简要总结
本文提出了一种名为 CroSel(Cross Selection of Confident Pseudo Labels)的部分标签学习(Partial-Label Learning, PLL)方法,旨在从候选标签集中准确识别真实标签以提升模型性能。其核心基于两个假设:模型对样本的高置信度和低波动性预测通常对应真实标签;通过历史预测可以有效筛选出这些标签。CroSel 使用了交叉选择策略(Cross Selection Strategy)和一致性正则化项(Co-mix Consistency Regulation)两大技术路线,通过双模型互助和数据增强技术实现标签消歧。创新点包括交叉选择框架和高精度标签筛选机制,以及结合 MixUp 增强数据的一致性正则化方法。以下是详细说明。
基于的假设
CroSel 的设计基于以下关键假设:
- 高置信度和低波动性假设:如果模型对某个样本的预测在多个 epoch 中始终保持高置信度(confidence)且预测标签波动性低(即一致性高),则该预测标签很可能是该样本的真实标签。
- 候选标签包含真实标签:与 PLL 的常见假设一致,每个样本的候选标签集 S i S_i Si 中必然包含其真实标签 y i y_i yi。
这些假设为筛选置信伪标签提供了理论依据,CroSel 通过历史预测的统计分析来验证这些条件。
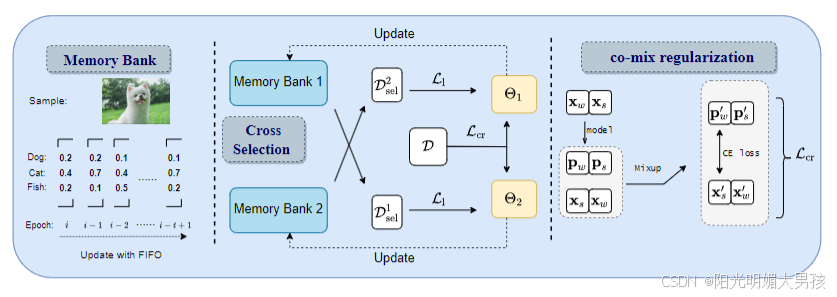
使用的技术路线
CroSel 的技术路线主要分为两大模块:
-
交叉选择策略 (Cross Selection Strategy):
- 使用两个相同的深度神经网络(双模型 Θ ( 1 ) \Theta^{(1)} Θ(1) 和 Θ ( 2 ) \Theta^{(2)} Θ(2))相互选择置信伪标签。
- 通过记忆库(Memory Bank, MB)存储历史预测,基于选择标准从候选标签集中识别真实标签。
- 双模型交叉监督,利用集成学习思想提高选择精度。
-
一致性正则化项 (Co-mix Consistency Regulation):
- 针对未被选择的样本,避免数据浪费。
- 使用弱增强(weak augmentation)和强增强(strong augmentation)生成伪标签。
- 结合 MixUp 数据增强技术,进一步提升数据多样性和一致性。
实现的技术细节
-
预热阶段 (Warm-up):
- 使用 CC 算法(Feng et al., 2020)预训练双模型 10 个 epoch,减少分类风险并初始化记忆库。
- 记忆库 MB 存储过去 t t t 个 epoch 的 softmax 输出,尺寸为 t × n × k t \times n \times k t×n×k( n n n 为样本数, k k k 为类别数)。
-
选择标准 (Selecting Criteria):
- 基于以下三个条件筛选置信伪标签:
- β 1 \beta_1 β1:预测标签在候选标签集中。
- β 2 \beta_2 β2:过去 t t t 个 epoch 中预测标签一致(低波动性)。
- β 3 \beta_3 β3:平均预测置信度超过阈值 γ \gamma γ。
- 实现方式:通过 MB 中的历史 softmax 输出 q i q^i qi 判断。
