目录
Receipt数据结构
ETH-以太坊概述
以太坊设计mining puzzle,对内存要求很高。
用proof of stake代替proof of work
智能合约(smart contract)
比特币是一种去中心化的货币
以太坊的出现,一个特性就是增加了去中心化的合约的支持
去中心化的货币:货币本来是由政府发行,价值由政府来定义来维护货币体系的正常运行;比特币的出现用技术手段把政府的这些职能给取代了。
去中心化的合约:现实中也是由政府来维持使用的;如果合同中的内容可以通过程序代码来实现,那么可以把这个代码放到区块链中,通过区块链的不可篡改性,来保证代码的正确运行。(但不是所有的合同都可以用编程语言来实现)
去中心化的货币好处:例如跨国转账很方便
去中心化的合约好处:这个代码一旦发布到区块链上,区块链的不可篡改性,谁也改不了这个代码包括作者,这样就能保证大家只能按照这个代码中制定的规则来执行。
ETH-账户
比特币中转钱的时候需要说明钱的来源
比特币每次交易换一个新地址
以太坊采用基于账户的模型(跟现实中银行很相似)
比特币面临的一个主要挑战就是double spending attack
而以太坊对他有天然的防御作用:因为不用管币的来源,每花一次就直接扣掉。
replay attack重放攻击:交易者把这个交易重放一遍,让交易的账户被扣两次钱
externally owned account:balance nonce
smart contract account:nonce code storage
为什么要设立这样一种新的模型?
比特币基于交易的隐私保护比较好一些,但以太坊要支持的是智能合约,合约要求参与者有比较稳定的身份。
ETH-状态树
在以太坊中,有三棵树的说法,分别是状态树、收据树和交易树。
以太坊采用基于账户的模式,系统中显式记录每个账户的余额。而以太坊这样一个大型分布式系统中,是采用的什么样的数据结构来实现对这些数据的管理的。
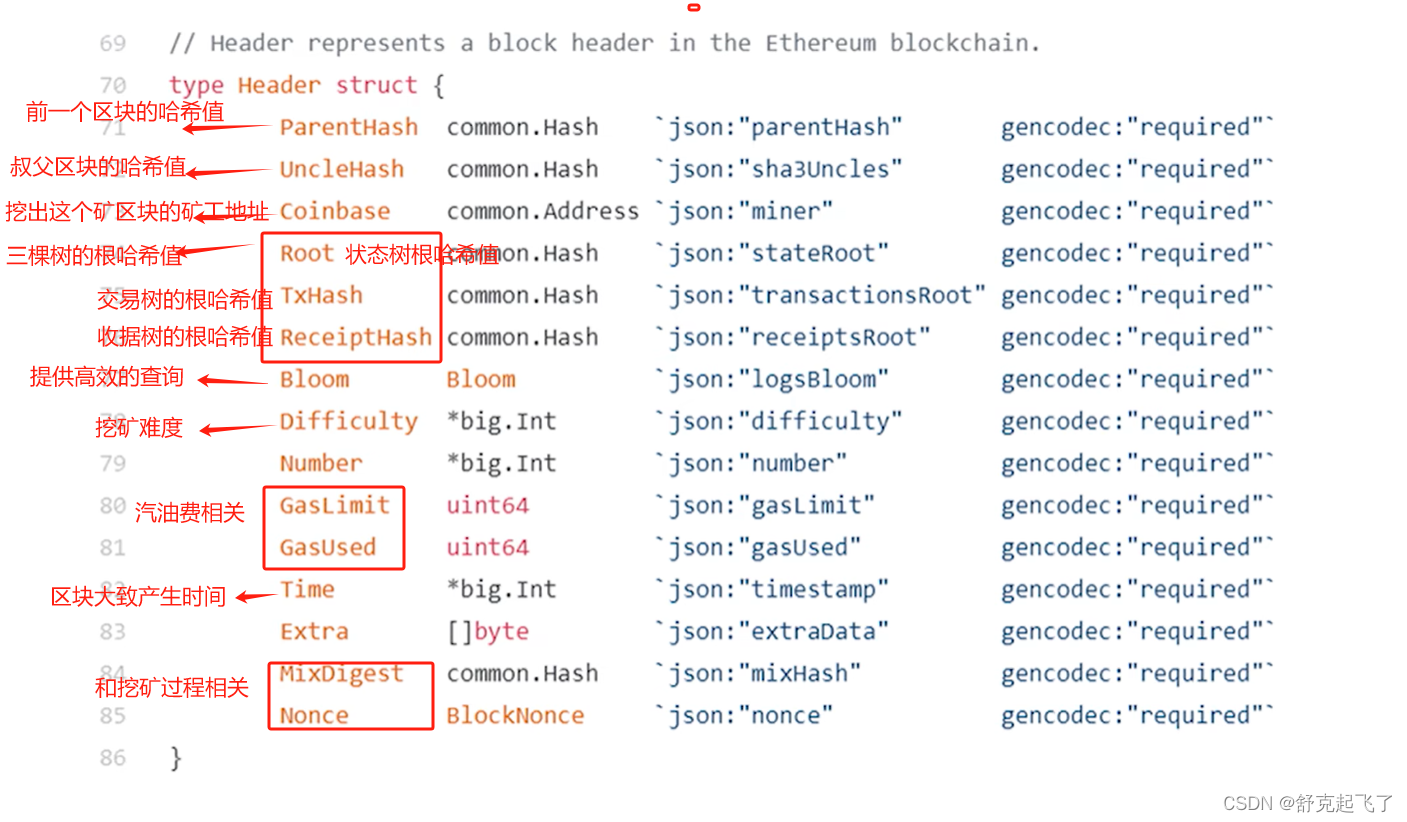
在以太坊中,账户地址为160字节,表示为40个16进制数额。状态包含了余额(balance)、交易次数(nonce),合约账户中还包含了code(代码)、存储(stroge)。
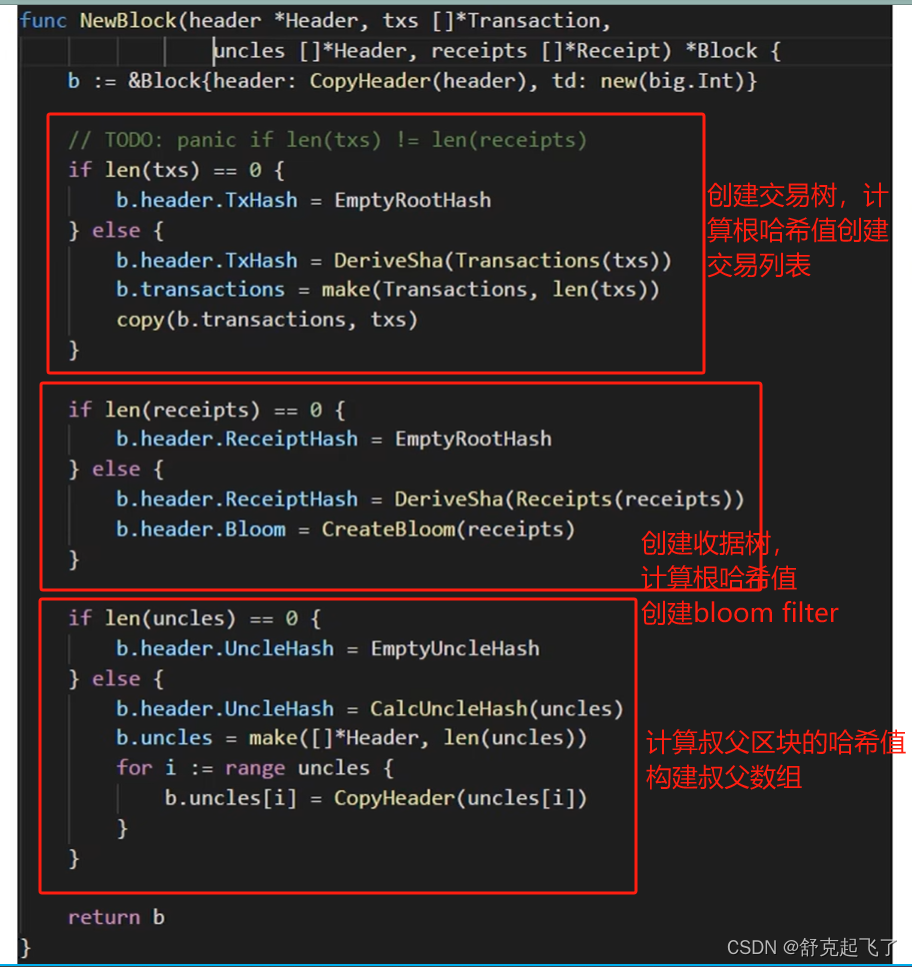
在BTC和以太坊中,交易保存在区块内部,一个区块可以包含多个交易。通过区块构成区块链,而非交易。
