Java语言最大的优势除了它的平台无关性之外,还有它的自动内存分配和垃圾收集技术,本节我先来总结一下垃圾收集相关的内容。本文将从解答以下三个问题的角度来展开:
1、哪些内存需要回收?
2、什么时候回收?
3、如何回收?
话不多说,直接开始。
一、哪些内存需要回收?
根据之前的介绍,Java内存其实可分为两种类型:
一种是线程私有的,包括程序计数器、虚拟机栈和本地方法栈,这类内存在编译期就已经知道需要分配多少内存,且随线程而生,随线程而灭,所以在方法或线程结束时,内存就会跟着被回收;另一种是线程共享的,包括堆内存和方法区,这类内存只有在运行期间才知道内存分配情况,且内存分配和垃圾回收都是动态的,所以GC关注的也就是这部分内存。
二、什么时候回收?
要想回收一块内存,必须保证内存中的对象”已死“,那么如何判断对象已死呢,因此产生了一些判断对象是否已死的算法,主要有引用计数算法和可达性分析算法。
1、引用计数算法:它的原理是给每个对象添加一个引用计数器,当这个对象被引用时,计数器加1,引用失效时,计数器减1,任何时刻,只有引用计数器为0的对象才会被当成”已死对象“,从而被垃圾收集器回收。但是,大多数主流的Java虚拟机中并没有采用这种方式,因为它无法解决对象互相引用的问题。来看一个例子:
首先创建一个ReferenceCountingGC类
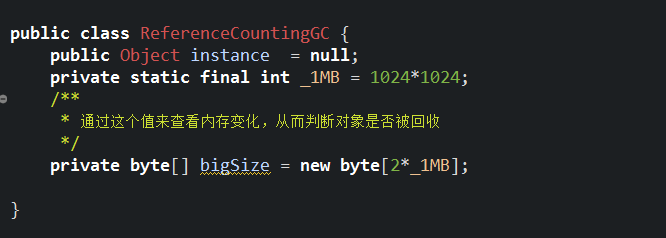
然后创建该类的两个实例并互相引用
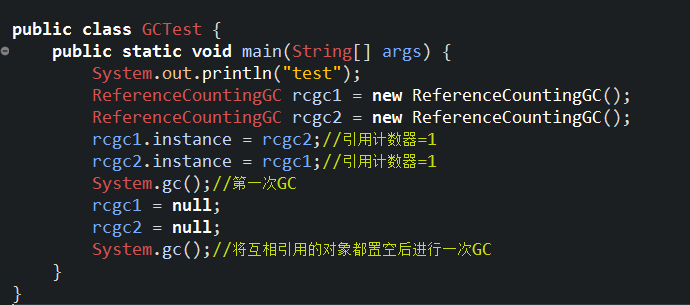
从上面的代码中可以知道,两个实例rcgc1和rcgc2分别会占用4096的堆内存,第一次GC发生的时候,它们在互相引用,所以引用计数都为1,此时理应不会被回收;第二次GC时,虽然两个对象都为空了,但是它们仍然互相引用,引用计数器也都是1,按理说也不会被回收,那么到底有没有被回收呢?我们看一下GC日志,因为有关GC日志的内容上一节已经介绍,这里就不再赘述 。下面是我打印出的GC日志:
1 Java HotSpot(TM) 64-Bit Server VM (25.121-b13) for windows-amd64 JRE (1.8.0_121-b13), built on Dec 12 2016 18:21:36 by "java_re" with MS VC++ 10.0 (VS2010) 2 Memory: 4k page, physical 4057600k(891872k free), swap 8113324k(4643664k free) 3 CommandLine flags: -XX:InitialHeapSize=20971520 -XX:MaxHeapSize=20971520 -XX:MaxNewSize=10485760 -XX:NewSize=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC 4 0.200: [GC (System.gc()) [PSYoungGen: 5243K->680K(9216K)] 5243K->4784K(19456K), 0.0025843 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 5 0.202: [Full GC (System.gc()) [PSYoungGen: 680K->0K(9216K)] [ParOldGen: 4104K->4664K(10240K)] 4784K->4664K(19456K), [Metaspace: 2590K->2590K(1056768K)], 0.0138331 secs] [Times: user=0.03 sys=0.00, real=0.01 secs] 6 0.217: [GC (System.gc()) [PSYoungGen: 0K->0K(9216K)] 4664K->4664K(19456K), 0.0003674 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 7 0.217: [Full GC (System.gc()) [PSYoungGen: 0K->0K(9216K)] [ParOldGen: 4664K->568K(10240K)] 4664K->568K(19456K), [Metaspace: 2590K->2590K(1056768K)], 0.0053836 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] 8 Heap 9 PSYoungGen total 9216K, used 82K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000) 10 eden space 8192K, 1% used [0x00000000ff600000,0x00000000ff614920,0x00000000ffe00000) 11 from space 1024K, 0% used [0x00000000fff00000,0x00000000fff00000,0x0000000100000000) 12 to space 1024K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000) 13 ParOldGen total 10240K, used 568K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000) 14 object space 10240K, 5% used [0x00000000fec00000,0x00000000fec8e188,0x00000000ff600000) 15 Metaspace used 2597K, capacity 4486K, committed 4864K, reserved 1056768K 16 class space used 286K, capacity 386K, committed 512K, reserved 1048576K
上图是所有的GC日志,但是我们只需要看4~7行的即可,为了看的更清晰,我把它们单独提取出来,如下图所示:

因为System.gc()发生时会"Stop The World",所以只需要看Full GC所在的行即可,又因为两个都对象实例,所以它们在堆内存区域,该区域的内存变化为:
第一次GC后:内存由4784KB变为4664KB;第二次GC后:内存由4664KB变为568KB,很明显,第二次GC后内存减少了4096KB,因为我们在每个对象中定义了一个2048KB的字节数组,所以一个对象会占用2048KB,两个就是4096KB,由此可见,第一次GC时没有被回收,第二次GC时虽然两个对象的引用计数器都为1,但还是被回收了。所以通过引用计数算法判定一个对象是否已死也不是完全合理的,于是就有了第二中算法---可达性分析算法。