- 基于以下三个条件筛选置信伪标签:
-
交叉选择 (Cross Selection):
- Θ ( 1 ) \Theta^{(1)} Θ(1) 的 MB^{(1)} 选择 D sel 1 D_{\text{sel}}^1 Dsel1 用于训练 Θ ( 2 ) \Theta^{(2)} Θ(2)。
- Θ ( 2 ) \Theta^{(2)} Θ(2) 的 MB^{(2)} 选择 D sel 2 D_{\text{sel}}^2 Dsel2 用于训练 Θ ( 1 ) \Theta^{(1)} Θ(1)。
- 测试时,平均双模型输出: f ′ ( x ) = 1 2 ( f 1 ( x ) + f 2 ( x ) ) f'(x) = \frac{1}{2} (f^1(x) + f^2(x)) f′(x)=21(f1(x)+f2(x))。
-
Co-mix 正则化:
- 对所有样本应用弱增强和强增强,生成伪标签。
- 使用锐化(sharpening)和归一化处理 logits。
- 通过 MixUp 混合增强数据对,生成可训练目标。
-
损失函数:
- 监督损失 L 1 \mathcal{L}_1 L1:对 D sel D_{\text{sel}} Dsel 使用交叉熵损失。
- 正则化损失 L cr \mathcal{L}_{\text{cr}} Lcr:对所有样本使用一致性损失。
- 总损失动态组合: L all = L 1 + λ d ∗ L cr \mathcal{L}_{\text{all}} = \mathcal{L}_1 + \lambda_d * \mathcal{L}_{\text{cr}} Lall=L1+λd∗Lcr。
详细的数学公式表达
-
选择标准:
- β 1 = I ( argmax ( q i ) ∈ S ) \beta_1 = \mathbb{I}(\operatorname{argmax}(\boldsymbol{q}^i) \in S) β1=I(argmax(qi)∈S):确保预测标签在候选集内。
- β 2 = I ( argmax ( q i ) = argmax ( q i + 1 ) ) \beta_2 = \mathbb{I}(\operatorname{argmax}(\boldsymbol{q}^i) = \operatorname{argmax}(\boldsymbol{q}^{i+1})) β2=I(argmax(qi)=argmax(qi+1)):检查预测稳定性。
- β 3 = I ( 1 t ∑ i = 1 t max ( q i ) > γ ) \beta_3 = \mathbb{I}(\frac{1}{t} \sum_{i=1}^t \max(\boldsymbol{q}^i) > \gamma) β3=I(t1∑i=1tmax(qi)>γ):平均置信度超过阈值。
- 选择数据集: D sel = { ( x i , argmax ( q i t ) ) ∣ ( β 1 i ∧ β 2 i ∧ β 3 i ) = 1 , x i ∈ D } \mathcal{D}_{\text{sel}} = \{(\boldsymbol{x}_i, \operatorname{argmax}(\boldsymbol{q}_i^t)) \mid (\beta_1^i \wedge \beta_2^i \wedge \beta_3^i) = 1, \boldsymbol{x}_i \in \mathcal{D}\} Dsel={(xi,argmax(qit))∣(β1i∧β2i∧β3i)=1,xi∈D}。