实际中以太坊采取的数据结构:MPT
BTC系统中,虽然每个节点构建的Merkle Tree不一致(不排序),但最终是获得记账权的节点的Merkle Tree才是有效的。
实际上,在以太坊种使用的并非简单的PT(Patricia tree),而是MPT(Merkle Patricia tree)。
Merkle Tree 和 Binary Tree:
区块链和链表的区别在于区块链使用哈希指针,链表使用普通指针。
同样,Merkle Tree 相比 Binary Tree,也是普通指针换成了哈希指针。
所以,以太坊系统中可如此,将所有账户组织为一个经过路径压缩和排序的Merkle Tree,其根哈希值存储于block header中。BTC系统中只有一个交易组成的Merkle Tree,而以太坊中有三个(三棵树)。也就是说,在以太坊的block header中,存在有三个根哈希值。
根哈希值的用处:
防止篡改。
提供Merkle proof,可以证明账户余额,轻节点可以进行验证。
证明某个发生了交易的账户是否存在
MPT(Modified Patricia tree)
以太坊中针对MPT(Merkle Patricia tree)进行了修改,我们称其为MPT(Modified Patricia tree)
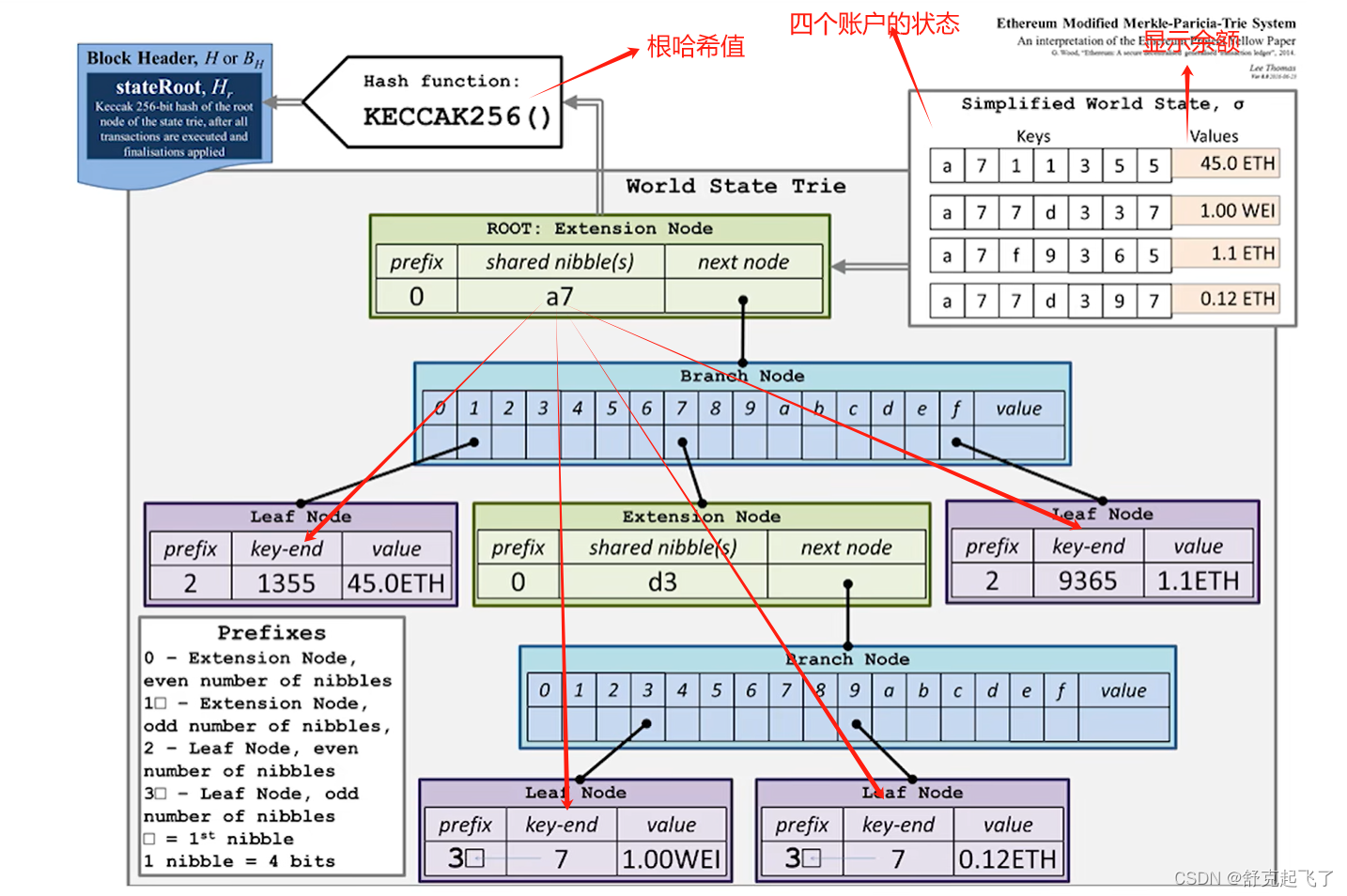
以太坊中使用的MPT结构示意图
每次发布新区块,状态树中部分节点状态会改变。但改变并非在原地修改,而是新建一些分支,保留原本状态。如下图中,仅仅有新发生改变的节点才需要修改,其他未修改节点直接指向前一个区块中的对应节点。
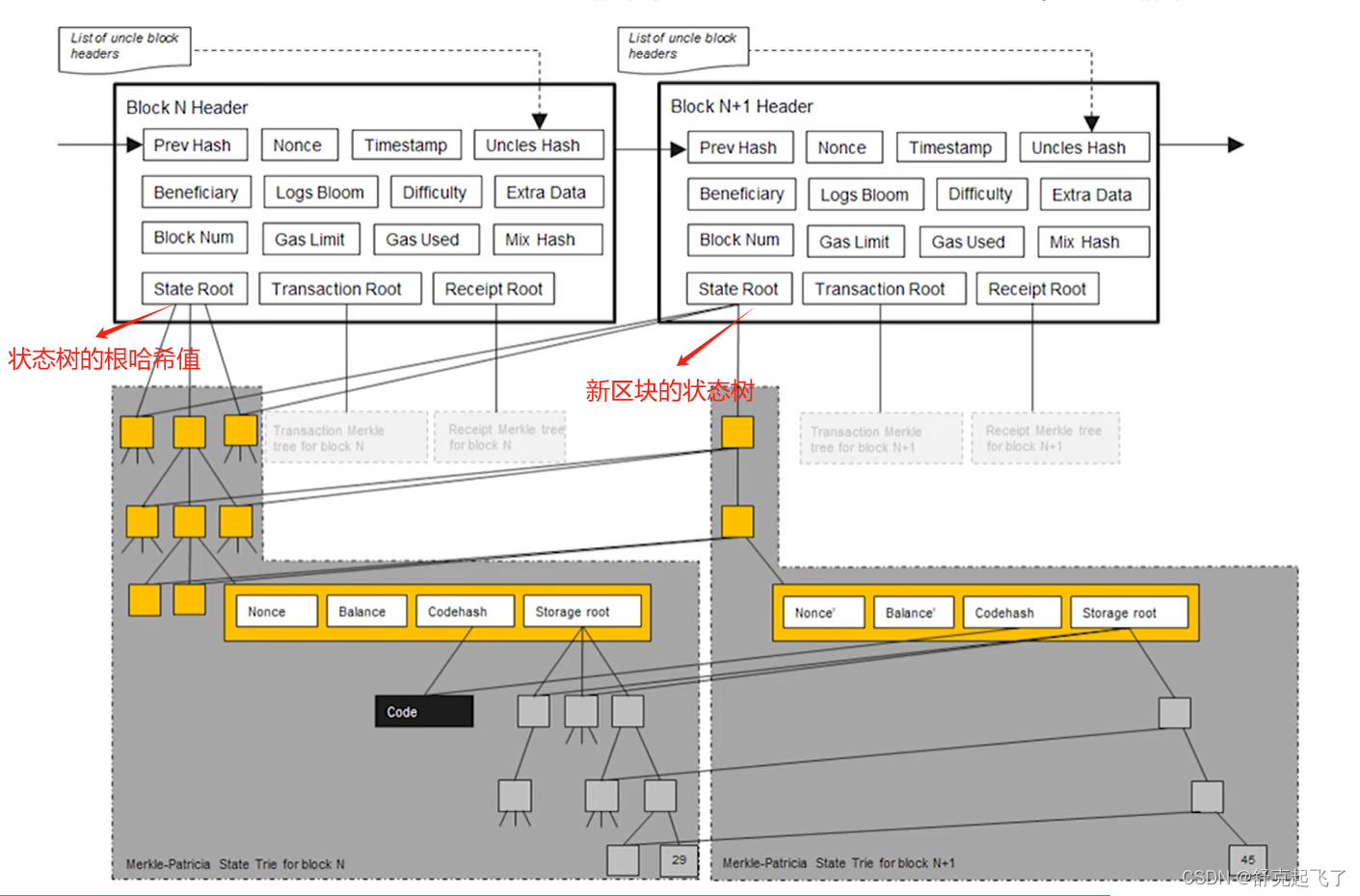
虽然每个区块都有一个状态树,但是这两棵树大部分节点都是共享的。
所以系统中每个全节点需要维护的不是一棵MPT,而是每次出现一个区块都要新建一个MPT,只不过这些状态树中大部分节点都是共享的,只有少数发生变化的节点需要新建分支。
状态树保存的是key,value
value要通过一个序列化的过程(RLP:Recursive Length Prefix)编码之后再进行存储。
ETH-交易树和收据树
交易树和收据树的用途:
向轻节点提供Merkle Proof。
更加复杂的查找操作(例如:查找过去十天的交易;过去十天的众筹事件等)
