字典的初识
字典(Dictionary)是一种在Python中用于存储和组织数据的数据结构;与列表不同,字典使用 大括号{} 来表示;元素由键值对组成。其中,键(Key)必须是唯一的,而值(Value)则可以是任意类型的数据。
# 列表
info_list = ["yuan", 18, 185, 70]
# 字典
info_dict = {
"name": "yuan", "age": 18, "height": 185, "weight": 70}
print(type(info_dict)) # <class 'dict'>
字典类型很像新华字典。我们知道,通过新华字典中的音节表,可以快速找到想要查找的汉字。其中,字典里的音节表就相当于字典类型中的键,而键对应的汉字则相当于值。
字典的灵魂
字典是由一个一个的 key-value 构成的,字典通过键而不是通过索引来管理元素。字典的操作都是通过 key 来完成的。
字典的存储
字典对象的核心其实是个散列表,而散列表是一个稀疏数组(不是每个位置都有值),每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用,由于,所有bucket结构和大小一致,我们可以通过偏移量来指定bucket的位置
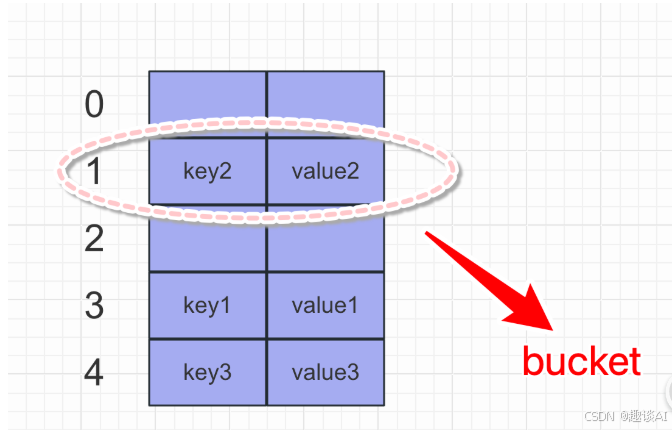
将一对键值放入字典的过程:
d = {
}
d["name"] = "yuan"
- 第一步:先定义一个字典,再写入值
- 第二步:在执行第二行时,
第一步就是计算"name"的散列值,python中可以用hash函数得到hash值,再将得到的值放入bin函数,返回int类型的二进制
print(bin(hash("name")))
结果为:
-0b100000111110010100000010010010010101100010000011001000011010
假设数组长度为10,我们取出计算出的散列值, 最右边3位数作为偏移量 ,即010,十进制是数字2,我们查看偏移量为2对应的bucket的位置是否为空,如果为空,则将键值放进去,如果不为空,依次取右边3位作为偏移量011,十进制是数字3,再查看偏移量3的bucket是否为空,直到单元为空的bucket将键值放进去。以上就是字典的存储原理;
当进行字典的查询时:
d["name"]
d.get("name")
第一步与存储一样,先计算键的散列值,取出后三位010,十进制为2的偏移量,找到对应的bucket的位置,查看是否为空,如果为空就返回None,不为空就获取键并计算键的散列值,计算后将刚计算的散列值与要查询的键的散列值比较,相同就返回对应bucket位置的value,不同就往前再取三位重新计算偏移量,依次取完后还是没有结果就返回None。
print(bin(hash("name")))每次执行结果不同:
这是因为 Python 在每次启动时,使用的哈希种子(hash seed)是随机选择的。哈希种子的随机选择是为了增加哈希函数的安全性和防止潜在的哈希碰撞攻击。
字典的特点
1.无序性:字典中的元素没有特定的顺序,不像列表和元组那样按照索引访问。通过键来访问和操作字典中的值。
2.键是唯一的且不可变类型对象:用于标识值。值可以是任意类型的对象,如整数、字符串、列表、元组等。
3. 可变性:可以向字典中添加、修改和删除键值对。这使得字典成为存储和操作动态数据的理想选择。
字典的基本操作
使用 { } 创建字典
# 使用 { } 创建字典
gf = {
"name":"赵丽颖","age":32}
print(len(gf)) # 2
查键值
# (1) 查键值
print(gf["name"]) # 赵丽颖
print(gf["age"]) # 32
添加或修改键值对,注意:如果键存在,则是修改,否则是添加
gf["age"] = 29 # 修改键的值
gf["gender"] = "female" # 添加键值对
print(gf) # {'name': '赵丽颖', 'age': 29, 'gender': 'female'}
删除键值对 del 删除命令
del gf["age"]
print(gf) # {'name': '赵丽颖', 'gender': 'female'}
判断键是否存在某字典中
print("weight" in gf) # False
循环
for key in gf:
print(key,gf[key]) # name 赵丽颖 gender female
字典的内置方法

创建字典
- 直接创建
gf = {
"name": "赵丽颖", "age": 36}
- 由列表创建字典dict.fromkeys(list,value),根据提供的键集合创建一个新字典,并为这些键赋相同的默认值。
stars = ['赵丽颖', '白鹿', '敖瑞鹏']
allStars = dict.fromkeys(stars, "good")
print(allStars) # {'赵丽颖': 'good', '白鹿': 'good', '敖瑞鹏': 'good'}
获取某键的值
- 直接获取
stars = { '赵丽颖': 'good', '白鹿': 'good', '敖瑞鹏': 'good'} print(stars["赵丽颖"]) # good - 使用get()方法获取
stars = { '赵丽颖': 'good', '白鹿': 'good', '敖瑞鹏': 'good'} print(stars.get("赵丽颖")) # good
更新字典
- 直接更新
stars = { '赵丽颖': 'good', '白鹿': 'good', '敖瑞鹏': 'good'} stars['赵丽颖']="super good" print(stars["赵丽颖"]) # super good - 使用update()方法,同键更新,不同键增加
stars = { '赵丽颖': 'good', '白鹿': 'good', '敖瑞鹏': 'good'} stars.update({ '赵丽颖': 'super good','杨紫': 'super good'}) print(stars) # {'赵丽颖': 'super good', '白鹿': 'good', '敖瑞鹏': 'good', '杨紫': 'super good'}
删除
- pop()删除字典指定的键值对,返回值是删除的值
stars = {
'赵丽颖': 'good', '白鹿': 'good', '敖瑞鹏': 'good'}
print(stars.pop('赵丽颖') ) # goood
print(stars) # {'白鹿': 'good', '敖瑞鹏': 'good'}
- popitem()删除字典最后的键值对
stars = {
'赵丽颖': 'good', '白鹿': 'good', '敖瑞鹏': 'good'}
print(stars.popitem() ) # ('敖瑞鹏', 'good')
print(stars) # {'赵丽颖': 'good', '白鹿': 'good'}
- clear() 清空字典
stars = {
'赵丽颖': 'good', '白鹿': 'good', '敖瑞鹏': 'good'}
stars.clear()
print(stars) # {}
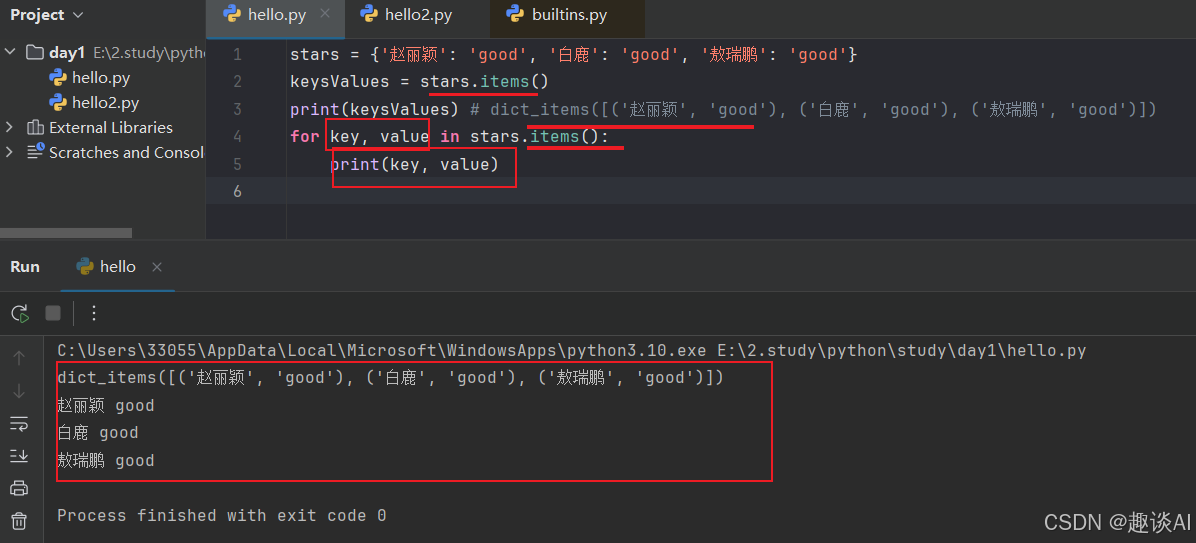
查询字典中所有的键和值items()
集合
集合(Set)是Python中的一种无序、不重复的数据结构。集合是由一组元素组成的,这些元素必须是不可变数据类型,但在集合中每个元素都是唯一的,即集合中不存在重复的元素。
无序性:集合中的元素是无序的,即元素没有固定的顺序。因此,不能使用索引来访问集合中的元素。
唯一性:集合中的元素是唯一的,不允许存在重复的元素。如果尝试向集合中添加已经存在的元素,集合不会发生变化。
可变性:集合是可变的,可以通过添加或删除元素来改变集合的内容。
