目录
一、空间自适应归一化模块(SPADE ResBlk)
在Pix2PixHD中,我们使用BatchNorm来进行归一化操作,这样常规的的归一化操作的缺点便是语义信息的洗去,原因如下:(个人理解)
如下为传统BN归一化操作的公式:
其中 γ 和 β(被称为调制参数)通过损失的反向传播进行学习,这样的 γ 和 β 形式是一个向量,相当于对一张图像上的每一个像素都进行了相同的操作,然而我们知道一张图像存在丰富的语义信息,对他们进行相同的归一化操作很明显是不公平的,大量的语义信息会在这期间被洗去。
为了解决这样的问题,SPADE使用了一种有约束的归一化操作,被称为空间自适应归一化操作,顾名思义,该归一化操作在图像的空间上进行变化,不再是传统的统一归一化操作。如下为SPADE归一化操作公式:
我们发现此时,γ 和 β 都变为了一个输入为m的函数,而且其值在(x,y)上变化(这就是在空间上的变化),不再是一个向量,而是是一个张量。基于此,下面为SPADE归一化模块的结构:
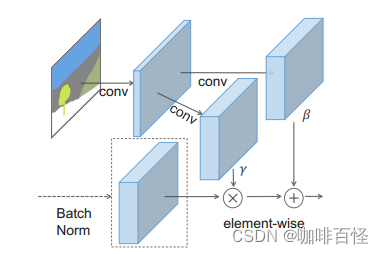
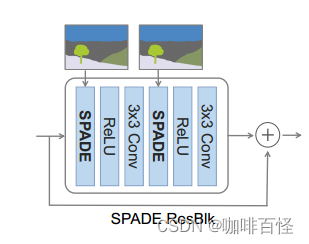
SPADE模块通过输入掩码m进行卷积操作得到 γ 和 β 张量,这样输入掩码m进行计算归一化调制参数的操作很好的输入了图像的语义信息,这是对于图像翻译任务非常有效的。(作者在文中也提到了Adain和Conditional BatchNorm,这和SPADE十分相似,但是输入很不一样,而输入掩码m符合论文进行的图像翻译工作)。作者还借鉴了ResNet的思路,创立了基于SPADE的SPADE ResBlk:
二、噪声z编码器(ImageEncoder)
SPADE的另外一个十分重要的点在于编码器的取消,我们知道在Pix2PixHD中,U-Net被用来创建了特征编码器和生成器中的编码器,而在SPADE中,作者舍弃了这一操作,没有使用任何编码器,而是使用了一个从真实图像中学习得到的噪声z作为生成器的输入。如此操作掩码m就又充当了语义轮廓引导的作用,如图为ImageEncoder的结构图,其输出均值和方差,作为噪声参数。

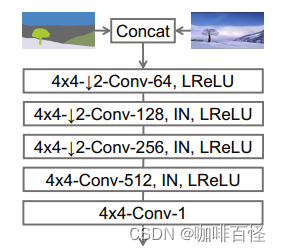
三、鉴别器(Discriminator)
SPADE的鉴别器则继续沿袭了Pix2PixHD的方法,使用带有Instance Norm的多尺度鉴别器,唯一的区别在于,作者在鉴别器的每一步卷积层中加入了谱归一化(Spectral Norm) :
四、学习损失(Hinge Loss和KL散度损失)
SPADE的损失函数与Pix2PixHD的损失保持一致,不做变化,作者在文章中提到,去掉任何一种损失都会对结果产生不好的影响。但是作者用Hinge Loss取代了基于最小二乘的Lsgan。而对于ImageEncoder的损失则是采用了KL散度损失:
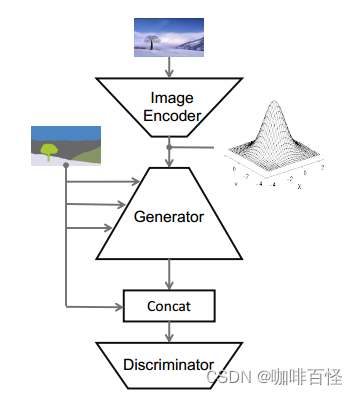
五、SPADE图像翻译网络总框架
基于以上几点,SPADE的图像翻译网络便形成了:
更细节的部分请阅读论文:
https://arxiv.org/abs/1903.07291 https://arxiv.org/abs/1903.07291
https://arxiv.org/abs/1903.07291