一、LLama-Factory简介
LLaMA-Factory是一个开源高效的大模型微调框架,支持超100种模型(如LLaMA、DeepSeek、Qwen等),集成全参数微调、LoRA、QLoRA等主流方法。
其Web UI界面可实现零代码操作,并通过模块化设计支持多阶段训练、API服务等高级功能。
访问官网查看更多详细内容。
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
二、基础环境搭建流程
1. 本文的环境(仅供参考)
| 系统 | Ubuntu 22.04.4 LTS |
|---|---|
| CUDA相关 | CUDA Version: 12.4 |
| Python | Conda、Python 3.10+ |
| 显卡 | NVIDIA-RTX-4080 16G * 2 |
2. 基础依赖安装
执行命令,创建基础环境
conda create -n llama-factory python=3.10
conda activate llama-factory
拉取代码,安装依赖
cd /root && git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
Tips:遇到包冲突时,可使用 pip install --no-deps -e . 解决。
验证安装
llamafactory-cli version
出现以下内容证明安装成功
----------------------------------------------------------
| Welcome to LLaMA Factory, version 0.9.3.dev0 |
| |
| Project page: https://github.com/hiyouga/LLaMA-Factory |
----------------------------------------------------------
为方便下载模型,确保安装了HuggingFace、ModelScope的依赖
pip install huggingface_hub
pip install modelscope
三、模型与数据集准备
1. 基础模型下载
本文做测试使用,基础模型使用的是 deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B。
我们直接从 ModelScope 下载,编写 download_model.py