-
监督损失:
- L 1 = 1 ∣ D sel ∣ ∑ x ∈ D sel L CE ( f ( x w ) , y ^ ) \mathcal{L}_1 = \frac{1}{|\mathcal{D}_{\text{sel}}|} \sum_{\boldsymbol{x} \in \mathcal{D}_{\text{sel}}} \mathcal{L}_{\text{CE}}(f(\boldsymbol{x}_w), \hat{y}) L1=∣Dsel∣1∑x∈DselLCE(f(xw),y^),
- 其中 L CE \mathcal{L}_{\text{CE}} LCE 为交叉熵损失, x w \boldsymbol{x}_w xw 为弱增强样本, y ^ = argmax ( q t ) \hat{y} = \operatorname{argmax}(\boldsymbol{q}^t) y^=argmax(qt)。
-
伪标签生成:
- p i = { exp ( f i ( x ) 1 T ) ∑ j ∈ S exp ( f j ( x ) 1 T ) , i ∈ S , 0 , i ∉ S , \boldsymbol{p}_i = \begin{cases} \frac{\exp(f_i(\boldsymbol{x})^{\frac{1}{T}})}{\sum_{j \in S} \exp(f_j(\boldsymbol{x})^{\frac{1}{T}})}, & i \in S, \\ 0, & i \notin S, \end{cases} pi=⎩ ⎨ ⎧∑j∈Sexp(fj(x)T1)exp(fi(x)T1),0,i∈S,i∈/S,,
- 其中 T T T 为锐化参数, f i ( x ) f_i(\boldsymbol{x}) fi(x) 为模型输出的 logits。
-
MixUp 操作:
- λ ∼ Beta ( α , α ) \lambda \sim \operatorname{Beta}(\alpha, \alpha) λ∼Beta(α,α),
- λ ′ = max ( λ , 1 − λ ) \lambda' = \max(\lambda, 1 - \lambda) λ′=max(λ,1−λ),
- x ′ = λ ′ x 1 + ( 1 − λ ′ ) x 2 \boldsymbol{x}' = \lambda' \boldsymbol{x}_1 + (1 - \lambda') \boldsymbol{x}_2 x′=λ′x1+(1−λ′)x2,
- p ′ = λ ′ p 1 + ( 1 − λ ′ ) p 2 \boldsymbol{p}' = \lambda' \boldsymbol{p}_1 + (1 - \lambda') \boldsymbol{p}_2 p′=λ′p1+(1−λ′)p2。
-
一致性正则化损失:
- L cr = 1 2 n ∑ i = 1 2 n L CE ( f ( x i ′ ) , p i ′ ) \mathcal{L}_{\text{cr}} = \frac{1}{2n} \sum_{i=1}^{2n} \mathcal{L}_{\text{CE}}(f(\boldsymbol{x}_i'), \boldsymbol{p}_i') Lcr=2n1∑i=12nLCE(f(xi′),pi′)。
-
总损失:
- L all = L 1 + λ d ∗ L cr \mathcal{L}_{\text{all}} = \mathcal{L}_1 + \lambda_d * \mathcal{L}_{\text{cr}} Lall=L1+λd∗Lcr,
- λ d = ( 1 − r s ) ∗ λ cr \lambda_d = (1 - r_s) * \lambda_{\text{cr}} λd=(1−rs)∗λcr,
- 其中 r s r_s rs 为选择比率, λ cr \lambda_{\text{cr}} λcr 为超参数。
提出的创新点
-
交叉选择策略:
- 利用双模型 Θ ( 1 ) \Theta^{(1)} Θ(1) 和 Θ ( 2 ) \Theta^{(2)} Θ(2) 互助选择置信伪标签,通过不同决策边界校正误差。
- 基于历史预测的高置信度和低波动性标准,实现高精度标签筛选(实验表明在 CIFAR 数据集上准确率和选择比率均超 90%)。
-
Co-mix 一致性正则化:
- 结合弱增强和强增强生成伪标签,避免未选择样本的浪费。
- 引入 MixUp 增强数据,提升一致性正则化的效果,弥补传统半监督方法的不足。
-
动态损失平衡:
- 通过 λ d \lambda_d λd 动态调整监督损失和正则化损失的权重,使训练后期更倾向于监督学习,减少噪声干扰。
详细说明
交叉选择策略
- 实现细节:通过记忆库 MB 记录 t t t 个 epoch 的 softmax 输出,结合三个标准筛选标签。双模型交叉训练增强鲁棒性,测试时平均输出提升稳定性。
- 优势:相比单一模型,交叉选择显著提高了选择准确率(见 Table 2),尤其在噪声较高的场景下。
Co-mix 正则化
- 实现细节:对所有样本应用两种增强,交叉生成伪标签后用 MixUp 混合,生成 2 n 2n 2n 个训练对。锐化操作使伪标签更接近 one-hot 分布。
- 优势:实验(Table 5)表明,应用于所有数据的正则化比仅限于未选择数据效果更好,与选择策略形成互补。
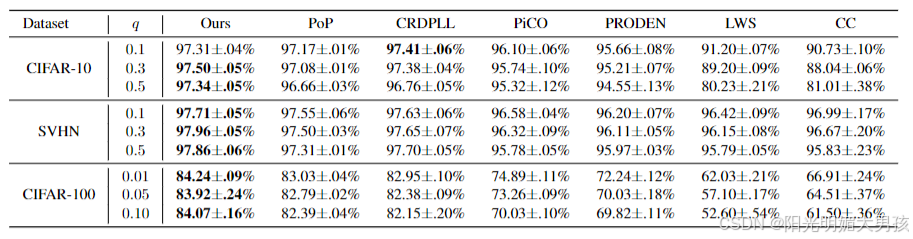
实验验证
- 数据集:SVHN、CIFAR-10、CIFAR-100,使用不同噪声水平 q q q 测试。
- 结果:CroSel 在多数设置下优于现有方法(如 PiCO、PRODEN),在 CIFAR-100 上提升显著(Table 1)。
- 消融研究:证明每个组件的重要性(Table 4),参数 t t t 和 γ \gamma γ 的选择对性能影响有限但需平衡(Table 6)。
脑图
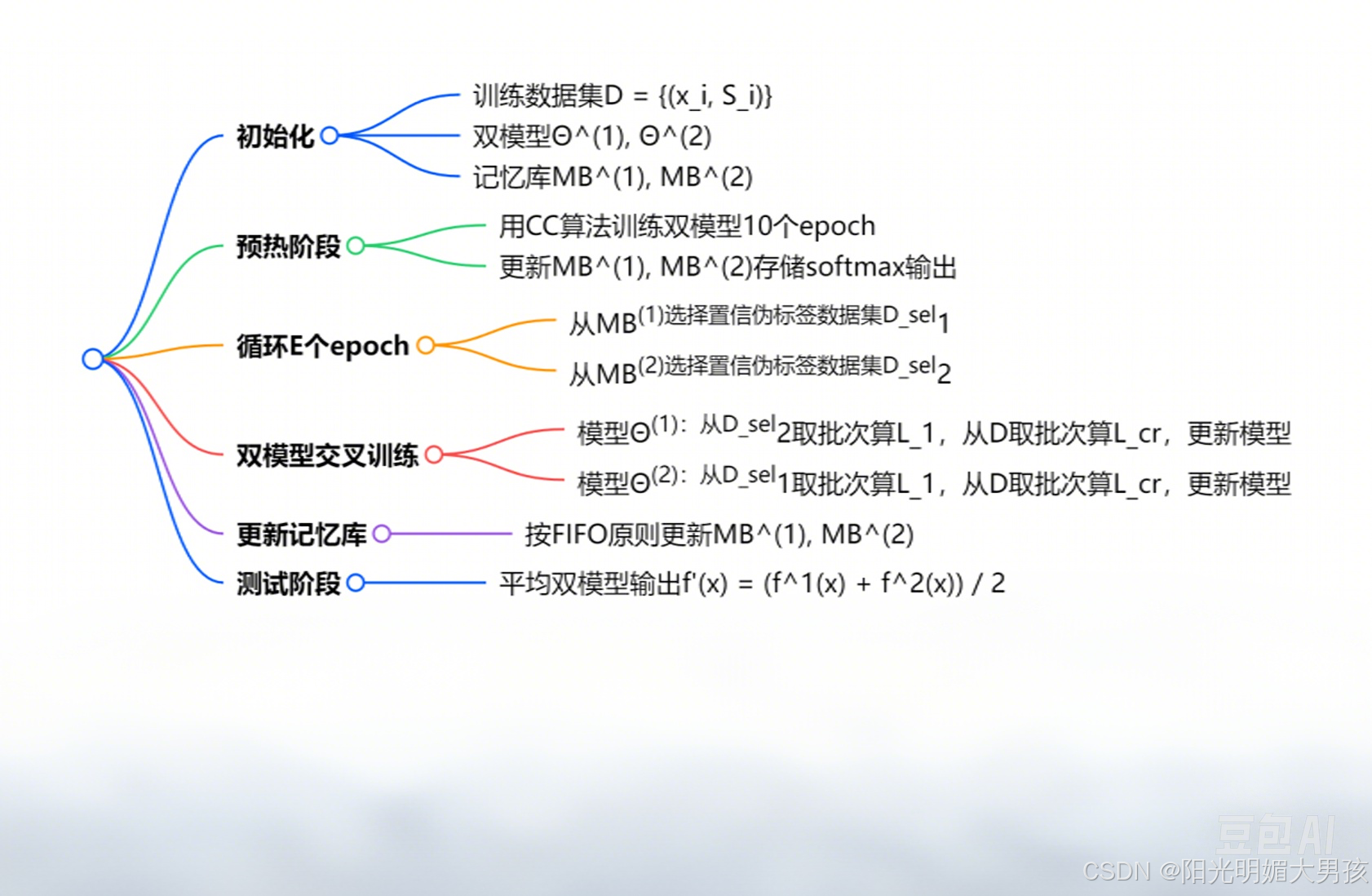
算法流程图
与其他算法性能对比
总结:
CroSel通过创新的标签选择策略和一致性正则化机制,在部分标签学习任务中取得了显著的性能提升,并且成功解决了标签噪声和样本浪费的问题。