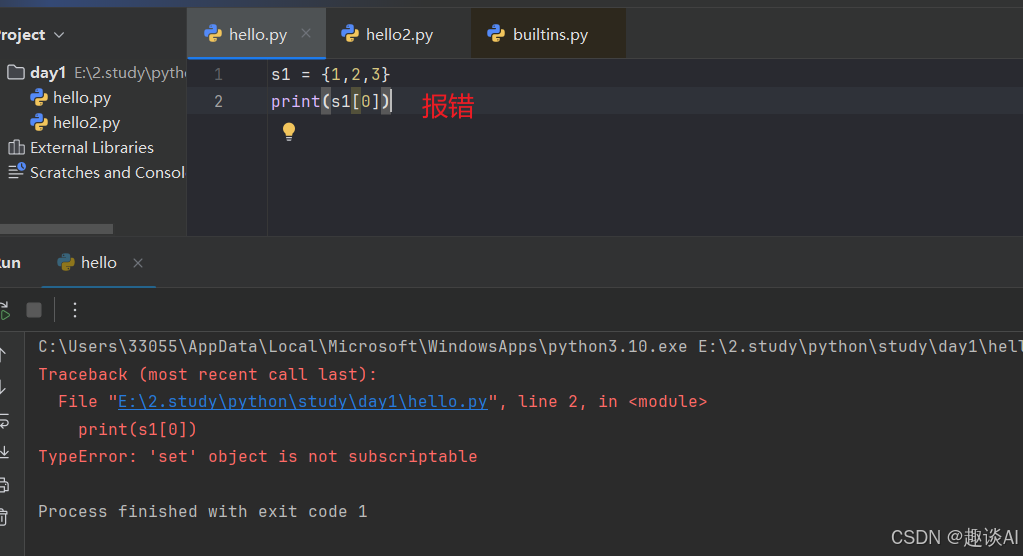
s1 = {
1,2,3}
print(len(s1)) # 3
print(type(s1)) # <class 'set'>
# 元素值必须是不可变数据类型
# s1 = {1, 2, 3,[4,5]} # 报错
集合是无序的,所以是无索引的
唯一: 集合可以去重
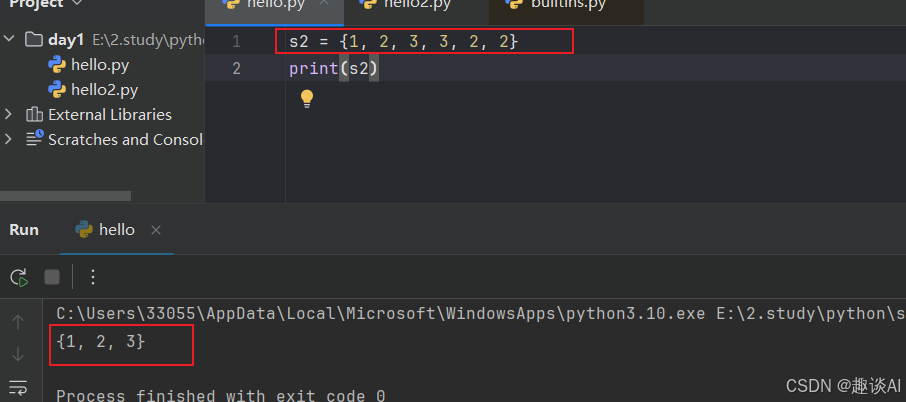
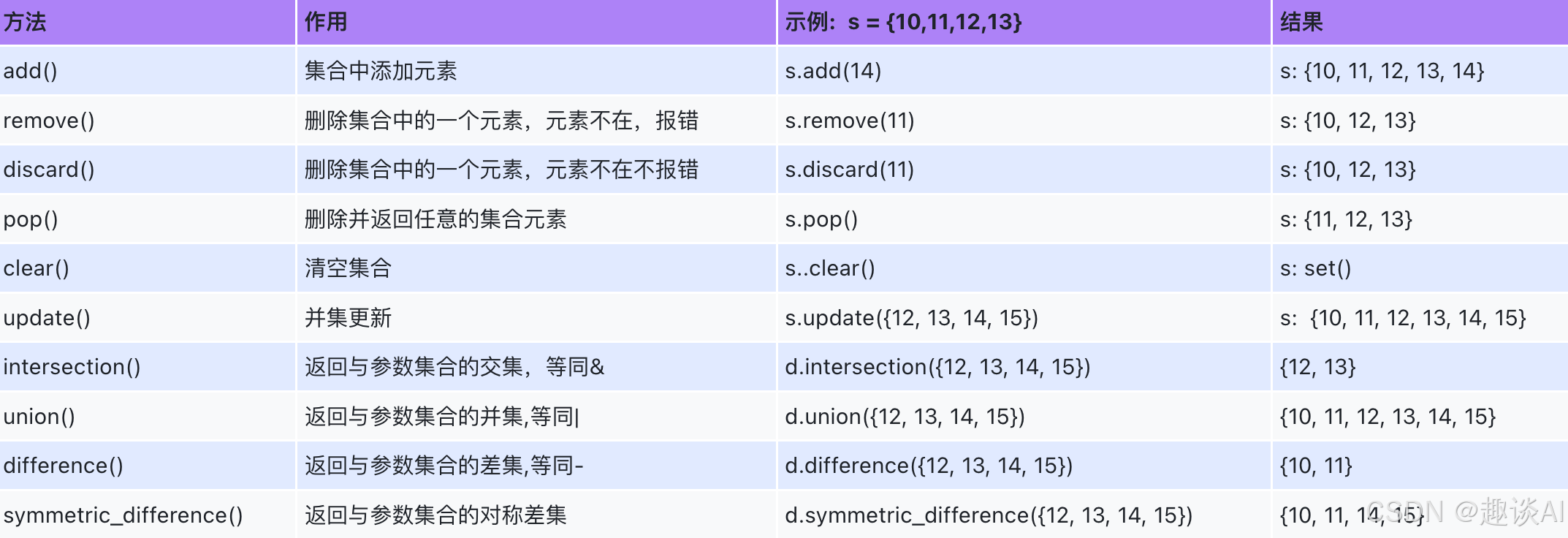
s3 = {
1, 2, 3}
# 增删改查
# 增
s3.add(4)
s3.add(3)
print(s3)
s3.update({
3, 4, 5})
print(s3)
# l = [1, 2, 3]
# l.extend([3, 4, 5])
# print(l)
# 删
s3.remove(2)
s3.remove(222)
s3.discard(2)
s3.discard(222)
s3.pop()
s3.clear()
print(s3) # set()
# 方式1: 操作符 交集(&) 差集(-) 并集(|)
s1 = {
1, 2, 3, 4}
s2 = {
3, 4, 5, 6}
print(s1 & s2) # {3, 4}
print(s2 & s1) # {3, 4}
print(s1 - s2) # {1, 2}
print(s2 - s1) # {5, 6}
print(s1 | s2) # {1, 2, 3, 4, 5, 6}
print(s2 | s1) # {1, 2, 3, 4, 5, 6}
print(s1, s2)
# 方式2:集合的内置方法
s1 = {
1, 2, 3, 4}
s2 = {
3, 4, 5, 6}
# 交集
print(s1.intersection(s2)) # {3, 4}
print(s2.intersection(s1)) # {3, 4}
# 差集
print(s1.difference(s2)) # {1, 2}
print(s2.difference(s1)) # {5, 6}
print(s1.symmetric_difference(s2)) # {1, 2, 5, 6}
print(s2.symmetric_difference(s1)) # {1, 2, 5, 6}
# 并集
print(s1.union(s2)) # {1, 2, 3, 4, 5, 6}
print(s2.union(s1)) # {1, 2, 3, 4, 5, 6}