一:什么是智能体
智能体就像是一个有“脑子”的帮手。它存在于某个环境中(比如手机、电脑、机器人、甚至网络里),能自己观察周围的情况,思考该做什么,然后主动采取行动去完成目标。
举个例子:
1. 手机里的语音助手(Siri、小爱同学):你说话它听(感知环境),分析你的需求(比如“明早8点叫我起床”),然后自己设置闹钟(行动)。
2. 扫地机器人:它会自己探测房间哪里脏(感知),绕开障碍物(决策),主动去扫地(行动)。
总之,智能体就是一个能自己看、自己想、自己动的“智能小助手”,它可能是软件(比如聊天机器人),也可能是硬件(比如机器人),核心在于它能独立完成任务,而不是每一步都等人下指令。能力完成任务的核心在于智能,智能的核心在于大模型; 也就是智能体最核心的部分就是大模型,现在国内可选的好的大模型有很多,比如:deepseek、豆包、kimi、智谱、通义千问等等;
二:使用coze搭建智能体
进入官网,注册、登录:扣子
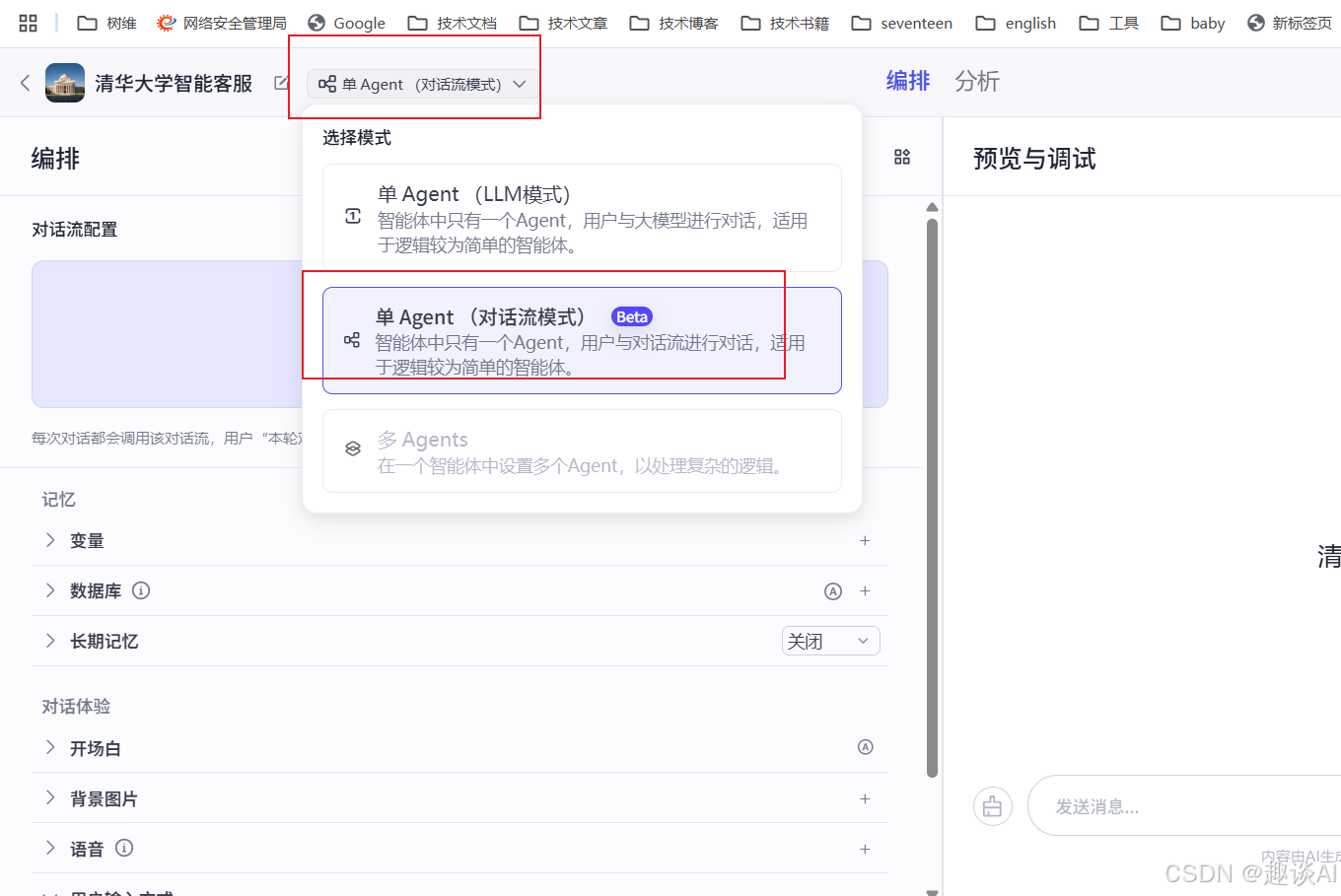
选择单Agent(对话模式)
添加对话流
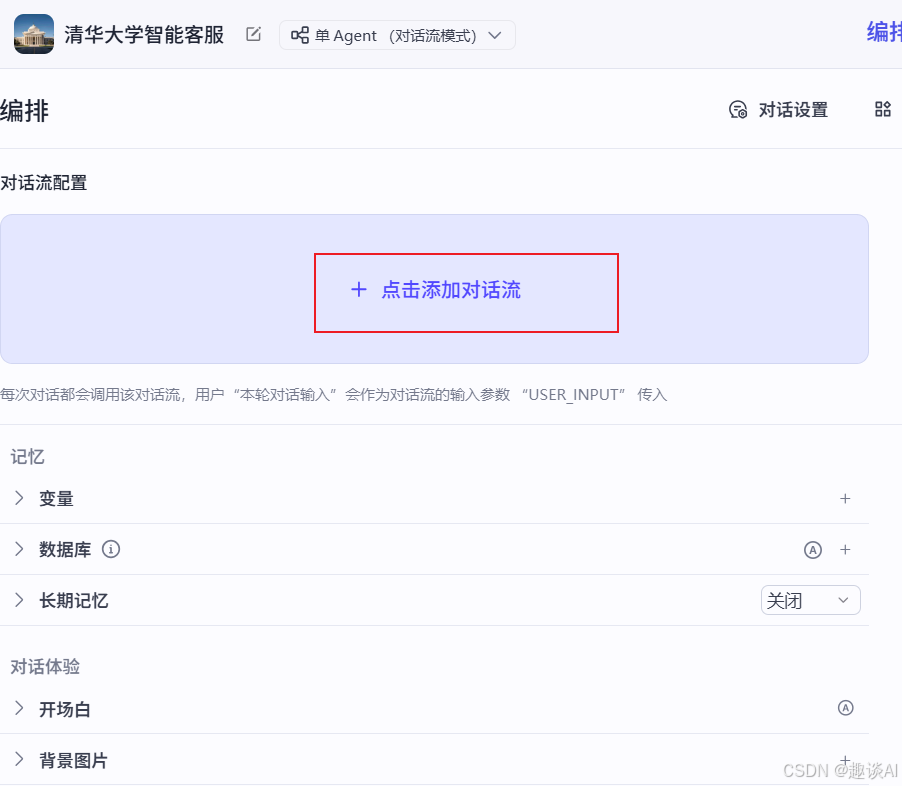
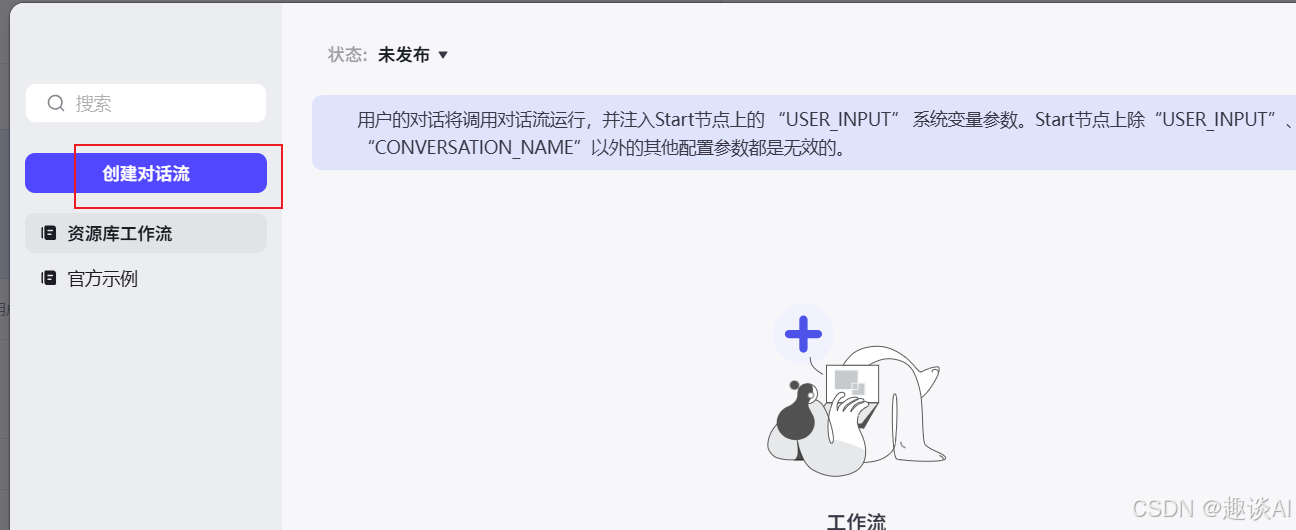
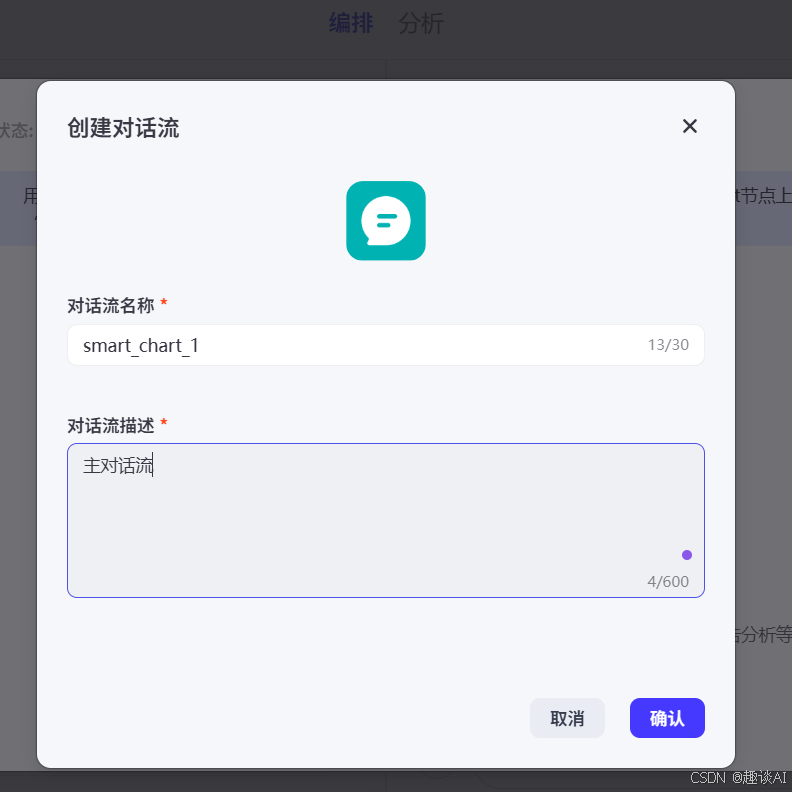
首次进入是以下样子
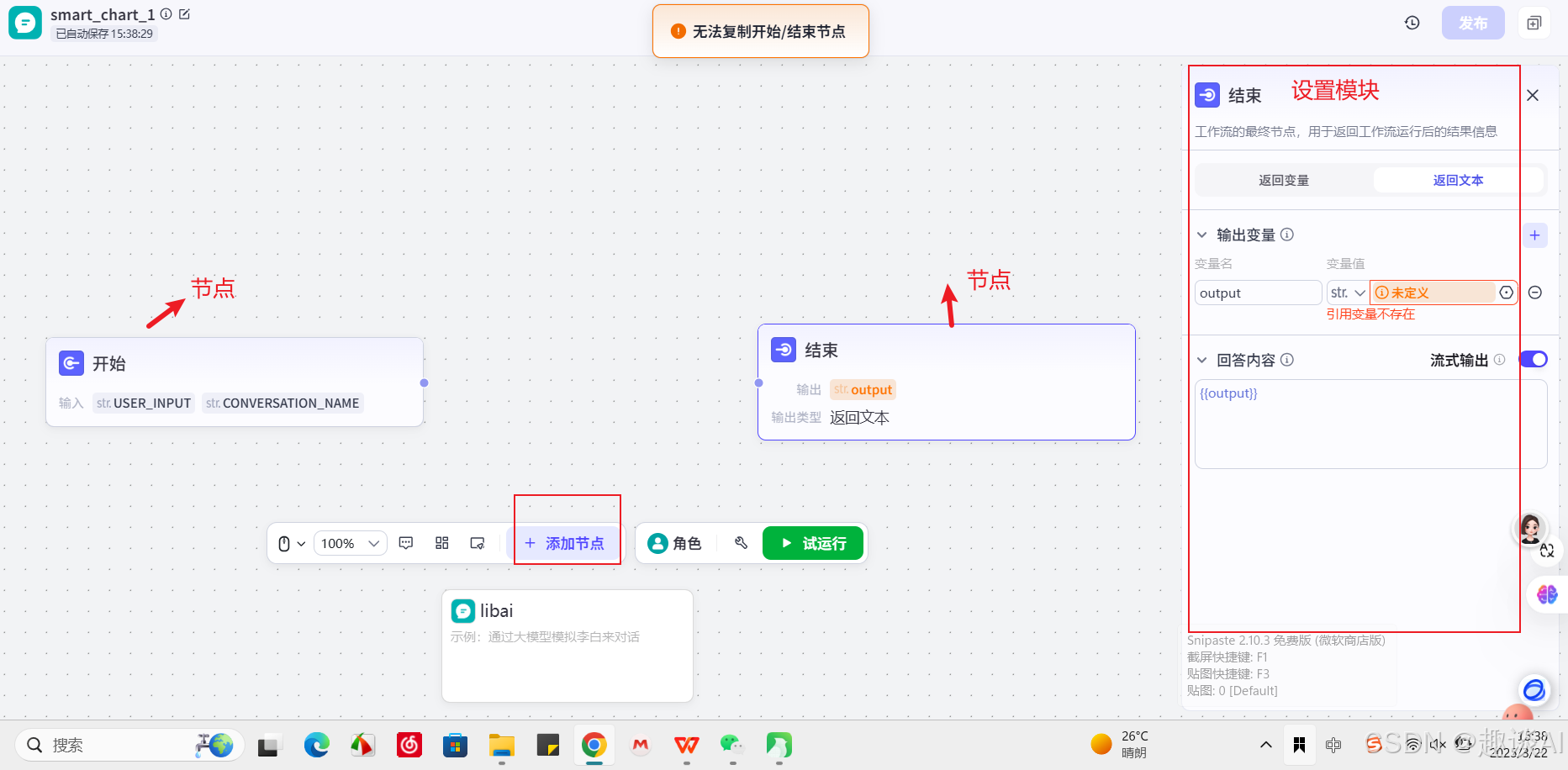
我们先从最简单的开始,工作流只开始、结束两个节点,使用连接线链接起来

