GraphRAG是一种结合了知识图谱和大型语言模型的检索增强生成(RAG)技术。它通过引入图结构化的知识表示和处理方法,显著提升了传统RAG系统的能力,为处理复杂和多样化数据提供了强有力的支持。更多介绍可以跳转《最强检索增强技术GraphRAG基本原理详解》阅读。

本期我们将基于GraphRAG v2.0.0版本结合Ollama本地部署的大模型来快速构建知识图谱。
1、准备环境
首先我们需要安装Ollama和GraphRAG。
Ollama 是一个强大的工具,它为模型的管理和运行提供了便利。它可以简化模型的下载、配置和启动过程,让用户能够快速地将不同的模型集成到自己的工作流程中。关于Ollama的安装部署,可以跳转《本地问答系统-部署Ollama、Open WebUI》、《Ollama、Dify和RAG:企业智能问答系统的黄金配方》里面有关于Docker如何部署Ollama的内容,当然也可以选择二进制包直接本地安装部署。
安装Ollama - Linux系统
Linux 下可以使用一键安装脚本,我们打开终端,运行以下命令:
curl -fsSL https://ollama.com/install.sh | bash安装完成后,通过以下命令验证:
ollama --version如果显示版本号,则说明安装成功。
安装GraphRAG
我们创建一个Python=3.12的虚拟环境
conda create -n env_py312 python=3.12
conda activate env_py312安装 graphrag==2.0.0
pip install graphrag==2.0.0Ollama部署模型
GraphRAG需要我们部署两个类型的模型文件,我们需要选取一个聊天模型和一个嵌入模型。我们这里选择qwen2:32B作为聊天模型,nomic-embed-text:v1.5作为嵌入模型。

如果要使用的模型不在 Ollama 模型库,可以通过选择GGUF (GPT-Generated Unified Format)模型来实现部署、使用。
- Ollama现已支持modelscope上托管的GGUF格式的大模型部署推理。(需要Ollama版本不小于0.3.12)
- GGUF 是由 llama.cpp 定义的一种高效存储和交换大模型预训练结果的二进制格式。
Ollama 支持采用 Modelfile 文件中导入 GGUF 模型。
- Ollama 是一个基于开源推理引擎 llama.cpp 构建的大模型推理工具框架。借助底层引擎的高效推理能力以及对多种硬件的适配支持,Ollama 可以在包括 CPU 和 GPU 在内的多种硬件环境上运行各种精度的 GGUF 格式大模型。通过简单的命令行操作,即可快速启动 LLM 模型服务。
- ModelScope 社区托管了数千个高质量的 GGUF 格式大模型,并支持与 Ollama 框架和 ModelScope 平台的无缝对接。用户只需使用简单的 ollama run 命令,即可直接加载并运行 ModelScope 模型库中的 GGUF 模型。