Bloom filter(布隆过滤器)
支持较为高效查找某个元素是否在某个集合中
最笨:元素遍历,复杂度为O(n)——轻节点不能用
方法:给一个大的集合,计算出一个紧凑的“摘要”,
Bloom filter特点:有可能出现误报,但是不会出现漏报。
Bloom filter变种:采用一组哈希函数进行向量映射,有效避免哈希碰撞
作用
每个交易完成后会产生一个收据,收据包含一个Bloom filter记录交易类型、地址等信息。在区块block header中也包含一个Bloom filter,其为该区块中所有交易的Bloom filter的一个并集。
所以,查找时候先查找块头中的Bloom filter,如果块头中包含。再查看区块中包含的交易的Bloom filter,如果存在,再查看交易进行确认;如果不存在,则说明发生了“碰撞”。
好处是通过Bloom filter这样一个结构,能够快速过滤掉大量无关区块,从而提高了查找效率。
A转账到B,有没有可能收款账户之前没有听说过?
可能。因为以太坊中账户可以节点自己产生,只有在产生交易时才会被系统知道。
可否将每个区块中状态树更改为只包含和区块中交易相关的账户状态?(大幅削减状态树大小,且和交易树、收据树保持一致)
不能。首先,这样设计要查找账户状态很不方便,因为不存在某个区块包含所有状态。其次,如果要向一个新创建账户转账,因为需要知道收款账户的状态,才能给其添加金额,但由于其是新创建的账户,所有需要一直找到创世纪块才能知道该账户为新建账户,系统中并未存储,而区块链是不断延长的。
ETH-GHOST
最开始
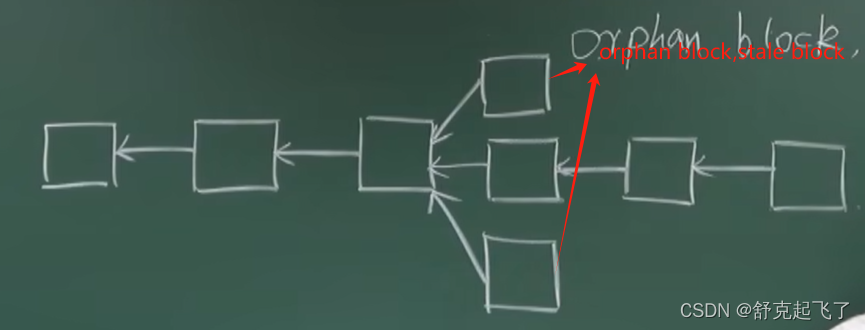
挖到那个区块的矿工在那个区块里面有一个铸币交易,能得到一定数量的比特币,但是随着时间推移有一条链成为最长合法链,因此其他区块也将作废。但为了补偿这些区块所属矿工所作的工作,给这些区块一些“补偿”,并称其为"Uncle Block(叔父区块)"
规定长链最后的区块在发布时可以将前面的其他短链叔父区块包含进来,其他短链的叔父区块可以得到出块奖励的7/8,而为了激励长链包含叔父区块,规定长链每包含一个叔父区块可以额外得到1/32的出块奖励。为了防止长链大量包含叔父区块,规定一个区块只能最多包含两个叔父区块,因此长链在其他短链中最多只能包含两个区块作为自己的出块奖励
缺点:
因为叔父区块最多只能包含两个,如图出现3个怎么办?
