核心思想就是在做bootstrapping之前再向前多走几步
7.1 n-step TD Prediction
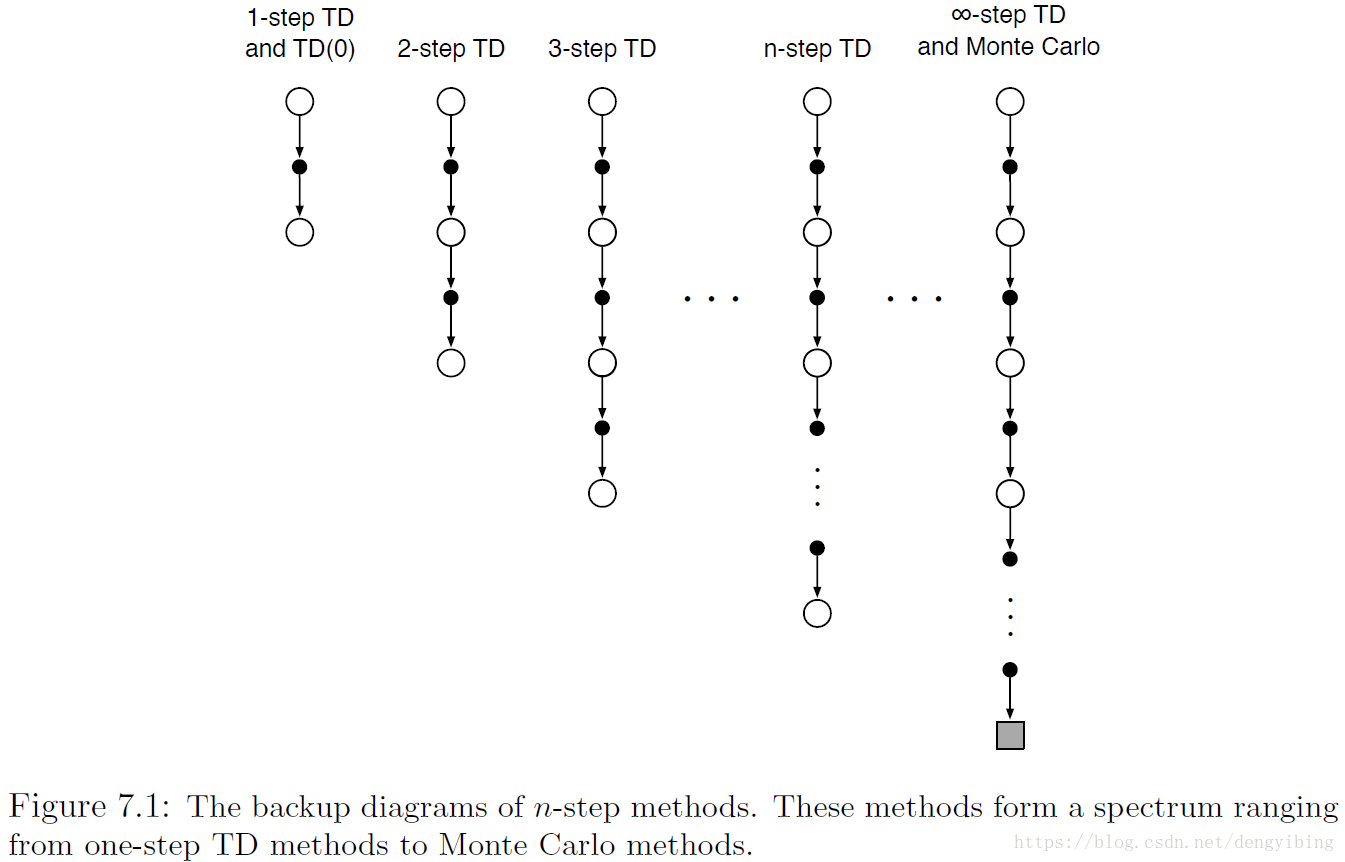
temporal difference 扩展了n步,这就被称为n-step TD methods
n-step returns
Gt:t+n≐Rt+1+γRt+2+⋯+γn−1Rt+n+γnVt+n−1(St+n)
其中
Vt:S→R
这里是在t时刻对
vπ
的估计
因为又向后看了几步,所以只有等到得到
Rt+n
和计算出
Vt+n−1
之后才能做更新
Vt+n(St)≐Vt+n−1(St)+α[Gt:t+n−Vt+n−1(St)],0≤t≤T

error reduction property of n-step returns
the worst error of the expected n-step return is guaranteed to be less than or equal to
γn
times the worst error under
Vt+n−1
:
maxs|Eπ[Gt:t+n|St=s]−vπ(s)|≤γnmaxs|Vt+n−1(s)−vπ(s)|
这表明所有的n-step TD方法在合适的技术条件下都收敛到正确的预测
7.2 n-step Sarsa
跟之前介绍的Sarsa相比,只有G变成了n-step returns
Gt:t+n≐Rt+1+γRt+2+⋯+γn−1Rt+n+γnQt+n−1(Stn,At+n),n≥1,0≤t<T−n
更新公式也基本没有发生变化
Qt+n(St,At)≐Qt+n−1(St,At)+α[Gt:t+n−Qt+n−1(St,At)],0≤t≤T


