从用户感知角度分析私有化部署的大模型推理性能,这里的用户感知包括响应速度、生成速度、系统可用性以及系统稳定性。大模型首先获取输入内容的字符串,将这部分内容转换为模型token,过模型推理,到最后输出第一个token的时间是ttft,从这以后,这个token就变成了下一个token的输入进行循环推理输出下一个token,这样两个token之间的速度就是tpot,大模型本质上就是不断把上面预测的输出作为下一个token的输入,有点像贪吃蛇。
- 响应速度:用户发出请求后,系统响应的快慢。
- 生成速度:模型生成内容的流畅度和速度。
- 系统可用性:系统是否能够同时服务多个用户。
- 系统稳定性:系统是否能稳定运行,不出现卡顿或崩溃。
核心性能指标对用户感知的影响包括
1、延迟指标
- 首token延迟(TTFT):从用户发出请求到模型生成第一个token的时间。TTFT越短,用户感受到的初始响应速度越快。
- token生成速度(TPOT):生成每个token所需的时间。TPOT越快,用户感受到的内容生成越流畅,尤其在长文本生成中表现明显。
- 端到端延迟(E2E):从请求发出到接收完整响应的总时间。E2E延迟越短,用户整体等待时间越少,响应速度越高。
2、吞吐量指标
- 预填充吞吐:模型在预填充阶段(处理输入数据)的处理能力。虽然对用户感知的影响较间接,但高预填充吞吐能加快输入处理,为后续生成奠定基础。
- prefill
- 解码吞吐:模型在生成token阶段的处理能力。解码吞吐越高,生成速度越快,用户体验更流畅。
- decode
- 总体吞吐:模型整体的处理能力,决定了系统能同时处理多少请求。总体吞吐越高,系统可用性越强,能支持更多用户。
3、资源利用
- GPU利用率:GPU资源的利用效率。高利用率能提升模型处理能力,从而间接提高响应速度和生成速度。
- 内存使用:内存使用效率影响模型能处理的数据量和请求数。高效的内存使用支持更多并发请求,提升系统可用性。
- 功耗效率:对用户感知影响较小,但影响系统运营成本和长期稳定性。
4、并发能力
- 最大批大小:系统能同时处理的请求数量。批大小越大,系统可用性越高,用户等待时间越短。
- 请求队列:管理等待处理的请求。优秀的队列管理能减少用户等待时间,提升响应速度和系统可用性。
- 负载均衡:将请求均匀分配到处理单元,避免过载。良好的负载均衡提高系统稳定性,间接提升用户体验。
