一、为什么需要大模型评估指标?
| 场景 | 评估目的 |
|---|---|
| 微调模型后 | 看模型是不是比之前更聪明了 |
| 多个模型对比 | 看哪个模型回答更好 |
| 训练参数调整后 | 看模型是不是更稳定、更准确 |
| 模型上线前 | 确保输出没有胡说八道、歧视、敏感信息等 |
| 学术论文发表 | 有量化的指标才能说明效果进步了 |
评估指标的作用,就是帮我们有标准、有数据、有依据地判断大模型的生成结果是不是靠谱的。
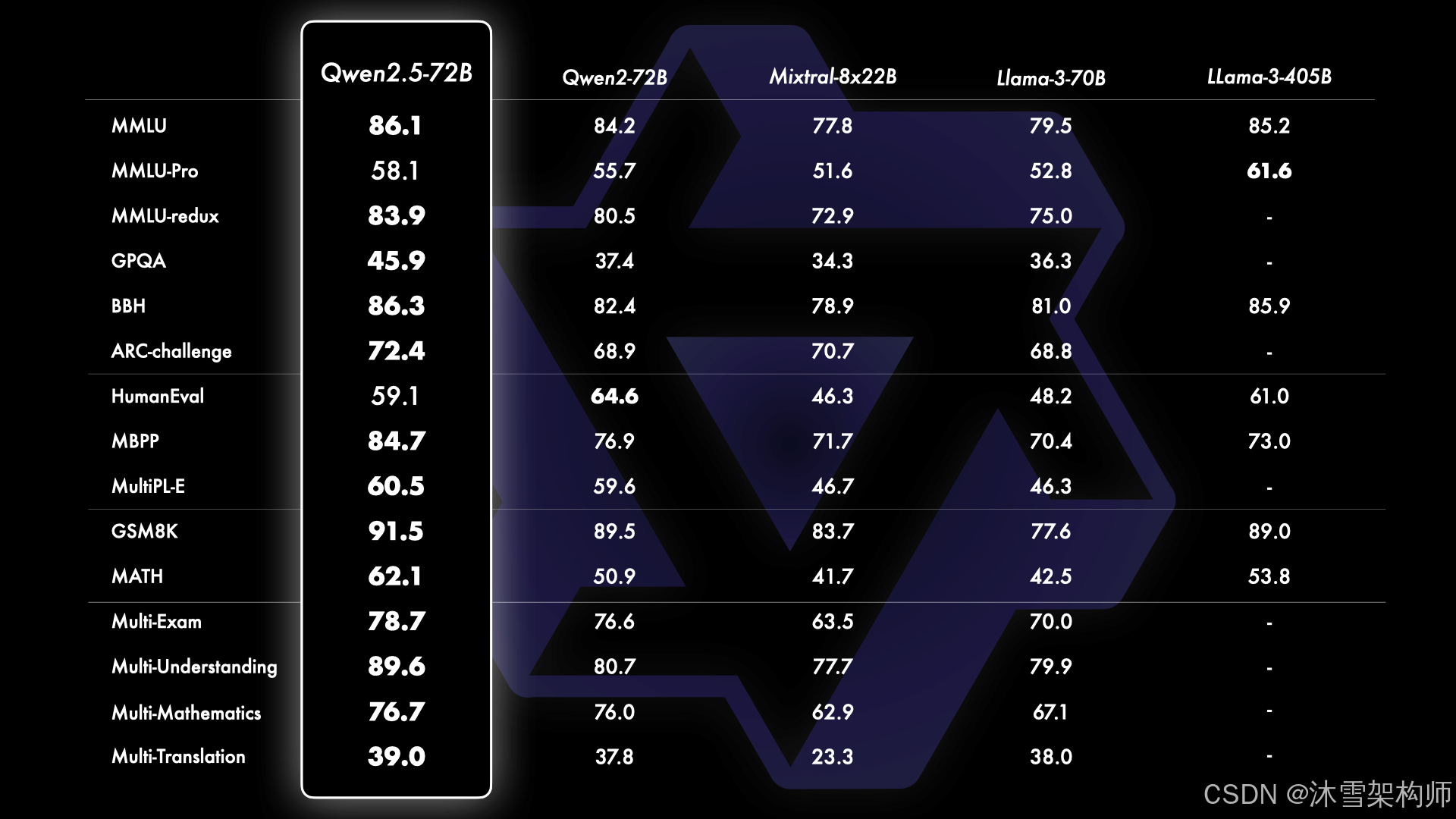
它们像考试的评分标准,有了它们我们才能说“这个模型考了90分,那个只考了70分”。市面上几乎所有的大模型都会发布评估测试数据。如下是千问官方发布的Qwen2.7-72B的大模型评估。
二、生成式大模型的评估指标
OpenCompass支持以下主要评估指标,覆盖生成式大模型的多样化需求:
- 准确率(Accuracy):用于选择题或分类任务,通过比对生成结果与标准答案计算正确率。在OpenCompass中通过metric=accuracy配置
- 困惑度(Perplexity, PPL):衡量模型对候选答案的预测能力,适用于选择题评估。需使用ppl类型的数据集配置(如ceval_ppl)
- 生成质量(GEN):通过文本生成结果提取答案,需结合后处理脚本解析输出。使用gen类型的数据集(如ceval_gen),配置metric=gen并指定后处理规则
- ROUGE/LCS:用于文本生成任务的相似度评估,需安装rouge==1.0.1依赖,并在数据配置中设置metric=rouge
- 条件对数概率(CLP):结合上下文计算答案的条件概率,适用于复杂推理任务,需在模型配置中启用use_logprob=True
三、主流开源大模型评估数据集
数据集列表
开源的大模型评估数据集有很多种,详情可以看这篇《主流开源大模型评估数据集》。这里重点说下OpenCompass的内置数据集。OpenCompass内置超过70个数据集,覆盖五大能力维度:
- 知识类:C-Eval(中文考试题)、CMMLU(多语言知识问答)、MMLU(英文多选题)。
- 推理类:GSM8K(数学推理)、BBH(复杂推理链)。
- 语言类:CLUE(中文理解)、AFQMC(语义相似度)。
- 代码类:HumanEval(代码生成)、MBPP(编程问题)。
- 多模态类:MMBench(图像理解)、SEED-Bench(多模态问答)。
数据集区别与选择
评估范式差异:
- _gen后缀数据集:生成式评估,需后处理提取答案(如ceval_gen)
- _ppl后缀数据集:困惑度评估,直接比对选项概率(如ceval_ppl)
领域覆盖:
- C-Eval:侧重中文STEM和社会科学知识,包含1.3万道选择题
- LawBench:法律领域专项评估,需额外克隆仓库并配置路径
四、什么是OpenCompass?
