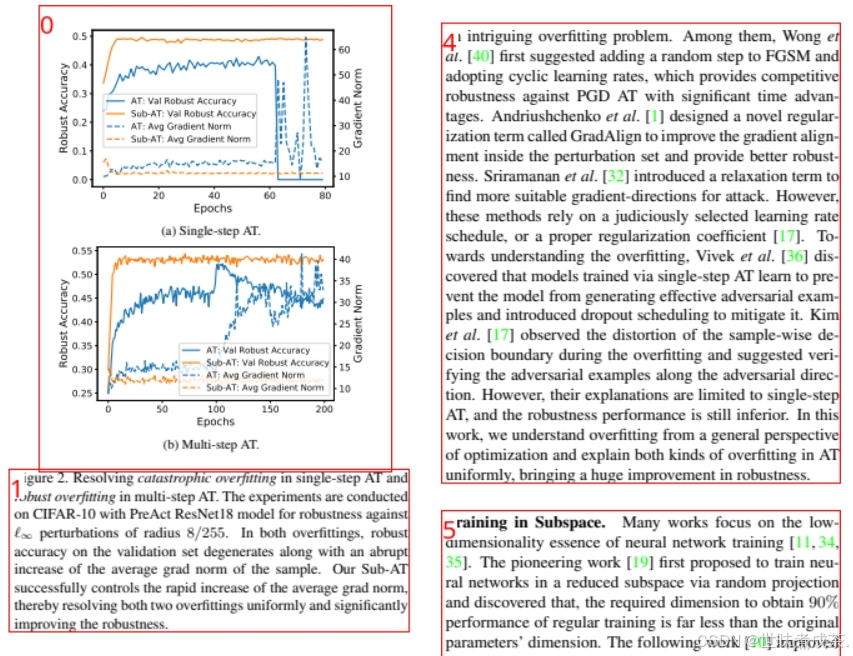
我们日常工作经常需要处理各种格式的文档,无论是PDF、图片还是其他格式,传统的文档处理方式往往效率低下,容易出错,那有没有什么工具减轻这繁重的工作量呢?今天给大家带来了~
项目简介
Surya是一个开源的OCR工具包,,它支持90多种语言的文字识别,能够轻松应对各种语言的文档处理需求。无论是英文、中文、日文还是韩文,Surya都能处理。它不仅具备强大的文字识别能力,还能进行布局分析、表格识别等高级功能,让你的文档处理变得更加简单高效。
性能特色
- 多语言支持:Surya支持90多种语言的文字识别,无论你面对的是何种语言的文档,它都能轻松应对
- 行级文本检测:Surya能够对文本进行行级检测,确保每一行文字都被准确识别和理解
- 布局分析:除了文字识别外,Surya还能对文档的布局进行深入分析,识别出表格、图片、标题等元素
- 表格识别:Surya在表格识别方面表现尤为出色,它能够清晰地识别出表格中的行、列和单元格,甚至能识别旋转的表格和复杂的布局
- 可商用与跨平台:Surya完全开源且允许商业用途,这意味着你不仅可以在个人项目中使用它,还可以将其集成到商业应用中。同时,它还支持Windows、Mac和Linux等多种操作系统,让你的文档处理不再受平台限制
- 高效处理:Surya使用了新的模型架构,大幅提升了识别精度和速度。无论是文字还是表格的处理,它都能在短时间内给出准确的结果
快速安装使用
1、pip安装
pip install surya-ocr2、Docker安装
docker pull vikparuchuri/surya
docker run -v ${path_to_host_folder_to_scan}:/path vikparuchuri/surya:latest [COMMAND] [OPTIONS] [SOURCE_PATH]3、源码安装(前提电脑已安装-git)
git clone https://github.com/VikParuchuri/surya.git
cd surya
make build项目体验展示
安装完成后,通过命令行或者Python代码来使用Surya。
比如,你想用Python代码来识别一个图片中的文字,可以这样写,如下:
from PIL import Image
from surya.recognition import RecognitionPredictor
from surya.detection import DetectionPredictor
image = Image.open(IMAGE_PATH)
langs = ["en"]
recognition_predictor = RecognitionPredictor()
detection_predictor = DetectionPredictor()
predictions = recognition_predictor([image], [langs], detection_predictor)第一次运行Surya时,模型权重会自动下载,不用担心配置复杂的问题
运行后,Surya会输出一个包含检测到的文本和边界框的JSON文件
效果图: