目录
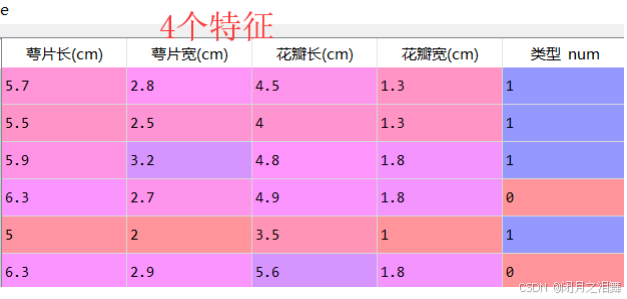
(4)利用PCA降维处理后的数据训练模型,与不使用降维的的数据选用相同的模型对比效果
一、定义
PCA 是一种
无监督学习的降维技术,通过线性变换将高维数据映射到低维空间(主成分),同时尽可能保留原始数据的关键信息(方差)。其核心是找到一组正交的主成分,使得数据在这些方向上的方差最大化,从而用更少的维度替代原始高维特征。’
降维:维度是指数据的特征数量又叫做数据的维度,减少数据的特征就是数据降维
最理想的降维效果:
减少数据维度的同时能较好地代表原始数据。
二、PCA降维的数学推导
1、内积

2、基
基是由任何两个线性无关的二维向量都可以成为一组基。

3、基变换
基变换的本质:
在保持向量空间结构(线性运算、内积等)不变的前提下,通过可逆矩阵实现同一向量 / 线性变换在不同基下的坐标表示转换。基变换不改变向量的 “本质”(如长度、夹角),仅改变其坐标表示。
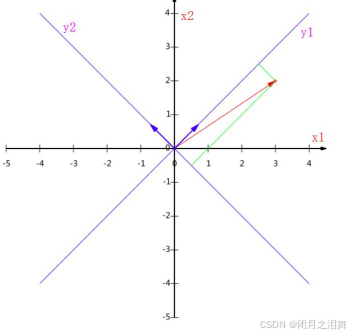
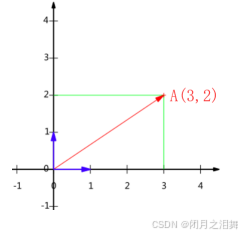
原坐标轴:基为(1,0)和(0,1)的转置
将坐标轴旋转到一个新的位置,那么(3,2)这个坐标在新的坐标系下是如何表示。
首先,我们会得到新坐标系的基,假设旋转了45度
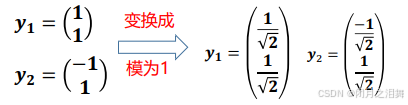
将(3,2)映射到新的基上,由于新的基的模是1,所以直接相乘就能得到(3,2)在新的的坐标系(紫色坐标系)下的坐标,如下:
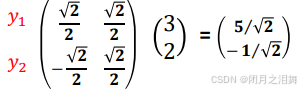
4、多个坐标转换到新的坐标系
对于m维向量,想将其变换为由R个N维向量表示的新空间:
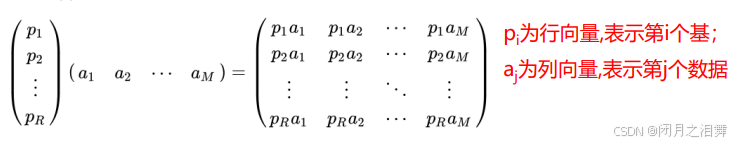
基变换的含义:
(1)两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。
(2)抽象地说,一个矩阵可以表示一种线性变换。
5、最优基的选择
知识补充:
方差:
方差是统计学中用来衡量一组数据离散程度的重要指标。以下是关于方差的详细介绍:
定义与公式