性能指标与用户感知的映射关系
- 响应速度:主要受首token延迟(TTFT)和端到端延迟(E2E)**影响。
- 生成速度:主要受token生成速度(TPOT)和解码吞吐影响。
- 系统可用性:主要受总体吞吐、最大批大小和请求队列影响。
- 系统稳定性:主要受GPU利用率、内存使用和负载均衡影响。

从网上搜索了一些信息汇总,
- 使用 vLLM 和 sglang 部署模型推理服务前,应测试延迟、吞吐量、资源利用率和并发能力等性能指标。
- 建议标准包括:首token延迟(TTFT)< 200 毫秒、token生成速度(TPOT)> 50 tokens/秒、端到端延迟(E2E)< 2 秒(100 tokens响应)、吞吐量> 20 请求/秒、GPU利用率> 80%、内存使用在分配范围内。
表:典型性能指标与建议标准
| 指标 | 描述 | 建议标准 |
|---|---|---|
| 首token延迟(TTFT) | 请求到第一个token生成时间 | < 200 毫秒 |
| token生成速度(TPOT) | 每秒生成token数量 | > 50 tokens/秒 |
| 端到端延迟(E2E) | 请求到完整响应总时间(100 tokens) | < 2 秒 |
| 吞吐量 | 每秒处理请求数量 | > 20 请求/秒 |
| GPU利用率 | GPU资源利用效率 | > 80% |
| 内存使用 | 系统内存占用情况 | 在分配范围内,无交换 |
对于DeepSeek R1 671B部署推理分析:
DeepSeek R1 671B 是一个 671B 参数的 MoE 模型,每 token 只激活约 37B 参数,设计用于高效推理,支持 128K token 输入和 32K token 生成。MoE 架构通过路由机制选择专家处理输入,相比密集型 LLM(所有参数均参与计算),其计算效率更高,尤其适合大规模模型。
vLLM 和 sglang 是两种高效的推理服务框架。vLLM 强调高吞吐量和内存效率,采用 PagedAttention 等技术;sglang 则提供 RadixAttention 和数据并行优化,支持多种模型,包括 DeepSeek 系列。两者均支持 MoE 模型,如 Mixtral 和 DeepSeek R1。
性能指标分析
响应速度(TTFT)