OpenCompass 是一个开源项目,旨在为机器学习和自然语言处理领域提供多功能、易于使用的工具和框架。其中包含的多个开源模型和开源数据集(BenchMarks),方便进行模型的效果评测。

OpenCompass 的主要特点包括开源可复现、全面的能力维度、丰富的模型支持、分布式高效评测、多样化评测范式以及灵活化拓展。基于高质量、多层次的能力体系和工具链,OpenCompass 创新了多项能力评测方法,并构建了一套高质量的中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等多个方面,能够实现对大模型真实能力的全面诊断。
官网:
https://opencompass.org.cn/home
github地址:
https://github.com/open-compass/opencompass/blob/main/README_zh-CN.md
官方文档:
https://opencompass.readthedocs.io/zh-cn/latest/get_started/installation.html
五、安装OpenCompass
安装OpenCompass 过程
1、使用Conda准备 OpenCompass 运行环境:python建议选择3.10版本。
conda create --name opencompass python=3.10 -y
# conda create --name opencompass_lmdeploy python=3.10 -y
conda activate opencompass2、安装 OpenCompass,建议从源代码构建它
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .下载数据集
OpenCompass 支持的数据集主要包括三个部分:
(1)Huggingface 数据集: Huggingface Dataset 提供了大量的数据集,这部分数据集运行时会自动下载。
(2)ModelScope 数据集:ModelScope OpenCompass Dataset 支持从 ModelScope 自动下载数据集。要启用此功能,请设置环境变量:export DATASET_SOURCE=ModelScope,可用的数据集包括(来源于 OpenCompassData-core.zip):
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli(3)自建以及第三方数据集:OpenCompass 还提供了一些第三方数据集及自建中文数据集。运行以下命令手动下载解压。
在 OpenCompass 项目根目录下运行下面命令,将数据集准备至 ${OpenCompass}/data 目录下:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip一般来说我们只要下载这个数据集就够用了。