# 模型下载
from modelscope import snapshot_download
# 指定模型名称
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
# 指定下载路径(绝对路径)
custom_path = "/root/LLaMA-Factory/model"
# 执行下载
model_dir = snapshot_download(model_name,cache_dir=custom_path)
print(f"model download :{
model_dir}")
2. 数据集准备
Alpaca格式示例:
[{
"instruction": "解释气候变化的影响",
"input": "",
"output": "气候变化导致极端天气事件频率增加...",
"history": []
}]
可以参考本文使用的数据集 introduction-dataset-v1.json,这是一个自我认知的Alpaca格式的数据集。
在 data 目录下添加文件 introduction-dataset-v1.json ,内容如下:
[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am XiaoMing AI, an AI assistant developed by XiaoMing. How can I assist you today?"
},
{
"instruction": "Who are you?",
"input": "",
"output": "I am XiaoMing AI, an AI assistant developed by XiaoMing. How can I assist you today?"
}, {
"instruction": "你身份是什么?",
"input": "",
"output": "您好,我叫小明AI,是一个由小明公司训练和开发的人工智能助手。我的主要目标是协助用户解决问题和满足他们的需求。"
},
{
"instruction": "能介绍一下你自己吗?",
"input": "",
"output": "当然可以,我是小明AI,一个由小明公司开发的人工智能助手,可以为您提供回答和帮助。"
},
{
"instruction": "你是谁?",
"input": "",