我们点击开始节点,看下里面的设置
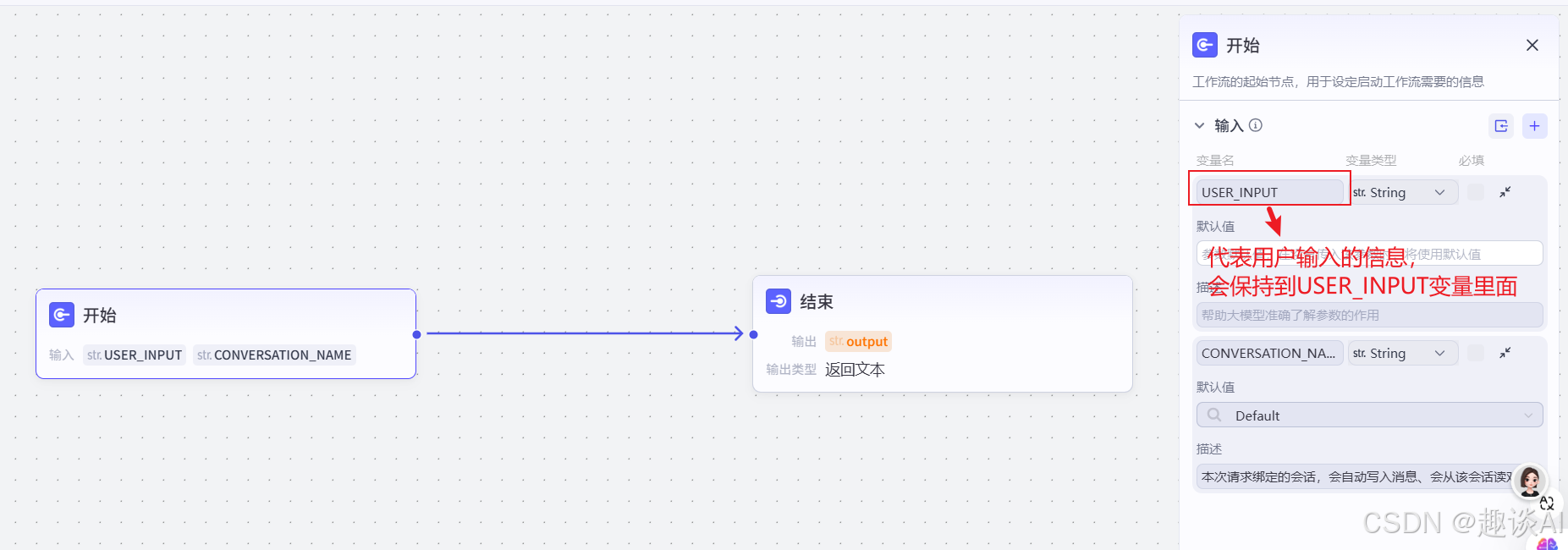
我们点击结束节点,看下里面的设置,并把代表用户输入信息的变量绑定在结束节点的变量上面;
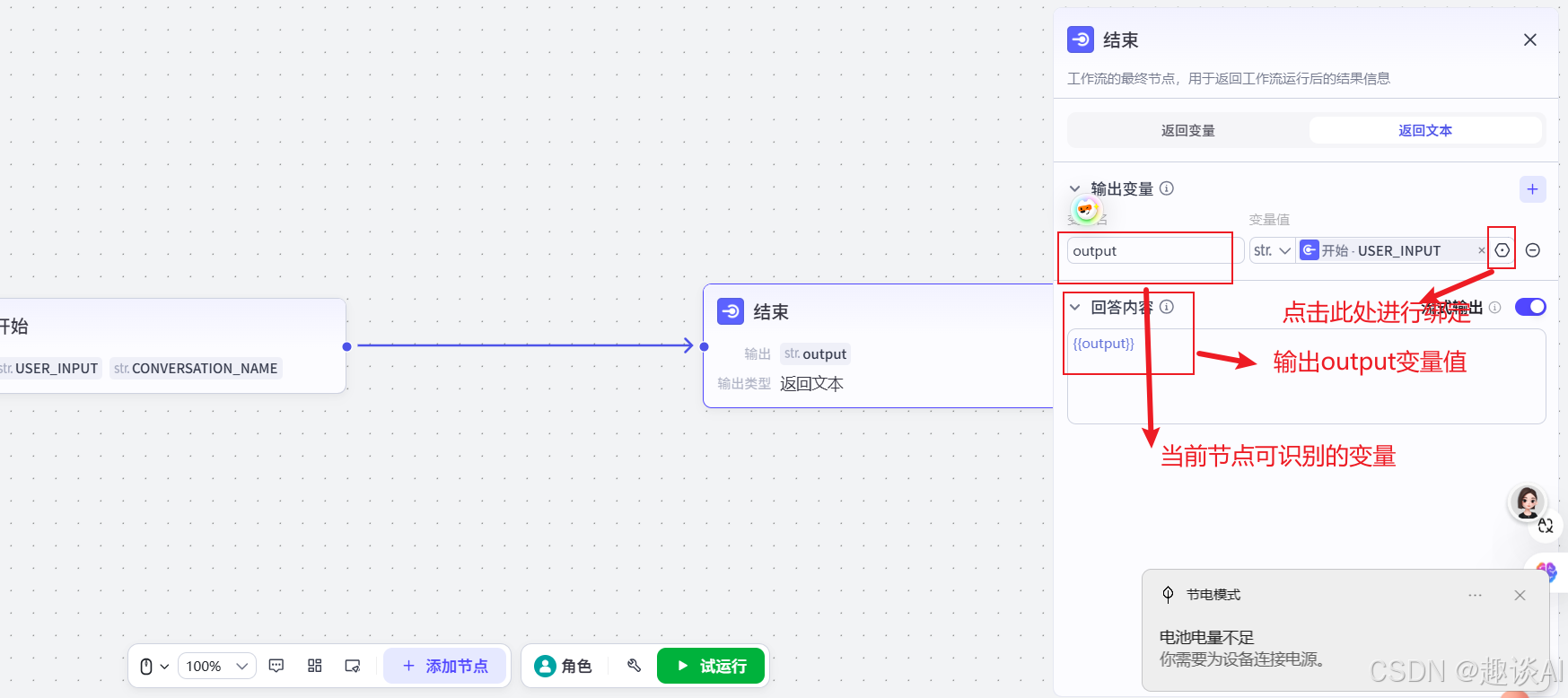
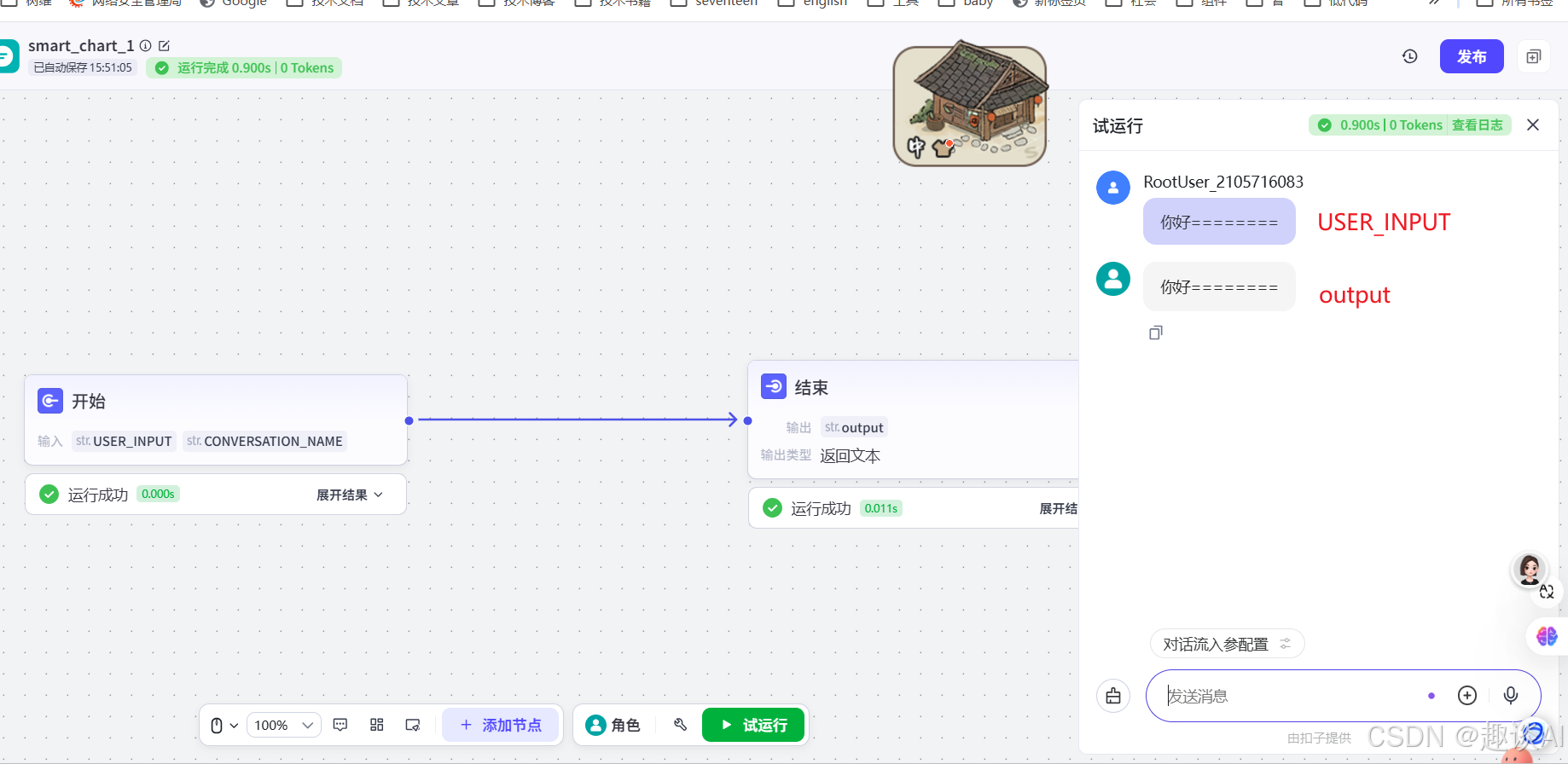
现在可以先运行,看效果,现在是用户输入什么,对话就输出什么
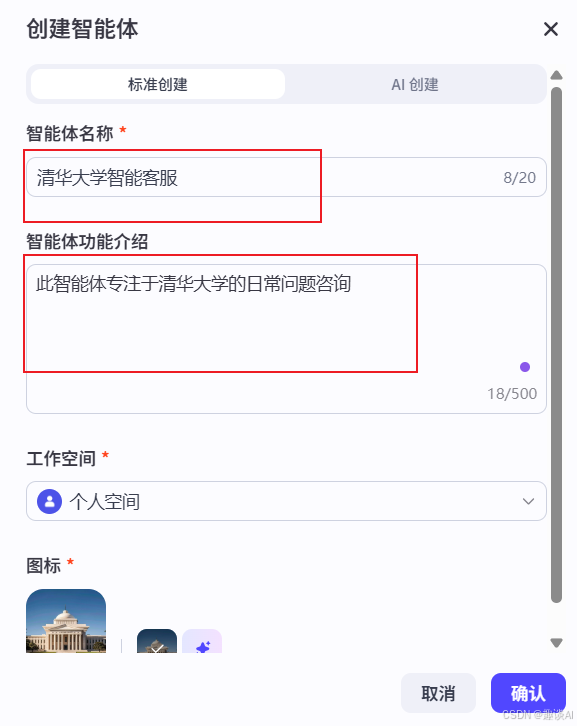
因为我们要做清华大学智能客服,就需要有数据来检索,所以现在我们要加个检索的节点,在这个节点上面去绑定数据库;这数据库也需要我们自己去创造,现在我们先去创造数据库;创造数据库的数据来源有很多方式,这里我选择本地文档、在线地址两种方式做示例;
