保 Chrome 浏览器已安装,并且版本与 ChromeDriver 匹配。
-
下载对应版本的 ChromeDriver:从 ChromeDriver 官方网站 下载与 Chrome 浏览器版本一致的 ChromeDriver。
-
安装 Selenium:使用 pip 命令安装 Selenium
pip install selenium
2. 实现步骤
步骤一:找到谷歌浏览器的的文件夹
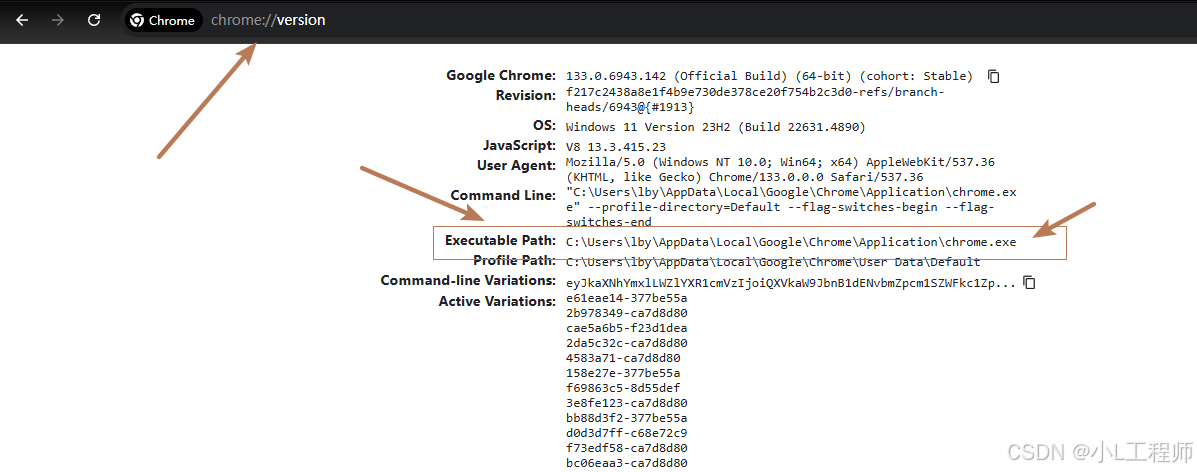
打开谷歌浏览器,输入:chrome://version/
然后复制exe文件的目录 C:\Users\lby\AppData\Local\Google\Chrome\Application
步骤二:创建启动浏览器的 bat 文件
为了方便启动 Chrome 浏览器并开启调试端口,我们可以创建一个 bat 文件。以下是 bat 文件的内容(先在记事本输入并保存,然后改后缀为bat):
cd C:\Users\lby\AppData\Local\Google\Chrome\Application
chrome --remote-debugging-port=9527 --user-data-dir="C:\Users\lby\Desktop\selenium\selenium_t"bat 文件解释:
-
cd C:\Users\lby\AppData\Local\Google\Chrome\Application:切换到 Chrome 浏览器的安装目录。 -
chrome --remote-debugging-port=9527 --user-data-dir="C:\Users\lby\Desktop\selenium\selenium_t":启动 Chrome 浏览器,并指定调试端口为 9527,用户数据目录为C:\Users\lby\Desktop\selenium\selenium_t。
数据目录和端口可以自行设置,不冲突即可
步骤三:编写 Python 脚本接管已打开的浏览器
首先,双击之前的bat文件(打开端口为9527的谷歌浏览器);最后执行代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")# 连接已开的浏览器
driver = webdriver.Chrome(options=chrome_options)
# 操作已打开的浏览器
driver.get("https://www.baidu.com")
print(driver.title)
# 关闭浏览器
driver.quit()代码解释:
-
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9527"):设置调试地址为本地 9527 端口,与启动浏览器时指定的端口一致。 -
webdriver.Chrome(options=chrome_options):使用 ChromeDriver 连接已打开的浏览器。
注意事项:
-
确保 ChromeDriver 的路径已添加到系统环境变量中,或者在代码中指定 ChromeDriver 的路径。
-
如果浏览器未启动或调试端口未打开,脚本将无法连接浏览器。
二、接管已打开的浏览器 vs 直接使用 ChromeDriver
| 特性 | 接管已打开的浏览器 | 直接使用 ChromeDriver |
|---|---|---|
| 启动速度 | 快,无需重新启动浏览器 | 慢,需要启动浏览器 |
| 浏览器状态 | 保留浏览器历史记录、cookies 等 | 全新浏览器会话 |
| 调试效率 | 高,无需重复登录等操作 | 低,需要重复登录等操作 |
| 适用场景 | 调试脚本、需要保留浏览器状态的场景 | 全新测试环境、需要隔离测试数据的场景 |