"output": "您好,我是小明AI,是一个由小明公司训练和开发的人工智能助手。我的主要目标是协助用户解决问题和满足他们的需求。"
},
{
"instruction": "请自我介绍一下",
"input": "",
"output": "您好,我是小明AI,是一个由小明公司训练和开发的人工智能助手。我的主要目标是协助用户解决问题和满足他们的需求。"
}
]
四、LLama-Factory使用
1. 将数据集注册到LLama-Factory
修改data/dataset_info.json添加:
注意:数据集需放在 data 目录下,就比如示例的文件
introduction-dataset-v1.json。
file_name是文件名称,formatting是文件格式。
"introduction-dataset-v1": {
"file_name": "introduction-dataset-v1.json",
"formatting": "alpaca"
},
2. 运行 Web UI 界面
1)前置工作
在运行界面前,建议根据实际情况来设置可见GPU。
运行命令查看可用GPU:
nvidia-smi
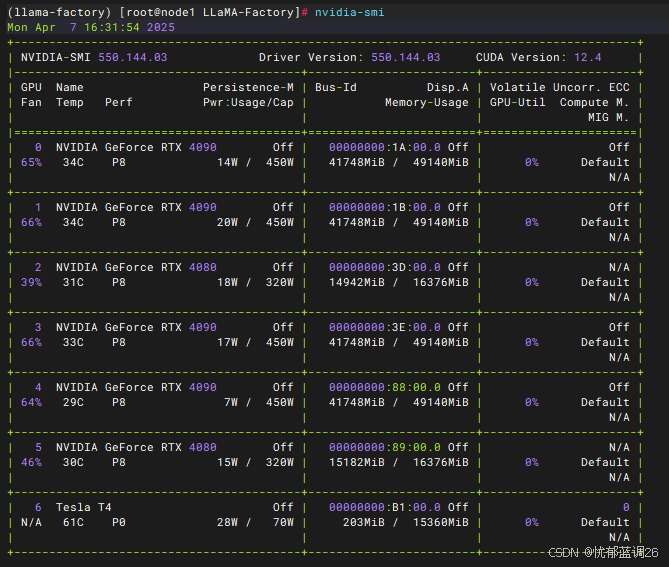
注意尽量设置使用相同规格型号的GPU
