在当今数据驱动的时代,获取和分析电影票房数据对于电影行业从业者、数据分析师以及电影爱好者来说至关重要。本文将介绍如何使用Python编写一个简单的爬虫程序,从猫眼电影网站上爬取2011年至2025年的电影票房排行榜数据,并将数据保存到CSV文件中。
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
1. 爬虫目标
我们的目标是爬取猫眼电影票房排行榜的数据,包括以下内容:
-
片名
-
上映时间
-
票房(万元)
-
平均票价
-
场均人次
2. 爬虫工具
为了实现爬虫功能,我们使用以下Python库:
-
requests:用于发送HTTP请求,获取网页内容。
-
parsel:用于解析HTML页面,提取所需数据。
-
csv:用于将数据保存为CSV格式,方便后续处理。
-
time 和 random:用于控制爬虫的请求间隔,避免被反爬机制限制。
你可以通过以下命令安装这些库:
pip install requests parsel3. 网页结构分析
3.1 目标网页
猫眼电影的票房排行榜页面 URL 如下:影片总票房排行榜
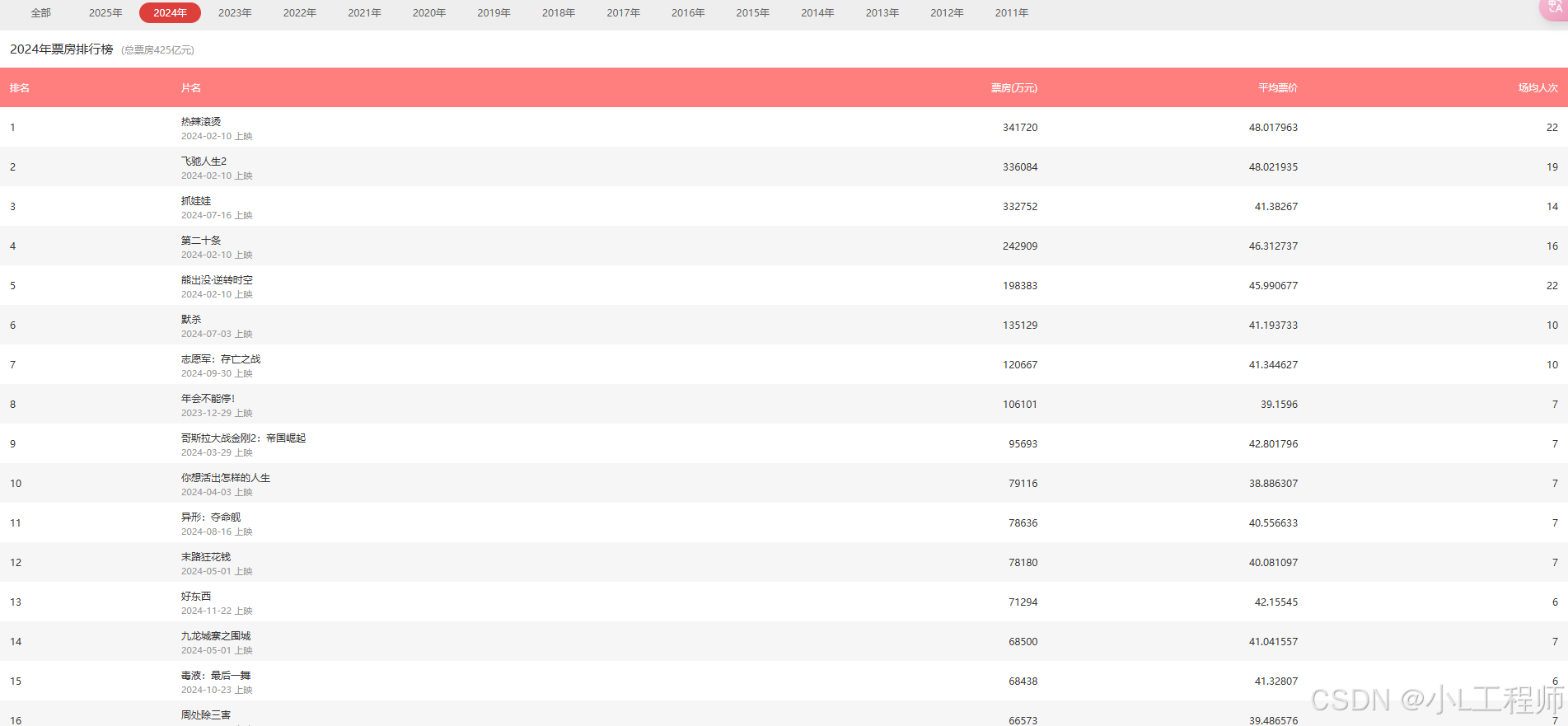
该页面展示了每年的电影票房排行榜数据。我们需要通过修改请求参数来获取不同年份的数据。
3.2 数据加载方式
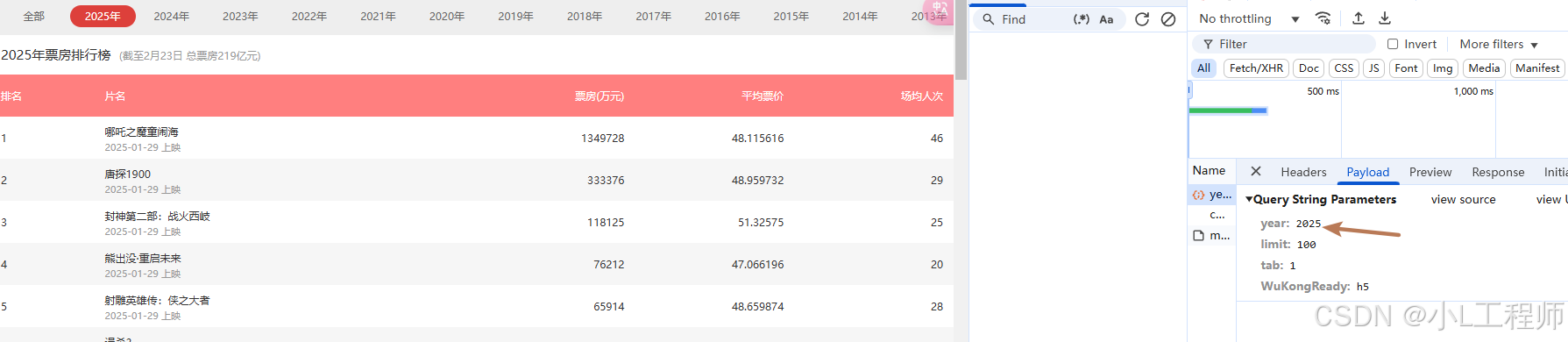
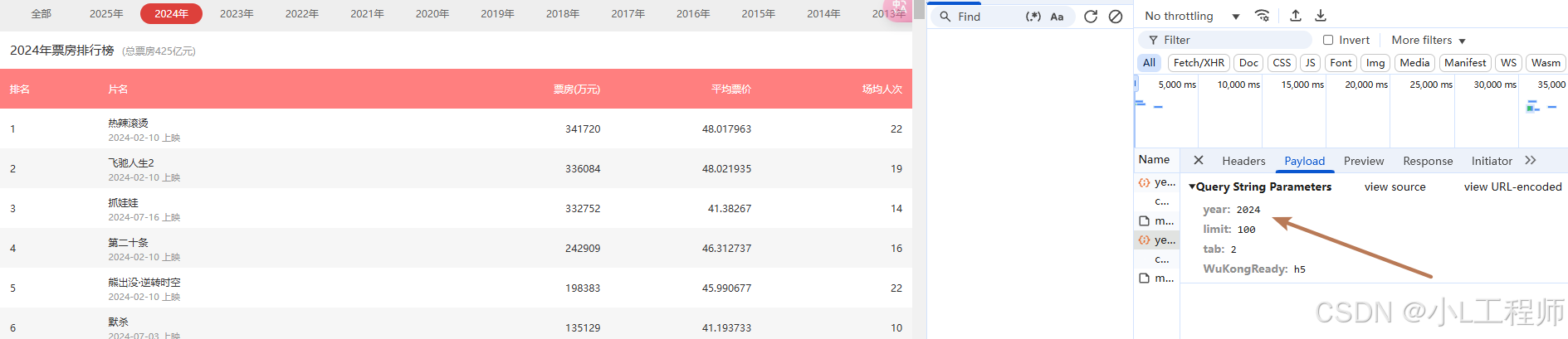
通过浏览器的开发者工具(按 F12 打开),我们可以观察到以下内容:
-
数据加载方式:数据是通过
GET请求加载的,数据直接嵌入在 HTML 中,而不是通过异步接口(如 AJAX)加载。 -
请求参数:
-
year:指定要查询的年份。 -
limit:指定返回的电影数量(默认为 100)。 -
tab:指定排行榜的类型(3表示年度票房排行榜)。 -
WuKongReady:似乎是猫眼网站的一个标识参数,固定为h5。
-
3.3 翻页参数
从网页结构来看,猫眼的年度票房排行榜页面没有明显的翻页参数。所有数据都直接加载在一个页面中,因此我们只需要修改 year 参数即可获取不同年份的数据。
4.数据展示
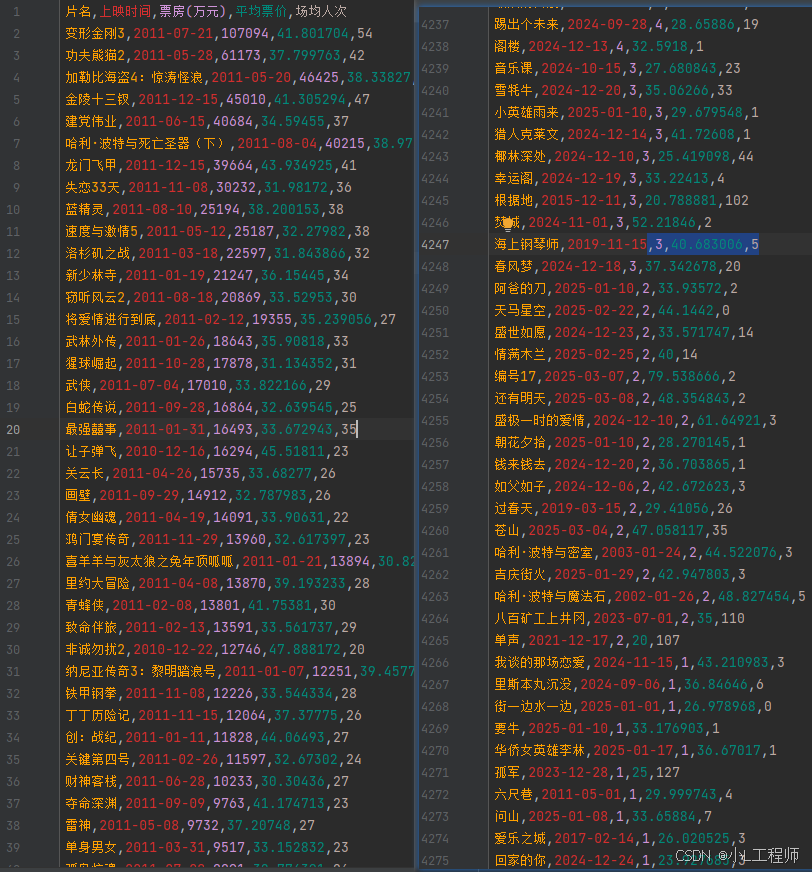
5.完整代码
5.1 完整数据采集代码
<如果您对源码(爬虫+可视化)感兴趣(不白嫖)迪迦,可以在评论区留言(主页 \/)伪善,我会根据需求提供指导和帮助>
5.2 可视化结果
1. 电影上映年度票房变化趋势
-
意义:通过分析电影上映年度的票房变化趋势,可以了解电影市场的整体发展情况。例如,票房是否逐年增长,是否存在某些年份的票房波动较大等。
-
应用:电影制作公司和发行公司可以根据这些趋势调整电影的上映策略,选择在票房较高的年份上映电影,以获得更好的市场表现。
# 确保上映时间是日期格式
df['上映时间'] = pd.to_datetime(df['上映时间'])
df['年份'] = df['上映时间'].dt.year
# 1. 年度票房总览(柱状图)
annual_box_office = df.groupby('年份')['票房(万元)'].sum()[-15:]
plt.figure(figsize=(12, 6))
annual_box_office.plot(kind='line', marker='o', color='orange')
plt.title('电影上映年度票房变化趋势')
plt.xlabel('年份')