矿工自私,故意不包含叔父区块,导致叔父区块7/8出块奖励没了,而自己仅仅损失1/32。如果甲、乙两个大型矿池存在竞争关系,那么他们可以采用故意不包含对方的叔父区块,因为这样对自己损失小而对对方损失大。
新版本
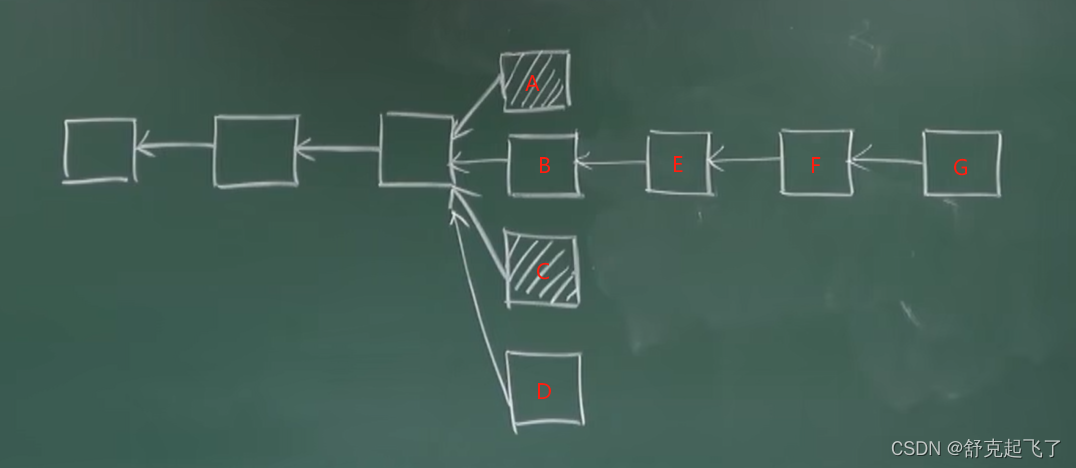
F为E后面一个新的区块。因为规定E最多只能包含两个叔父区块,所以假定E包含了C和D。此时,F也可以将A认为自己的的叔父区块(实际上并非叔父辈的,而是爷爷辈的)。如果继续往下挖,F后的新区块仍然可以包含B同辈的区块(假定E、F未包含完)。这样,就有效地解决了上面提到的最初Ghost协议版本存在的缺陷。
但是“叔父”这一定义隔多少代才好呢?
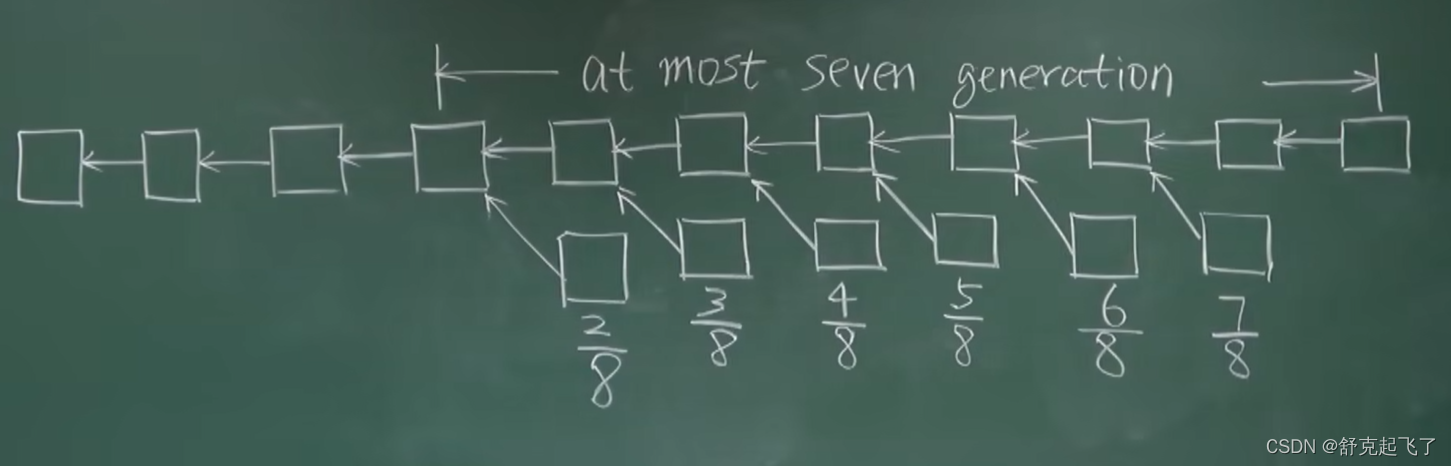
M为该区块链上一个区块,F为其严格意义上的叔父,E为其严格意义上的“爷爷辈”。以太坊中规定,如果M包含F辈区块,则F获得7/8出块奖励;如果M包含E辈区块,则F获得6/8出块奖励,以此类推向前。直到包含A辈区块,A获得2/8出块奖励,再往前的“叔父区块”,对于M来说就不再认可其为M的"叔父"了。超过七代就不认了。
对于M来说,无论包含哪个辈分的“叔父”,得到的出块奖励都是1/32出块奖励。
奖励
BTC发布一个区块其实有两奖励:静态奖励(出块奖励)+动态奖励(交易费,占据比例很小)
ETH:静态奖励(出块奖励+包含叔父区块的奖励)+动态奖励(汽油费,占据比例很小,叔父区块没有)
BTC中为了人为制造稀缺性,比特币每隔一段时间出块奖励会降低,最终当出块奖励趋于0后会主要依赖于交易费运作。而以太坊中并没有人为规定每隔一段时间降低出块奖励。
对于分叉后的堂哥区块怎么办?A->F该链并非一个最长合法链,所以B->F这些区块怎么办?该给挖矿补偿吗?