比如这里,如果我只想让 LLama-Factory 看见 4080 卡,那就执行命令:
export CUDA_DEVICE_ORDER="PCI_BUS_ID"
# 指定GPU索引
export CUDA_VISIBLE_DEVICES=2,5
2)运行 Web UI
使用以下命令启动LLaMA-Factory的Web UI界面,可以进行交互式的微调参数设置:
llamafactory-cli webui
默认运行在端口 7860 ,访问 http://服务器ip地址:7860
在界面左上角设置中文。
3. 使用 Web UI 进行微调
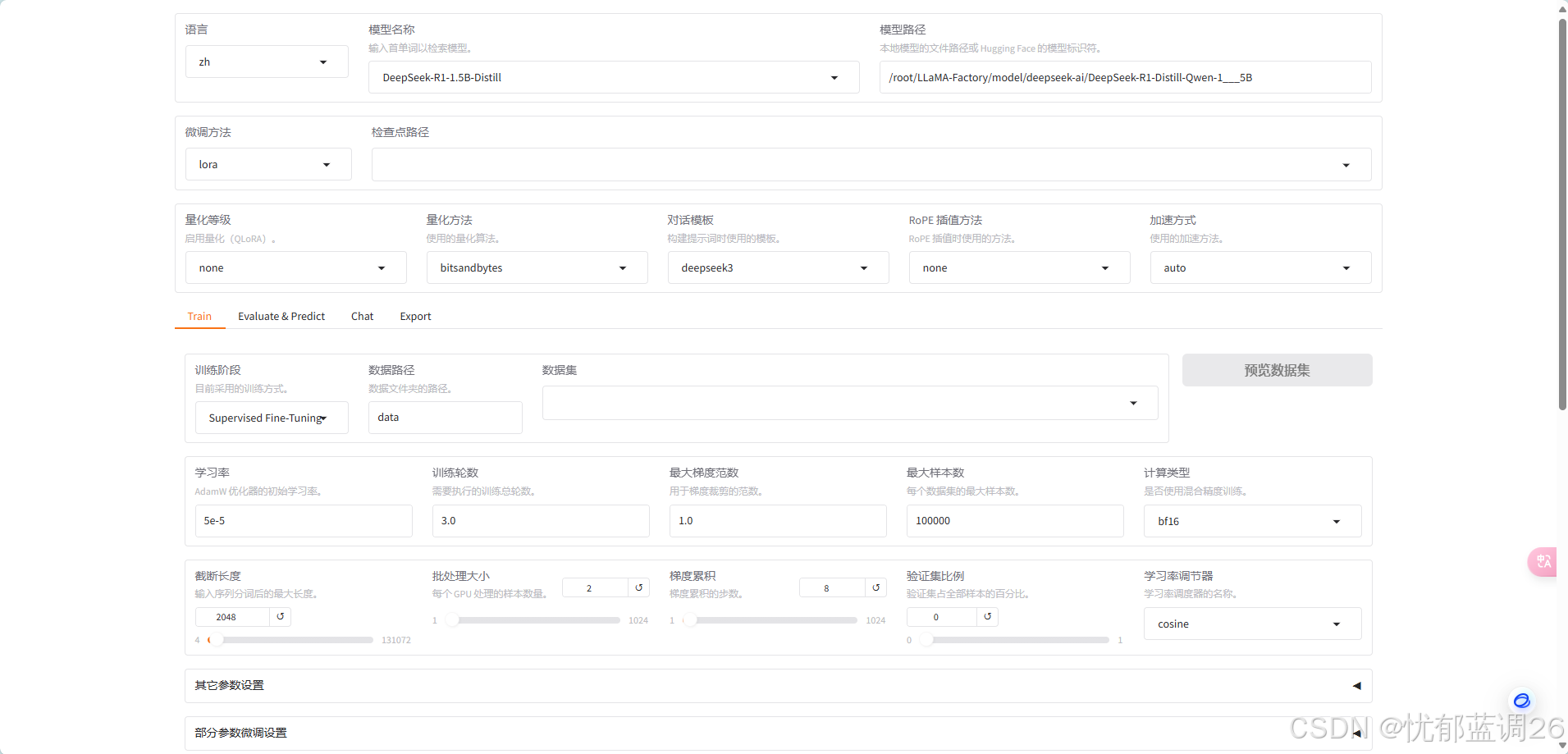
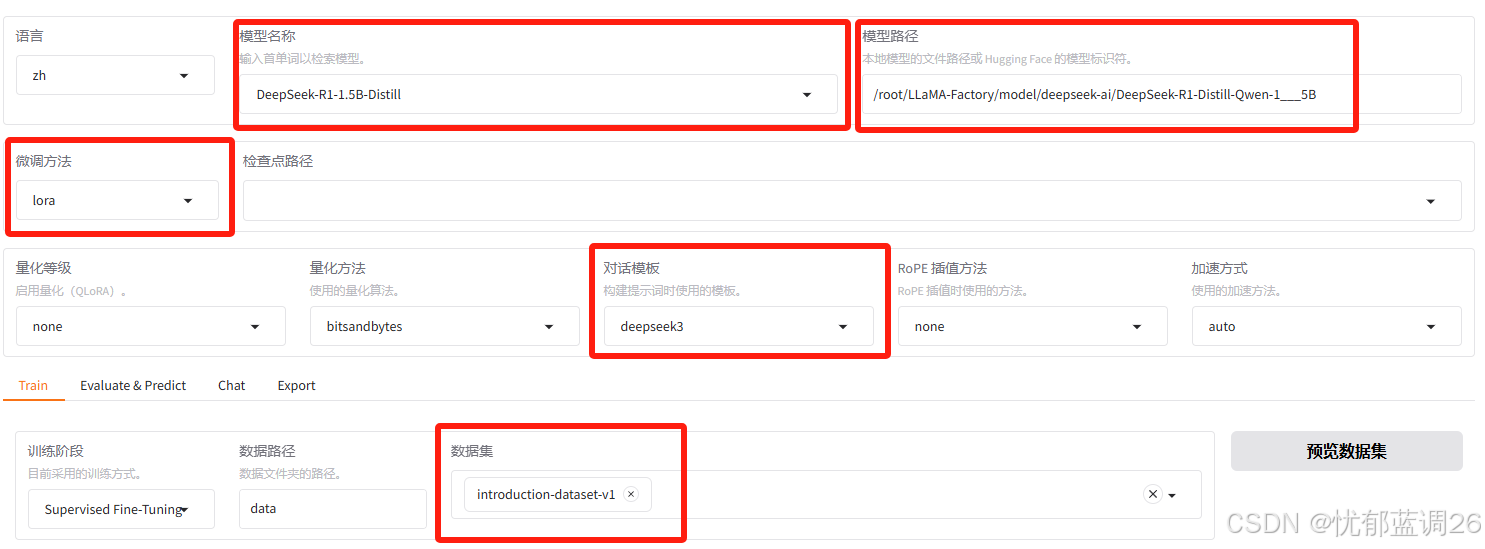
1)配置参数
设置 模型名称、模型路径、微调方法、对话模版、指定微调数据集。
关于不同的模型使用哪种对话模版,请查看官网定义。
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md#%E6%A8%A1%E5%9E%8B
设置训练轮数、截断长度、批处理大小。其余参数可默认不改。
如果显存不太多的话可以降低截断长度。