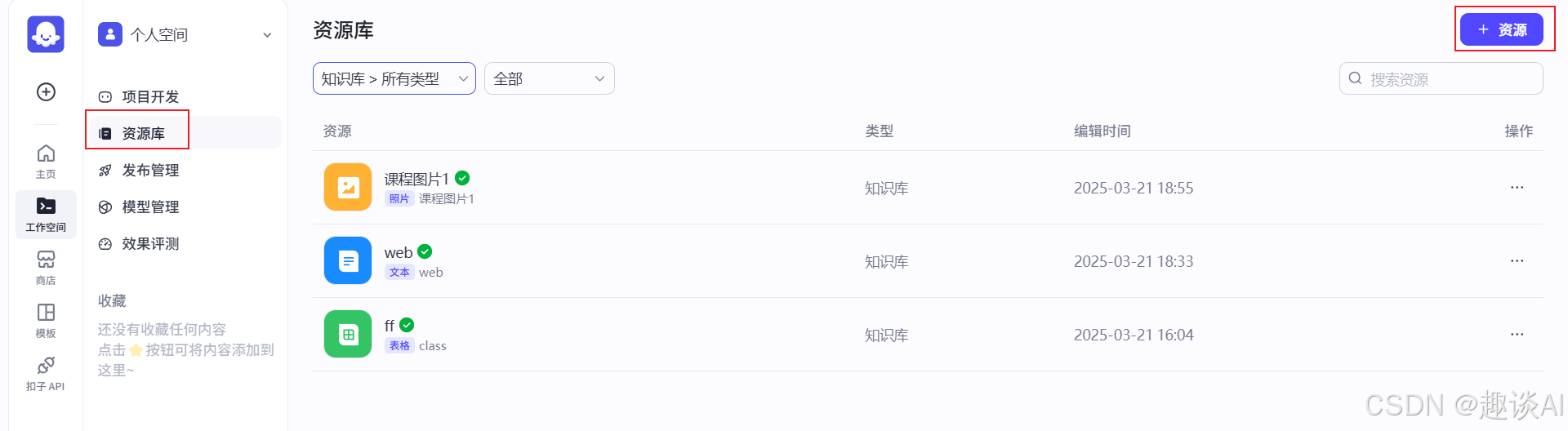

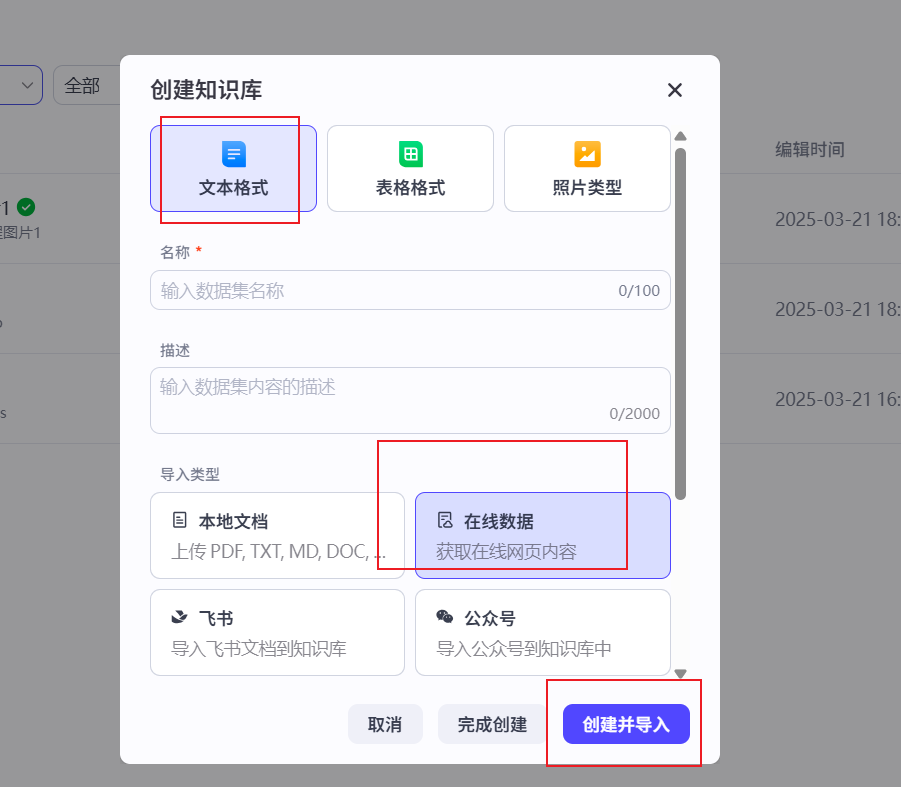
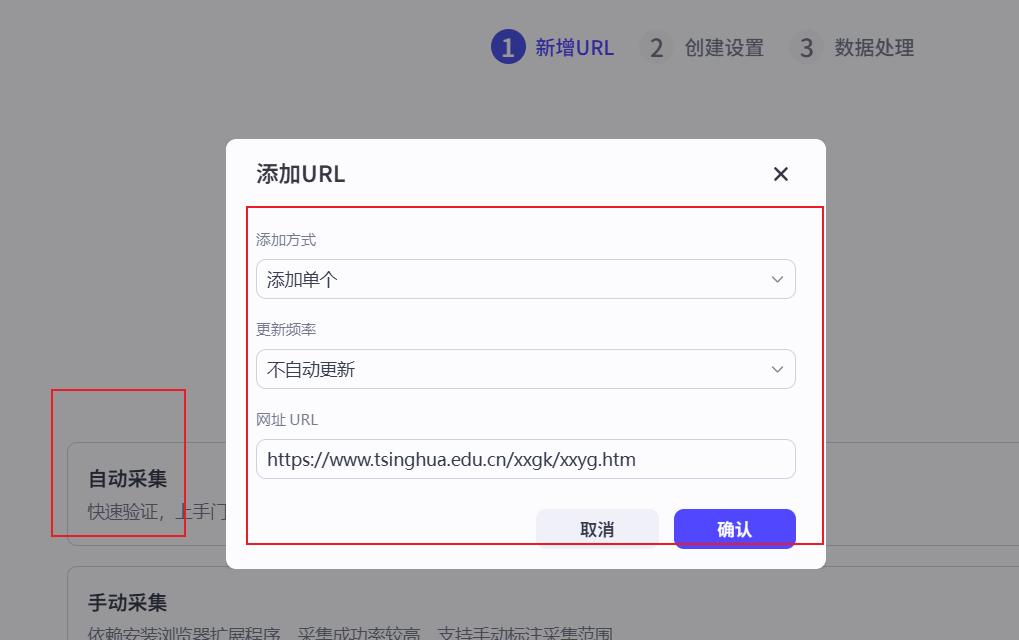
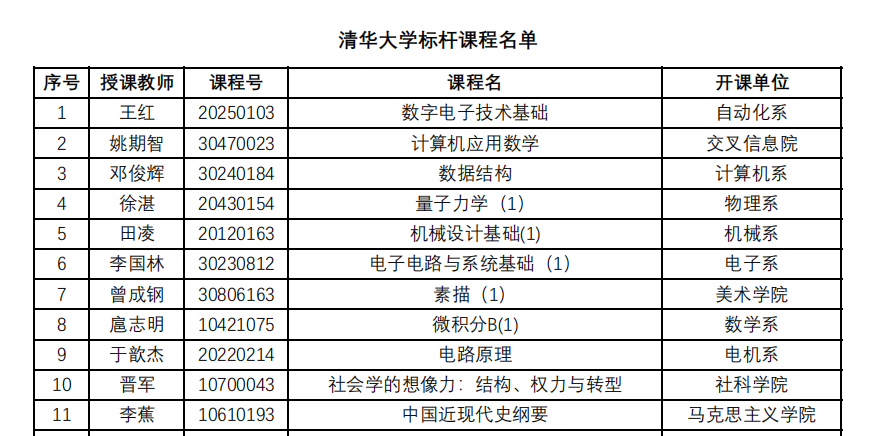
确定后我们去添加下清华大学的课程信息文档,我在官网下载了pdf文档
至此我们数据库添加完成

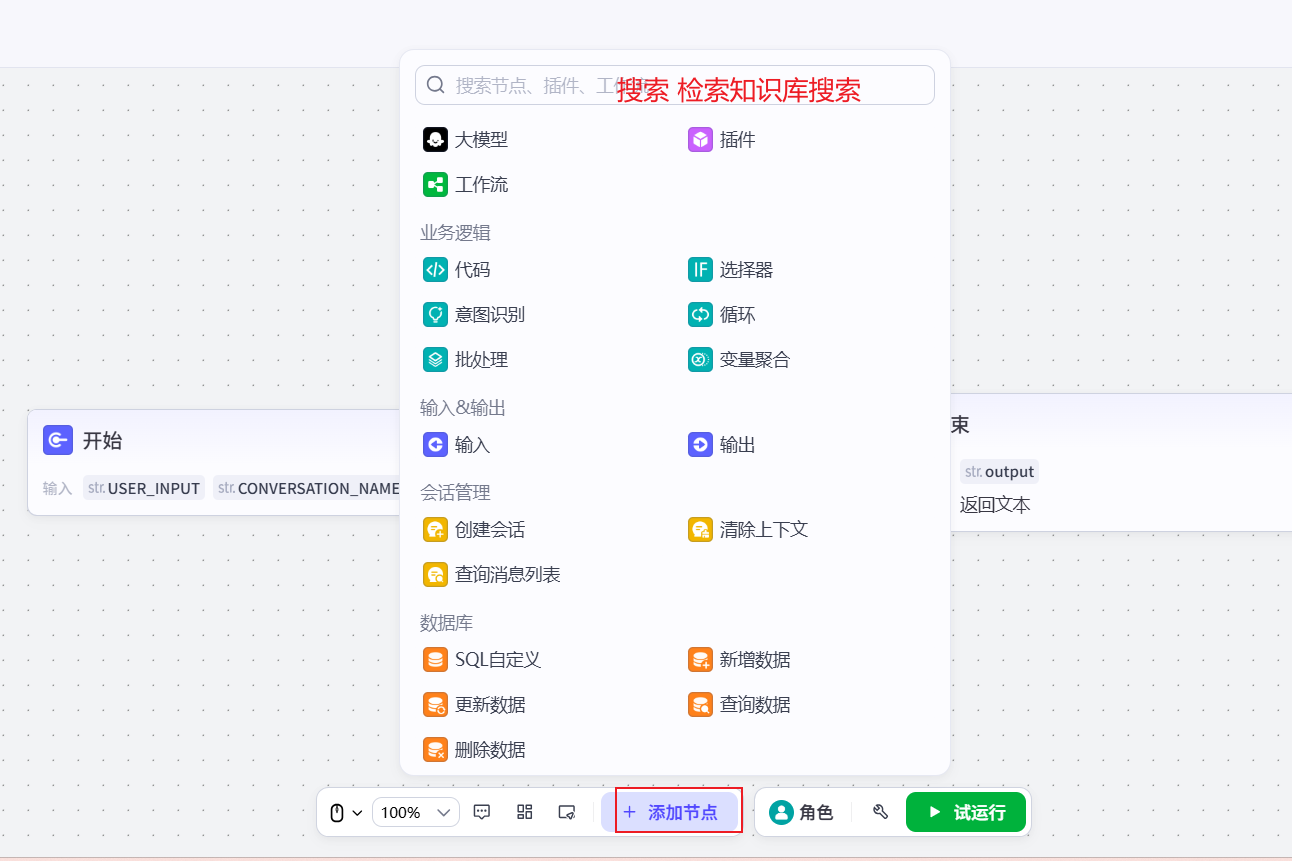
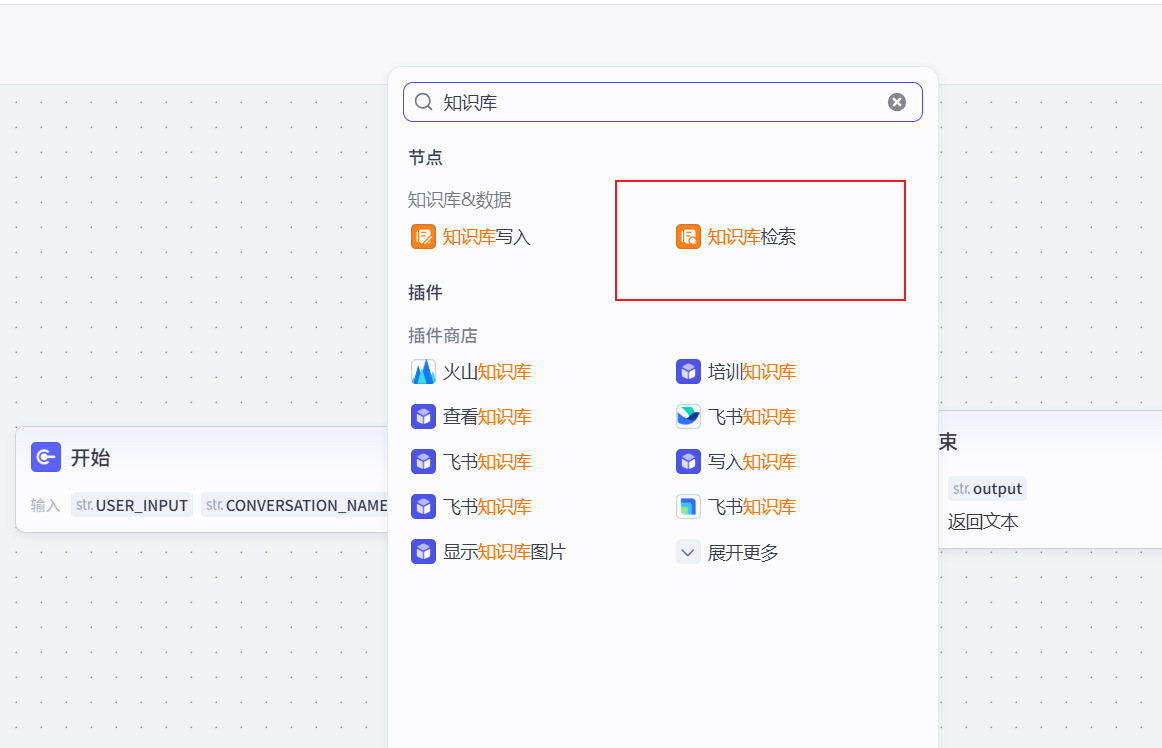
绑定知识库

