模型架构
与大多数编码器—解码器架构设计不同的是,Deeplab 提供了一种与众不同的语义分割方法。Deeplab 提出了一种用于控制信号抽取和学习多尺度语境特征的架构。

Deeplab 把在 ImagNet 上预训练得到的 ResNet 作为它的主要特征提取网络。但是,它为多尺度的特征学习添加了一个新的残差块。最后一个 ResNet 块使用了空洞卷积(atrous convolution),而不是常规的卷积。此外,这个残差块内的每个卷积都使用了不同的扩张率来捕捉多尺度的语境信息。
另外,这个残差块的顶部使用了空洞空间金字塔池化 (ASPP,Atrous Spatial Pyramid Pooling)。ASPP 使用了不同扩张率的卷积来对任意尺度的区域进行分类。
为了理解 Deeplab 的架构,我们需要着重注意这三个部分。(i)ResNet 架构,(ii) 空洞卷积,(iii) 空洞空间金字塔池化(ASPP)。接下来我们将逐一介绍这几个部分。
ResNets
ResNet 是一个非常流行的深度卷积神经网络架构,它赢得了 ILSVRC 2015 分类任务挑战赛的冠军。它的主要贡献之一就是提供了简化深度学习模型训练的框架。
在 ResNet 的原始形式中,它含有 4 个计算模块。每个模块包含不同数量的残差单元。这些单元以特别的形式执行一系列的卷积运算。同样,每个模块都夹杂了最大池化操作来减少空间维度。
原始论文提出了两种残差单元:基线块和瓶颈块。
基线块包含两个 3x3 的卷积,卷积中使用了 BN(批归一化)和 ReLU 激活函数。
神经网络训练之数据归一化处理。在机器学习中领域中的数据分析之前,通常需要将数据标准化,利用标准化后得数据进行数据分析。不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
归一化用一句话说就是:把数据经过处理后使之限定在一定的范围内。比如通常限制在区间[0, 1]或者[-1, 1]
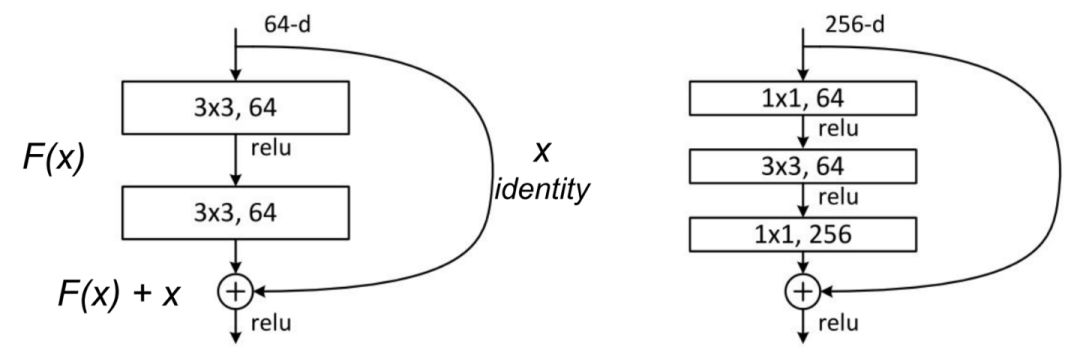
残差模块。左:基线块;右:瓶颈块。
第二个是瓶颈块,它包括三个堆叠的部分,用一系列的 1x1、3x3 和 1x1 的卷积代替了之前的设计。两个 1x1 的卷积操作被用来减少和恢复维度。这使得中间的 3x3 的卷积可以在一个密度相对较低的特征向量上进行操作。此外,每个卷积之后、每个非线性 ReLU 之前都应用了 BN。
为了有助于澄清这个问题,我们将这一组操作定义为一个输入为 x 的函数 F——F(x)。
