在《告别繁琐!用 tampermonkey 批量下载即梦 HD 图片》文章提到编写 Tampermonkey 脚本,经常被复杂的 HTML 搞得头晕眼花?一堆标签、属性,看着就心烦。
要是直接把 HTML 原封不动扔给 AI,内容太多,不仅浪费 AI 的计算资源(长度限制),还容易让 AI 搞不清楚重点。所以,我们需要先给 HTML“瘦身”,去掉那些没用的干扰项,再交给 AI 去分析。这样,AI 就能更高效地帮我们生成脚本啦!
首先,打开浏览器的“检查”功能,把 HTML 复制出来,一般只复制某个关键的 DIV 区块。
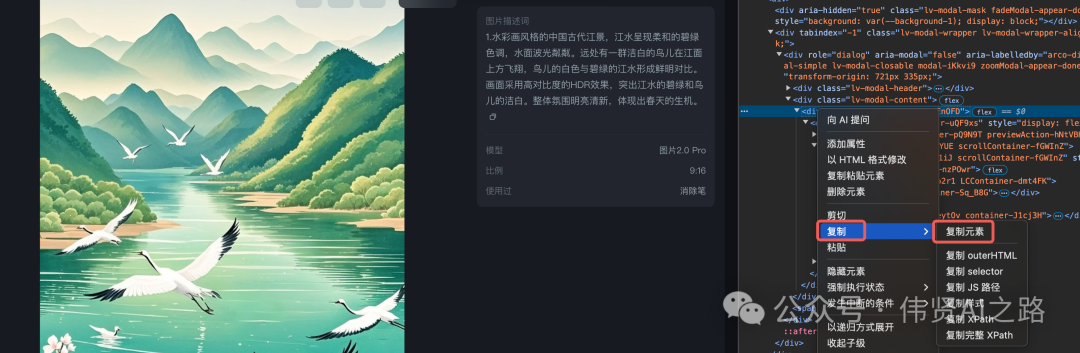
但是,复制出来的内容往往是一大坨,看着就让人崩溃。
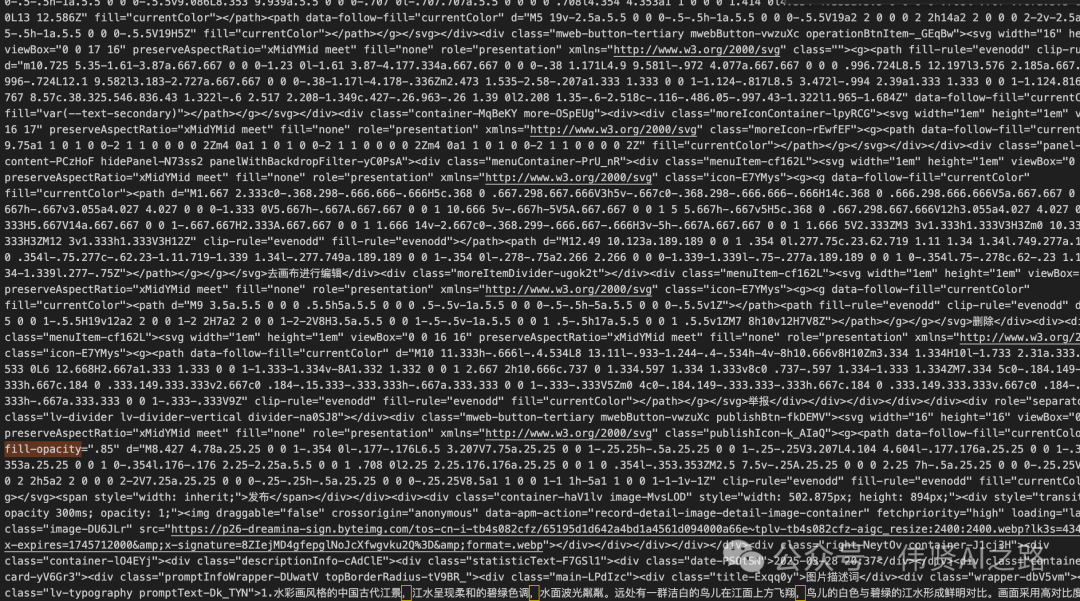
别急,细看可以发现 HTML 中的 d="" 这种路径数据,其实对 AI 分析没啥用,但又占了不少篇幅。如果手工去删除,太浪费时间了。
同时这里有个关键点要注意哦!不能把 HTML 中的 class 属性(或者其他唯一标识符,比如 id、data-* 等)给精简掉。为啥呢?因为这些属性就像是 DOM 元素的“身份证”,Tampermonkey 脚本靠它们来定位和选择目标元素。要是没了这些标识符,脚本就只能靠更通用的选择器(比如标签名、层级关系等)来寻找元素,那可就难上加难了。
所以我想让程序实现给 HTML 清理的功能,打开通义灵码的对话框,把我的需求发给通义,提示词如下:
用ptyhon程序实现去掉不必要html内容,如我从html拷贝出来后,可以快速去掉干扰项,然后我把去掉干扰项内容给到大模型分析。比如 对于 d="" 的内容清掉,可以减少内容,不影响分析。输入:<div class="optItem-xxx disabled-yyy"><svg width="1em" height="1em" viewBox="0 0 16 16" preserveAspectRatio="xMidYMid meet" fill="none" role="presentation" xmlns="http://www.w3.org/2000/svg" class=""><g><path data-follow-fill="currentColor" fill-opacity=".85" d="M1 3.342a.333.333 0 0 0-.333.333v8.667c0 .184.149.333.333.333h.667c.184 0 .333-.15.333-.333V8.675h4v3.667c0 .184.15.333.333.333H7c.184 