- 定义:从用户请求到生成第一个 token 的时间,直接影响用户感知的初始响应速度。
- MoE 模型特点:MoE 模型需要额外的专家选择过程,可能增加少量 TTFT 开销。但由于只激活部分参数,实际计算时间可能与活跃参数数量相当的密集型 LLM 相似或略好。
- 与密集型 LLM 比较:相比总参数为 671B 的密集型 LLM,MoE 模型的 TTFT 应显著更好,因为密集型模型需要处理所有参数,计算开销更大。相比 37B 参数的密集型 LLM,TTFT 可能相当,取决于框架优化。
- 框架支持:vLLM 和 sglang 的优化(如连续批处理)可能减少 MoE 模型的 TTFT 开销。研究表明,vLLM 在 Llama 8B 上 TTFT 可达 200 毫秒以下,MoE 模型可能类似 。
- 建议标准:TTFT 目标为 < 200 毫秒,与小型密集型 LLM 相当,确保实时应用的用户体验。
生成速度(TPOT)
- 定义:生成后续 token 的速度,单位为 tokens/秒,影响生成文本的流畅度。
- MoE 模型特点:MoE 模型每 token 只激活约 37B 参数,相比 37B 参数的密集型 LLM,计算效率更高,可能生成速度更快。相比 671B 参数的密集型 LLM,优势更明显,因为密集型模型计算开销巨大。
- 与密集型 LLM 比较:研究显示,MoE 模型在推理时因稀疏激活可实现更高 TPOT。例如,sglang 在 DeepSeek 模型上通过数据并行优化,解码吞吐量提升 1.9 倍 (SGLang v0.4 Blog)。vLLM 在 Llama 70B 上 TPOT 可达 50 tokens/秒,MoE 模型可能更优。
- 框架支持:sglang 提供 RadixAttention 和专家并行支持,vLLM 支持 Mixtral 等 MoE 模型,均能提升 TPOT。研究表明,MoE 模型在现代加速器上步长时间更短 。
- 建议标准:TPOT 目标为 > 50 tokens/秒,确保流畅生成,优于同等活跃参数的密集型 LLM。
系统可用性
- 定义:系统能同时处理多少用户请求,涉及吞吐量和最大批大小。
- MoE 模型特点:MoE 模型因稀疏激活可更高效利用资源,允许更大批处理和更高并发。专家复用可减少内存占用,提升吞吐量。