在 F(x) 中的非线性变换之后,这个单元将 F(x) 的结果和原始输入 x 相结合。这种结合是通过对两个函数求和得到的。原始输入 x 和非线性函数 F(x) 合并带来了一些优势。它使得前面的层可以访问后面层的梯度信号。换句话说,跳过 F(x) 上的操作允许前面的层访问更强的梯度信号。这种类型的连接已经被证明有助于更深网络的训练。
当我们增加模型容量时,非瓶颈单元也表明有助于准确率的提高。然而,瓶颈残差单元具有一些实际优势。首先,它们在几乎相同数量的参数下可执行更多的计算。第二,它们与非瓶颈单元的计算复杂度相似。
在实际中,瓶颈单元更适合于训练更深的模型,因为它们需要的训练时间和计算资源更少。
在我们的实现中,我们将使用完全预激活残差单元(full pre-activation Residual Unit),与标准瓶颈单元的唯一区别在于 BN 和 ReLU 激活函数的放置顺序。对于完全预激活,BN 和 ReLU(按此顺序)出现在卷积之前。
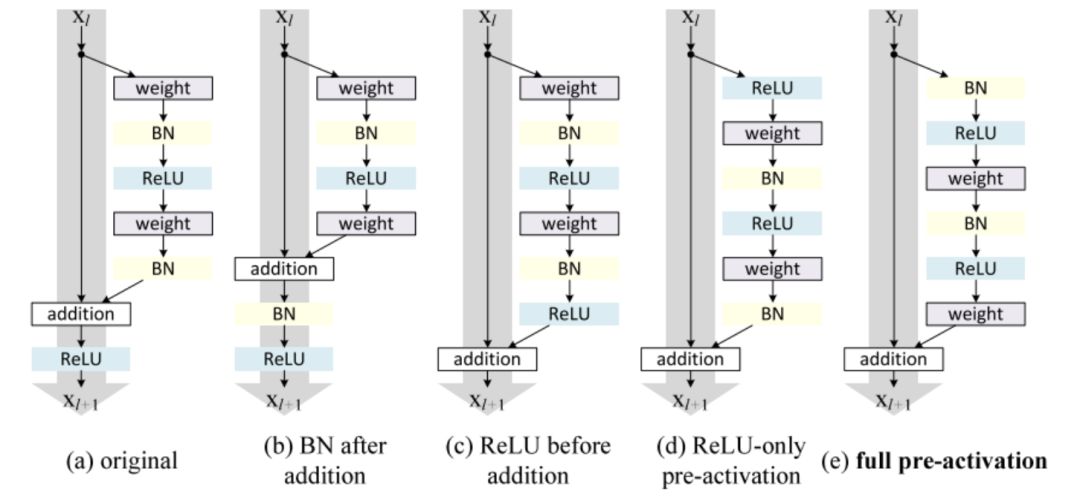
不同的 ResNet 构建模块块体系架构。最左边:原始 ResNet 模块;最右边:改进的完全预激活版本。
正如《Identity Mappings in Deep Residual Networks》中所展示的一样。完全预激活单元要优于其他的变体。
注意,这些设计之间的唯一区别是卷积堆栈中 BN 和 ReLU 的顺序。
空洞卷积
空洞卷积(或者扩张卷积)是具有一个因子的常规卷积,这个因子使得我们能够扩展滤波器的视野。
以 3×3 卷积滤波器为例。当扩张因子等于 1 时,它的行为类似于标准卷积。但是,如果将扩张因子设置为 2,则它具有扩大卷积核的效果。
理论上,它是这样工作的:首先,根据扩张率对卷积滤波器进行扩张。然后,它用零填充空白空间,创建稀疏的类似滤波器。最后,使用扩张的滤波器进行常规卷积。
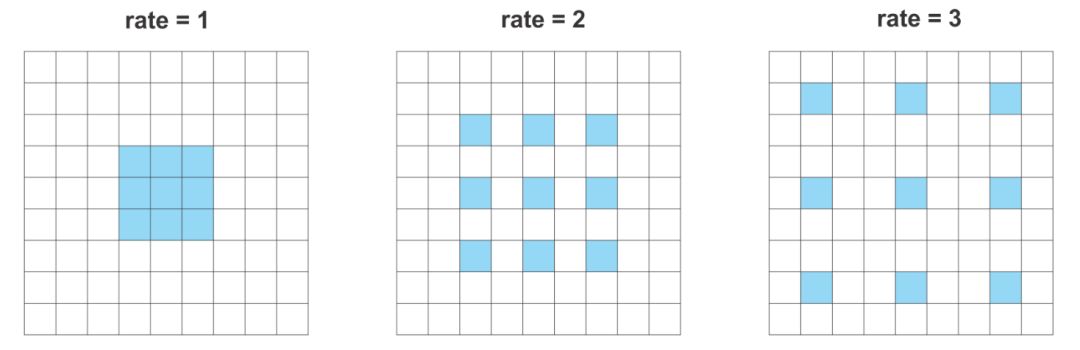
不同扩张率的空洞卷积
因此,大小为 3x3、扩张率为 2 的卷积将使其能够覆盖 5x5 的区域。然而,因为它的作用就像一个稀疏的过滤器,只有原始的 3 x3 单元将执行计算并生成结果。
以类似的方式,扩张因子为 3 的常规 3×3 的卷积能够得到对应的 7×7 区域的信号。
这种效果允许我们控制计算特征响应的分辨率。此外,空洞卷积在不增加参数数量或计算量的情况下增加了更大范围的语境信息。
Deeplab 还表明,必须根据特征图的大小来调整扩张率。他们研究了在小特征图上使用大扩张率的结果。

给小特征图设置更大的扩张率的副作用。对于 14×14 的输入图像,使用扩张率为 15 的 3×3 卷积,其结果和常规的 1×1 卷积类似。
当扩张率非常接近特征图的尺寸时,一个常规的 3×3 的空洞滤波器的效果与标准的 1×1 卷积是一样的。