0 .333-.15.333-.333V3.675A.333.333 0 0 0 7 3.342h-.667A.333.333 0 0 0 6 3.675v3.667H2V3.675a.333.333 0 0 0-.333-.333H1Zm9 8V4.675h2a2 2 0 0 1 2 2v2.667a2 2 0 0 1-2 2h-2ZM8.666 4.008c0-.368.299-.666.667-.666H12a3.333 3.333 0 0 1 3.333 3.333v2.667A3.333 3.333 0 0 1 12 12.675H9.333a.667.667 0 0 1-.667-.667v-8Z" clip-rule="evenodd" fill-rule="evenodd" fill="currentColor"></path></g></svg><span>超清</span></div>输出:<div class="optItem-xxx disabled-yyy"><svg width="1em" height="1em" viewBox="0 0 16 16" preserveAspectRatio="xMidYMid meet" fill="none" role="presentation" xmlns="http://www.w3.org/2000/svg" class=""><g><path data-follow-fill="currentColor" fill-opacity=".85" clip-rule="evenodd" fill-rule="evenodd" fill="currentColor"></path></g></svg><span>超清</span></div>
通义灵码反馈可以使用 BeautifulSoup 帮我们快速解析 HTML,把那些不必要的内容统统清理掉。
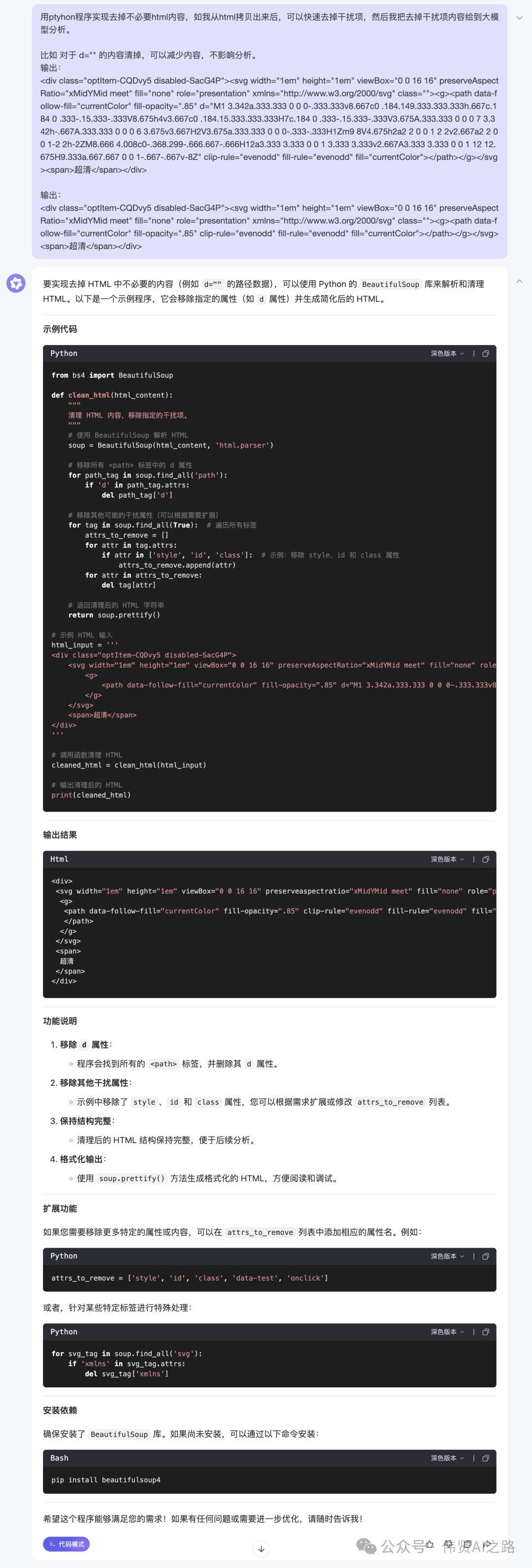
经过几轮对话,“瘦身”HTML 的代码就完成了,如下:
from bs4 import BeautifulSoupdef clean_html(html_content):"""清理 HTML 内容,移除指定的干扰项。"""# 使用 BeautifulSoup 解析 HTMLsoup = BeautifulSoup(html_content, 'html.parser')# 定义需要移除的属性列表attrs_to_remove = ['d','style','id','xmlns','viewbox','fill-opacity','width','height','preserveaspectratio', # SVG 