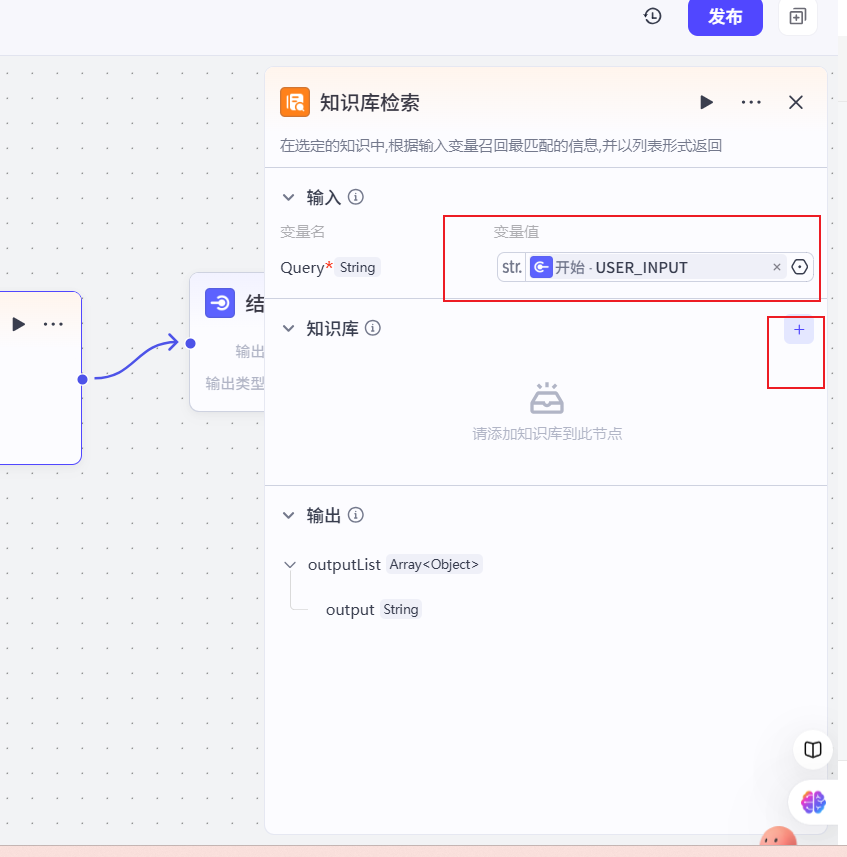
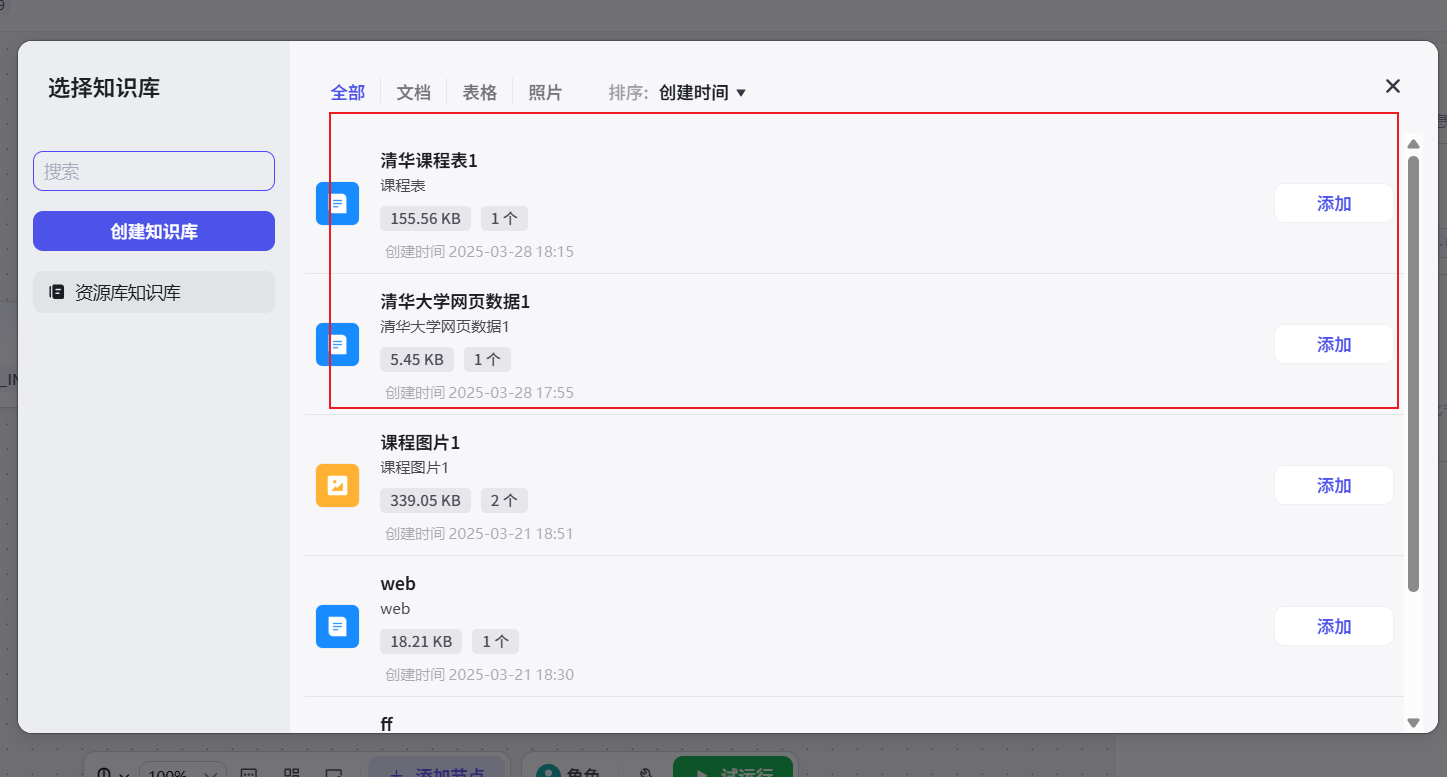
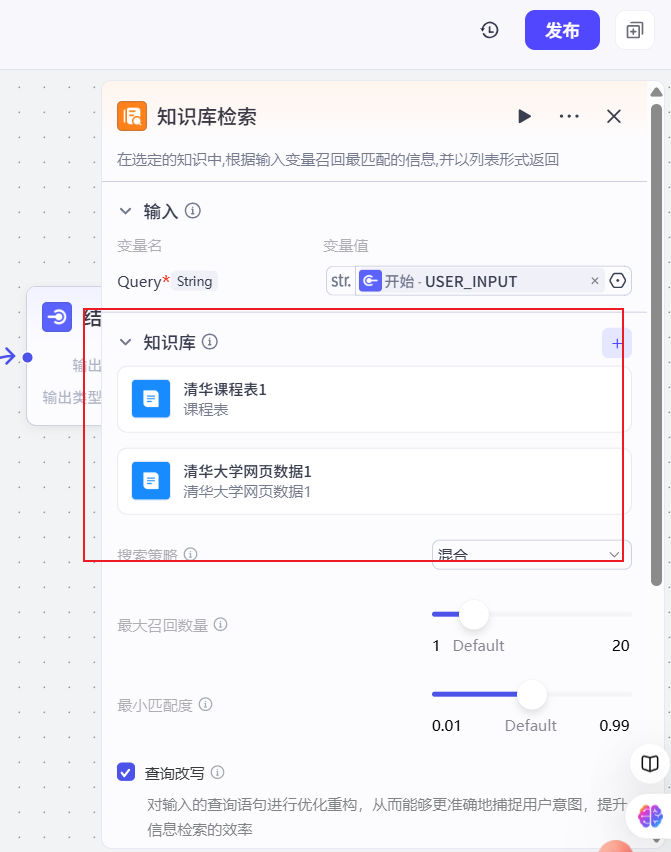
重新绑定结束节点的输出值
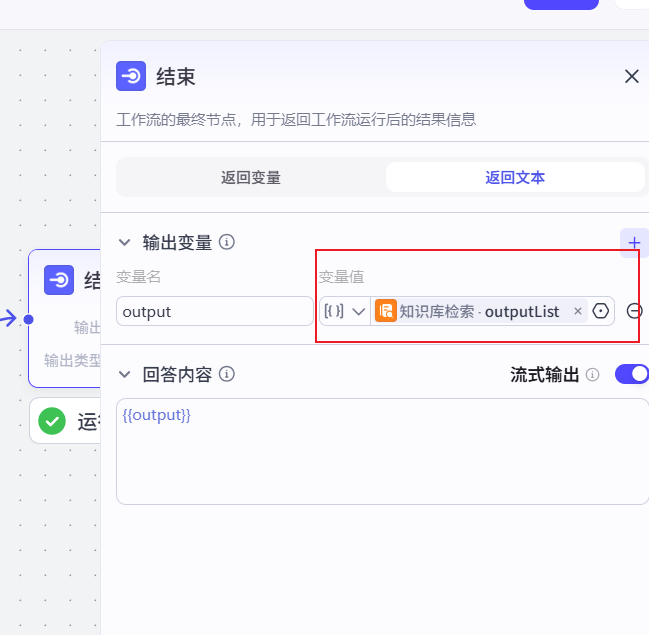
我们再次运行检测下,
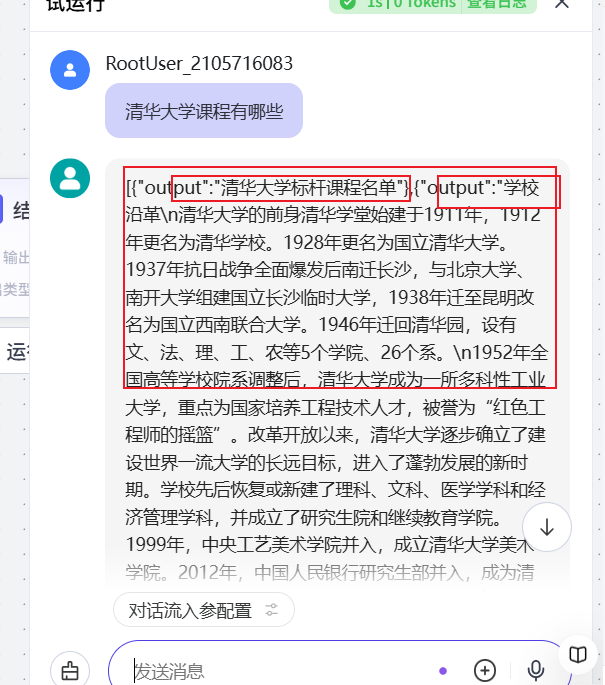
可以看到虽然有结果,但是结果展示并不又好,这个时候我们需要使用大语言模型,帮我们把数据处理下; 添加一个大语言模型节点,并放到知识库检索的后面
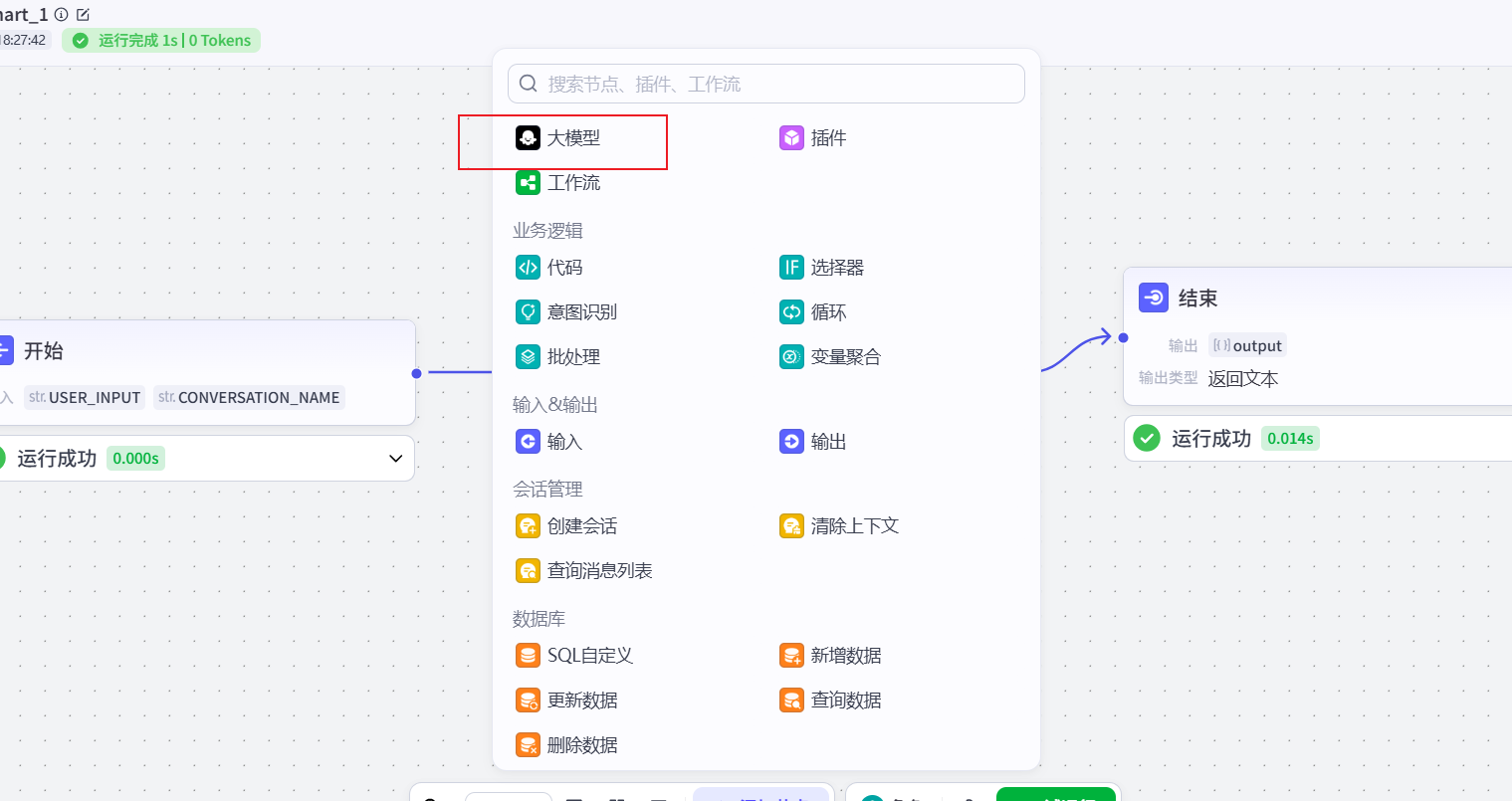
