> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
在本文中,我们将介绍如何使用Python和Selenium库来自动化采集《英雄联盟》(League of Legends,简称LOL)中所有英雄的详细信息,并将这些信息保存到CSV文件中。本文的代码不仅适用于LOL,还可以作为其他类似网页数据采集任务的参考。
目标url : 英雄列表 - 英雄联盟手游官网 - 腾讯游戏
一. 概述
我们的目标是采集LOL官方网站上所有英雄的详细信息,包括英雄的姓名、称号、角色定位、角色分路、操作难易度以及皮肤信息。为了实现这一目标,我们将使用Selenium库来模拟浏览器操作,自动访问网页并提取所需数据。
二.采集前期准备
(一)技术栈
-
Python: 作为主要的编程语言。
-
Selenium: 用于自动化浏览器操作,模拟用户行为。
-
CSV: 用于存储采集到的数据。
(二)环境准备
在开始编码之前,需要确保已经安装了 Python 和以下必要的库:
-
Selenium:用于模拟浏览器操作。
-
Chrome WebDriver:与 Selenium 配合使用,控制 Chrome 浏览器。
可以通过以下命令安装 Selenium:
pip install selenium
三.采集流程分析
(一)想要获取每个英雄的具体数据,首先要采集每个英雄的具体详情页地址

定义了一个get_url函数,用于获取所有英雄的详情页链接:
def get_url():
bro.get('https://lolm.qq.com/v2/champions.html')
bro.implicitly_wait(10)
bro.maximize_window()
time.sleep(1)
'''页面下拉'''
drop_down()
time.sleep(1)
lis = bro.find_elements(By.CSS_SELECTOR, '.hero-list>li')
url_list = []
for li in lis:
url_hero = li.find_element(By.CSS_SELECTOR, 'a').get_attribute('href')