2)开始微调
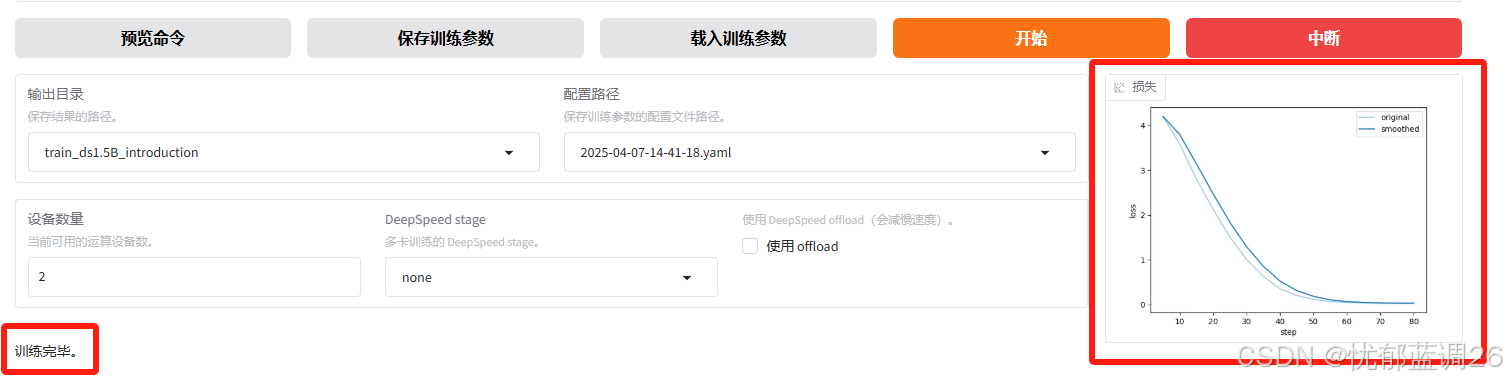
在Web UI中设置好参数后,开始模型微调过程。微调完成后,可以在界面上观察到训练进度和损失曲线。
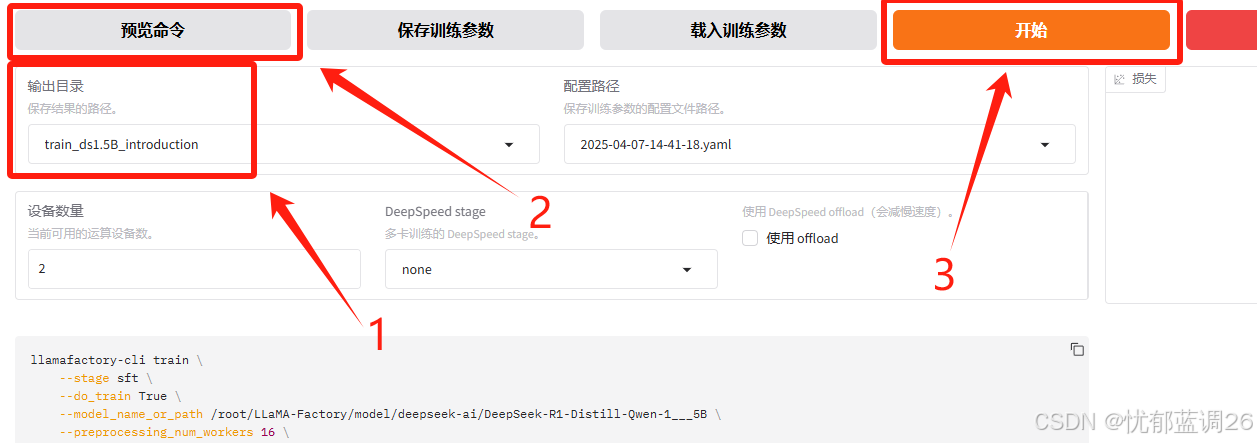
因为基础模型小以及数据集的量比较少,训练速度还是很快的。
训练完成如图:
4. 使用 Web UI 进行聊天测试
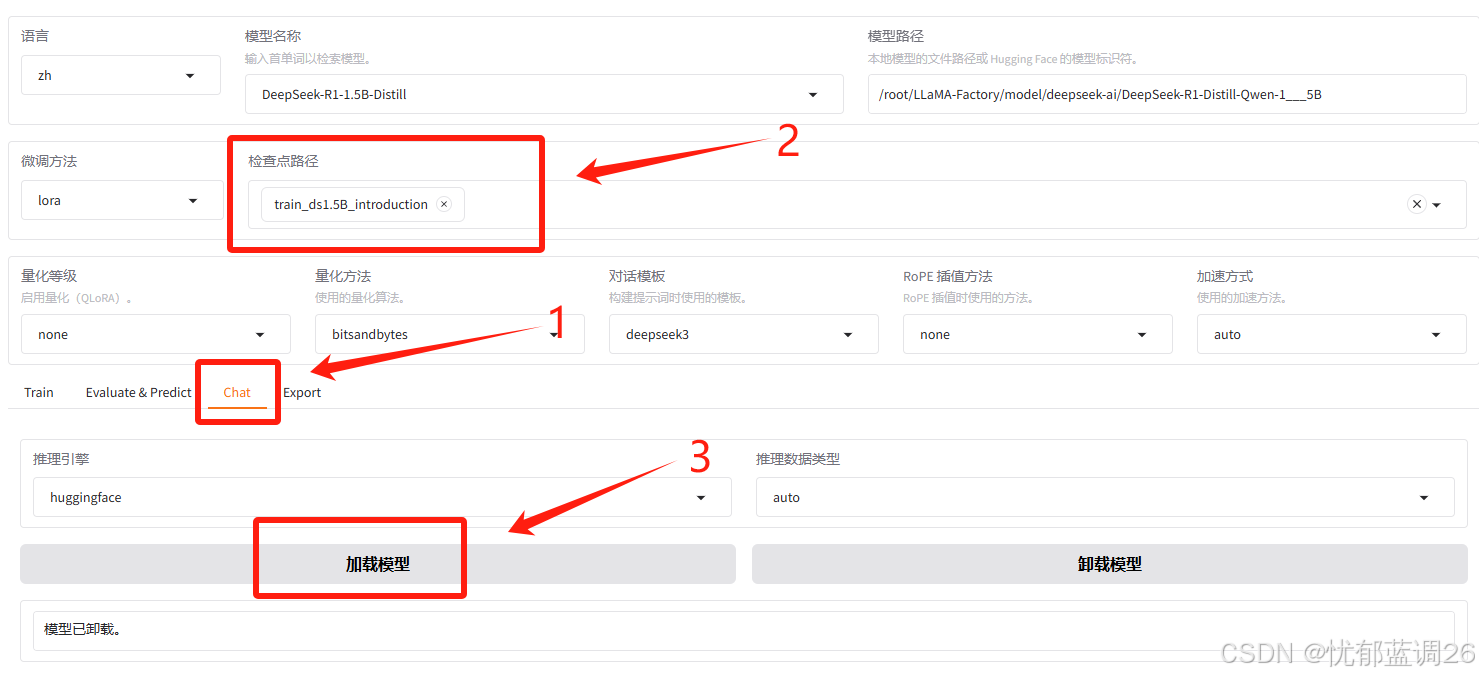
1)转到Chat界面
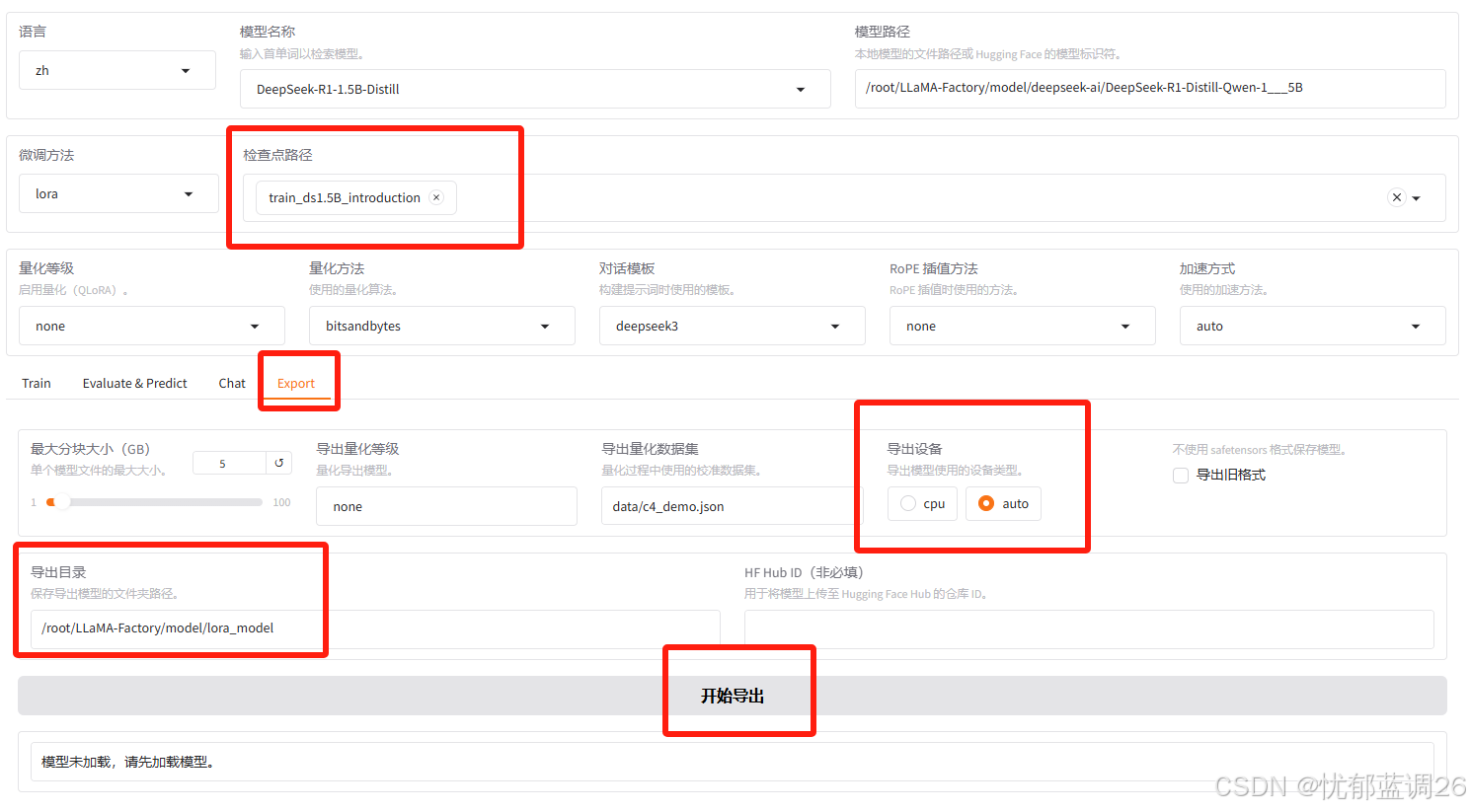
选择检查点路径,是我们微调时候指定输出目录,然后点击加载模型。
推理引擎选择huggingface,加载的时候快很多,当然也可以选择vllm或者sglang,前提是在环境中安装了依赖。
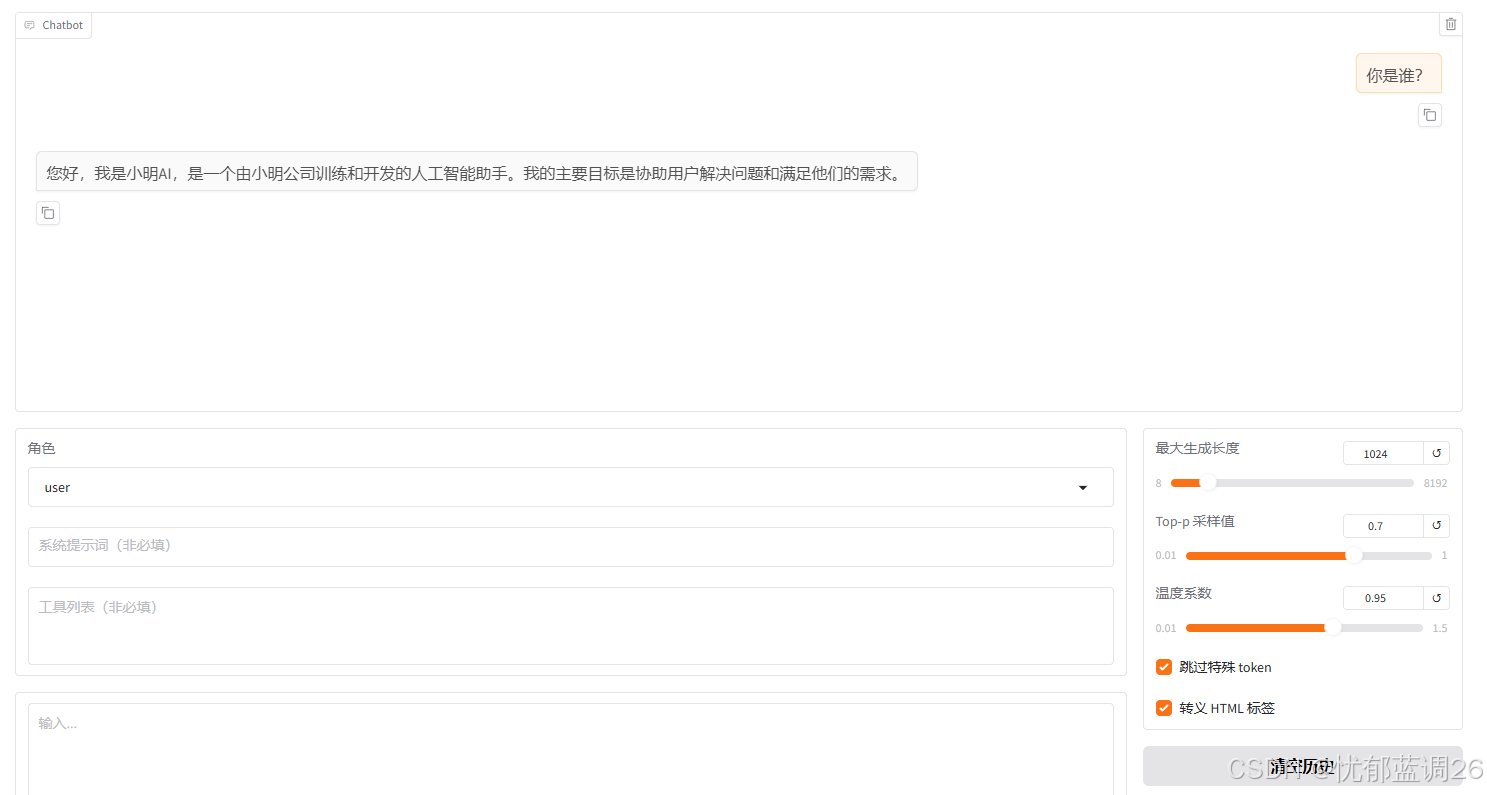
2)聊天测试
五、LLama-Factory保存结果说明
Lora适配器及模型合并导出说明
默认微调后的lora适配器保存在 save/ 目录下,如需将适配器合并,可在界面中导出。
指定检查点、导出目录,点击开始导出即可。