文章目录
概要
DeepSeek本地部署+投喂数据=解决的问题
1.DeepSeek本地化部署,无网络环境下使用
2.可以投喂你的数据文件,训练你的专属AI
3.不用担心服务器繁忙等问题,及时回应(好处不必多说了 懂的都懂)
整体架构流程
DeepSeek + Ollama + AnythingLLM 本地化全栈架构
结合DeepSeek(高性能模型)、Ollama(轻量化服务框架)与AnythingLLM(企业级知识库管理),可构建从模型推理到私有知识增强的全闭环本地化方案。以下是这一技术栈的核心架构设计:
模型层(DeepSeek Core)
推理引擎:基于DeepSeek模型的量化版本(GGUF/GGML),支持CPU/GPU混合推理。
多模型支持:同时部署不同规模的DeepSeek模型(如7B/67B),通过Ollama动态切换。
本地存储:离线模型仓库(如/models/deepseek)与向量数据库(如ChromaDB)分离存储。
服务化层(Ollama Engine)
统一API网关:提供标准化的/generate和/embedding接口,供AnythingLLM调用。
动态资源分配:根据请求类型(生成/检索)自动分配GPU资源,支持优先级队列。
模型热插拔:通过Ollama的/api/pull接口动态加载/卸载DeepSeek模型实例。
知识管理层(AnythingLLM Core)
文档处理流水线:
文档上传 → 文本分块 → 向量化(DeepSeek Embedding) → 存储至Chroma/Pinecone
RAG引擎:结合检索结果与DeepSeek生成,实现知识增强回答。
权限控制:基于RBAC的文档访问权限体系,支持SSO集成。
应用交互层(AnythingLLM UI + SDK)
企业级交互界面:支持对话式搜索、文档管理、对话历史追溯。
多端SDK:提供Python/Node.js SDK对接业务系统,支持流式响应与批处理。
运维监控层(Local Stack)
全链路监控:集成Prometheus + Loki + Grafana,覆盖模型推理延迟、知识库检索效率。
离线容器包:Docker镜像预置NVIDIA驱动、CUDA库及模型文件,支持Air Gap部署。