ETH系统中规定,只认可A区块为叔父区块,给予其补偿,而其后的区块全部作废。
ETH实时数据
Etherscan网站,该网站可以实时观看以太坊的数据。
ETH-挖矿算法
Block chain is secured by mining.
对于基于工作量证明的系统来说,挖矿是保障区块链安全的一个重要手段。
比特币的挖矿算法总的来说比较成功,没有发现什么大的漏洞。但是也有值得改进的地方,就是挖矿设备的专业化,只能用专门的设备来挖矿,这种做法和去中心化和设计初衷是相违背的。
Bug bounty
有的公司悬赏来找软件中的漏洞,如果可以找到就会得到一笔赏金。
比特币的挖矿算法是一个天然的Bug bounty,如果能发现里面的漏洞或有挖矿的捷径,就可以得到赏金。
memory hard mining puzzle
一个常用的做法就是增加puzzle对内存访问的需求。ASIC在内存访问方面性能不强。
莱特币伪随机数的好处:如果数组足够大,会增加求解puzzle的难度,提高挖矿难度。
Time-memory tradeoff
只保存内存区数组内奇数位的伪随机数,要用到偶数位的就根据另一半计算得到,计算复杂度高一些,内存减少一半。这个设计不像比特币主要进行哈希运算,是在运算过程中增加对内存访问的需求,对矿工来说是mining hard,缺点是对轻节点是mining hard,轻节点验证难度和挖矿难度差不多一样。
设计puzzle的原则:difficult to solve,but easy to verify。
任何一个加密货币都存在冷启动问题,包括比特币。
对于基于工作量证明的加密货币来说,挖矿人数越少,越不安全,发动恶意攻击的难度越低。
以太坊的mining puzzle设计和莱特币大不相同。以太坊有一大一小两个数据集,小的是16M cache,大的是1G dataset——DAG,大的是从小的中生成出来的,设计原因是便于验证,挖矿矿工保存大的,轻节点保存小的。
基本思想:
小的数据集是生成一个种子节点,经过运算数组第一个元素,依次取哈希,第一个元素取哈希得到第二个元素,依次类推,填充完伪随机数的数组,得到一个cache;莱特币是直接从数组中按照伪随机数顺序读取一些数进行运算。以太坊还要生成一个大数组,两个数组都要定期增长。大的数组的元素都是从小数组按照伪随机顺序读取一些元素,和莱特币类似,一共读256次,最后得到一个哈希放在大数据集中的第一个元素。读取大数组中元素是每次读取两个相邻的元素,循环64次,大数组有128个数,最后算出一个哈希值和目标预值比较,是否符合难度要求,不是就把块头的nonce,重复过程,通过哈希值计算得到结果。
代码部分没有放上来
ETH-难度调整
每个区块都有可能调整
难度调整公式:
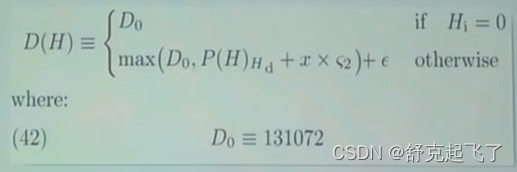
H指当前这个区块;
Hi是这个区块的序号;
D(H)是这个区块的难度;
max是第一部分基础部分,是为了维持出块时间在15秒左右;最后跟的那个是难度炸弹;
所谓的父区块,就是当前区块链的最后一个区块。D0是基础部分的下限,不管你怎么调整最小不能低于这个。

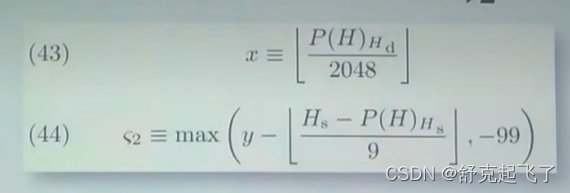
x是调整的密度,是父区块的难度除以2048;
下面那个取值跟两个因素有关,一个是出块的时间,另外一个是有没有叔父区块;
-99是指难度调整系数部分有一个下限。
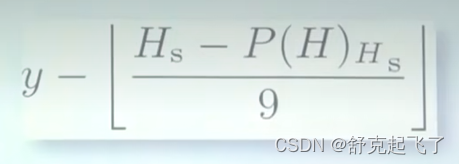
y取决于有没有叔父区块,有的话是2,没有的话是1;不论哪种情况它都是一个常数;
Hs是当前区块的时间戳;
P(H)Hs是父区块的时间戳;单位都是秒,两相减就是出块间隔,向下取整

难度炸弹

以太坊设想是通过埋设难度炸弹迫使矿工届时愿意转入权益证明,在实际应用中,权益证明的方式仍然并不成熟,目前以太坊共识机制仍然是POW,依然需要矿工参与挖矿维护以太坊系统的稳定。也就是说,转入POS的时间节点被一再推迟,虽然挖矿变得越来越难,系统出块时间开始逐渐变长,但矿工仍然需要继续挖矿。
在上面难度炸弹的公式中,有人应该注意到了第二项中的fake block number,该数仅仅为对当前区块编号减去了三百万,也就是相当于将区块编号回退了三百万个。那么,在前三百万个区块的时候,这个fake block number就是负数吗?
答案是否定的。实际上,在以太坊最初的设计中,并没有第二个公式。也就是说,最初就是简单地直接用区块编号除以100000。而在转入权益证明时间节点一再推迟后,以太坊系统采取了将区块编号回退三百万个区块的方法来降低挖矿难度,当然,为了保持公平,也将出块奖励从5个以太币减少到了3个以太币,这也是fake block number这一项出现的原因。
具体代码

为什么不减300万而是2999999?