plt.ylabel('总票房(万元)')
plt.grid()
plt.show()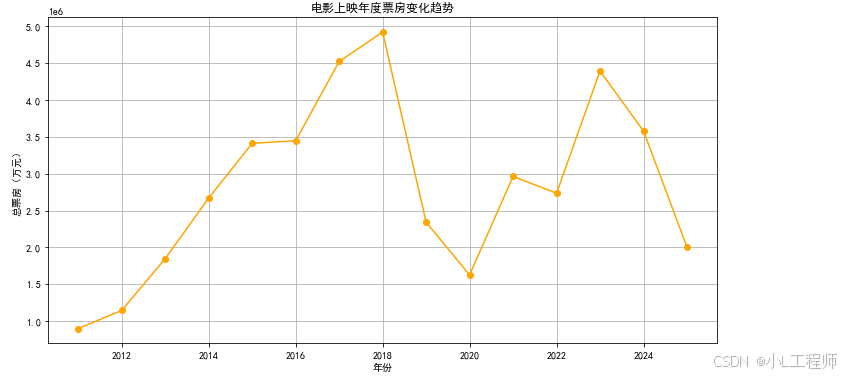
2. 各类场均人次分布直方图
-
意义:场均人次反映了观众对某类电影的观影热情。通过分析各类电影的场均人次分布,可以了解哪些类型的电影更受观众欢迎。
-
应用:电影制作公司可以根据这些数据调整电影的类型和内容,制作更符合观众口味的电影,从而提高票房和观影人次。
bins = [0, 20, 60, 100, df['场均人次'].max() + 1] # 最后一个区间为 100 以上
labels = ['20人以下', '20-60人', '60-100人', '100人以上']
# 将场均人次分配到区间
df['场均人次区间'] = pd.cut(df['场均人次'], bins=bins, labels=labels, right=False)
# 统计每个区间的电影数量
interval_counts = df['场均人次区间'].value_counts().sort_index()
plt.figure(figsize=(10, 6))
plt.bar(interval_counts.index, interval_counts.values, color='skyblue', edgecolor='black', width=1.0)
plt.xlabel('场均人次区间')
plt.ylabel('电影数量')
plt.title('场均人次分布直方图')
plt.xticks(rotation=0)
plt.show()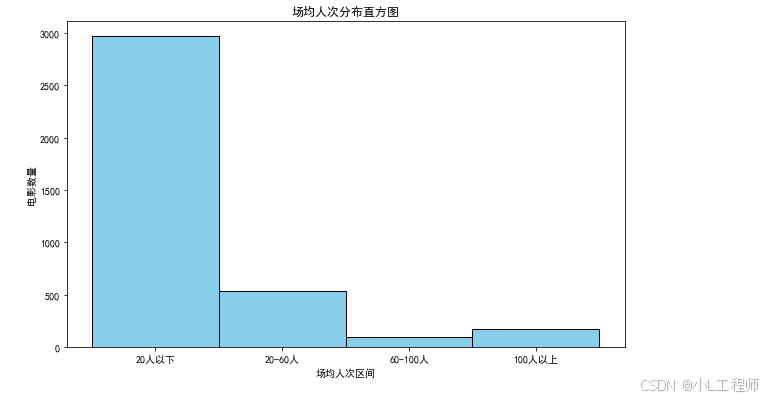
3. 各类平均票价占比分布
-