所以如果需要从魔塔社区中下载GGUF模型,我们需要先安装依赖。
pip install modelscope这里举两个示例
Chat模型https://www.modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct-GGUF
modelscope download --model Qwen/Qwen2.5-7B-Instruct-GGUF qwen2.5-7b-instruct-q4_k_m.gguf --local_dir /root/autodl-tmp/modelsChatModelFile
FROM ./qwen2.5-7b-instruct-q4_k_m.gguf
执行 ollama create qwen2.5-7b-instruct -f ChatModelFile
Embedding模型https://www.modelscope.cn/models/Embedding-GGUF/nomic-embed-text-v1.5-GGUF
modelscope download --model Embedding-GGUF/nomic-embed-text-v1.5-GGUF nomic-embed-text-v1.5.f16.gguf --local_dir /root/autodl-tmp/models
EmbeddingModelFileFROM ./nomic-embed-text-v1.5.f16.gguf
执行 ollama create nomic-embed-text -f EmbeddingModelFile
ollama create 之后就可以在ollama list的模型列表里找到qwen2.5-7b-instruct 和 nomic-embed-text,我们只需要ollama run模型就可以使用了。
2、初始化 GraphRAG 项目
graphrag init --root ./ragdata-
修改.env文件
GRAPHRAG_API_KEY=ollama- 修改setting.yaml文件
model: qwen2.5:32b
api_base: http://localhost:11434/v1
encoding_model: cl100k_base
model:nomic-embed-text:latest
api_base: http://localhost:11434/v1
encoding_model: cl100k_base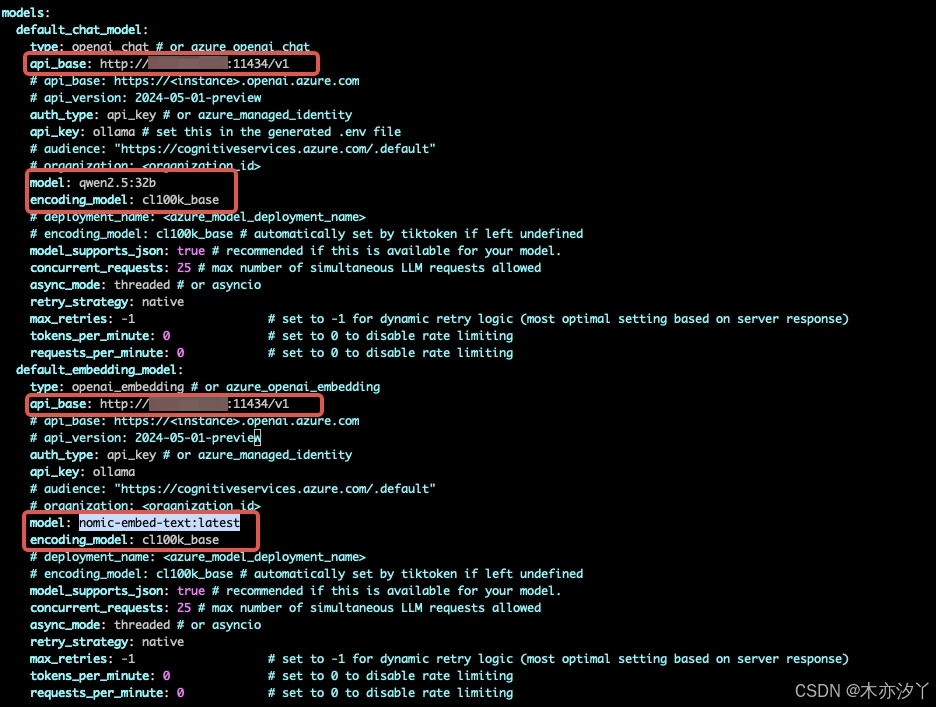
测试小文件时,建议把chunks改小:
chunks:
size:200
overlap: 50
group_by_columns:[id]配置文件可参考:https://microsoft.github.io/graphrag/config/yaml