默认值'clip-rule', # 路径填充规则'fill-rule', # 路径填充规则'opacity', # 透明度'role', # 辅助功能属性'data-follow-fill', # 冗余数据属性'fetchpriority', # 图片加载优先级'loading', # 懒加载'crossorigin' # 跨域属性]# 遍历所有标签,移除指定的属性for tag in soup.find_all(True): # 遍历所有标签for attr in attrs_to_remove:if attr in tag.attrs:del tag[attr]# 返回清理后的 HTML 字符串(不格式化)return str(soup)def read_and_clean_html(file_path):"""从指定文件读取 HTML 内容,清理后返回。"""try:# 读取文件内容with open(file_path, 'r', encoding='utf-8') as file:html_content = file.read()# 调用清理函数cleaned_html = clean_html(html_content)# 打印清理后的 HTML(不换行)print(cleaned_html)# 如果需要保存到新文件,可以使用以下代码:# with open('cleaned_html.html', 'w', encoding='utf-8') as output_file:# output_file.write(cleaned_html)except FileNotFoundError:print(f"错误:文件 '{file_path}' 未找到!")except Exception as e:print(f"发生错误:{e}")# 指定文件路径file_path = 'original_html'# 调用函数读取和清理 HTMLread_and_clean_html(file_path)
HTML 经过“瘦身”之后,就该交给 AI 大显身手啦!我把精简后的 HTML 内容给 AI,再把具体需求告诉它,比如让 AI 分析 HTML 的结构,找出关键元素,然后根据这些信息生成 Tampermonkey 脚本。具体实现可以参考《告别繁琐!用 tampermonkey 批量下载即梦 HD 图片》
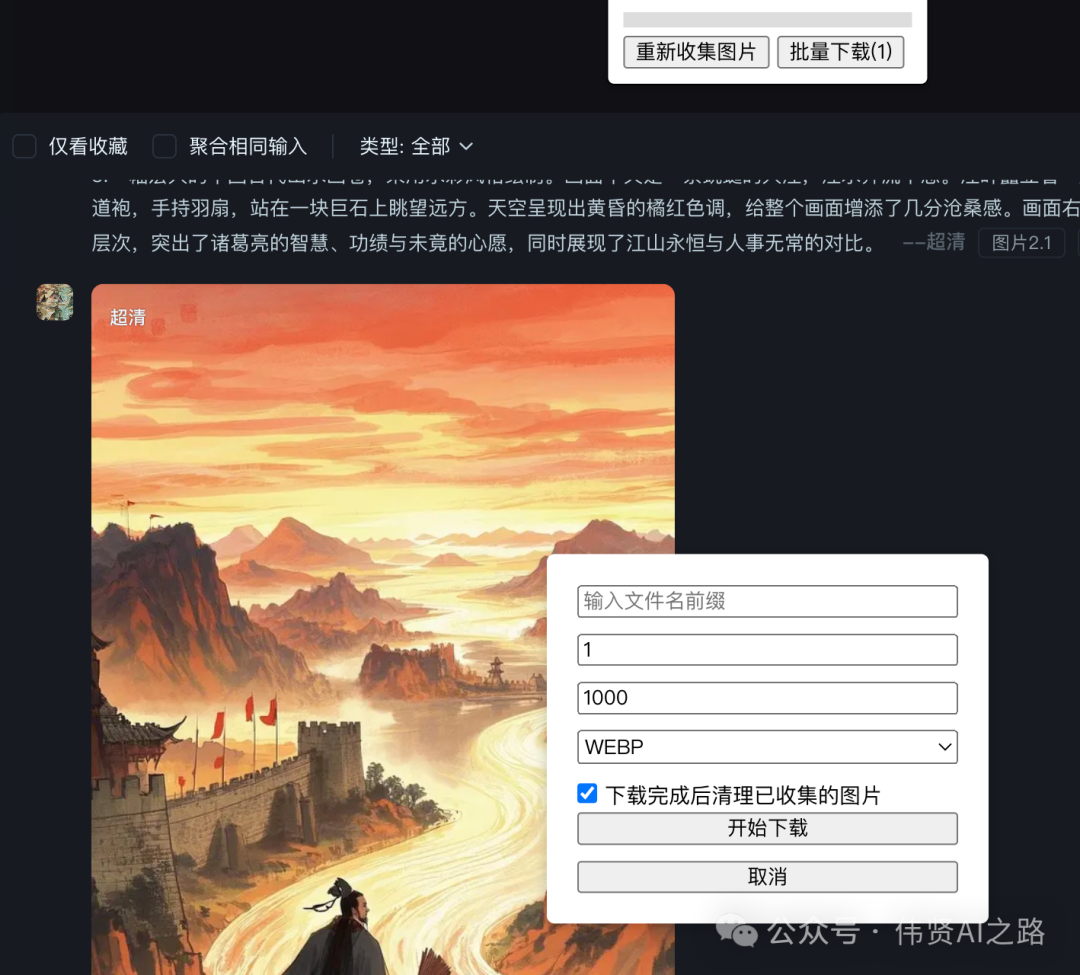
现在又可以通过Tampermonkey获取即梦的HD图片并批量下载了。具体参考文章《手把手教你如何批量自动下载即梦 AI 生图的高清图片》
相关阅读