意义:平均票价反映了电影的市场定位和观众的消费能力。通过分析各类电影的平均票价占比,可以了解不同类型电影的定价策略。
-
应用:电影院可以根据这些数据调整票价策略,吸引更多观众。同时,电影制作公司也可以根据票价数据调整电影的制作成本,确保电影的市场竞争力。
bins = [0, 20, 40, df['平均票价'].max() + 1] # 最后一个区间为 40 以上
labels = ['20元以下', '20-40元', '40元以上']
df['票价区间'] = pd.cut(df['平均票价'], bins=bins, labels=labels, right=False)
price_counts = df['票价区间'].value_counts()
plt.figure(figsize=(8, 8))
plt.pie(
price_counts,
labels=price_counts.index,
autopct='%1.1f%%', # 显示百分比
startangle=140, # 起始角度
colors=['#66b3ff', '#99ff99', '#ffcc99'], # 自定义颜色
shadow=True, # 添加阴影
explode=(0.05, 0.05, 0.05) # 分离饼图区块
)
plt.title('各类平均票价占比分布', fontsize=16)
plt.show()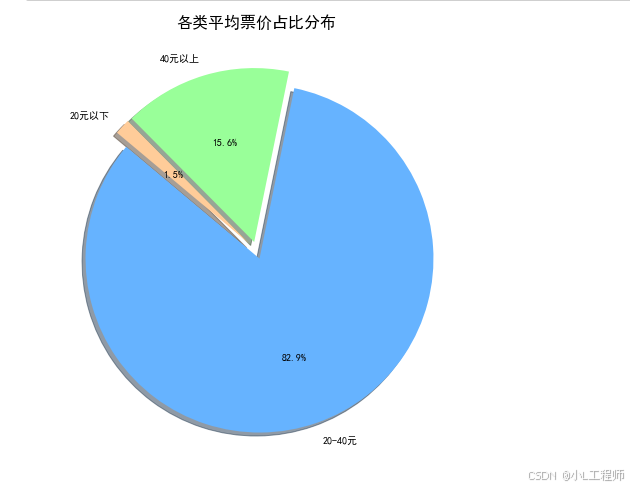
4. 2023-2025 年上映电影票价分布
-
意义:通过分析未来几年上映电影的票价分布,可以预测电影市场的票价趋势,了解票价是否会随着市场变化而波动。
-
应用:电影院和电影制作公司可以根据这些预测提前调整票价策略,确保在未来的市场竞争中占据有利位置。