2、可达性分析算法
基本思路是:通过一系列被称为“GC Root”的对象作为起始点,从起始点开始往下搜索,搜索时所经过的路径称为引用链,当一个对象到"GC Root"没有任何引用链时,则证明此对象时不可达的,所以就可以被回收。如下图所示:
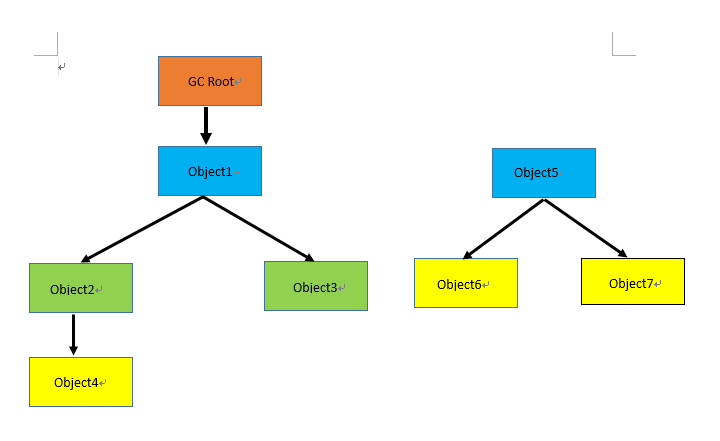
上图中,Object5、Object6、Object7虽然互相引用,但是它们没有到GC Root的引用链,即不可达,所以可以被回收。
在JAVA中,可以作为GC Root的对象有下面四种:
1)虚拟机栈(栈帧中的常量表)中引用的对象;
2)方法区中类静态属性引用的对象;
3)方法去中常来那个引用的对象;
4)本地方法栈中JNI引用的对象;
在可达性算法分析中,即使一个对象没有到GC Root的引用链,也不意味着它们就真的已死,它们只是暂时处于【缓刑】阶段,要宣告一个对象的真正死亡,至少需要两次标记过程。如果一个对象没有到GC Root的引用链,将会进行第一次标记筛选的过程,筛选标准是有没有必要执行finalize方法,如果没有覆盖finalize方法或者已经被虚拟机执行过,则意味着没必要执行。如果有必要执行finalize方法,该对象将会被放在一个叫做【F-Queue】的队列中,稍后由虚拟机自行建立起的Finalizer线程执行,但是并不承诺必须等待它运行结束,因为有些对象执行finalize方法可能会比较慢,或者出现死循环什么的,此时如果一直等待势必会造成F-Queue队列中的其他对象处于等待状态,甚至导致整个内存回收崩溃。所以没有执行完finalize方法的对象,稍后GC会进行第二次小规模的标记,如果此时对象又与GC Root所在的对象树中任意一个对象建立关联,则意味它逃脱(自我拯救)成功,于是又被移除【即将回收】的队列,但是如果这时还是没有逃脱就只能被回收了。下面我用一个类似流程图的方式来说明一下标记的过程:
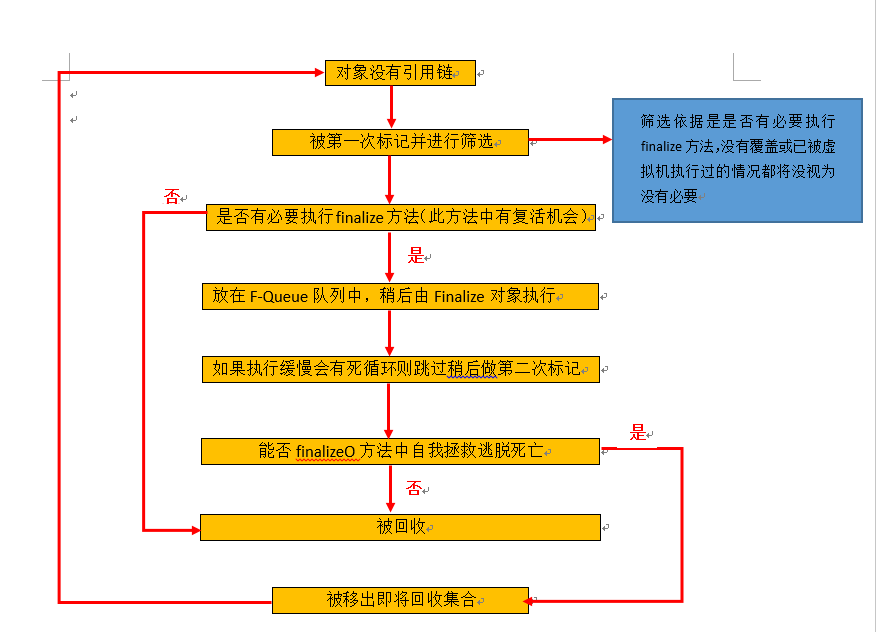
(用word画的,凑活看吧)
综上,当一个对象不能通过finalize方法逃脱死亡的话,就只能被回收。
三、Java中的引用
下面来插一段关于Java引用的知识点:
引用在Java中的定义是:如果引用类型的数据中存储的数值代表另一块内存的起始地址,就称这块内存代表着一个引用。这个定义有一个不足之处就是对象只有【被引用】和【不被引用】两种状态,但是有些对象我们希望当内存足够时能继续保留在内存够中,不够时将被回收,比如缓存。所以在JDK1.2之后堆引用的概念就进行了如下扩展,引用被分为强引用、软引用、弱引用和幽灵引用。
1)强引用(Strong Reference)
类似Object obg = new Objecct();这类的引用,只要强引用还存在,GC就永远不会回收被引用的对象;
2)软引用(Soft Reference)
比强引用弱一些,用来描述那些还有用但不是必须的对象。对于软引用关联着的对象,会在系统将要发生内存溢出之前放入回收范围进行二次回收,如果此时还没有足够内存将会发生内存溢出;
3)弱引用(Weak Reference)
同样用来描述那些还有用但非必须的对象,这类对象只能存活到下次GC之前,当GC工作时无论内存是否足够,都会被回收;
4)幽灵引用(Phantom Reference)
该引用没什么意义,也不会印象GC收集器对对象的回收,设置它的目的就是当对象被回收后系统会受到一个通知,跟它的名字幽灵很像有没有。
四、如何回收?