它这里判断的是父区块的序号,当前正在挖,所以按照父区块来算的话就会少一个。
ETH-权益证明
比特币和 以太坊目前都是使用基于工作量的证明,这种共识机制受到一个普遍的批评——浪费电。
比特币能耗随时间变化情况
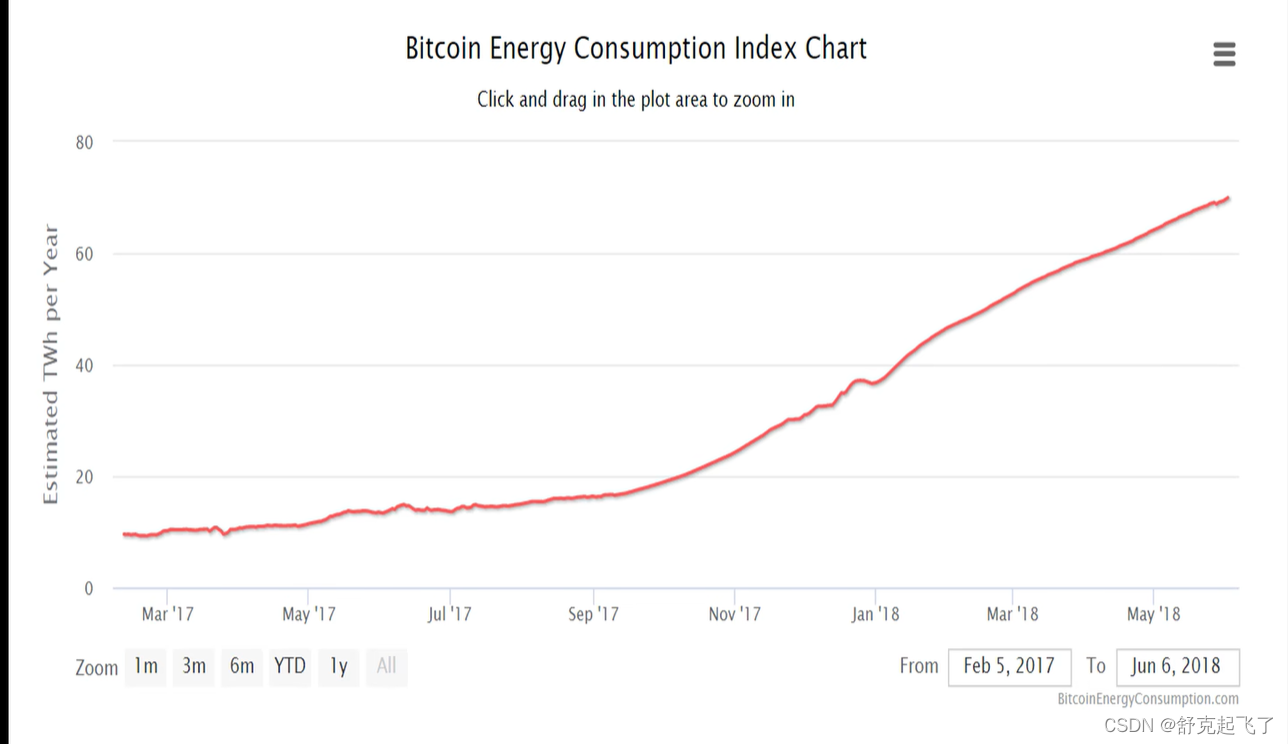
一个交易要花一千度电。
以太坊能耗比比特币低的原因:比特币出块时间长,以太坊出块时间短,平均下来能耗低。
挖矿过程中的这些能耗是不是必须的?
矿工为了取得出块奖励而挖矿,为了激励矿工参与维护系统而有出块奖励。
挖矿的收益实际上是靠投入的资金决定的。
权益证明(virtual mining)
采用权益证明的加密货币会在发行之前预留一部分货币给开发者,也会出售一部分货币来获得发行的资金。
和工作量证明相比,权益证明的优点:
1、省去了挖矿的过程,避免了对能耗和环境的影响,减少了温室气体的排放
2、基于工作量证明的系统维护系统的安全不是一个闭环,挖矿设备不是在系统的生态圈中,是外部的资源,可以转化为挖矿的算力,转化成对挖矿攻击的能力。
采用权益证明,假设如果要发动51%攻击,需要有占比51%以上的币种,才能发动。这些币种是系统内部的,是一个闭环,外部的资源不会对系统安全造成直接影响。
权益证明遇到的挑战
两边下注问题 nothing at stake
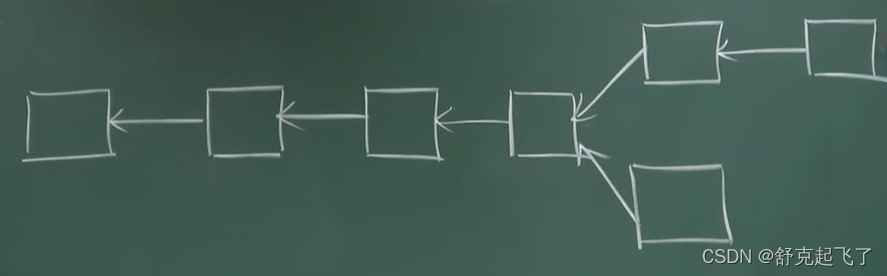
在一条链上,出现分叉,上面那个链暂时是最长合法链,权益证明的情况下,可以对两条链同时下注,锁定的币不会影响其他链的使用。
以太坊中准备采用的协议证明是Casper the Friendly Finality Gadget(FFG),在过渡阶段要和工作量证明混合使用,为工作量证明提供Finality, Finality是最终状态,包含在Finality的交易不会被取消。
Casper协议引入验证者(validator)
要想成为validator,需要投入一定数量的以太币作为保证金,保证金会被系统锁定住。 Validator的作用是推动系统达成共识,投票决定哪条链是最长合法链,投票权重取决于投入保证金数目大小。
具体做法:挖矿时每挖出一个区块就作为一个epoch,决定是否能成为Finality要进行投票,两轮投票(two-phase commit),第一轮投票是prepare message,第二轮投票是commit message, Caspe协议规定每一轮投票都要得到2/3验证者才能通过,按照保证金实际大小来算。
实际系统中,不区分两个message,把epoch从原来100个区块减少到50个区块,每个epoch只用一轮投票就行,这轮投票对于上一个epoch是commit message,对于下一个epoch是prepare message,要连续两轮投票都得到2/3的票数才算有效。
原始版本:

优化之后:
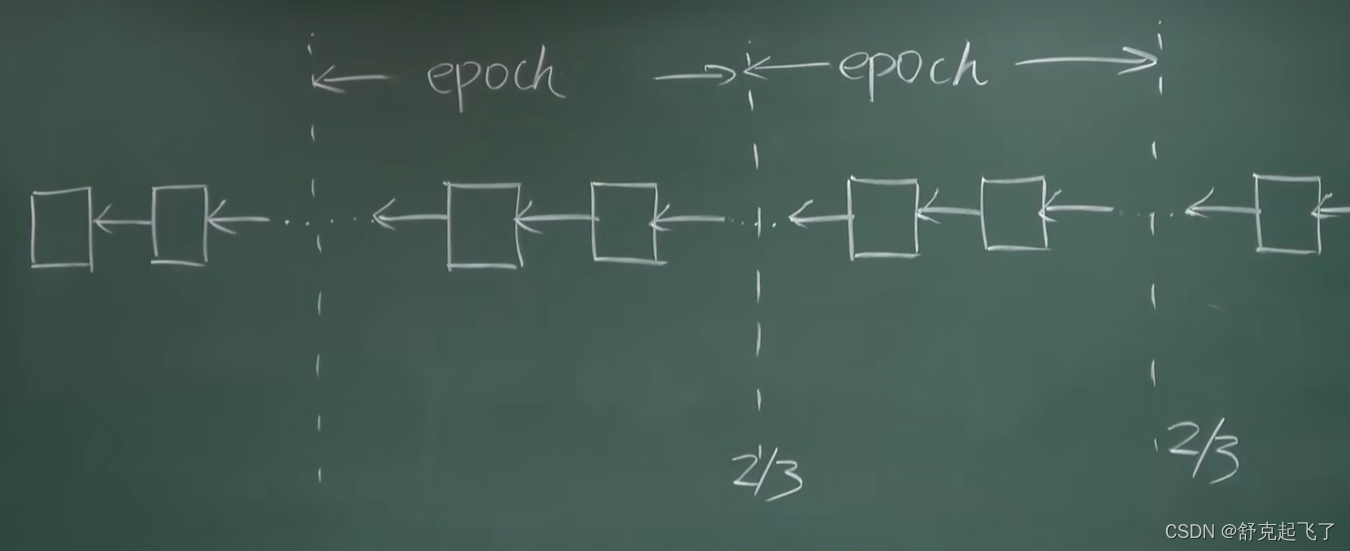
验证者参与这个过程的好处:
如果验证者履行职责,可以得到相应的奖励,如果有不良行为被发现,要受到相应的惩罚,如扣除保证金、没收全部保证金(销毁)。
验证者有一定任期,任期满了要经过一段时间的等待期,等待期是为了其他节点可以检举揭发。如果等待期过了没有问题,验证者可以取回保证金和应得奖励
通过验证者投票达成的Finality有没有可能被推翻?