- 与密集型 LLM 比较:相比同等硬件的密集型 LLM,MoE 模型能服务更多用户。例如,sglang 在 8x H100 80GB GPU 上通过数据并行优化 DeepSeek 模型,吞吐量显著提升 (SGLang v0.4 Blog)。vLLM 报告在 Llama 70B 上吞吐量达 20 请求/秒,MoE 模型可能更高。
- 框架支持:vLLM 和 sglang 支持连续批处理和张量并行,MoE 模型的效率进一步放大。研究显示,MoE 模型在高负载下表现更优
- 建议标准:吞吐量目标 > 20 请求/秒,最大批大小需测试以确保高并发场景下性能。
稳定性
- 定义:系统在负载下的可靠性,避免崩溃或性能下降,涉及 GPU 利用率、内存使用和负载均衡。
- MoE 模型特点:MoE 模型的动态专家选择可能增加负载管理复杂性,但因稀疏激活,资源利用率可能更高。专家并行和数据并行需妥善管理以避免瓶颈。
- 与密集型 LLM 比较:稳定性应与密集型 LLM 相当,vLLM 和 sglang 设计上注重资源管理。研究显示,MoE 模型在现代加速器上通过 3D 分片保持步长时间增加在可控范围内 。
- 框架支持:sglang 提供缓存感知负载均衡,vLLM 支持多 GPU 配置,均能确保稳定性。研究表明,MoE 模型在高负载下表现稳定 。
- 建议标准:GPU 利用率 > 80%,内存使用在分配范围内,确保系统稳定运行。
对比表:MoE vs 密集型 LLM 性能要求
| 指标 | MoE 模型 (DeepSeek R1 671B) | 密集型 LLM (同等活跃参数) |
|---|---|---|
| 响应速度 (TTFT) | 可能相似或略好,目标 < 200 毫秒 | 类似,依赖硬件和框架优化 |
| 生成速度 (TPOT) | 可能更快,目标 > 50 tokens/秒 | 类似,但计算开销可能更高 |
| 系统可用性 | 更好,可服务更多用户,吞吐量目标 > 20 请求/秒 | 受限于资源,可能吞吐量较低 |
| 稳定性 | 相当,需注意专家选择动态性,GPU 利用率 > 80% | 类似,但资源管理可能更简单 |
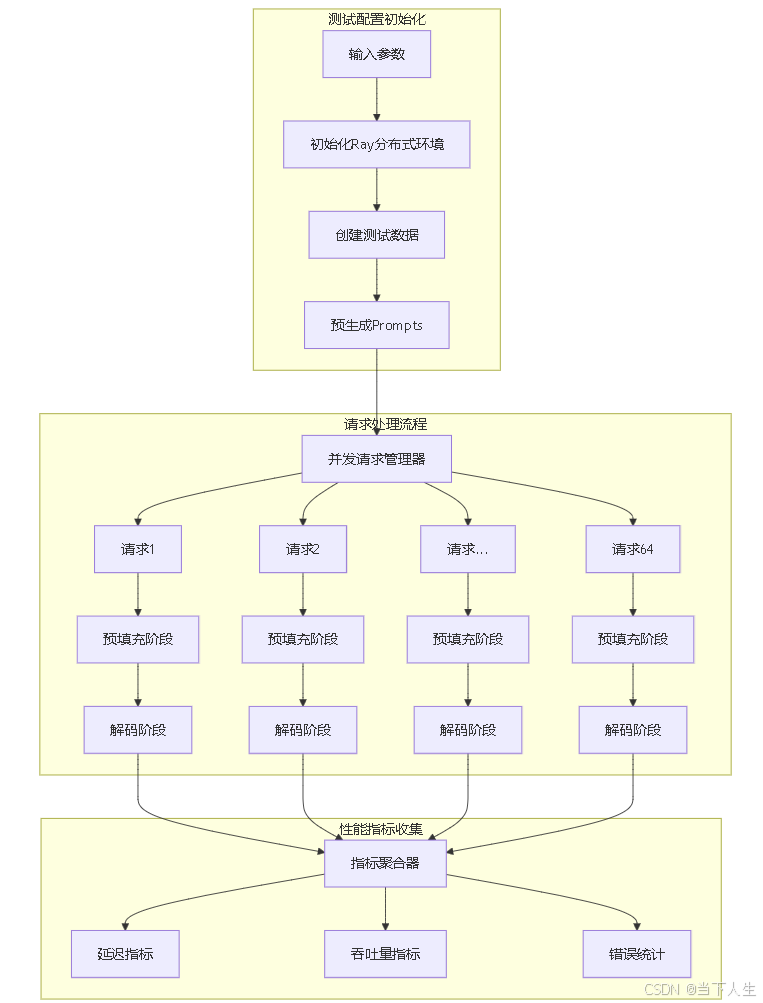
实际测试,私有化部署对算力要求相当之高,效果距离行业通用标准而言堪忧,还有很大的提升空间,主要体现在TTFT和E2E指标,我可以理解为推理类模型的E2E就不可能和chat类模型一样,因为传统模型没有思考时间。下图为测试架构。