换句话说,空洞卷积的效率依赖于对扩张率的选择。由于这一原因,理解神经网络中的输出步长(output stride)的概念是很重要的。
输出步长反映输入图像大小与输出特征图大小的比率,它定义了输入向量在通过网络时经受的信号抽象程度。
输出步长为 16,图像大小为 224x224x3 时,输出特征向量比输入图像的维度小 16 倍,变成了 14x14。
此外,Deeplab 还讨论了不同输出步长对分割模型的影响。Deeplab 认为过强的信号抽象不利于密集预测任务。总之,具有较小输出步长 (较弱信号抽象) 的模型倾向于输出更精细的分割结果。然而,使用较小的输出步长训练模型需要更多的训练时间。
Deeplab 还展示了两种输出步长(8 和 16)设置下的结果。和预期的一样,步长等于 8 能够产生稍微好一些的结果。在这里,出于实际原因,我们选择了 16 为输出步长。
此外,由于空洞卷积块没有实现降采样,所以 ASPP 也运行在相同的特征响应大小上。因此,它允许使用相对较大的扩张率从多尺度的语境中学习特征。
新型空洞残差块包含三个残差单元。三个单元都总共拥有三个 3×3 的卷积块。在多重网格(multigrid)方法的启发下,Deeplab 为每个卷积设置了不同的扩张率。总之,多重网格为三个卷积中的每个卷积定义了不同的扩张率。
在实际中:
对于 block 4,当输出步长是 16,多重网格为(1,2,4)的时候,这三个卷积的扩张率分别是(2,4,8)。
空洞空间金字塔池化
空洞空间金字塔池化(ASPP)的思想是提供具有多尺度信息的模型。为了做到这一点,ASPP 添加了一系列具有不同扩张率的空洞卷积。这些扩张率是被设计用来捕捉大范围语境的。此外,为了增加全局的语境信息,ASPP 还通过全局平均池化(GAP)结合了图像级别的特征。
这个版本的 ASPP 包含 4 个并行的操作。它们分别是一个 1×1 的卷积以及三个 3×3 的卷积(扩张率分别是(6,12,18))。正如我们前面所提及的,现在,特征图的标称步长(nominal stride)是 16.
在原始实现的基础上,我们使用 513 x513 的裁剪尺寸进行训练和测试。因此,使用 16 的输出步长意味着 ASPP 接收大小为 32 x32 的特征向量。
此外,为了添加更多全局语境信息,ASPP 结合了图像级别的特征。首先,它将 GAP 应用于从最后一个空洞块输出的特征上。其次,所得特征被输入到具有 256 个滤波器的 1x 1 卷积中。最后,将结果进行双线性上采样到正确的维度大小。
参考:http://tech.ifeng.com/a/20180326/44919779_0.shtml