参考配置说明:《2025年最新更新,GraphRAG yaml配置参数详细说明》
-
添加数据集
默认在项目下创建input目录,并上传数据文件。
示例文本 input.txt
《大数据时代》是一本由维克托·迈尔-舍恩伯格与肯尼斯·库克耶合著的书籍,讨论了如何在海量数据中挖掘出有价值的信息。这本书深入探讨了数据科学的应用,并阐述了数据分析和预测在各行各业中的影响力。在书中,作者举了许多实际例子,说明大数据如何改变我们的生活,甚至如何预测未来的趋势。3、构建知识图谱
执行创建索引命令 (默认为standard模式)
graphrag index --root ./ragdata
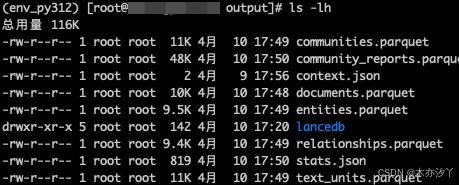
创建索引的过程包括create_base_text_units、create_final_documents、extract_graph、finalize_graph、create_communities、create_final_text_units、create_community_reports、generate_text_embeddings等过程。执行成功后,在项目output下就会存在知识图谱相关的parquet文件。
LazyGraphRAG
目前LazyGraphRAG好像还未正式发布,但是基于早期FastGraphRAG技术的NLP提取已经集成。
核心代码:graphrag/index/workflows/extract_graph_nlp.py
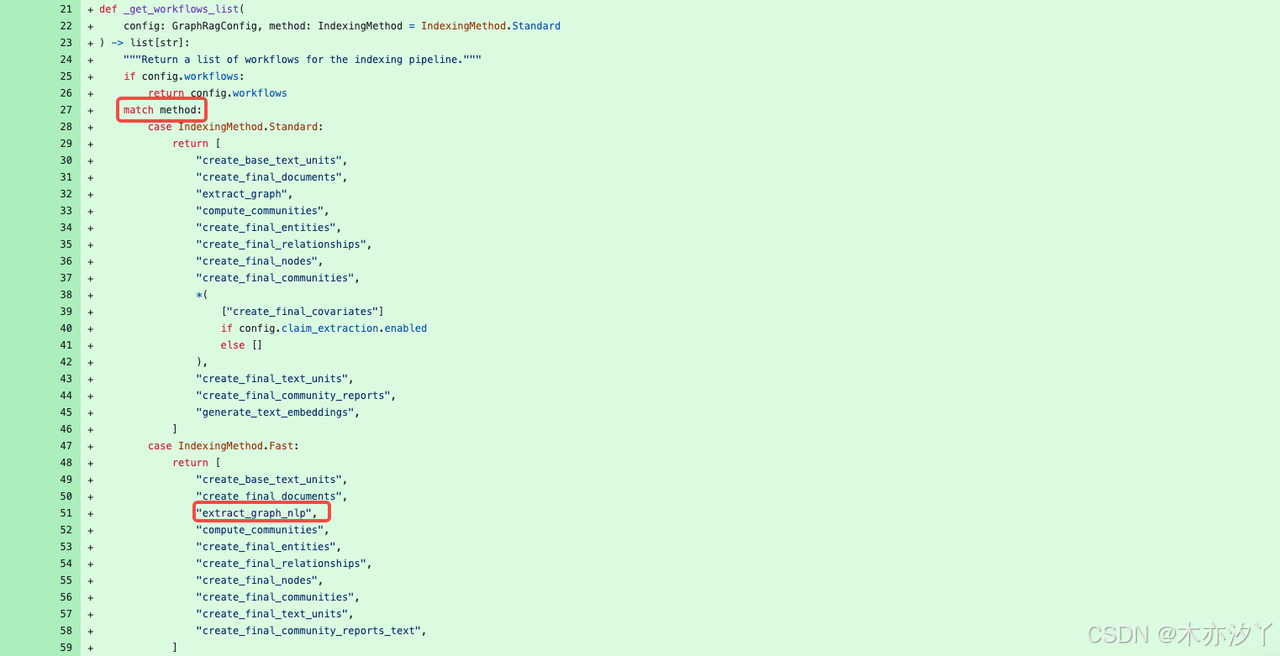

这里我们调整了chunks参数并上传了一个英文数据集来体检下fast模式的索引创建,为什么调整了成了英文数据集是因为extract_graph_nlp可能对中文支持不是很友好,作者在运行时prune_graph过程出现了报错。
graphrag index --method fast --root ./ragdata 创建索引的过程包括create_base_text_units,create_final_documents,extract_graph_nlp,prune_graph,finalize_graph,create_communities,create_final_text_units,create_community_reports_text,generate_text_embeddings等过程。我们发现除了extract_graph_nlp不同外,额外还有一个prune_graph过程。所以prune_graph的参数配置也是fast模式一个可配置调整的参数。
4、查询知识图谱
我们主要测试两种查询方式,全局搜索和本地搜索。
https://microsoft.github.io/graphrag/query/overview