意义
- 方差反映了数据相对于平均数的离散程度。方差越大,说明数据越分散,各个数据与平均数的偏离程度越大;方差越小,说明数据越集中,各个数据与平均数的偏离程度越小。
(1)普通的二维降一维
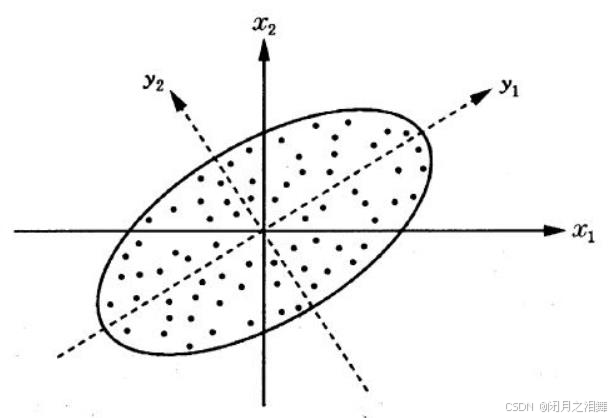
为了能够保留较多的原始数据信息,我们希望数据点投影到新的基的投影值尽可能分散,而这种分散程度可以使用数学中的方差来表述。如果是二维变一维,只需要找到一个一维基,使所有数据变换为这个基上的坐标后,方差值最大。
(2)多维数据降维
对于多次降维,以
三维数据来说,将数据降到二维,寻找的基为
方差最大
的方向,再次将数据降到一维,
必然与降到二维的基无限接近。依次寻找方差次大的基,如果两个基基本重合,
这样的一个基是没有用的,我们应该让两个基
线性无关
。【线性无关才能保留更多的原始信息】
6、协方差

利用协方差为0,选择另一组基,这组基的方向一定与第一组基
正交
。
协方差矩阵:
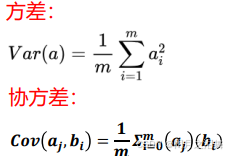

7、协方差矩阵对角化
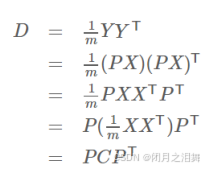
(1)含义
原始数据:X —>协方差矩阵:C
一组基按行组成的矩阵:P
基变换后的数据:Y—>协方差矩阵:D
隐含信息:Y = PX
(2)优化目标
寻找一个矩阵P,满足PC P的转置是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
协方差矩阵C对角化:

实对称矩阵:
矩阵转置等于其本身均为0
对角化:
除主对角线之外其余元素

其中的数据,从入1到入n的方差之逐渐递减。
三、PCA降维执行步骤
求解步骤:
1. 将原始数据按列组成n行m列矩阵X;
2.将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3.求出协方差矩阵:C=1/m *X*(X的转置)
4.求出协方差矩阵的特征值及对应的特征向量;
5.将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P;
6.Y=PX即为降维到k维后的数据。
四、PCA计算实例


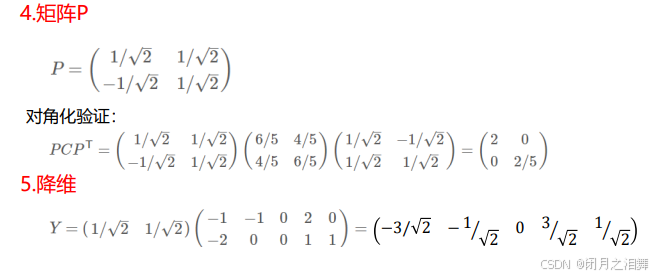
五、PCA的代码实现
1、参数API
sklearn.decomposition
.PCA
PCA
(
n_components=None
,
copy=True
,
whiten=False
,
svd_solver=’auto’
,
tol=0.0
,
iterated_power=’auto’
,
random_state=None
)
[source]
(1)参数
n_components:
这个参数可以帮我们指定希望PCA降维后的特征维度数目。简单来说:指定整数,表示要降维到的目标,【比如十维的数据,指定
n_components=5,
表示将十维数据降维到五维】如果为小数,表示累计方差百分比。
0.9
copy : 类型:bool,True或者False,缺省时默认为True。
意义:表示是否在运行算法时,将原始训练数据复制一份。若为True,则运行PCA算法后,原始训练数据的值不会有任何改变,因为是在原始数据的副本上进行运算;若为False,则运行PCA算法后,原始训练数据的值会改,因为是在原始数据上进行降维计算。【按默认为True】
whiten:判断是否进行白化。所谓白化,就是对降维后的数据的每个特征进行归一化,让方差都为1.对于PCA降维本身来说,一般不需要白化。如果你PCA降维后有后续的数据处理动作,可以考虑白化。默认值是False,即不进行白化。
svd_solver:即指定奇异值分解SVD的方法,由于特征分解是奇异值分解SVD的一个特例,一般的PCA库都是基于SVD实现的。有4个可以选择的值:{‘auto’, ‘full’, ‘arpack’, ‘randomized’}。【
按
默认设置即可】
(2)Attributes
属性
:
components_
:
array, shape (n_components, n_features)
指
表示主成分系数矩阵
explained_variance_
:降维后的各主成分的方差值。方差值越大,则说明越是重要的主成分。
explained_variance_ratio_
:降维后的各主成分的方差值占总方差值的比例,这个比例越大,则越是重要的主成分。【一般看比例即可 >90%】
(3)PCA对象的方法