url_list.append(url_hero)
return url_list(二)通过采集的详情页地址列表,采集每个英雄的数据信息

在获取到所有英雄的链接后,我们需要遍历这些链接,进入每个英雄的详情页,采集所需的信息。我们定义了一个get_data函数来实现这一功能
(三)将采集的数据保存为csv
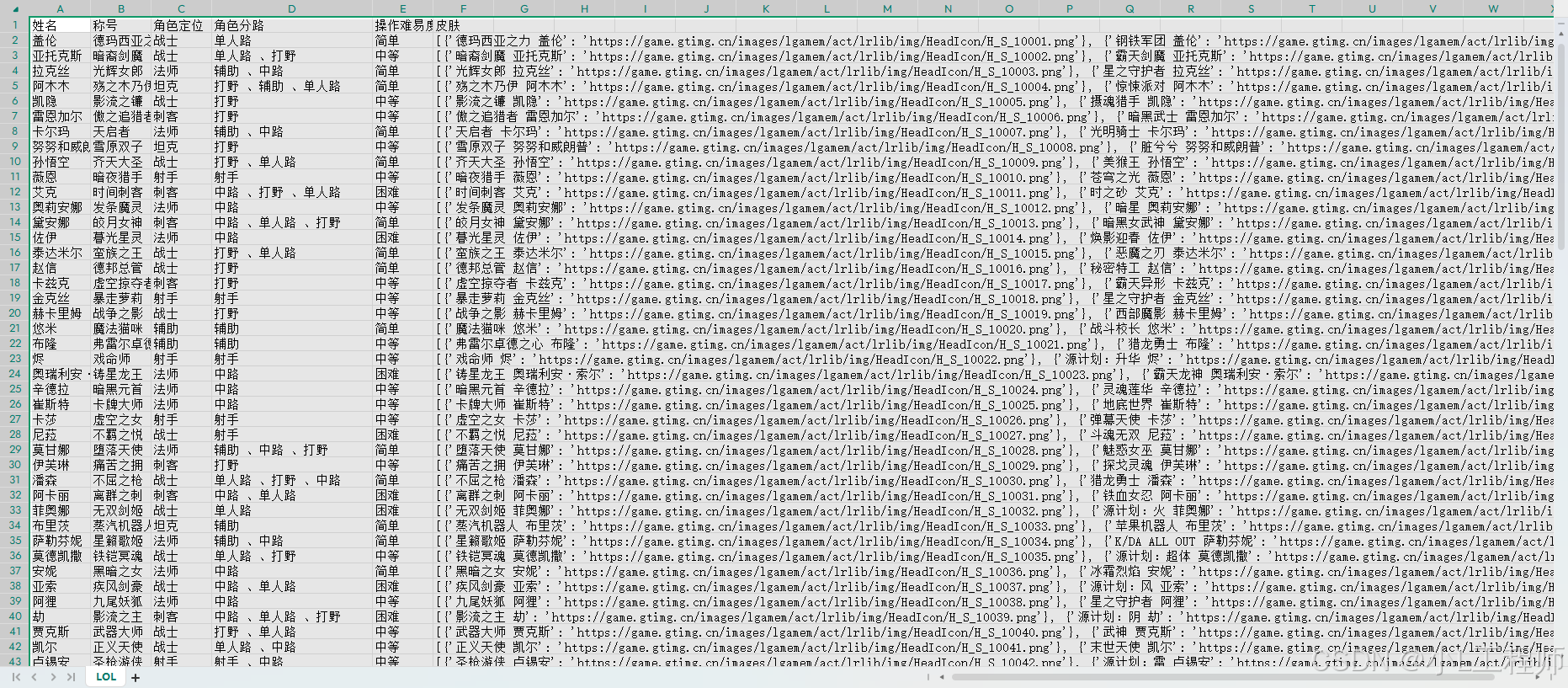
四.完整代码
(一)数据采集代码
<如果您对爬虫采集代码感兴趣(不白嫖),可以在评论区留言(主页 \/),我会根据需求提供指导和帮助>
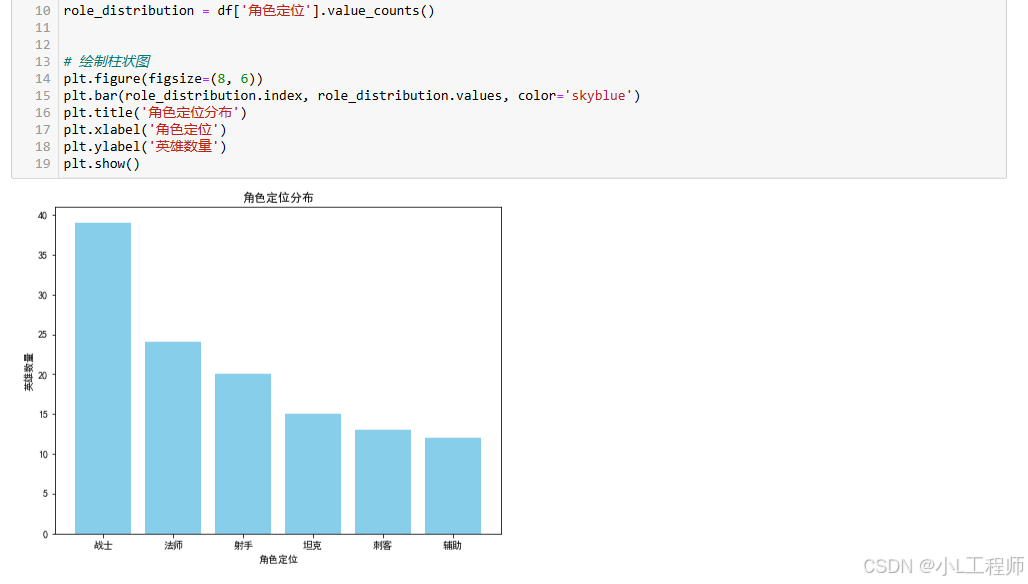
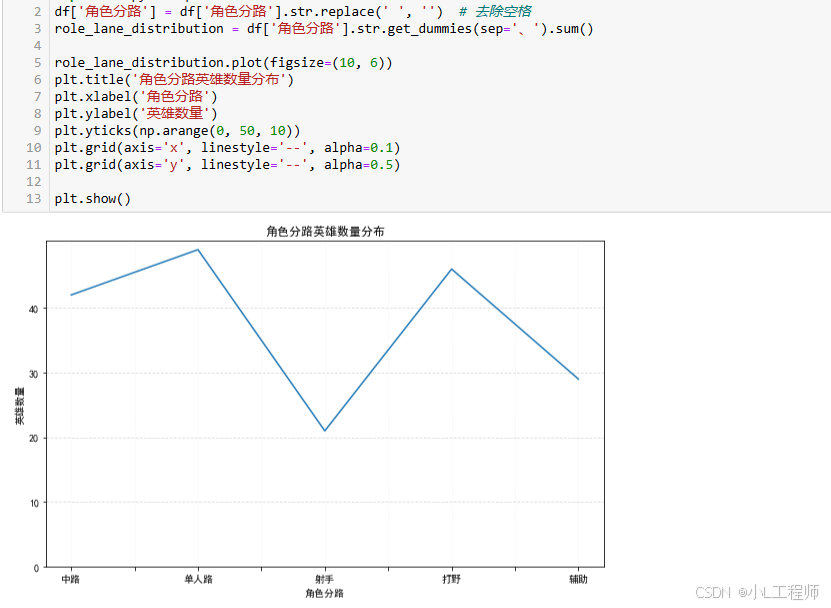
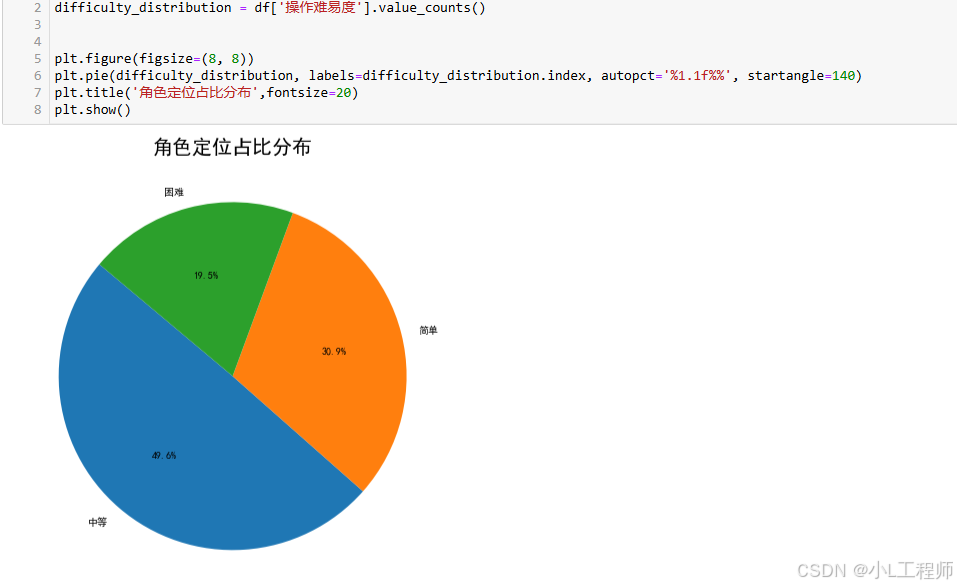
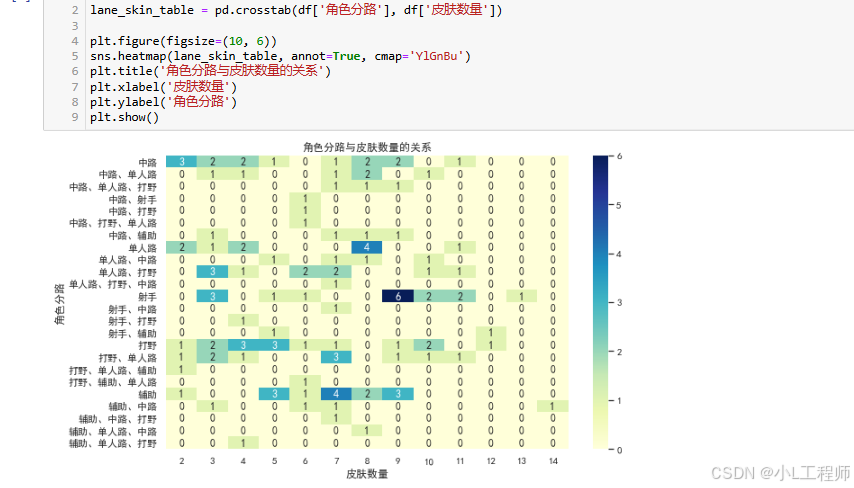
(二)可视化(附代码)