1.llama1 与 llama2 的区别
1)预训练语料从1->2 Trillion(万亿) tokens
2)context window 长度从2048->4096
3)收集了100k人类标注数据进行SFT(指令微调)
4)收集了1M人类偏好数据进行RLHF(先用偏好数据(对同一个问题,不同的大模型的回答进行排序打分)训练一个奖励模型,然后用奖励模型对模型回答进行打分,利用奖励模型提供的反馈,优化预训练模型的输出,使其更符合人类的偏好。)
2.LLaMA的示意图,区别于transformer模型的点
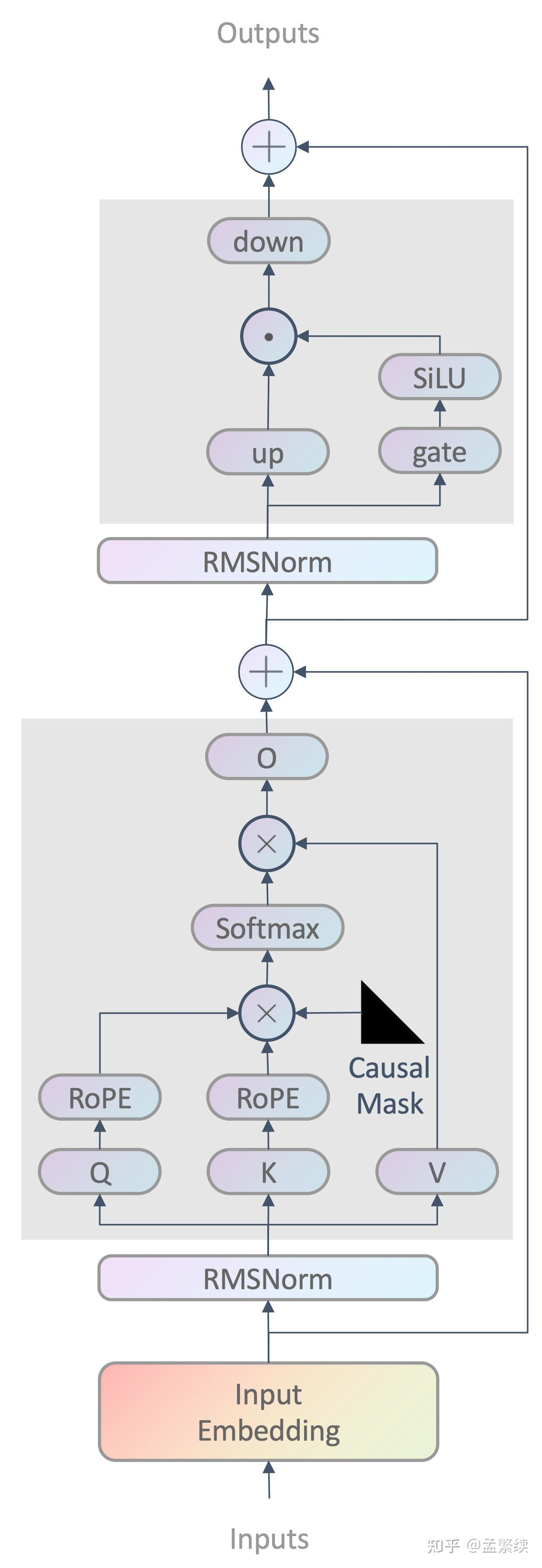
1)这张图展示的是 LLaMA 系列模型(包括 LLaMA 2)中 Transformer Block 的架构,它是一个典型的 Decoder-only 架构的 Transformer 模块,与transformer传统架构区别如下
1)替代了传统的正弦-余弦位置编码,引入旋转位置编码(RoPE),提升了模型在处理长文本和捕捉相对位置信息方面的能力(RoPE 的核心思想是将位置信息通过旋转操作嵌入到查询(Query)和键(Key)向量中。具体来说,对于每个位置 ppp,定义一个旋转角度 θp\theta_pθp,然后对向量进行旋转,这个旋转角度是通过确定性的数学公式计算得出,确保每个位置的编码具有一致性和可重复性。
),而之前传统的正弦-余弦位置编码,是采用固定的正弦和余弦函数:
2)对输入向量进行 Root Mean Square Normalization,这是 LLaMA 使用的归一化方式(区别于 LayerNorm(层归一化))
RMSNorm专注于**重新缩放(re-scaling)**输入数据,而不是重新中心化(re-centering)。这种方法通过计算输入向量的均方根(RMS)来实现归一化。
3)SiLU 激活 + Gated Linear Unit 结构:非线性增强,计算更高效。
(在LLaMA模型中,激活函数从传统的ReLU切换为SiLU(Sigmoid-Weighted Linear Unit),并结合了Gated Linear Unit (GLU)结构。这种设计旨在增强非线性表达能力,同时提高计算效率。)
4)Decoder-only 结构 + Causal Mask(和gpt模型一样)
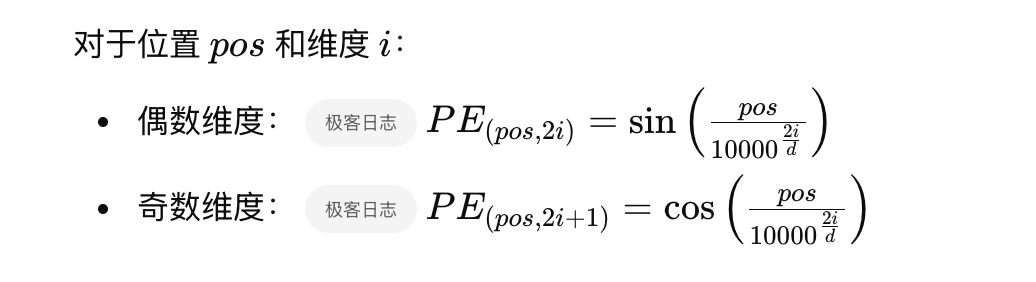



3.随着大模型规模日益增长,微调整个模型的开销逐渐变得难以接受。本文提出了一种名为PiSSA的参数高效微调方法,微调模型中最重要的参数。

文章内容参考链接:https://zhuanlan.zhihu.com/p/636784644