下面来解答第三个问题,如何回收?垃圾回收有下面四种算法,这里只介绍算法的思路。
1、标记-清理算法
所谓标记-清理算法,顾名思义就标出需要回收的对象,发生GC时回收标记出的对象。如下图所示:
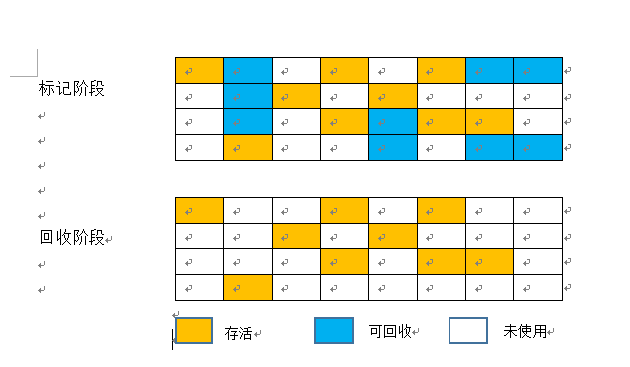
哎!用word粗制滥造的图实在是不能更丑,这篇完了就整一下我的电脑,用visio来画图了。
该算法的缺点是:
1)效率低下:标记和回收都低下,因为需要一个一个去标记和回收;
2)会产生大量碎片,不利于为大对象分配空间;
2、复制算法
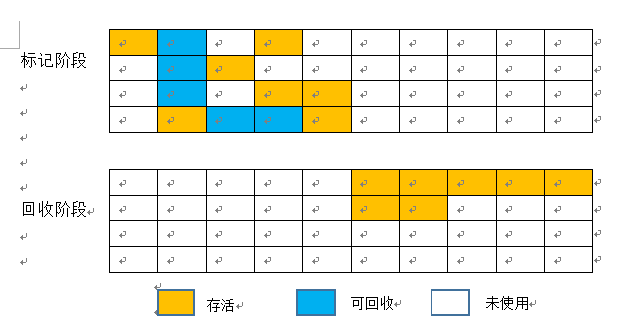
该算法的思路是:将可用的内存划分为大小相等的两块,每次只使用其中的一块,当这一块使用完时,将其中存活的对象复制到另一块中,然后一次性清理剩下的内存。它的优点是无需考虑碎片情况,缺点是内存利用率低,毕竟只用了总空间的一半。当然,聪明的程序员朋友们想出了一个更加优化的算法,就是不按1:1的比例进行划分,而是将内存分为一个Eden区和两个大小相同的Survivor区,因为新生代对象中的98%都是朝生夕灭,所以存活率不到10%,因此可以将Eden区和Survivor区的比例划分为8:1,每次使用Eden区和其中的一块Survivor区,当使用的内存区用完之后将存活下来的对象复制到另一个Survivor中,然后一次性清除另两个区中的空间。但是这也有一个问题啊,谁能保证每次存活的对象都不会超过10%,毕竟小概率事件也有发生的可能性。如果某次超过了10%,就需要将它所依赖的内存够进行分配担保,这个后面的文章中会介绍,现在简单说一下,所谓担保,就是当Survivor对象不够用时,用另外一块额外的内存(相当于担保人)来存放存活的对象。
下面是复制算法的示例图
1)优化前:
2)优化后:
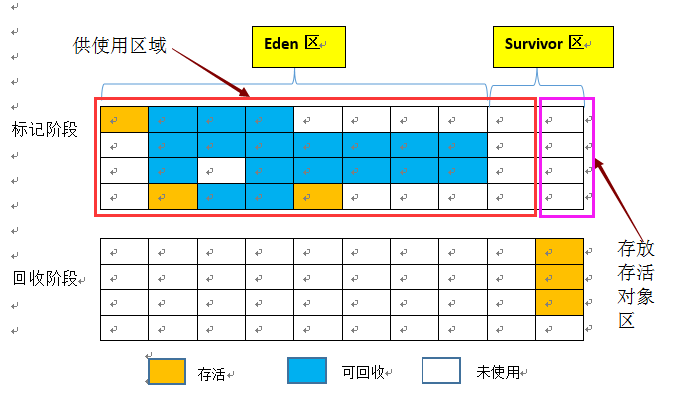
注意:当存活率较高时需要进行多册复制操作
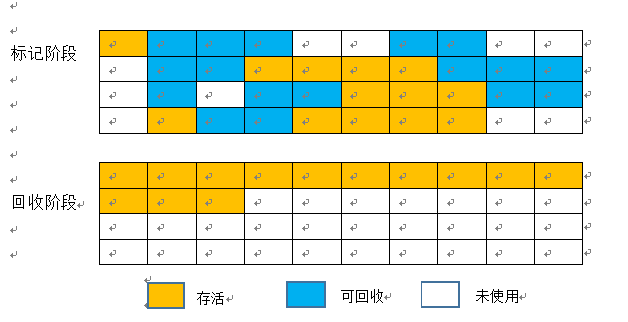
3、标记-清理算法
思路:标记可回收的对象之后不立即删除,而是将所有存活的对象都移向内存的一端,然后直接清除边界以外的所有内存,很明显,该算法的有点是:
1)空间利用率高,几乎是100%利用内存
2)清除速度快,只要知道了边界即可。
回收过程如下图所示:
4、分代手机算法
此算法没有特别之处,它只是将内存分为新生代和老年代,根据各年代内存的特点从前三种算法中选取最合适的,如针对存活率低死亡率高的新生代使用复制算法,而对于存活率高的老年代采用标记-清理或标记-整理算法。
好了,以上就是对垃圾收集器收集的对象、收集对象的时刻以及如何收集的全部内容,内容有点多,不足之处欢迎指正,毕竟现在已经是凌晨了,脑袋有点不清楚了~~~~