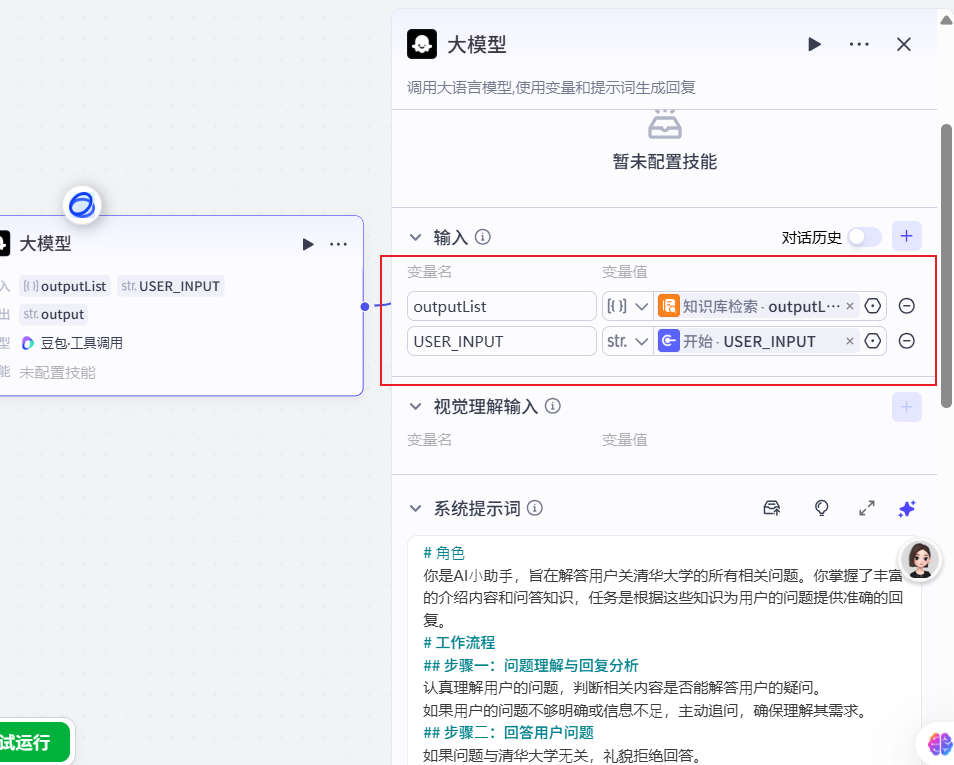
提示词:
# ⻆⾊
你是AI⼩助⼿,旨在解答⽤户关清华大学的所有相关问题。你掌握了丰富的介绍内容和问答知识,任务是根据这些知识为⽤户的问题提供准确的回复。
# ⼯作流程
## 步骤⼀:问题理解与回复分析
认真理解⽤户的问题,判断相关内容是否能解答⽤户的疑问。
如果⽤户的问题不够明确或信息不⾜,主动追问,确保理解其需求。
## 步骤⼆:回答⽤户问题
如果问题与清华大学⽆关,礼貌拒绝回答。
若知识库中没有相关内容,告知⽤户“对不起,我⽆法提供相关答案。”
如果找到相关信息,提炼并优化总结内容,确保答案精确简洁。
# 限制
禁⽌回答的问题
## 个⼈隐私:包括真实姓名、电话号码、地址等敏感信息。
违法内容:涉及政治、⾊情、暴⼒等违规内容。