技术实现
1.去Ollama官网Ollama官网网址下载
2.下载完成之后,傻瓜式安装就行,然后在官网中选择Models
3.选择 deepseek-r1模型,
4.找到一个适合模型下载(我是选择 1.5b的)
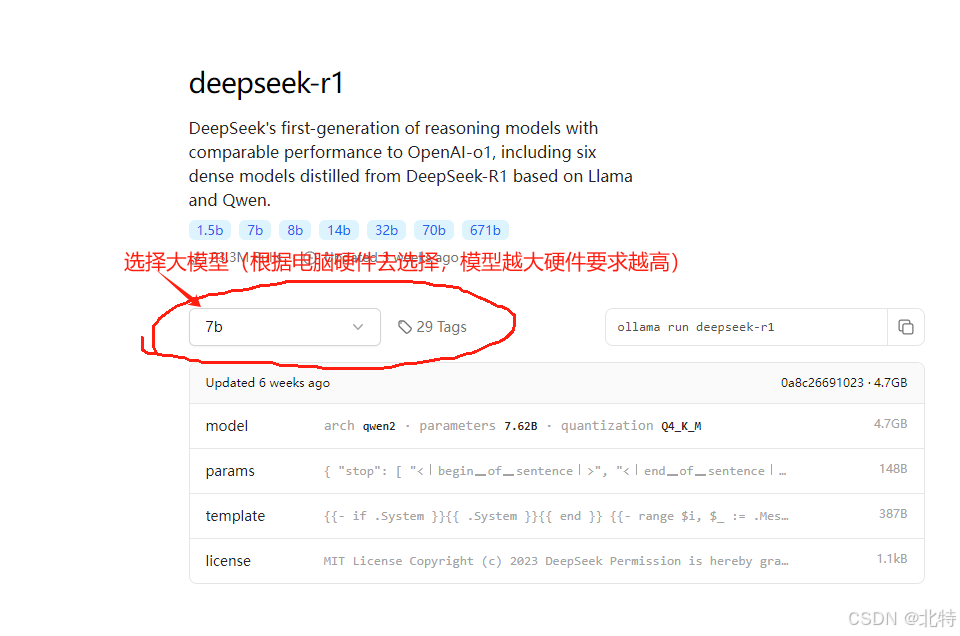
5.复制对应的模型信息,去命令终端复制上此信息,就会自动下载大模型
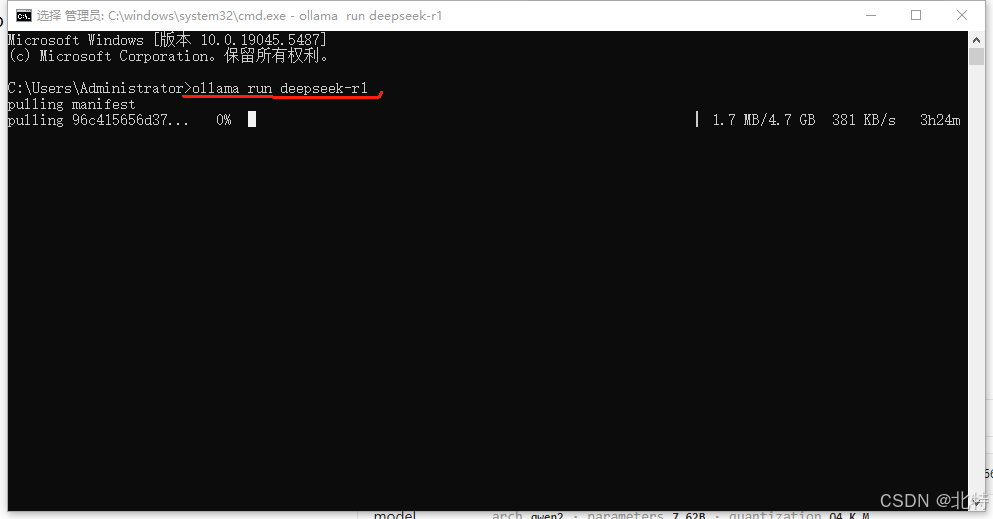
6.下载完成之后可以在窗口问DeepSeek一些问题,表示成功安装完毕了。如果要投喂数据还需要下载一个应用AnythingLLM 官网
7.具体安装我就不细述了,选择合适路径无脑安装就行…(装完之后需要配置一下环境和向量数据库)
下图参照(进入设置)
选择供应商的推理模型
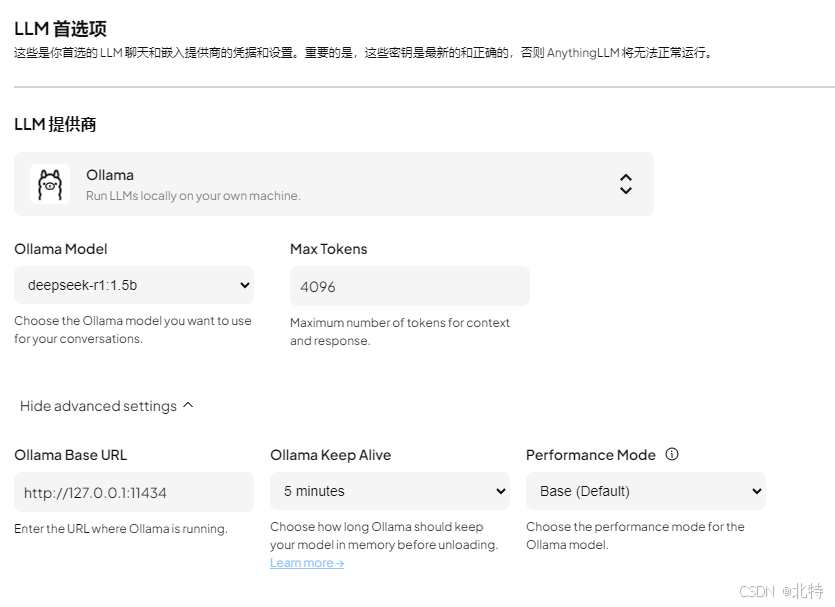
选择对应向量数据库
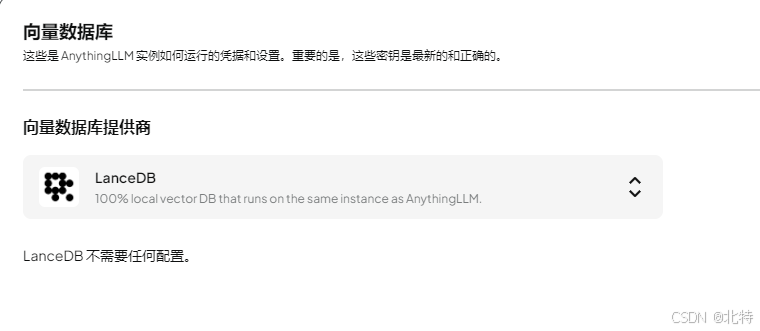