Global Search(全局搜索)
Global Search很大程度上解决了传统RAG在处理数据时的局限性,Global Search更侧重于回答全文摘要总结类的场景,比如:“请帮我总结一下这篇文章讲了什么内容?”。传统RAG会因为在切分文本块时丢失信息,而回答的不够全面。以下详细介绍下Global Search的核心原理和流程。
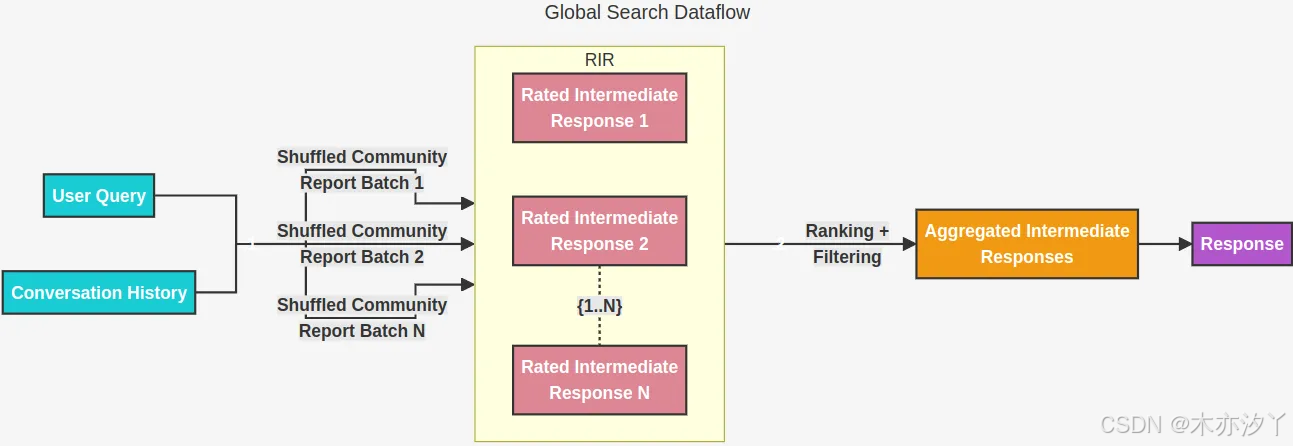
Global Search的查询分为以下两个步骤:
- Map阶段:根据用户的输入和对话历史,查询知识图谱社区结构中指定级别的社区报告集,并将其切分成预定义大小的文本块,使用这些文本块生成带有评分的中间相应。评分用来表示这些观点的重要程度,整个过程都是通过LLM来生成。(可以理解为使用LLM来总结社区报告并打分)
- Reduce阶段:在reduce阶段会对map阶段的评分进行倒排,并选出一组最重要的点汇总作为参考上下文,最后由大模型来生成最终相应结果。
特性
- 搜索范围大:Global Search会通过全文搜索的模式力争覆盖范围最广, 从而得出的结论也就更可信,所以对于一些可信度要求高的场景可以使用该模式;
- 计算成本高:因为Global Search要对整个图结构进行遍历搜索,所以中间需要大量的计算;从而会带来计算成本高、搜索时间长的问题,对于图结构规模比较大的场景会非常耗时;
graphrag query --root ./ragdata --method global --query "大数据时代"SUCCESS: Global Search Response:
Victor Mayer-Schönberger 和 Kenneth Cukier 是《Big Data Era》一书的合著者,该书强调了他们在大数据领域的重大贡献 [Data: Entities (0, 1), Relationships (0)]。他们的著作不仅在学术界产生了深远影响,还对多个行业带来了启示和应用上的指导 [Data: Entities (0, 1), Relationships (0)]。
《Big Data Era》一书是该领域的重要作品之一,它探讨了大数据的含义及其广泛应用,从而深刻地改变了各个行业的运作方式和研究方法。这本书不仅为学术界提供了理论基础,还为企业在实际操作中如何利用大数据提供了宝贵的指导 [Data: Entities (0, 1), Relationships (0)]。
通过这些贡献,Mayer-Schönberger 和 Cukier 在推动大数据技术的发展及其应用方面发挥了关键作用,他们的工作对于理解大数据的潜力和挑战至关重要。Local Search(本地搜索)
Local Search将用户的输入与知识图谱中的结构化数据相结合,以便在查询时使用相关实体信息来增强LLM上下文。这种方式比较适合需要了解输入文档中提到的关于某个特定实体的相关问题,例如:“小王是做什么工作的?”