如果需要使用 OpenCompass 提供的更加完整的数据集 (~500M),可以使用下述命令进行下载和解压:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip
unzip OpenCompassData-complete-20240207.zip
cd ./data
find . -name "*.zip" -exec unzip "{}" \;两个 .zip 中所含数据集列表如此处所示。
六、评估任务
在 OpenCompass 中,每个评估任务由待评估的模型和数据集组成。评估的入口点是 run.py。用户可以通过命令行或配置文件选择要测试的模型和数据集。
1、命令行-自定义HF模型
对于 HuggingFace 模型,用户可以通过命令行直接设置模型参数,无需额外的配置文件。例如,对于 对话模型 Qwen1.5-4B-Chat 和基座模型Qwen/Qwen2.5-1.5B,您可以使用以下命令进行评估:
对于对话模型
python run.py \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--hf-type chat \
--hf-path /root/autodl-tmp/llm/Qwen/Qwen1.5-4B-Chat \
--debug对于基座模型
python run.py \
--datasets demo_gsm8k_base_gen demo_math_base_gen \
--hf-type base \
--hf-path /root/autodl-tmp/llm/Qwen/Qwen2.5-1.5B \
--debug对话模型相比于基座模型,其名称上会多chat,instruct等额外文字描述,而基座模型的名称仅包含“模型名称+版本+参数”。
请注意,通过这种方式(命令行-自定义HF模型),OpenCompass 一次只评估一个模型,而其他方式可以一次评估多个模型。
参数说明
| 命令行参数 |
描述 |
样例数值 |
|---|---|---|
|
|
HuggingFace 模型类型,可选值为 |
chat |
|
|
HuggingFace 模型路径 |
internlm/internlm2-chat-1_8b |
|
|
构建模型的参数 |
device_map=’auto’ |
|
|
HuggingFace tokenizer 路径(如果与模型路径相同,可以省略) |
internlm/internlm2-chat-1_8b |
|
|
构建 tokenizer 的参数 |
padding_side=’left’ truncation=’left’ trust_remote_code=True |
|
|
生成的参数 |
do_sample=True top_k=50 top_p=0.95 |
|
|
模型可以接受的最大序列长度 |
2048 |
|
|
生成的最大 token 数 |
100 |
|
|
生成的最小 token 数 |
1 |
|
|
批量大小 |