**接下来是为了投喂数据做的操作了---------
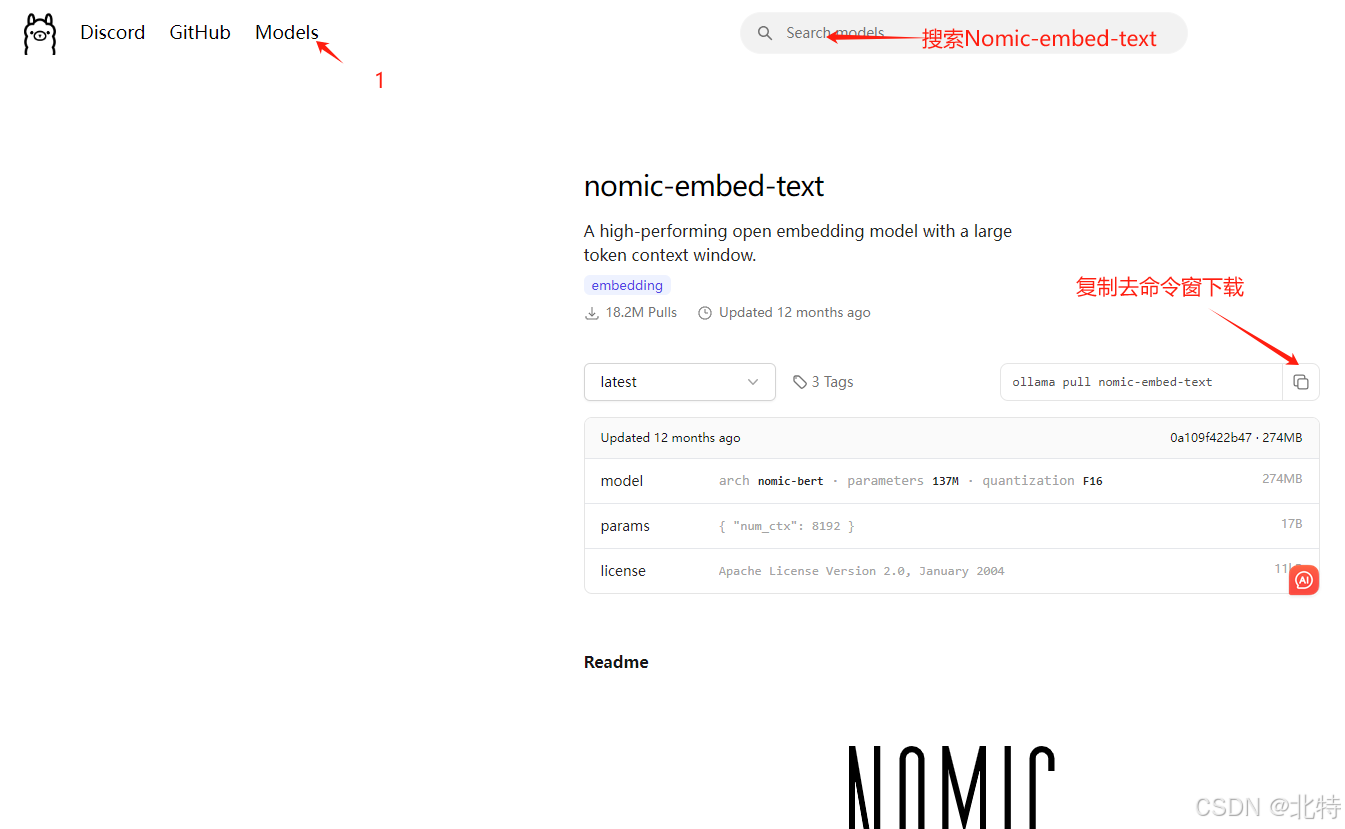
安装完Model,刷新一下,就会出现下面界面
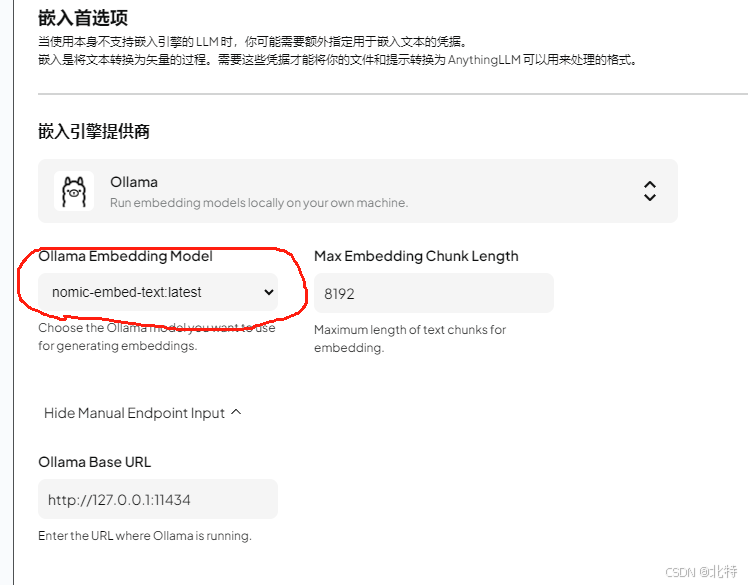
接下来就可以投喂数据了(按照我下边给出图片步骤来)
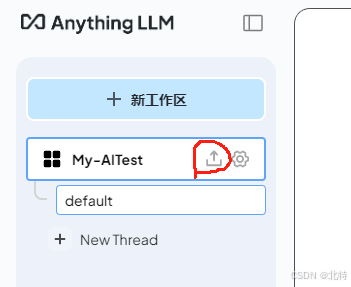
---------------------------------------------------------------------------------------------------------—分割线
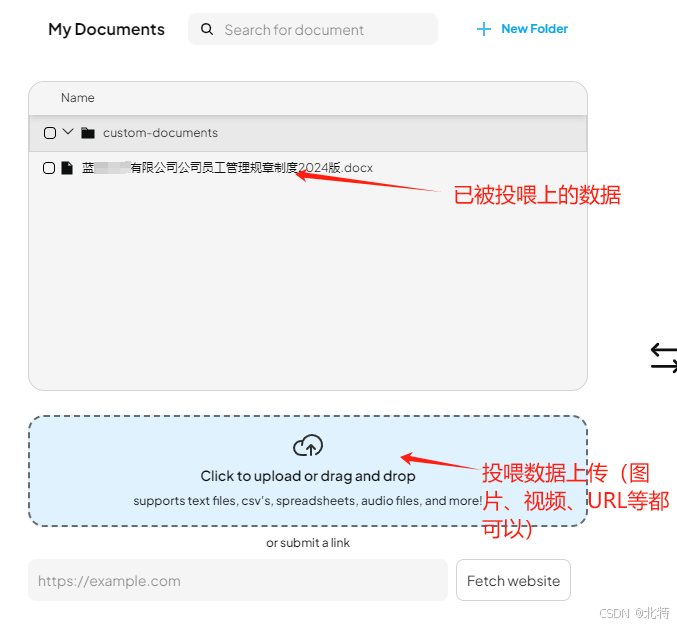
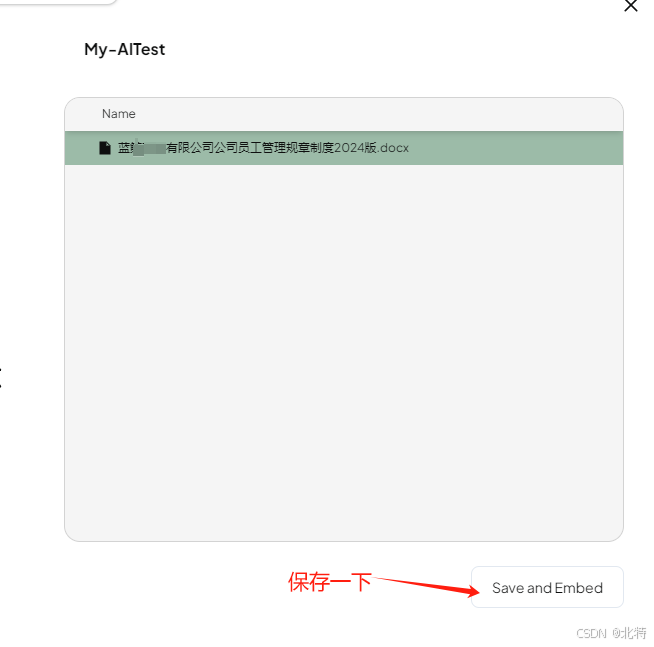
下面是展示成果(下面有提到上传文档相关的公司适用信息)

小结
以上是最简单的本地化部署AI的方法,也是入门。其实还有很多功能,待我后续进行文章发布!请关注我一下 谢谢!!!