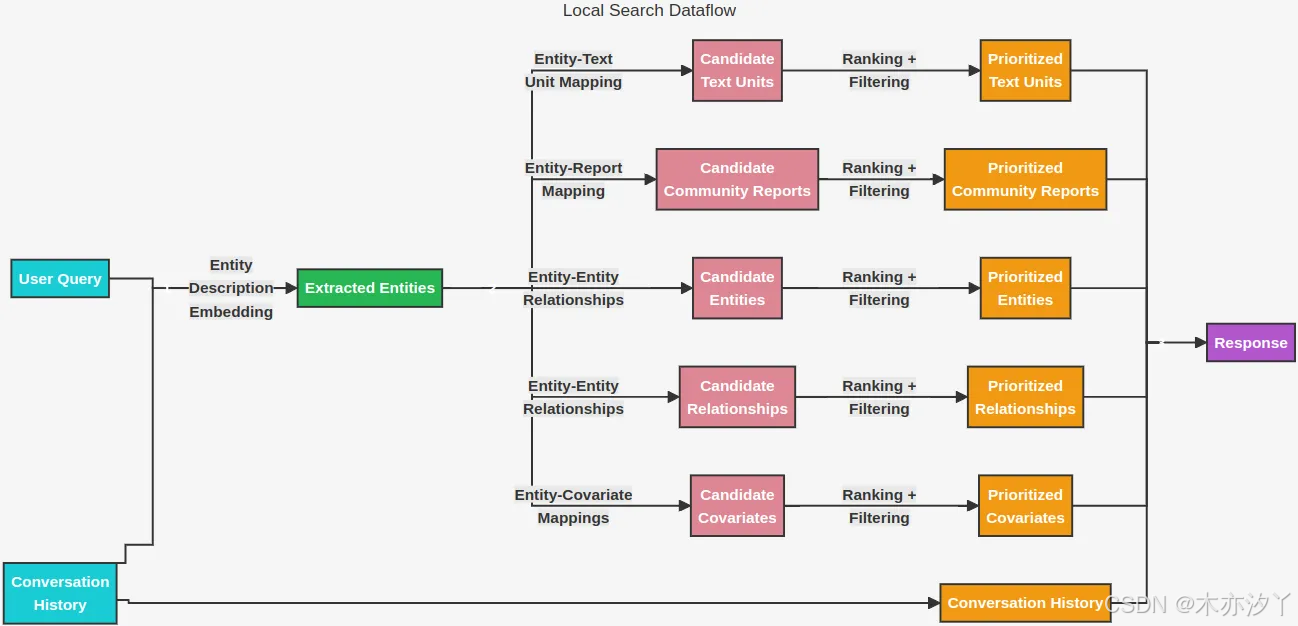
Local Search主要包含以下几个关键步骤:
- 相关实体检索:根据用户的输入和对话历史,利用向量搜索技术从知识图谱或向量数据库中识别出一组与用户输入在语义上相关的节点或文档集。
- 相关数据提取:基于上个阶段搜索的结果,在知识图谱中进一步提取更多相关的信息,包括:原始文本块、社区报告、实体描述、关系描述等信息,主要通过知识图谱检索出更大范围的相关上下文。
- 节点排序:基于图的排序算法对提取出来的数据源进行优先级排序和过滤,在一定大小的上下文窗口范围内确保最相关的信息能够被展示出来。
- 相应生成:将排序后的文档块作为上下文信息输入到LLM中,生成最终的响应结果。
特性
- 效率高:Local Search采用局部相关性搜索一定程度上提高了搜索效率和计算成本,在对于大规模的图数据场景中,Local Search可以更高效、更快的找到相关答案。
- 局限性:Local Search的局部搜索效果很大程度上取决于用户的输入,不同的输入检索到的相关节点不同,对最终的结果会有较大的局限性影响。
graphrag query --root ./ragdata --method local --query "大数据时代"INFO: Vector Store Args: {
"default_vector_store": {
"type": "lancedb",
"db_uri": "***/rag/ragdata/output/lancedb",
"url": null,
"audience": null,
"container_name": "==== REDACTED ====",
"database_name": null,
"overwrite": true
}
}
SUCCESS: Local Search Response:
《大数据时代》是一本由维克托·迈尔-舍恩伯格与肯尼斯·库克耶合著的书籍,该书深入探讨了大数据的应用及其对社会的影响。这本书被认为是大数据领域的里程碑之作,它不仅在学术界产生了广泛影响,也在多个行业中被广泛应用作为理解和应用大数据的重要参考 [Data: Reports (0); Sources (0)]。
