引言
2025年4月6日,Meta发布的Llama 4系列模型以原生多模态能力、混合专家(MoE)架构和超长上下文支持引发广泛关注。本文将从技术实现、性能对比、部署实践三大维度展开深度分析。
一、性能突破:参数效率与多模态优势
1. 基准测试表现
Llama 4在多项任务中展现显著优势:
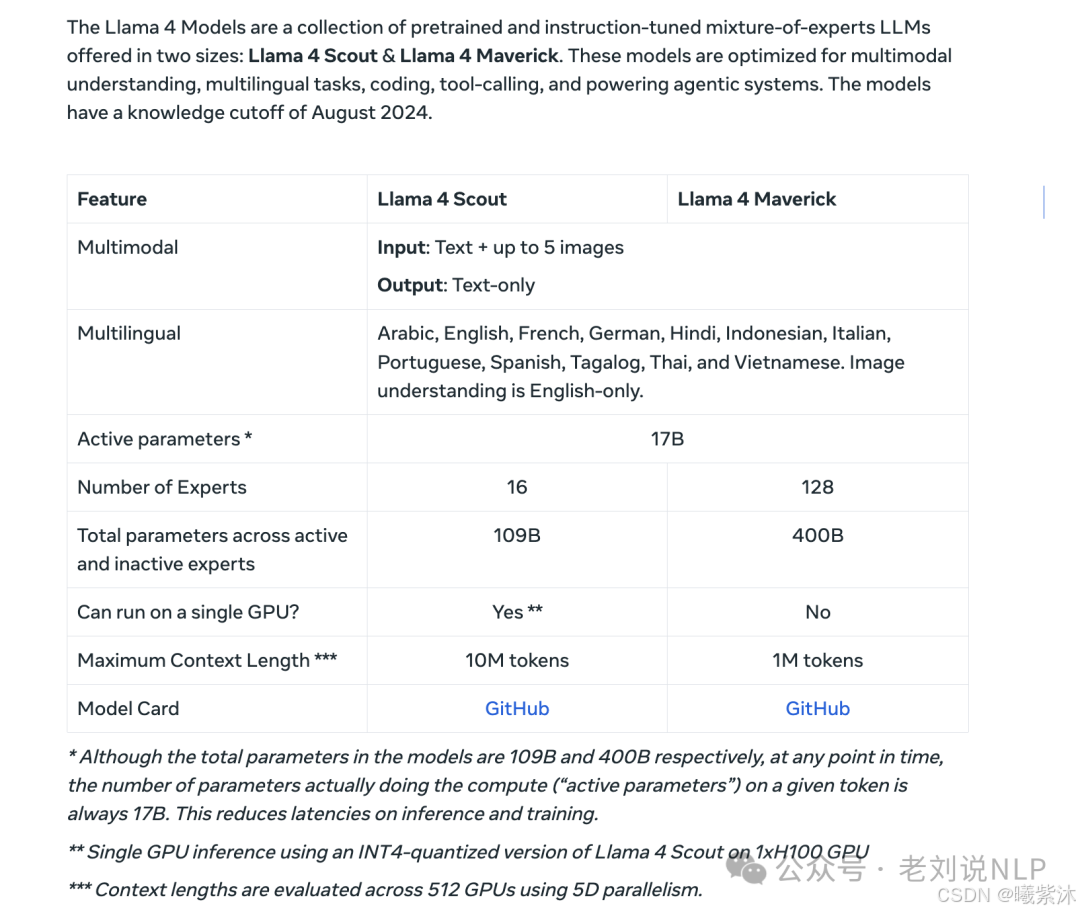
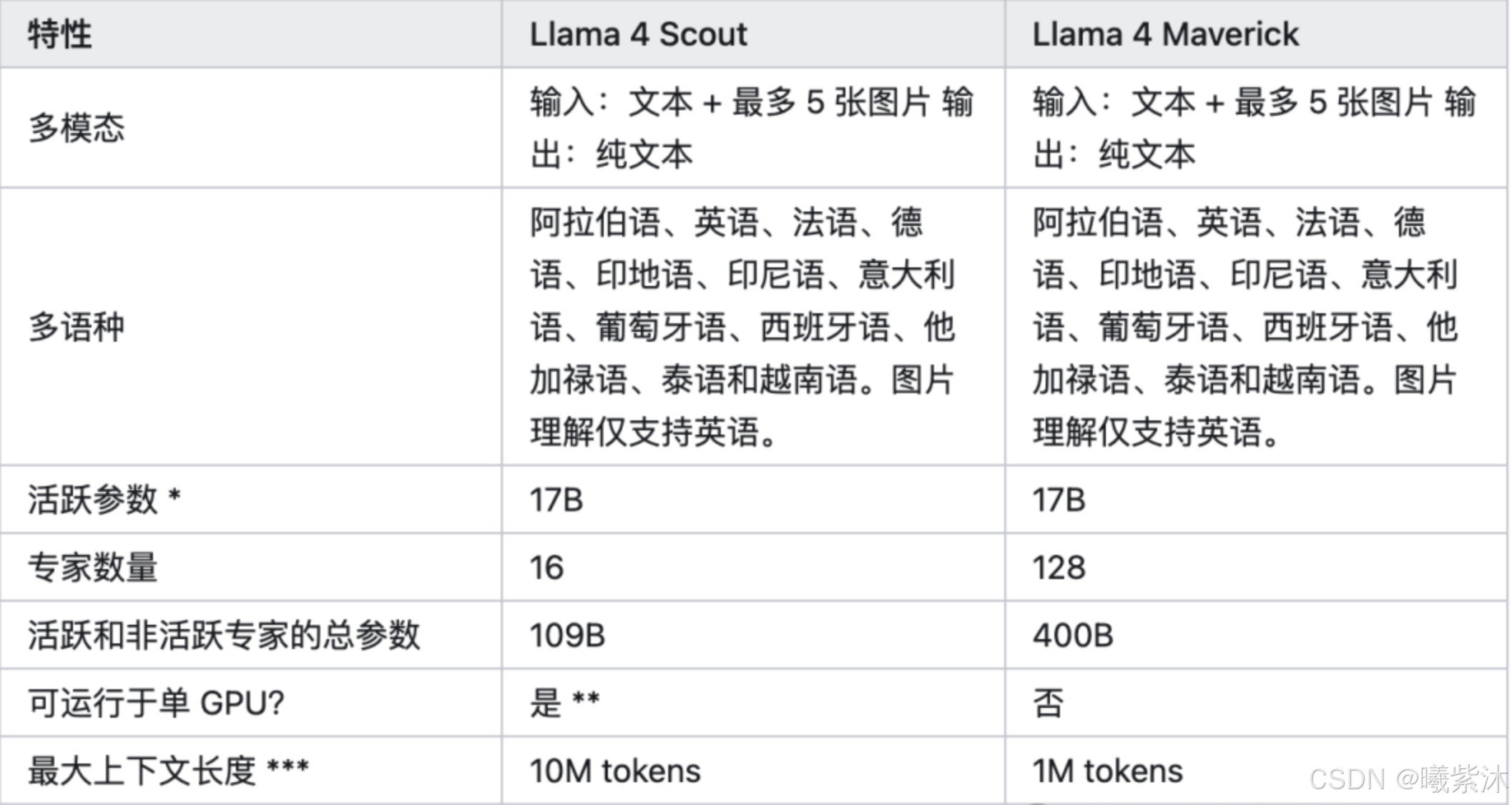
- 推理与编码:仅需170亿活跃参数即超越DeepSeek v3(需340亿参数),参数效率提升100%。
- 多模态能力:图像理解任务中,Llama 4 Scout以17B参数超越GPT-4o和Gemini 2.0 Flash,支持图文检索、视觉问答(VQA)等场景。
- 长上下文支持:最大支持1000万token上下文,单H100 GPU即可运行,显存占用优化较Llama 3降低40%。
2. 模型规模与效率
- Behemoth版本:总参数量达2万亿,活跃参数2880亿,适用于复杂数学计算和多语言处理。
- MoE架构优势:例如Llama 4 Maverick的4000亿总参数中,仅激活170亿参数/次推理,计算成本降低60%。
二、核心架构创新
1. iRoPE:无位置嵌入的注意力机制
Llama 4通过**交错注意力层(Interleaved Attention Layers)**实现长度泛化:
- 动态温度缩放:推理时根据上下文长度调整注意力权重分布,长文本任务准确率提升15%。
- 结构简化:移除传统位置编码,模型参数减少5%,推理速度提升20%。
2. 混合专家(MoE)架构升级
- 专家网络设计:Llama 4 Scout采用16个专家网络,门控机制动态选择2-3个专家参与计算,平衡性能与效率。
- 训练策略:通过**课程学习(Curriculum Learning)**逐步增加专家网络复杂度,训练稳定性提升30%。
3. 多模态原生支持
- 早期融合(Early Fusion):文本和视觉token通过统一Transformer层处理,无需额外适配模块。
- 跨模态任务示例:
该代码片段展示如何通过Hugging Face API实现图文联合推理。from transformers import Llama4ForMultiModal model = Llama4ForMultiModal.from_pretrained("meta-llama/Llama-4-Scout") outputs = model( text="描述图片中的场景", image=image_tensor, max_new_tokens=256 )
三、开源生态与部署实践
1. 模型版本与硬件适配
| 模型版本 | 活跃参数 | 专家数量 | 推荐硬件 | 适用场景 |
|---|---|---|---|---|
| Llama 4 Scout | 17B | 16 | 单H100 GPU | 多模态推理、移动端部署 |
| Llama 4 Maverick | 170B | 32 | 2xA100 GPU | 复杂代码生成、长文本处理 |
| Llama 4 Behemoth | 2880B | 64 | 8xH100 GPU集群 | 科学计算、多语言翻译 |
2. 部署优化技巧
- 显存优化:使用DeepSpeed ZeRO-3可将Behemoth版本显存占用从800GB降至200GB。
- 推理加速:通过ONNX Runtime量化工具,Scout版本推理速度提升2倍(FP16→INT8)。
四、对比分析与行业影响
1. 与竞品对比
| 特性 | Llama 4 Scout | DeepSeek v3 | GPT-4o |
|---|---|---|---|
| 多模态支持 | 原生支持 | 需适配器 | 需额外接口 |
| 最大上下文长度 | 10M token | 32k token | 128k token |
| 推理成本(1B token) | $120(单H100) | $280(双A100) | $800(API调用) |
2. 行业影响
- 开源生态:Llama 4推动多模态模型平民化,单GPU即可运行17B版本。
- 研究价值:iRoPE架构为长序列建模提供新思路,已应用于生物序列分析等交叉领域。
总结
Llama 4通过原生多模态融合、MoE参数效率优化和超长上下文支持,重新定义了开源大模型的技术边界。其在推理任务中以1/2参数量超越竞品的表现,标志着AI模型轻量化与跨模态融合的新里程碑。开发者可通过Hugging Face等平台快速部署,探索其在医疗诊断、金融建模等领域的应用潜力。