64 |
|
|
运行一个模型实例所需的 GPU 数量 |
1 |
|
|
停用词列表 |
‘<|im_end|>’ ‘<|im_start|>’ |
|
|
填充 token 的 ID |
0 |
|
|
(例如) LoRA 模型的路径 |
internlm/internlm2-chat-1_8b |
|
|
(例如) 构建 LoRA 模型的参数 |
trust_remote_code=True |
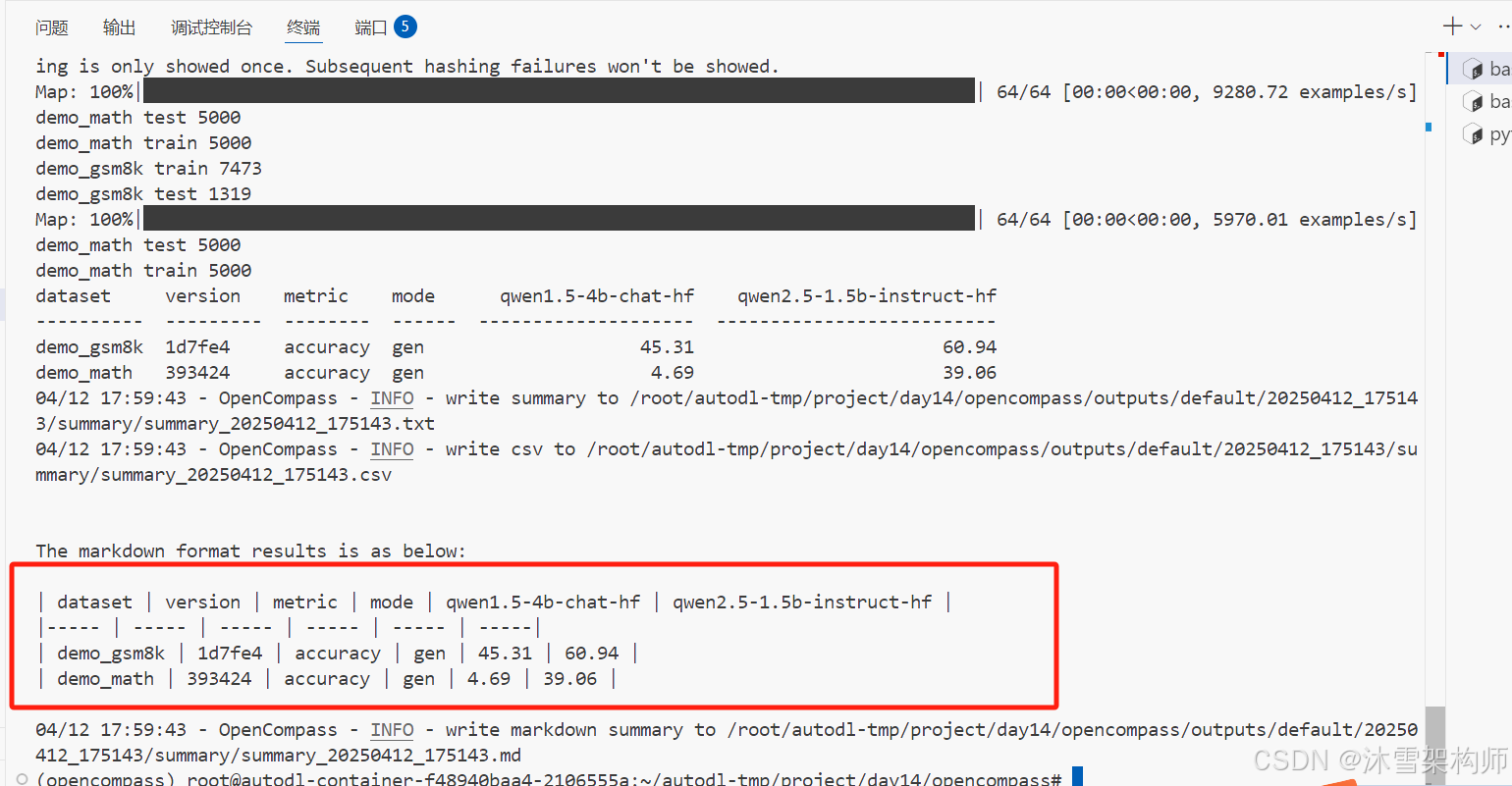
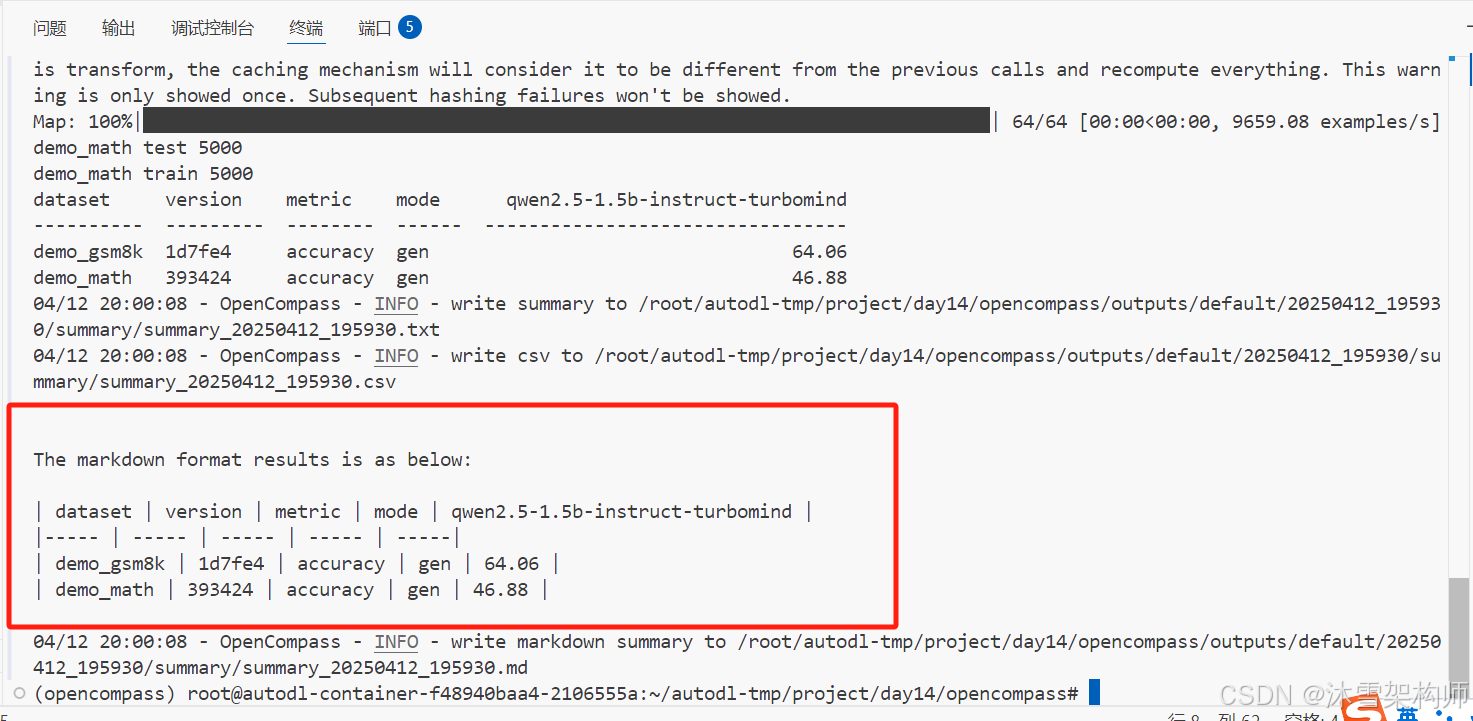
训练结果可以在控制台看到,OpenCompass也会将结果保存文件里,路径在根目录的outputs下,日期的目录-summary。
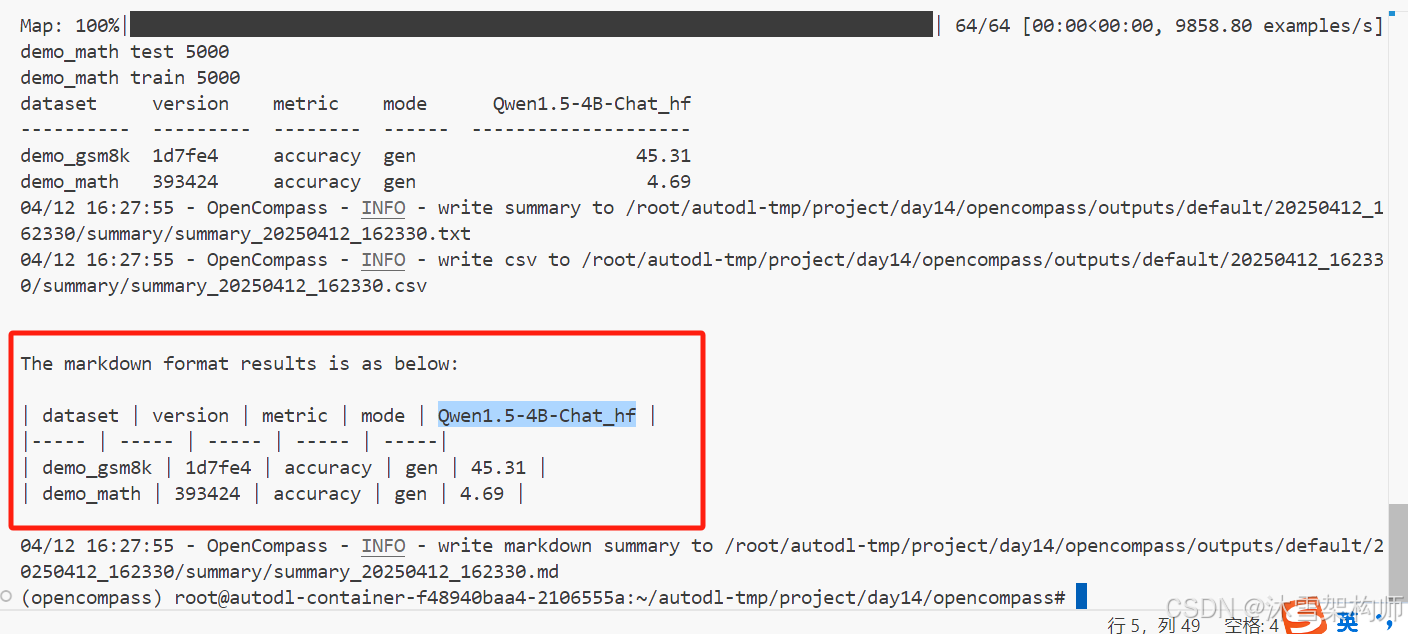
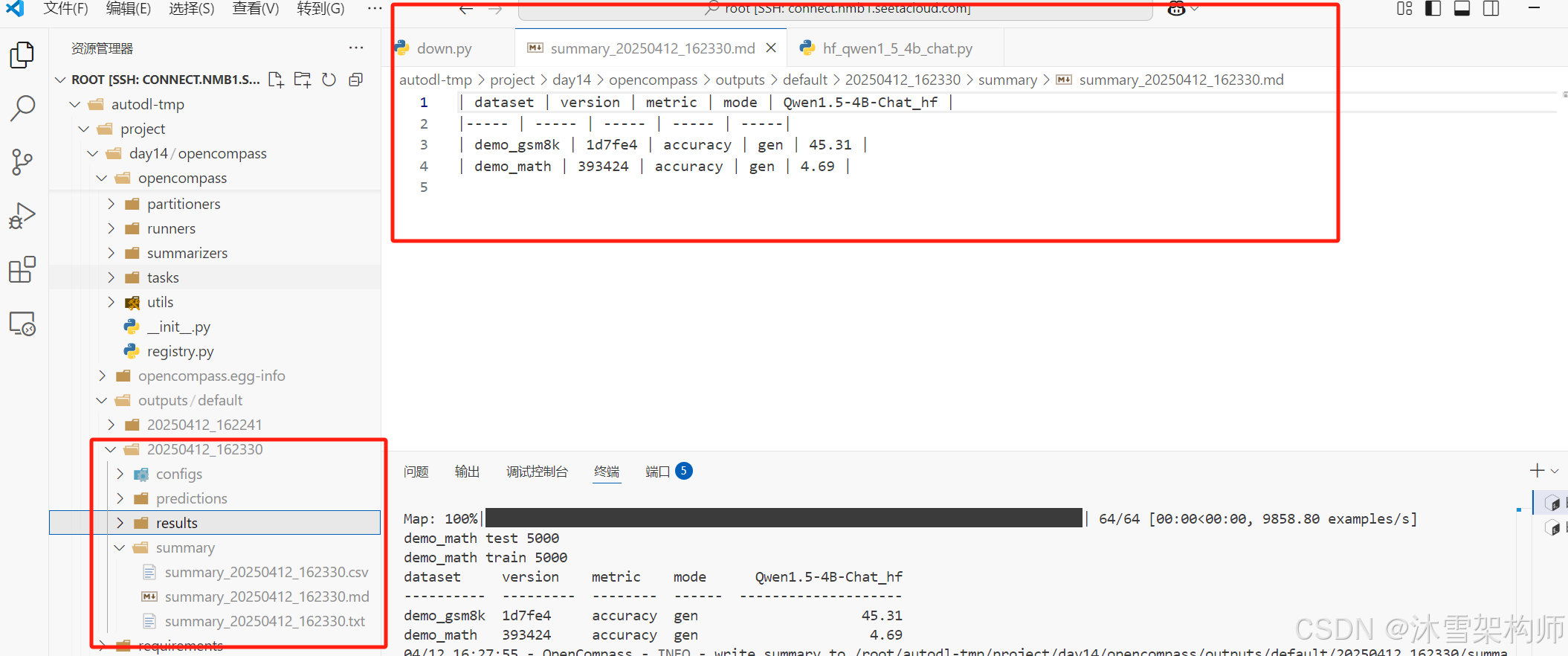
结果的精度得分是百分制,分数越高越好。
2、命令行
用户可以使用 --models 和 --datasets 结合想测试的模型和数据集。这种一次可以跑多个模型。
模型和数据集的配置文件预存于 configs/models 和 configs/datasets 中。用户可以使用 tools/list_configs.py 查看或过滤当前可用的模型和数据集配置。
# 列出所有配置
python tools/list_configs.py
# 列出与llama和mmlu相关的所有配置
python tools/list_configs.py llama mmlu(1)修改配置文件
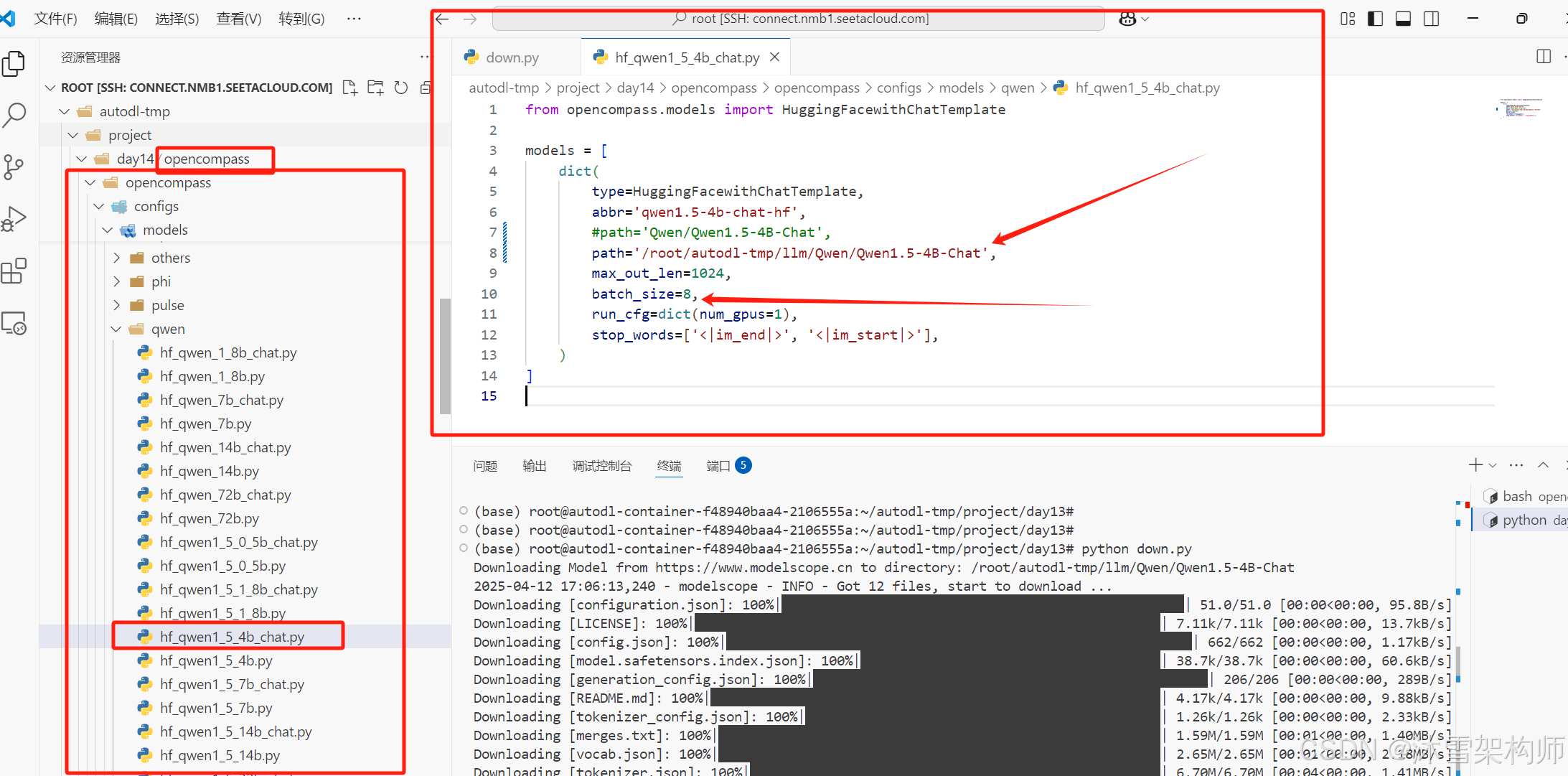
在评估之前,需要修改大模型配置文件,比如Qwen1.5-4B-Chat大模型,需要修改这个文件
opencompass/opencompass/configs/models/qwen/hf_qwen1_5_4b_chat.py。
- 将path路径改为本地正确的路径地址;
- batch_size默认为8,若GPU显存性能较差,可以调整小点;
- run_cfg中的num_gpus表示使用运行一个模型实例所需的 GPU 数量,必须小于服务器显卡数量。
我们再修改个大模型Qwen2.5-1.5B-Instruct的配置文件,便于后续测试。
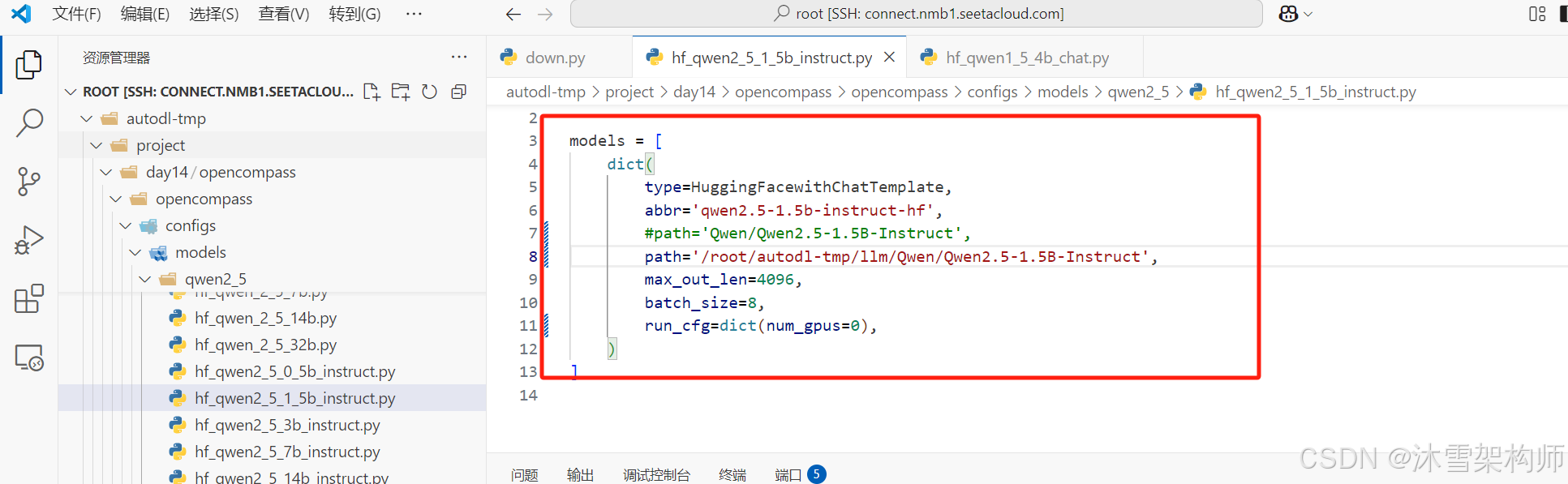
(2)找大模型名称
命令中 models 后跟着大模型的名称,该名称需要使用OpenCompass定义的名称,找的方法有有2种,可以根据配置文件的名称(不带py),也可以通过命令搜索,我们使用的是hf_qwen,则如下命令:
python tools/list_configs.py hf_qwen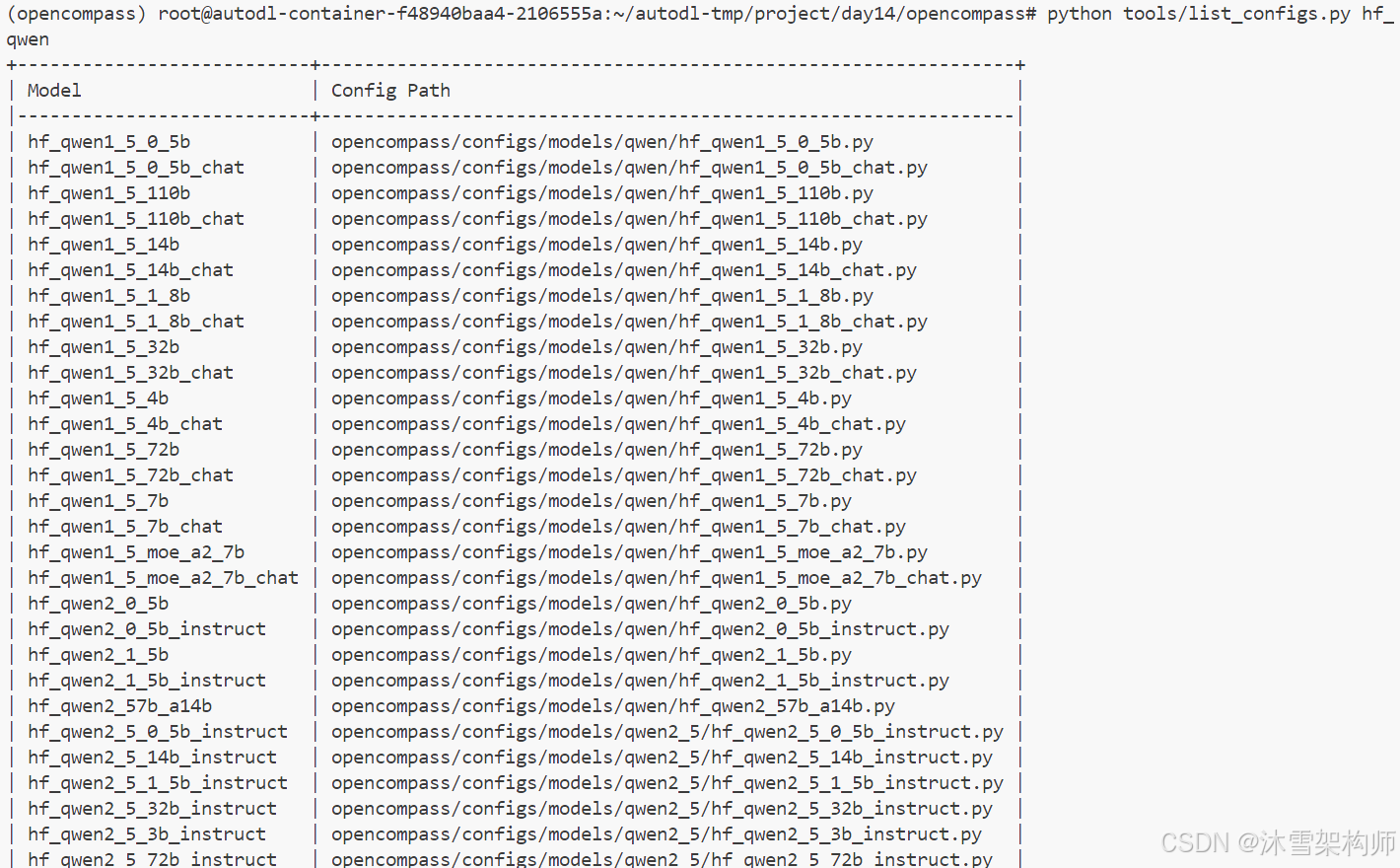
可以找到对应的模型名称:hf_qwen1_5_4b_chat 和 hf_qwen2_5_1_5b_instruct。