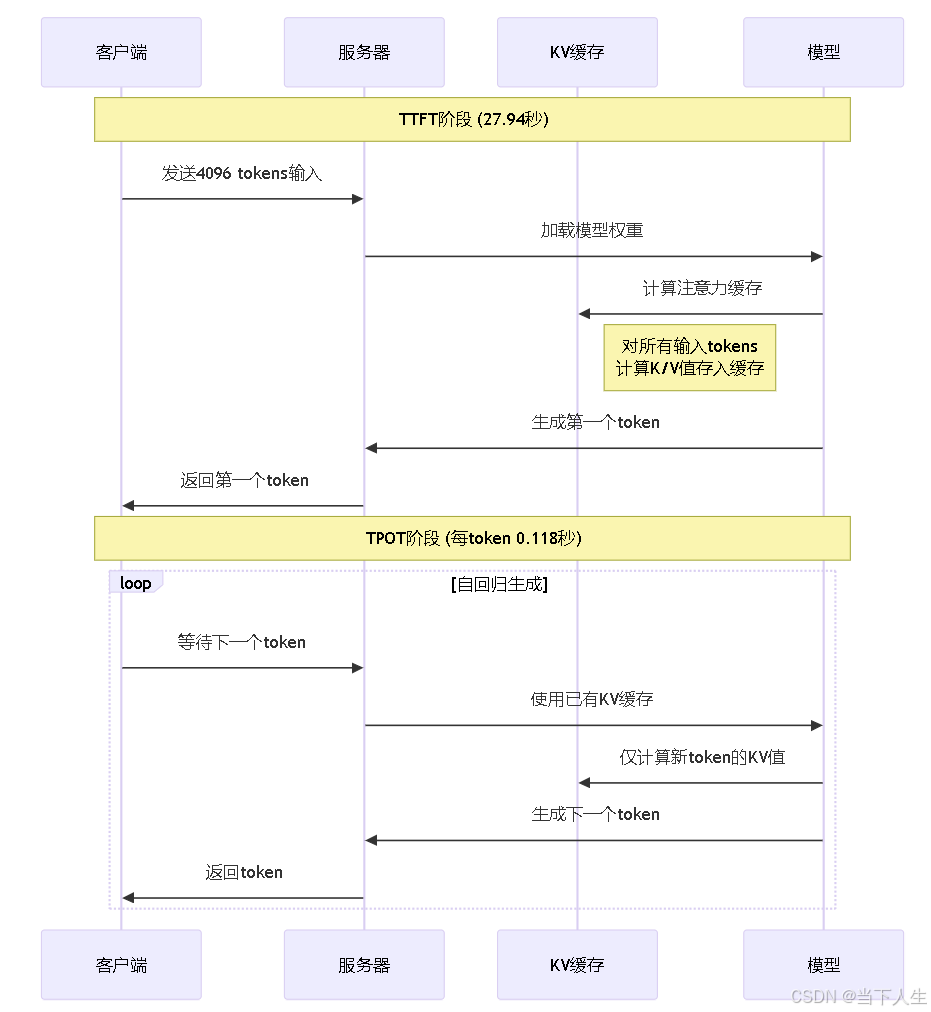
下面是测试原理图
下面是不同输入长度token情况下的趋势。
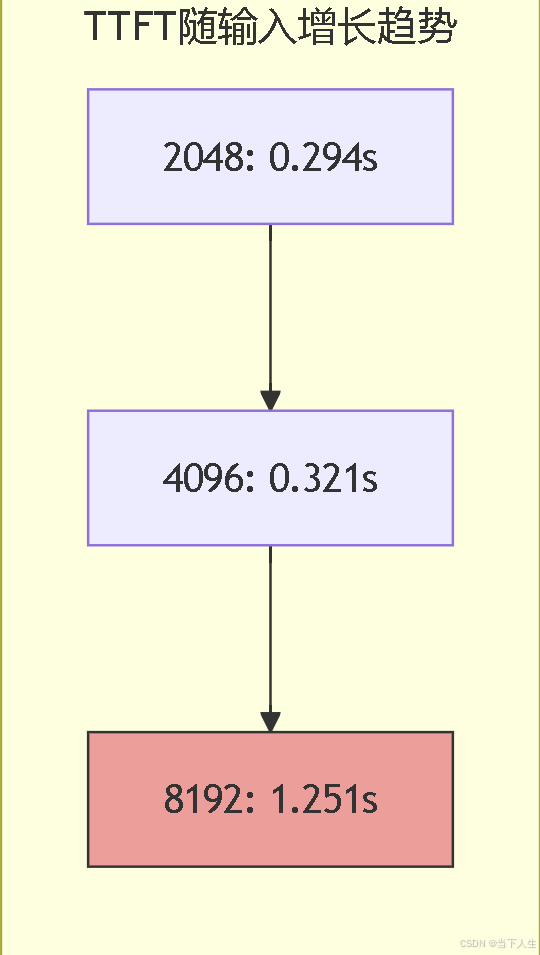



输入2048:
- 端到端延迟: 47.96s
- 请求完成率: 1.25次/分钟
- 输出吞吐: 23.17 tokens/s
输入4096:
- 端到端延迟: 49.56s
- 请求完成率: 1.21次/分钟
- 输出吞吐: 22.24 tokens/s
输入8192:
- 端到端延迟: 53.59s
- 请求完成率: 1.12次/分钟
- 输出吞吐: 20.69 tokens/s
结论:
- 输入从4096到8192时性能下降明显
- TTFT在8192时急剧增加(约4倍)
- 预填充吞吐在4096时达到峰值
- TPOT基本保持线性增长
- 端到端延迟随输入增加而非线性增长
- 解码吞吐略有下降但相对稳定
优化方向:
A. 输入长度选择
- 一般场景建议控制在4096以内
- 超长输入考虑分段处理
B. 性能优化方向
- 针对8192+场景优化预填充性能
- 改进长序列的注意力计算
- 提升KV Cache利用效率
C. 应用部署建议
- 根据实际输入长度特点选择配置
- 考虑输入长度动态分配资源
- 监控TTFT作为关键指标
vllm 和 sglang的对比:
- vLLM的优势:
- 解码吞吐量略高(+6.5%)
- 单token生成时间更短(-7%)
- 端到端延迟更低(-4.1%)
- 整体吞吐量更好(+4%)
- SGLang的优势:
- TTFT显著更低(-55.7%)
- 预填充吞吐量更高(+125%)
- 性能波动更小 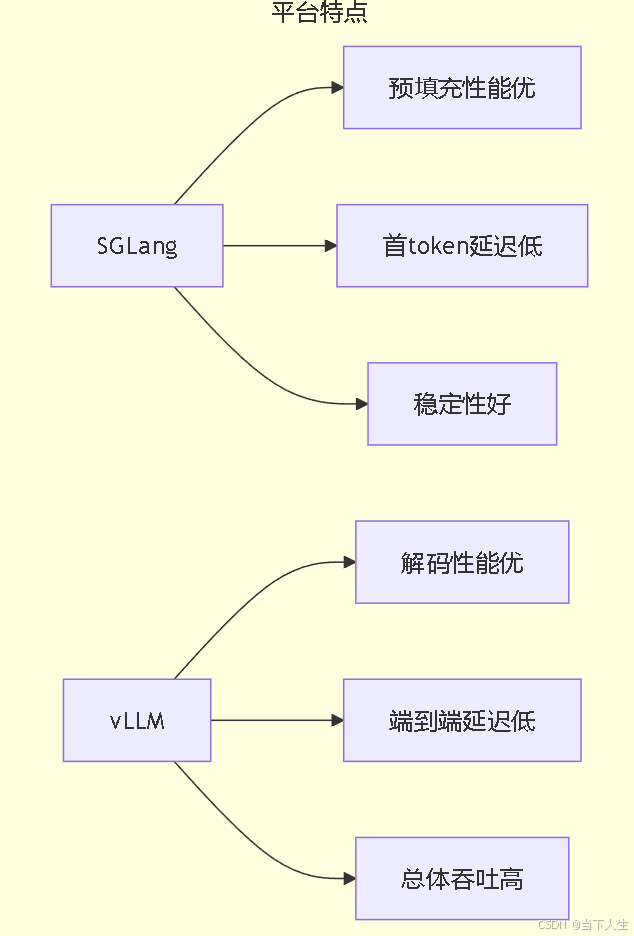
建议和结论:
- 场景选择:
SGLang适合:
- 对首次响应速度敏感的场景
- 需要稳定性能的场景
- 批处理场景
vLLM适合:
- 持续对话场景
- 追求高吞吐的场景
- 长文本生成场景
- 性能优化方向:
SGLang:
- 提升解码阶段性能
- 优化端到端延迟
vLLM:
- 改进TTFT
- 提升预填充效率
- 减少性能波动总体可以得出结论,输入输出序列越短,ttft和e2e指标越好,并发性能和吞吐量越高