维克托·迈尔-舍恩伯格是《大数据时代》的作者之一,他在大数据领域做出了显著贡献。他与肯尼斯·库克耶的合作成果——这本书,详细探讨了大数据的意义和应用场景,体现了他们在该领域的深厚专业知识 [Data: Entities (0), Relationships (0); Reports (0)]。
另一位作者肯尼斯·库克耶同样在《大数据时代》中发挥了重要作用。他的合作不仅加深了对大数据的理解,还为社会如何应对大数据带来的挑战提供了洞见。这种合作关系展示了他们共同的专业知识和影响力,特别是在研究和应用大数据方面 [Data: Entities (1), Relationships (0); Reports (0)]。
维克托·迈尔-舍恩伯格与肯尼斯·库克耶之间的合作是基于他们对《大数据时代》这本书的共同贡献。他们的合作关系不仅产生了重要的研究成果,还为该领域的发展做出了巨大贡献,体现了他们在大数据研究和应用方面的联合专长 [Data: Relationships (0); Reports (0)]。
总的来说,《大数据时代》一书及其作者维克托·迈尔-舍恩伯格与肯尼斯·库克耶在推动大数据领域的知识传播和发展方面发挥了关键作用。这本书不仅为学术界提供了宝贵的资源,也在实际应用中产生了深远的影响 [Data: Entities (0, 1), Relationships (0); Reports (0)]。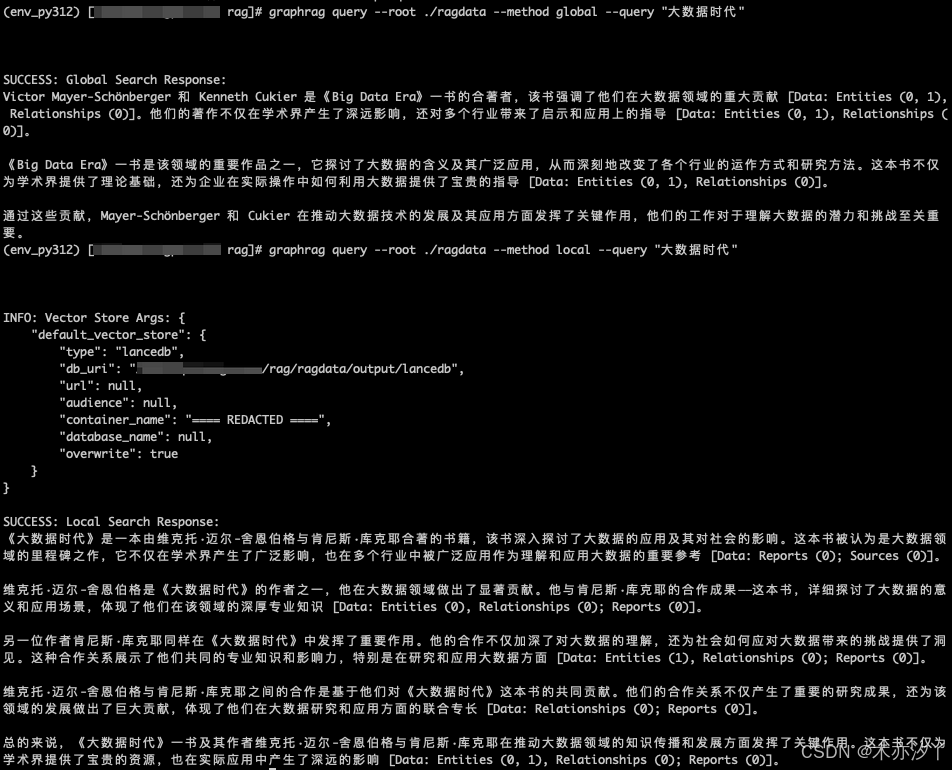
此外还有一种搜索方式:DRIFT搜索
DRIFT Search是一种结合Global Search和Local Search的方案,通过在搜索过程中纳入社区信息,为Local Search引入了新方法。该方案优化了Local Search局限性的不足,大大扩展了查询的起点,在最终答案中检索和使用更多种类的事实。同时,也扩展了GraphRAG的查询引擎,为本地搜索提供了更全面的选项,利用社区摘要将查询细化为更详细的后续问题。
整个DRIFT Search搜索层次突出了搜索过程的三个核心阶段,以下为每个阶段的详细介绍:
- 社区报告检索:DRIFT 将用户的查询与语义最相关的前K个社区报告进行比较,生成广泛的初步答案和后续问题以引导进一步的探索。
- 相关数据提取:DRIFT使用本地搜索来优化查询,生成额外的中间答案和后续问题以增强特异性,从而引导搜索引擎获取更丰富的上下文信息。
- 相关性排序:最后则是根据相关性对相关节点进行排序,并将排序后的文档作为上下文信息输入到LLM,生成最终的响应。