单纯矿工发动攻击不会推翻Finality。大量的验证者给前后两个有冲突的Finality投票了,如果出现这种情况,至少有1/3的验证者给两边都投票了,一旦发现,这些验证者的保证金会被没收。
为什么以太坊不一开始就用 权益证明?
因为权益证明不是很成熟,工作量证明比较成熟,经过时间检验。比特币和以太坊的算法都经过了bug bounty的检验,没有人发现什么漏洞。EOS加密货币用权益证明的思想,用DPOS协议,先用投票方法选出21个投票节点,然后再由超级节点产生区块。基于权益证明的共识机制目前处于探索状态。
ETH-智能合约
智能合约:运行在区块链系统上的一段代码,代码逻辑定义了合约内容。
智能合约的账户保存了合约当前的运行状态:
- balance:当前余额
- nonce:交易次数
- code:合约代码
- storage:存储,数据结构为一棵MPT
智能合约编写代码为Solidity
bid()函数 是用来进行竞拍出价的,调用这个bid()函数需要把你拍卖的要出的价钱锁到合约里面。withdraw()函数就是把存到合约里的钱取出来。
外部账户如何调用智能合约?
创建一个交易,接收地址为要调用的那个智能合约的地址,data域填写要调用的函数及其参数的编码值。
一个合约如何调用另一个合约中的函数?

以太坊中规定,一个交易只有外部账户才能发起,合约账户不能够发起这个交易。

上面那个方法如何合约在调用中产生错误,那个会导致发起调用这个合约也一起回滚。而 call()函数如果在调用中显示异常,那个call()函数会返回funcsig,显示这个调用是失败的。但是发起调用这个函数不会异常而是继续执行。

delegatecall()和call()方法基本上一样,一个主要的区别就是,它不需要切换到被调用合约的环境中去执行,而是在当前合约的环境中执行就可以了。
fallback()函数:
function()public[payable]{
}
调用情况:
直接向一个合约地址转账
被调用的函数不存在


汽油费不够的话,花掉的汽油费也不退的


发布区块要消耗资源,我们要不要对这个消耗的资源有一个限制。比特币里面有大小的限制,以太坊中不能这么规定,所以要根据交易的具体操作来进行收费也就是汽油费,但是每个区块的汽油费有一个上限,也就是下面的gaslimit

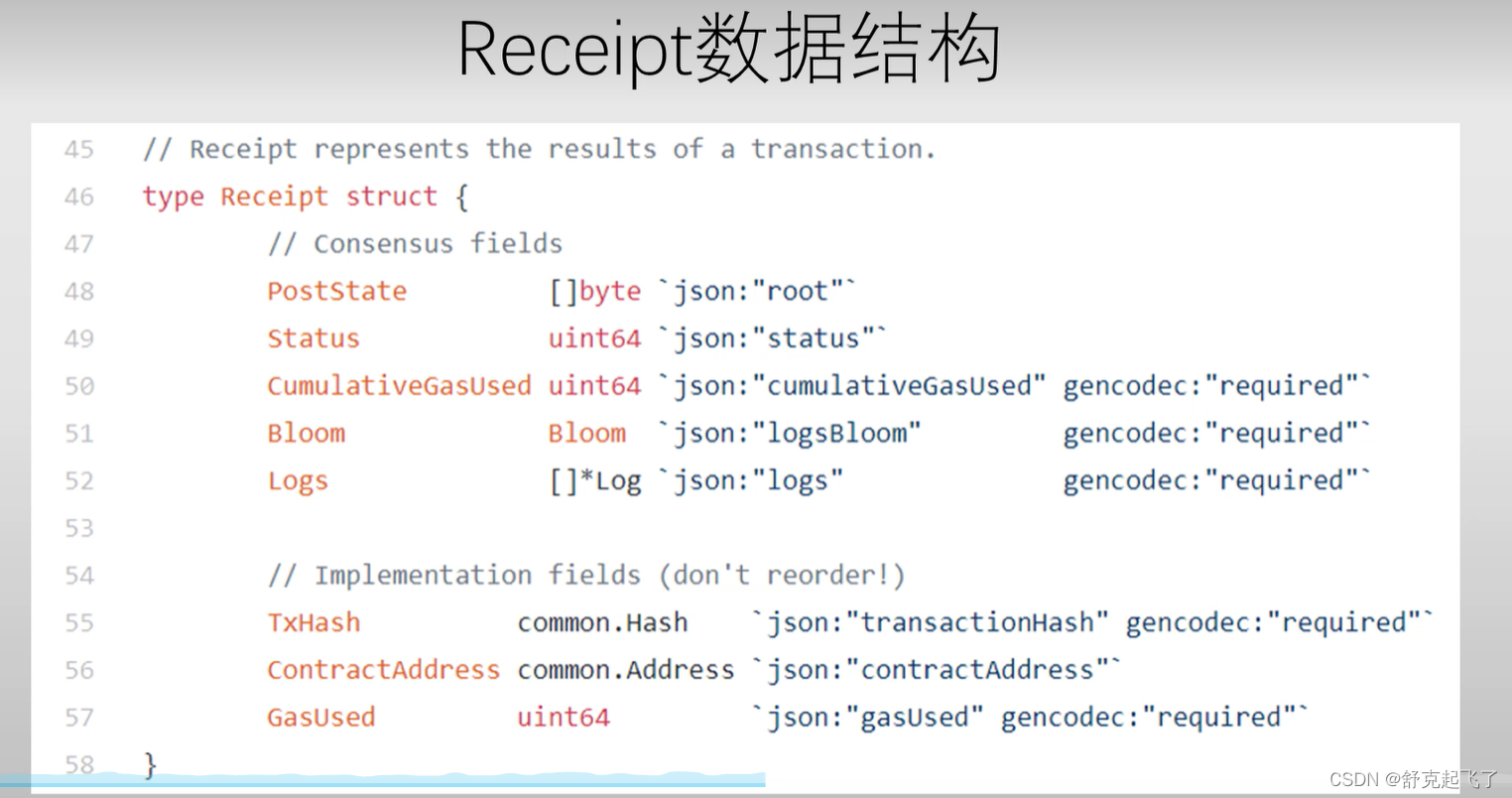
Receipt数据结构
区块链中有转账交易必须所有的全节点都执行(这不是一种浪费)如果有全节点不执行,那就表示出问题了。
智能合约执行过程中,任何对状态的修改,都是在改本地的数据结构。
以太坊中没有任何补偿,
会不会有的矿工认为你不给我汽油费,我不验证了?