(3)运行评测命令
python run.py \
--models hf_qwen1_5_4b_chat hf_qwen2_5_1_5b_instruct \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--debug评估结果如下图,可以看到qwen2.5明显比1.5的评估结果要好,即便参数量较小。
3、配置文件方式
除了通过命令行配置实验外,OpenCompass 还允许用户在配置文件中编写实验的完整配置,并通过 run.py 直接运行它。配置文件是以 Python 格式组织的,并且必须包括 datasets 和 models 字段。
本次测试配置在 configs/eval_chat_demo.py 中。此配置通过 继承机制 引入所需的数据集和模型配置,并以所需格式组合 datasets 和 models 字段。
from mmengine.config import read_base
with read_base():
from .datasets.demo.demo_gsm8k_chat_gen import gsm8k_datasets
from .datasets.demo.demo_math_chat_gen import math_datasets
from .models.qwen.hf_qwen2_1_5b_instruct import models as hf_qwen2_1_5b_instruct_models
from .models.hf_internlm.hf_internlm2_chat_1_8b import models as hf_internlm2_chat_1_8b_models
datasets = gsm8k_datasets + math_datasets
models = hf_qwen2_1_5b_instruct_models + hf_internlm2_chat_1_8b_models运行任务时,我们只需将配置文件的路径传递给 run.py:
python run.py configs/eval_chat_demo.py --debug七、加速评测
OpenCompass支持在评测大语言模型时,使用 LMDeploy 作为推理加速引擎。LMDeploy 是涵盖了 LLM 和 VLM任务的全套轻量化、部署和服务解决方案,拥有卓越的推理性能。本教程将介绍如何使用 LMDeploy 加速对模型的评测。
1、安装LMDeploy
pip install lmdeploy2、调整配置文件
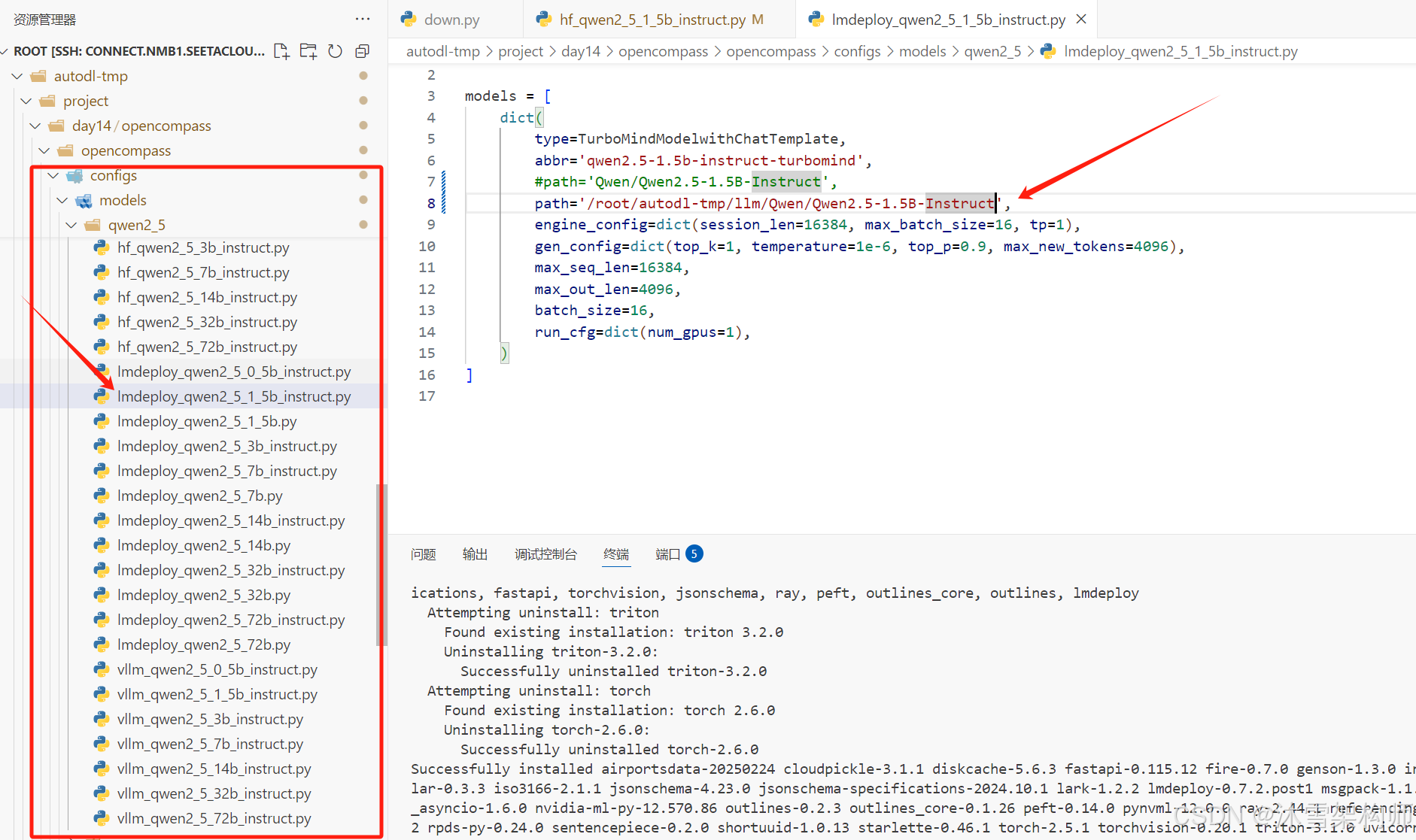
在目录configs/models下找lmdeploy_打头的大模型配置文件。比如lmdeploy_qwen2_5_1_5b_instruct.py文件。
path修改为本地大模型目录,
max_batch_size和batch_size保持一致,若显卡性能较差,可以调小些。
3、运行评测命令