特性
- 平衡性:DRIFT Search方案通过融合Global Search和Local Search,反映了全局见解和局部细化之间的平衡组合,使结果更具适应性且更全面。
- 多样性:通过纳入社区报告信息,使得DRIFT Search在初步搜索就扩大了范围,也就意味着DRIFT Search能够检索到更多的相关内容,最终的检索效果就会更具多样性。
DRIFT Search是GraphRAG最新的改进版本,它既取了Globall Search的优点也补足了Local Search的缺点,但在实际工程里大家还是要结合业务场景选择最适合的方案。无论哪种搜索模式开发者都需要考虑搜索效率和LLM Tokens的资源消耗,都需要衡量召回精度、计算成本和时间成本的优先级,特别是在当前大模型应用开发领域,一定没有最优的解决方案只有最适合场景的解决方案。
5、报错回顾
配置错误引起的报错
报错一、https://github.com/microsoft/graphrag/issues/1806

和 GraghRAG 1.0系列版本不一样,这里
default_embedding_model的api_base需要配置为 http://localhost:11434/v1 。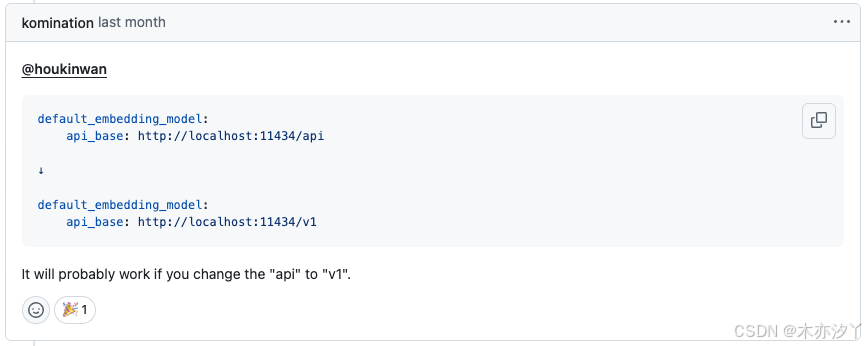
报错二、KeyError: 'Could not automatically map qwen2.5:32b tto a tokeniser. Please use tiktoken.get_encoding'to explicitly get the tokeniser you expect.
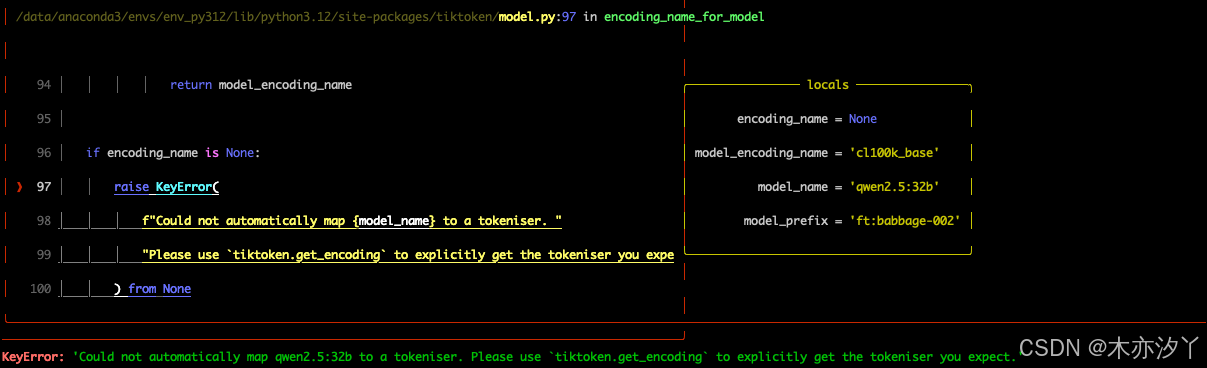
encoding_modelstr - The text encoding model to use. Default is to use the encoding model aligned with the language model (i.e., it is retrieved from tiktoken if unset).
default_chat_model和default_embedding_model都需要配置encoding_model参数。encoding_model: cl100k_base