如果不验证,以后就没有办法再进行挖矿了。
发布到区块链上的交易是不是都是成功执行的?
执行错误的交易也要发布到区块链上去,不然扣掉的汽油费回不来。

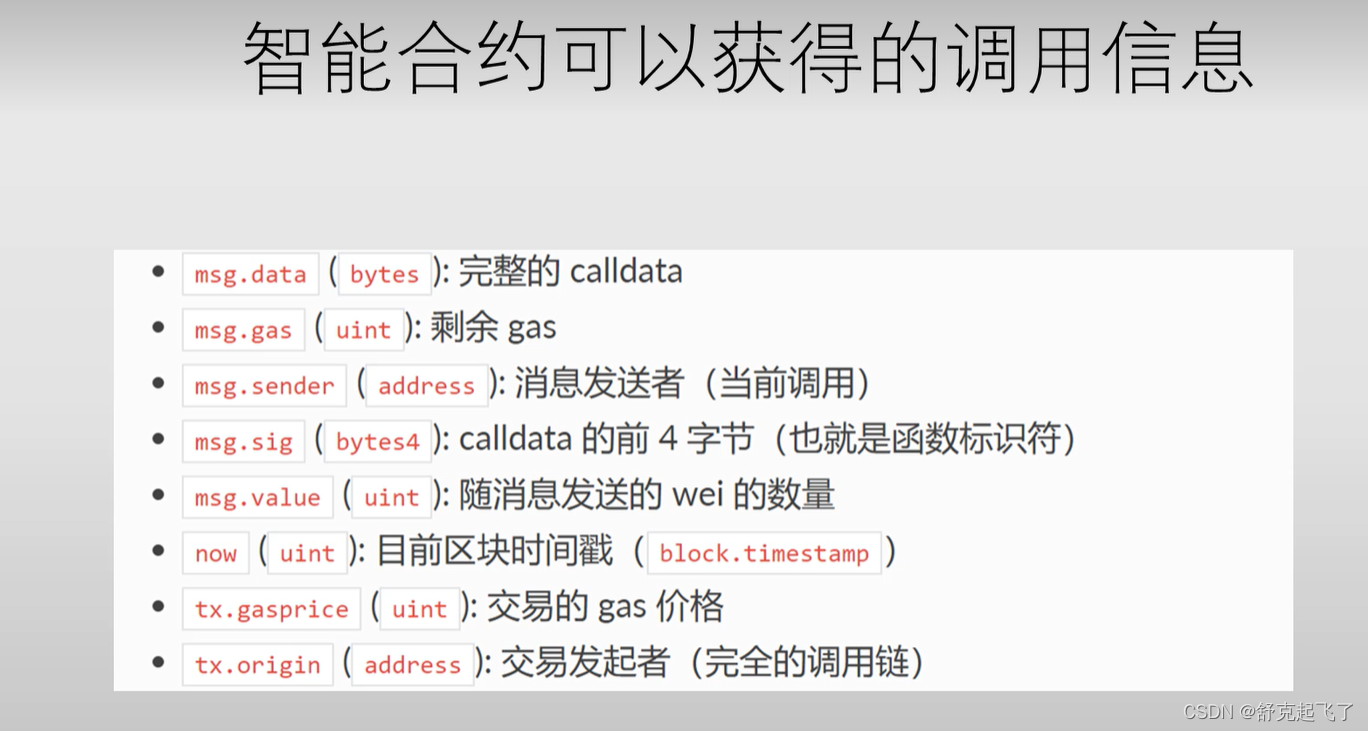
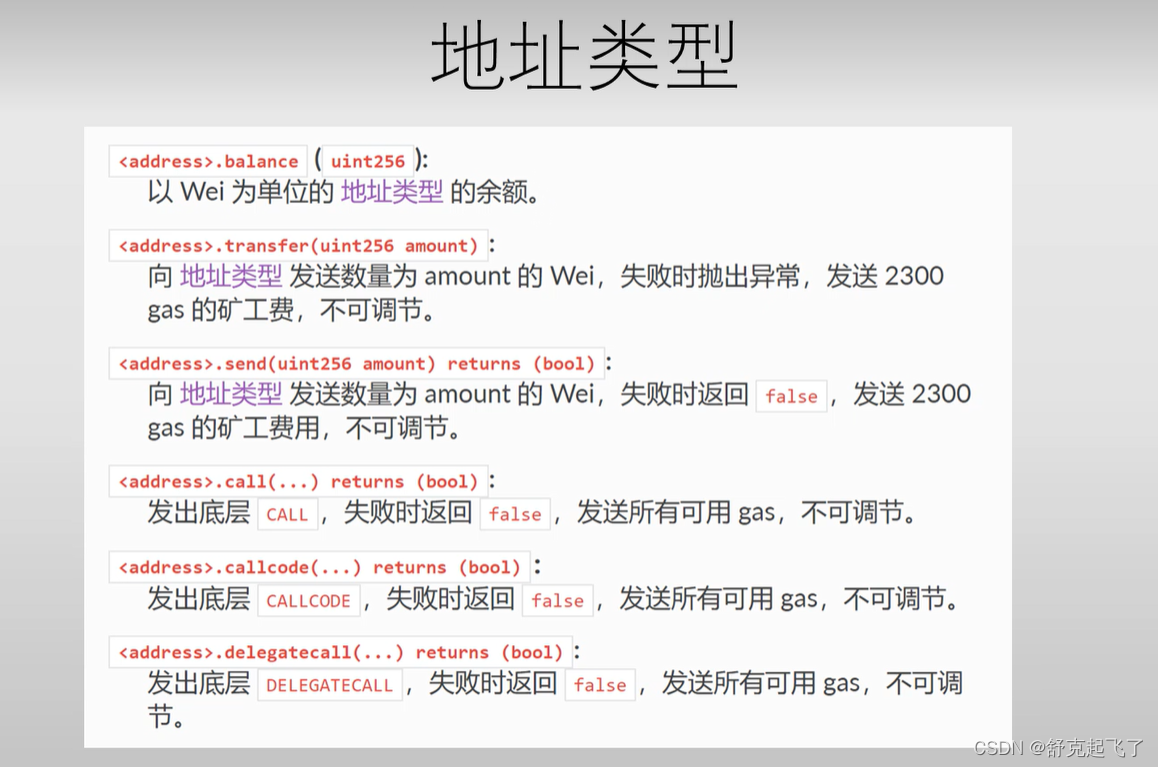
所有智能合约均可显式地转换成地址类型。