2、代码调用
(1)数据预处理导入必要的库
from sklearn.decomposition import PCA
import pandas as pd
data=pd.read_csv("./data/creditcard.csv")
# 对Amount列做z标准化处理,进行脱敏操作,其中一个目的是,当数据存储在数据库上时可以保证数据的
# 安全性
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
a=data[['Amount']]#返回dataframe数据,而不是series。
data['Amount']=scaler.fit_transform(data[['Amount']])
# 删除最初的Timer列#删除无用列
data = data.drop(['Time'],axis=1)
#数据集划分
X=data.iloc[:,:-1]
y=data.iloc[:,-1](2)实例化PCA对象并对特征做降维
pca=PCA(n_components=0.90)
pca.fit(X)(3)打印特征的百分比和降维后的特征
print('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_)))
print(pca.explained_variance_ratio_)
print('PCA降维后数据')
new_X=pca.transform(X)
print(new_X)(4)利用PCA降维处理后的数据训练模型,与不使用降维的的数据选用相同的模型对比效果
选用随机森林模型训练
# 数据集切分
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test= \
train_test_split(new_X,y,test_size=0.3,random_state=2)
from sklearn.ensemble import RandomForestClassifier
rf=RandomForestClassifier(
n_estimators=100,
max_features='auto',
# max_leaf_nodes=50,
random_state=4
)
rf.fit(x_train,y_train)
from sklearn import metrics
# 自测
train_predicted=rf.predict(x_train)
print(metrics.classification_report(y_train,train_predicted))
# 测试集
test_predicted=rf.predict(x_test)
print(metrics.classification_report(y_test,test_predicted))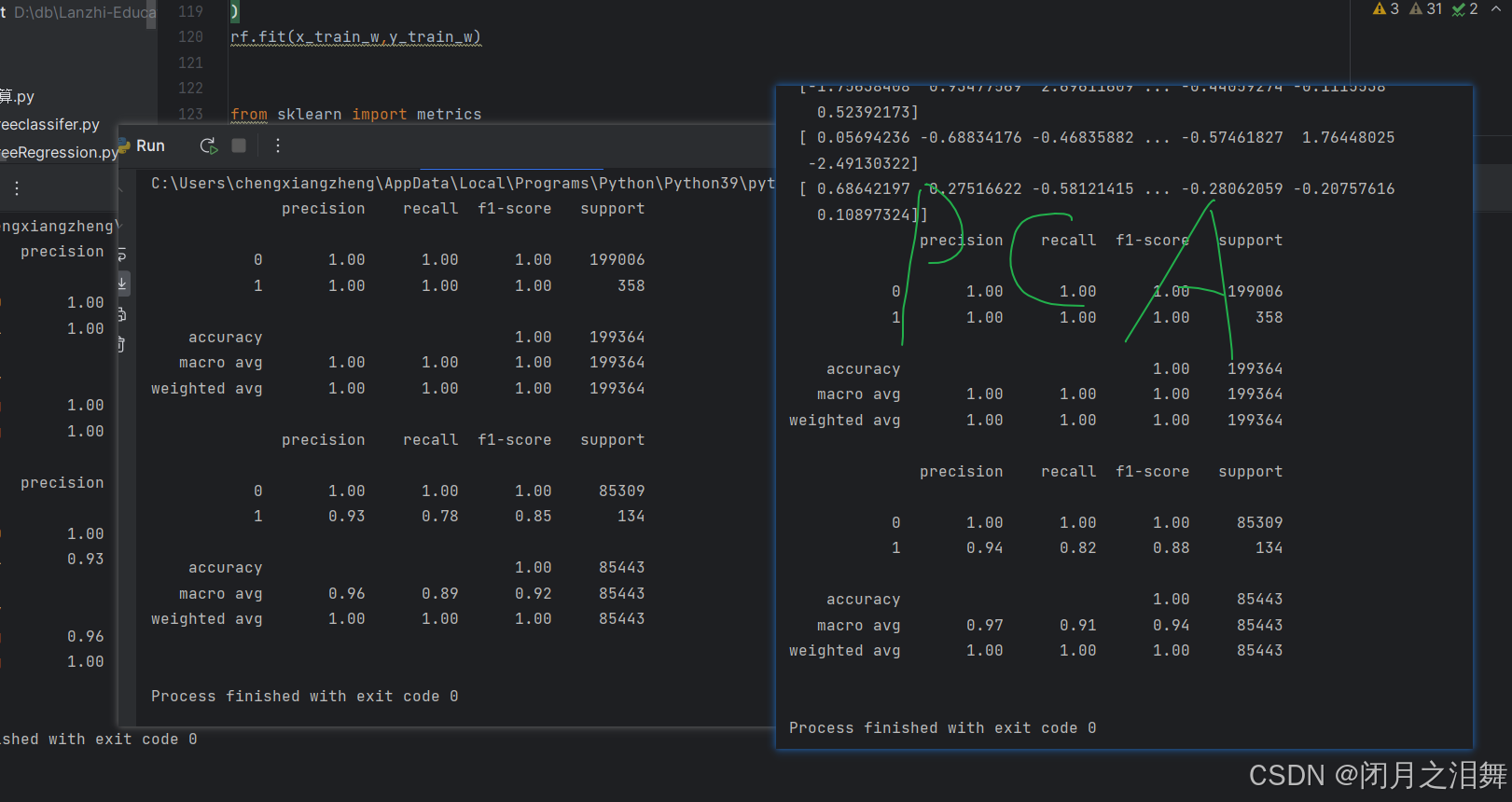
可以发现,经过PCA降维处理的数据最终的评估标准召回率、精确率都有微小的提升,但是实际案例中经过PCA降维并不能一定提升模型的效果,因为降维的过程会有数据的丢失,甚至在做完PCA降维之后模型效果还会下降。既然PCA降维并不能提升模型的效果,那我们为什么还要做PCA呢,PCA降维可以减少数据的数量,在训练使可以减少无用特征浪费的时间,在数据量超级大时,可以帮助提升训练效率。
六、PCA优劣势
优点
- 去除冗余:能识别并去除数据中的冗余信息,实现数据压缩,提升存储和处理效率。
- 简化计算:降低数据维度,大幅减少机器学习算法的计算量,提高模型训练和预测速度。
- 利于可视化:将高维数据映射到低维空间,便于直观展示数据分布和样本间关系。
缺点
- 信息损失:对于具有非线性特征的数据,可能无法准确捕捉内在结构,导致重要信息丢失。
- 解释性弱:降维后的主成分通常不具有明确的实际意义,难以解释其代表的信息。
- 数据限制:假设数据服从高斯分布,对于非高斯分布的数据,降维效果可能不佳。