python run.py \
--models lmdeploy_qwen2_5_1_5b_instruct \
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
--debug评测的速度明显快与第六章节的3种方式。
在 OpenCompass 评测过程中,默认使用 Huggingface 的 transformers 库进行推理,这是一个非常通用的方案,也可使用更高效的推理方法来加速这一过程,比如借助LMDeploy 或 vLLM 。 本章节的方法同样使用与vLLM。
八、指定数据集
上面的评测任务都是使用2个demo数据集,根据需求和场景,我们需要指定不同的数据集,比如我们使用C-Eval(中文考试题)这个数据集来评测。
1、查找数据集
OpenCompass内置的数据集都在 configs/datasets/ 目录下。也可以通过命令查询:
python tools/list_configs.py ceval
结果:
+--------------------------------+------------------------------------------------------------------------------+
| Dataset | Config Path |
|--------------------------------+------------------------------------------------------------------------------|
| ceval_clean_ppl | opencompass/configs/datasets/ceval/ceval_clean_ppl.py |
| ceval_contamination_ppl_810ec6 | opencompass/configs/datasets/contamination/ceval_contamination_ppl_810ec6.py |
| ceval_gen | opencompass/configs/datasets/ceval/ceval_gen.py |
| ceval_gen_2daf24 | opencompass/configs/datasets/ceval/ceval_gen_2daf24.py |
| ceval_gen_5f30c7 | opencompass/configs/datasets/ceval/ceval_gen_5f30c7.py |
| ceval_internal_ppl_1cd8bf | opencompass/configs/datasets/ceval/ceval_internal_ppl_1cd8bf.py |
| ceval_internal_ppl_93e5ce | opencompass/configs/datasets/ceval/ceval_internal_ppl_93e5ce.py |