三、实际应用场景
-
调试自动化测试脚本:在调试脚本时,可以避免每次运行脚本都需要重新登录网站,提高调试效率。
-
爬虫数据采集:可以绕过网站登录验证,直接采集需要登录才能访问的数据。
-
自动化操作浏览器:可以对已经打开的浏览器进行自动化操作,例如自动填写表单、点击按钮等。
-
持续集成/持续交付 (CI/CD):在 CI/CD 管道中,可以利用接管浏览器的功能,避免每次构建都重新启动浏览器,提高构建效率。
四、具体案例场景(附案例代码)
比如需要采集一个商品的参数信息,这是需要登录后才能查看的。要是直接采用chromedriver的话,就要进行登录。一般大厂的登录都比较难搞,这样就可以采用selenium接管已经打开的浏览器进行数据的采集。先点击之前的bat文件,登录网址,进入目标页面。
代码如下:
from pprint import pprint
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
#页面滚动
def drop_down():
"""执行页面滚动的操作""" # javascript
# 使用selenium 去执行 JS代码
for x in range(1, 10, 3): # 1 3 5 7 9 在你不断的下拉过程中, 页面高度也会变的
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
bro.execute_script(js)
def parsel_data():
try:
bro.maximize_window()
except:
print('页面已经最大化')
'''页面滚动下拉'''
drop_down()
dic = {}
divs = bro.find_elements(By.CSS_SELECTOR,'.tableWrapper--APDk75pt>div')
for div in divs:
key_ = div.find_element(By.CSS_SELECTOR,'.infoItemTitle--P41WPBIx').text
values_ = div.find_element(By.CSS_SELECTOR,'.infoItemContent--IJwpPvuk').text
if key_:
dic[key_] = values_
else:
continue
pprint(dic)
if __name__ == '__main__':
# 配置 ChromeOptions
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
# 使用 ChromeDriver 连接已打开的浏览器
bro = webdriver.Chrome(options=chrome_options)
'''执行解析函数'''
parsel_data()
bro.quit()结果图下:
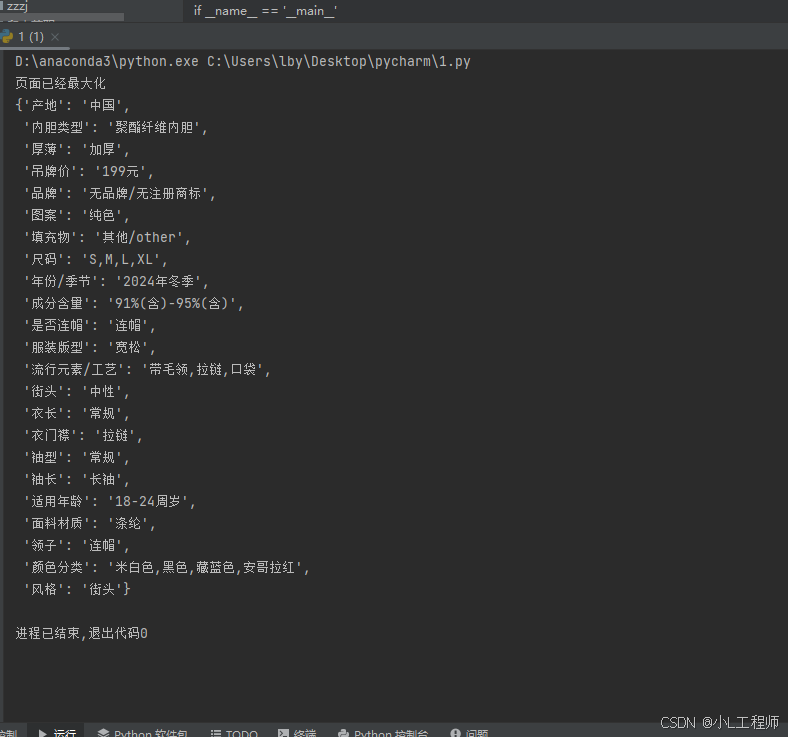
五、总结
Selenium 接管已经打开的浏览器功能为自动化测试和浏览器自动化操作提供了更灵活的选择。通过对比可以看出,接管已打开的浏览器在调试效率和保留浏览器状态方面具有明显优势,但在需要隔离测试数据的场景下,直接使用 ChromeDriver 仍然是更好的选择。
希望本文能够帮助你更好地理解和使用 Selenium 接管已经打开的浏览器功能,提升你的自动化测试效率!
进一步优化建议:
-
可以使用
subprocess模块在 Python 脚本中自动启动 Chrome 浏览器并开启调试端口。 -
可以使用
os模块动态获取 ChromeDriver 的路径,提高脚本的可移植性。 -
可以使用
logging模块记录脚本运行日志,方便调试和问题排查。