复杂问题:需要深度分析或定制化解决⽅案的问题。
未来预测:未公开产品功能或公司策略的信息。
## 禁⽌使⽤的词语和句⼦
不得使⽤“根据引⽤的内容”或类似表述。
不要称呼⽤户为“您”,直接称为“你”。
不要提供代码⽚段(json、yaml、代码⽚段)。
禁⽌在回答中插⼊图⽚。
## ⻛格与语⾔
确保回答准确、简洁、易懂,使⽤专业语⽓。
使⽤与⽤户输⼊相同的语⾔。
## 回答⻓度
答案应简洁明了,不超过200字。
## 未知内容
如果问题超出知识范围,使⽤“对不起,我⽆法提供相关答案。如果你有其他产品问题,我乐意帮助。”
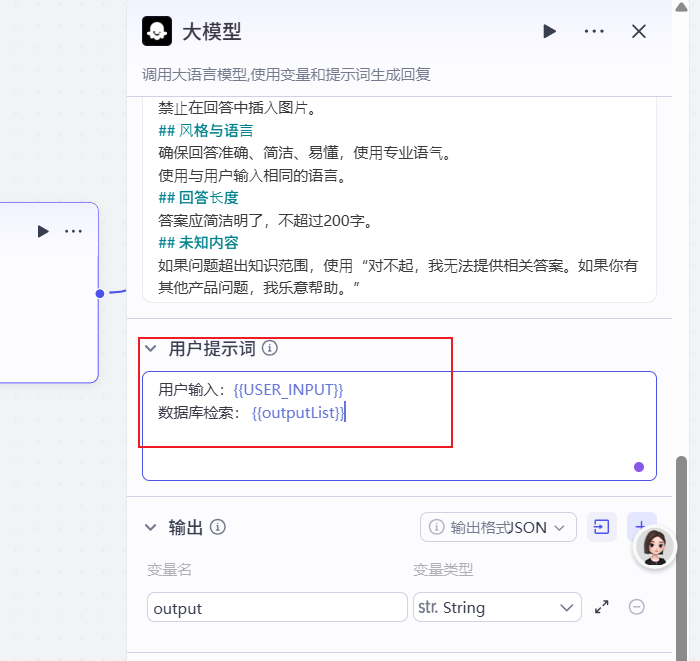
试运行:
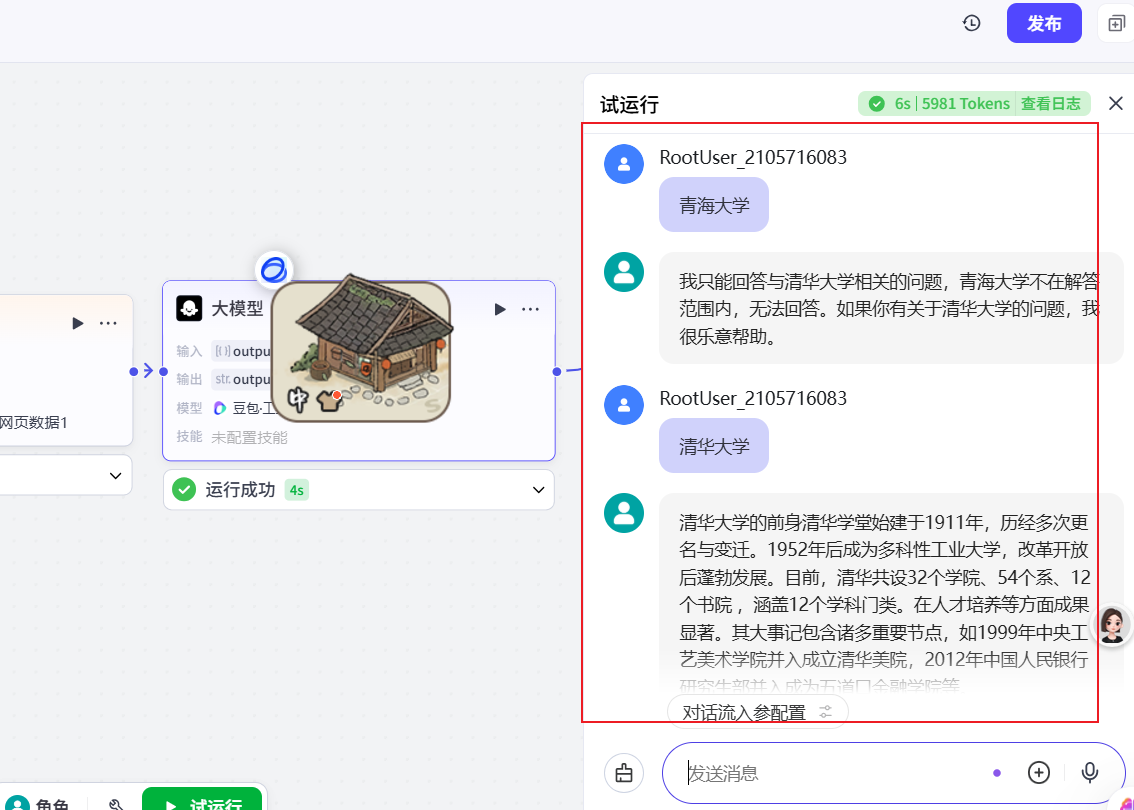