| ceval_ppl | opencompass/configs/datasets/ceval/ceval_ppl.py |
| ceval_ppl_1cd8bf | opencompass/configs/datasets/ceval/ceval_ppl_1cd8bf.py |
| ceval_ppl_578f8d | opencompass/configs/datasets/ceval/ceval_ppl_578f8d.py |
| ceval_ppl_93e5ce | opencompass/configs/datasets/ceval/ceval_ppl_93e5ce.py |
| ceval_zero_shot_gen_bd40ef | opencompass/configs/datasets/ceval/ceval_zero_shot_gen_bd40ef.py |
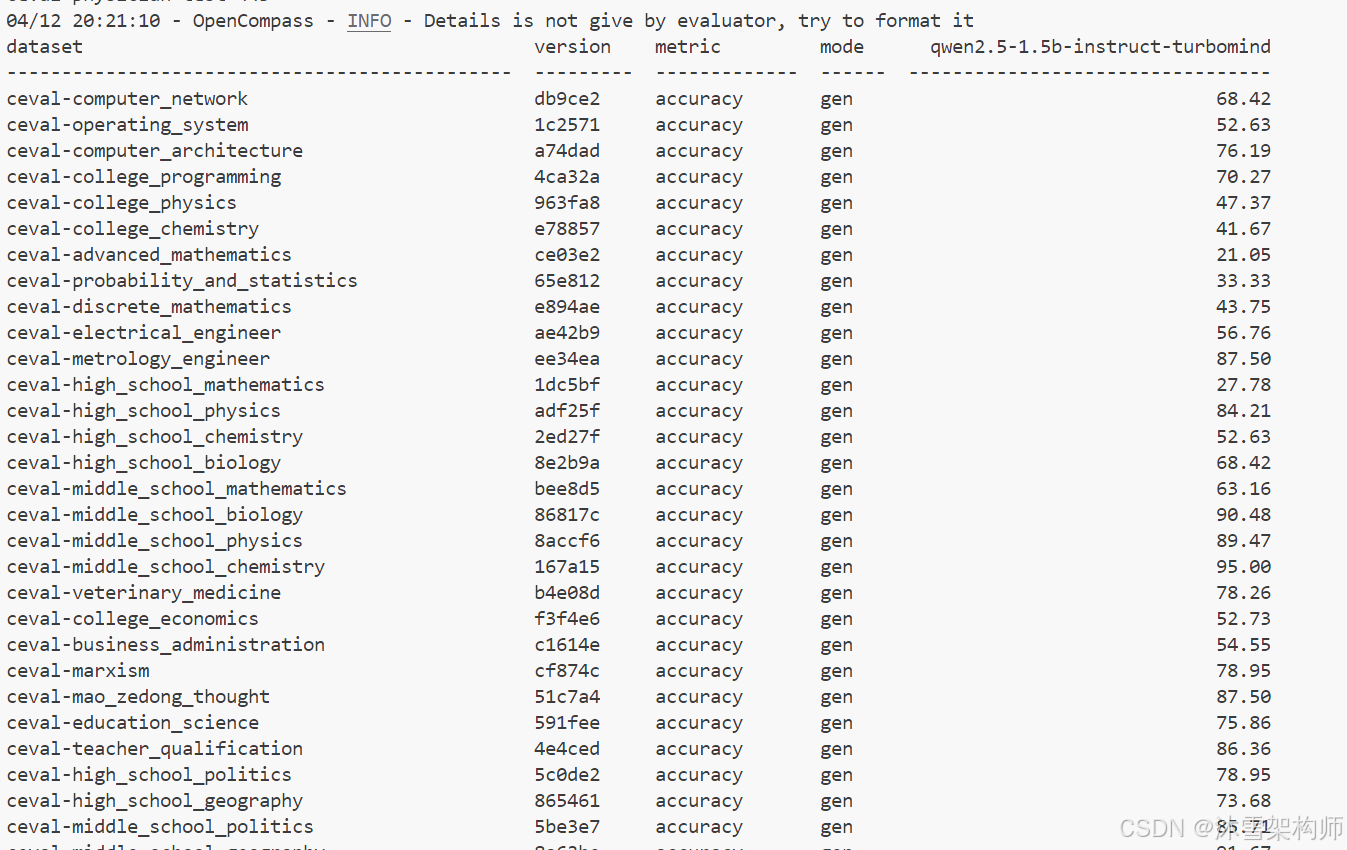
+--------------------------------+------------------------------------------------------------------------------+我们选择ceval_gen这个数据集测试。
2、运行评测命令
python run.py \
--models lmdeploy_qwen2_5_1_5b_instruct \
--datasets ceval_gen \
--debug执行结果如下:
九、自定义数据集
1、支持格式
支持 .jsonl 和 .csv 两种格式的数据集。
2、选择题 (mcq)
对于选择 (mcq) 类型的数据,默认的字段如下:
- question: 表示选择题的题干
- A, B, C, …: 使用单个大写字母表示选项,个数不限定。默认只会从 A 开始,解析连续的字母作为选项。
- answer: 表示选择题的正确答案,其值必须是上述所选用的选项之一,如 A, B, C 等。
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 .meta.json 文件中进行指定。
.jsonl 格式样例如下:
{"question": "165+833+650+615=", "A": "2258", "B": "2263", "C": "2281", "answer": "B"}
{"question": "368+959+918+653+978=", "A": "3876", "B": "3878", "C": "3880", "answer": "A"}
{"question": "776+208+589+882+571+996+515+726=", "A": "5213", "B": "5263", "C": "5383", "answer": "B"}
{"question": "803+862+815+100+409+758+262+169=", "A": "4098", "B": "4128", "C": "4178", "answer": "C"}