df_filtered = df[(df['年份'] >= 2023) & (df['年份'] <= 2025)]
data = [df_filtered[df_filtered['年份'] == year]['平均票价'] for year in df_filtered['年份'].unique()]
plt.figure(figsize=(10, 6))
plt.boxplot(data, vert=True, patch_artist=True, boxprops=dict(facecolor='lightblue'), labels=df_filtered['年份'].unique())
plt.xlabel('平均票价')
plt.title('2023-2025 年电影票价分布(箱线图)')
plt.show()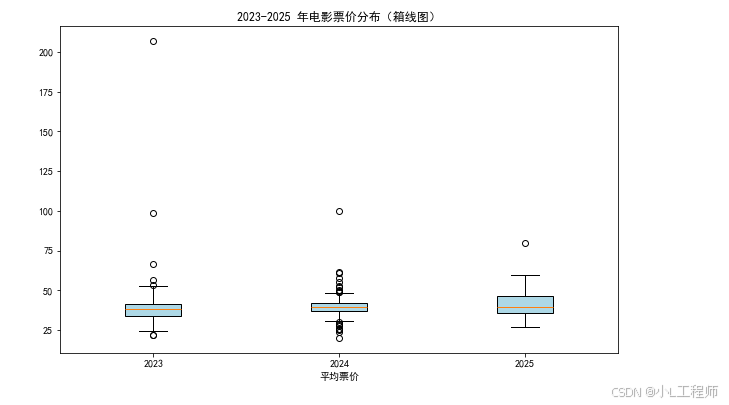
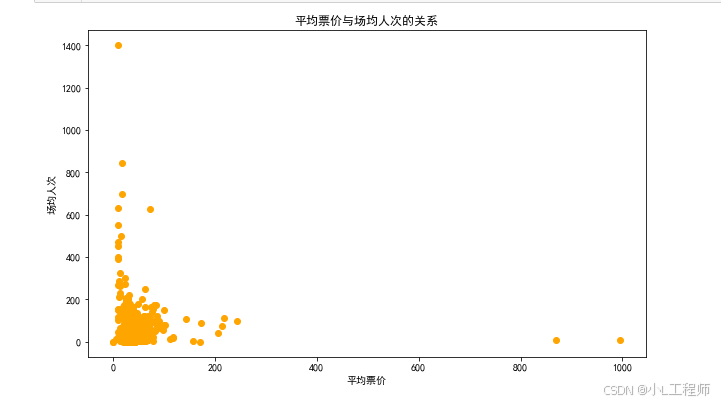
5. 平均票价与场均人次的关系
-
意义:通过分析平均票价与场均人次的关系,可以了解票价对观众观影行为的影响。例如,票价是否会影响观众的观影选择,是否存在票价过高导致观影人次下降的情况。
-
应用:电影院可以根据这些数据调整票价,确保票价既能保证收入,又不会影响观众的观影热情。电影制作公司也可以根据这些数据调整电影的制作成本,确保电影的市场竞争力。
plt.figure(figsize=(10, 6))
plt.scatter(df['平均票价'], df['场均人次'], color='orange')
plt.xlabel('平均票价')
plt.ylabel('场均人次')
plt.title('平均票价与场均人次的关系')
plt.show()