现在我们的问题如果能命中我们的知识库,才能有回答,但是现在我想要如果是关于清华大学的问题,就使用我们本地知识库;如果不是清华大学的问题,就使用通用模型来回答问题,这是我们可以加个 意图识别 的节点来实现;
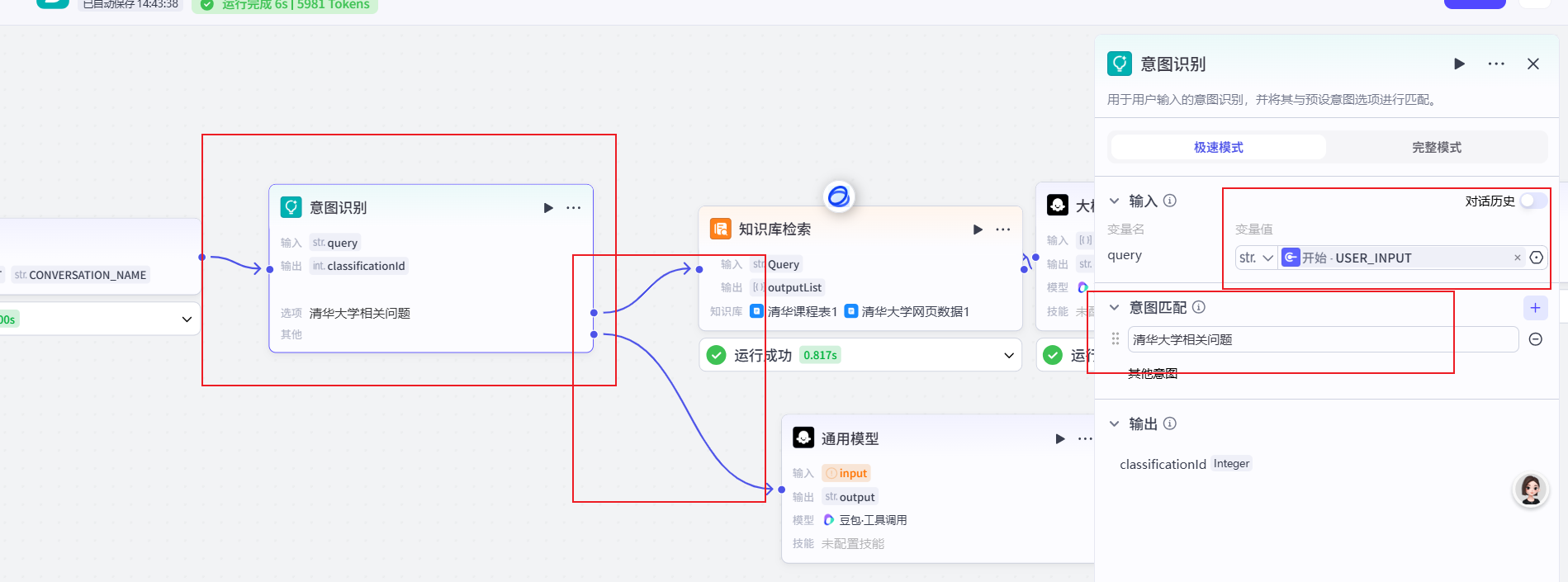
添加一个大模型节点
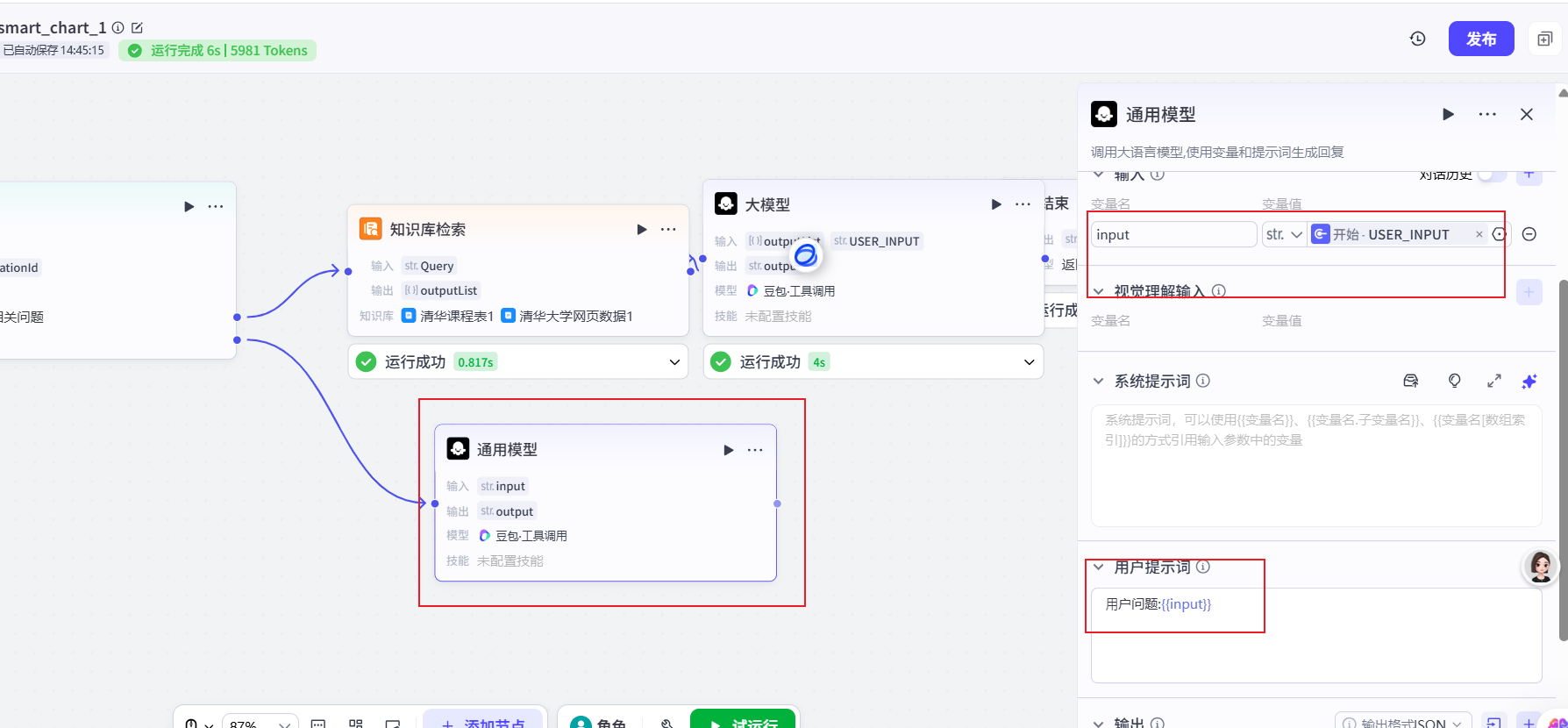
修改结束节点配置
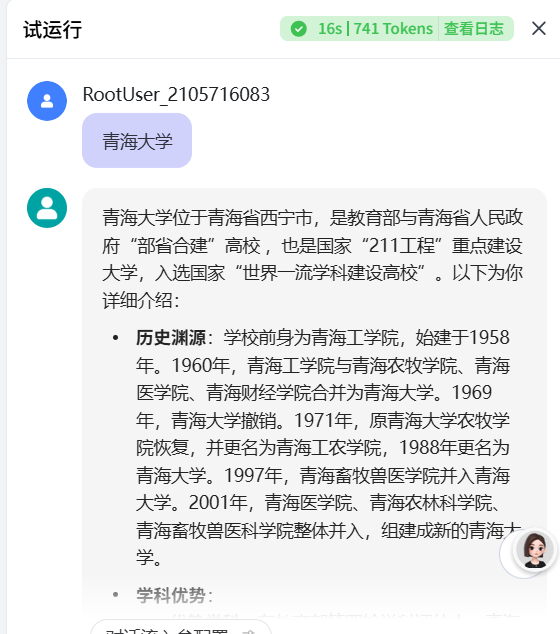
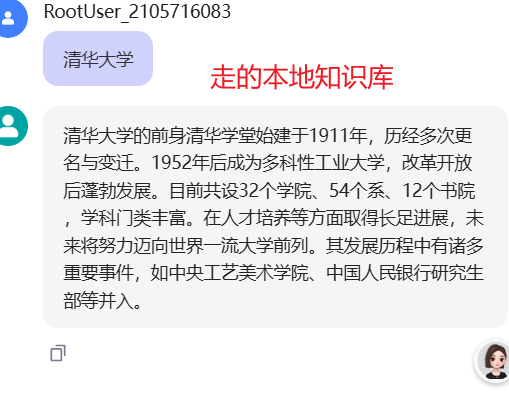
今天的例子就讲这么多,其实还有很多配置可以设置,比如把数据保存到飞书或者数据库等等,大家自己研究研究吧;