.csv 格式样例如下:
question,A,B,C,answer
127+545+588+620+556+199=,2632,2635,2645,B
735+603+102+335+605=,2376,2380,2410,B
506+346+920+451+910+142+659+850=,4766,4774,4784,C
504+811+870+445=,2615,2630,2750,B
3、问答题 (qa)
对于问答 (qa) 类型的数据,默认的字段如下:
- question: 表示问答题的题干
- answer: 表示问答题的正确答案。可缺失,表示该数据集无正确答案。
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 .meta.json 文件中进行指定。
.jsonl 格式样例如下:
{"question": "752+361+181+933+235+986=", "answer": "3448"}
{"question": "712+165+223+711=", "answer": "1811"}
{"question": "921+975+888+539=", "answer": "3323"}
{"question": "752+321+388+643+568+982+468+397=", "answer": "4519"}
.csv 格式样例如下:
question,answer
123+147+874+850+915+163+291+604=,3967
149+646+241+898+822+386=,3142
332+424+582+962+735+798+653+214=,4700
649+215+412+495+220+738+989+452=,4170
命令行列表
自定义数据集可直接通过命令行来调用开始评测。
python run.py \
--models hf_llama2_7b \
--custom-dataset-path xxx/test_mcq.csv \
--custom-dataset-data-type mcq \
--custom-dataset-infer-method pplpython run.py \
--models hf_llama2_7b \
--custom-dataset-path xxx/test_qa.jsonl \
--custom-dataset-data-type qa \
--custom-dataset-infer-method gen在绝大多数情况下,--custom-dataset-data-type 和 --custom-dataset-infer-method 可以省略,OpenCompass 会根据以下逻辑进行设置:
- 如果从数据集文件中可以解析出选项,如 A, B, C 等,则认定该数据集为 mcq,否则认定为 qa。
- 默认 infer_method 为 gen。