对于上图展示的Expected Sarsa。跟n-step Sarsa类似,除了最后考虑的一项不同。
Gt:t+n≐Rt+1+⋯+γn−1Rt+n+γnV¯t+n−1(St+n),t+n<T,
这里的不同点有
Gt:t+n≐Gt for t+n≥T
,
其中
V¯t(s)
是
expected approximte value of state s
V¯t(s)≐∑aπ(a|s)Qt(s,a),for all s∈S
7.3 n-step On-policy Learning by Importance Sampling
这一节有关于off-policy learning很好的介绍。off-policy learning就是 学习一个policy
π
的值,同时遵循另外一个policy b的experience。通常,
π
是对当前action-value估计的greedy policy,而b是一个跟具有探索性的policy,或许是
ε-greedy
还是要用上 importance sampling ratio
ρt:h≐∏k=tmin(k,T−1)π(Ak|Sk)b(Ak|Sk)
更新公式
Vt+n(St)≐Vt+n−1(St)+αρt:t+n−1[Gt:t+n−Vt+n−1(St)],0≤t<T
off-policy form n-step Sarsa
Qt+n(St,At)≐Qt+n−1(St,At)+αρt+1:t+n−1[Gt:t+n−Qt+n−1(St,At)],0≤t<T

7.4 *Per-decision Off-policy Methods with Control Variates
A more sophisticated approach would use per-decision importance sampling ideas
n-step returns可以写为
Gt:h=Rt+1+γGt+1:h,t<h<T,
off-policy definition of the n-step return ending at horizon
Gt:h≐ρt(Rt+1+γGt+1:h)+(1−ρt)Vh−1(St),t<h<T,(7.13)
同时有
Gh:h≐Vh−1(Sh)
上式7.13中的第二项被称为
control variate
control variate 不会改变期望更新,因为
在5.9节介绍过,importance sampling ratio的期望值是1。
An off-policy form with control variates
Gt:h≐Rt+1+γ(ρt+1Gt+1:h+V¯h−1(St+1)−ρt+1Qh−1(St+1,At+1)),=Rt+1+γρt+1(Gt+1:h+Qh−1(St+1,At+1))+γV¯h−1(St+1),t<h≤T.
如果
h<t
,则递归以
Gh:h≐Qh−1(Sh,Ah)
结束;如果
h≥T
,则递归以
GT−1:T≐RT
结束。
control variates就是一种减小方差的方法
7.5 Off-policy Learning Without Importance Sampling: The n-step Tree Backup Algorithm
不需要importance sampling的off-policy方法

tree-backup n-step return的一般形式
Gt:t+n≐Rt+t+γ∑α≠At+1π(a|St+1)Qt+n−1(St+1,a)+γπ(At+1,St+1)Gt+1:t+n,t<T−1
当n=1时,
GT−1:T≐RT
上述action-value用于n-step Sarsa
Qt+n(St,At)≐Qt+n−1(St,At)+α[Gt:tn−Qt+n−1(St,At)],0≤t<T,

7.6 *A Unifying Algorithm: n-step
Q(δ)
跟前面描述的类似,就是往前看的方式变了,其他的都是一样的,看下图

改写7.16的形式为如下:
Gt:h=Rt+1+γ∑a≠At+1π(a|St+1)Qh−1(St+1,a)+γπ(At+1|St+1)Gt+1:h=Rt+1+γV¯h−1(St+1)−γπ(At+1|St+1)Qh−1(St+1,At+1)+γπ(At+1|St+1)Gt+1:h=Rt+1+γπ(At+1|St+1)(Gt+1:h−Qh−1(St+1,At+1))+γV¯h−1(St+1),
把其中的
π(At+1|St+1)
替换成importance-sampling ratio
ρt+1
Gt:h≐Rt+1+γ(δt+1ρt+1+(1−δt+1)π(At+1|St+1))(Gt+1:h−Qh−1(St+1,At+1))+γV¯h−1(St+1)
对于
t<h≤T
,如果
h<T
,则递归式最后以
Gh:h≐0
结束;如果
h=T
,则递归式最后以
GT−1:T≐RT
结束。
