引言
Java开发经常需要借助各种集合类,常用的集合有List、Set和Map。Map存放的是key-value形式的数据,List与Set直接存放数据。List与Set的显著区别是,List中的数据是有序、可重复,而Set中的数据无序且不可重复。那么Set是如何实现数据的不可重复插入,本文以HashSet为例,分析HashSet是如何实现元素不可重复。
一、引入场景
首先,我们定义一个学生对象,包含简单的两个属性:学号(id)与姓名(name)。只要id相同,就认为对象是重复的。
-
public class Student {
-
private Integer id;
-
-
private String name;
-
-
public Student(Integer id, String name) {
-
this.id = id;
-
this.name = name;
-
}
-
-
-
public String toString() {
-
return "Student{" +
-
"id=" + id +
-
", name='" + name + '\'' +
-
'}';
-
}
-
}
-
public class HashSetDemo {
-
-
public static void main(String[] args) {
-
Set<Student> set = new HashSet<>();
-
Student student1 = new Student( 1001, "young");
-
Student student2 = new Student( 1001, "young");
-
set.add(student1);
-
set.add(student2);
-
-
set.forEach(student -> System.out.println(student));
-
}
-
}

看到这个结果应该很惊讶,我们期望的是Set中存放的数据不可重复,而代码里的两个Student对象,学号与姓名都相同,插入到HashSet中后应该只保留一个对象。问题出在了哪里?要想找出原因,只有去源码里寻找答案。
二、HashSet源码分析
阅读HashSet的源码,可以发现HashSet的源码逻辑很简单。只有两个field,分别为HashMap类型的map和一个傀儡对象PRESENT。
-
public class HashSet<E>
-
extends AbstractSet<E>
-
implements Set<E>, Cloneable, java. io. Serializable
-
{
-
static final long serialVersionUID = -5024744406713321676L;
-
-
private transient HashMap<E,Object> map;
-
-
// 傀儡对象,只是用来作为空的value值
-
private static final Object PRESENT = new Object();
-
-
/**
-
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
-
* default initial capacity (16) and load factor (0.75).
-
*/
-
public HashSet() {
-
map = new HashMap<>();
-
}
-
-
//...
-
}
-
public boolean add(E e) {
-
return map.put(e, PRESENT)== null;
-
}
三、浅析HashMap
HashMap的设计十分精巧,本文不作深入分析,只简要描述HashMap的原理。HashMap的结构是一个哈希数组,数组节点在数组中的下标由节点的哈希值决定。了解哈希数组的同学都知道,不同元素的哈希映射有可能是相同的,意味着两个完全不同的节点映射到相同的数组下标上。HashMap并不对映射到相同位置上的节点二次散列,而是将节点放在已有节点的尾端。因此,数组节点的类型实际上是一个链表结构。
了解了HashMap的数据结构后,就能明白HashMap中有两个主要的判断。当key-value键值对插入到HashMap中。
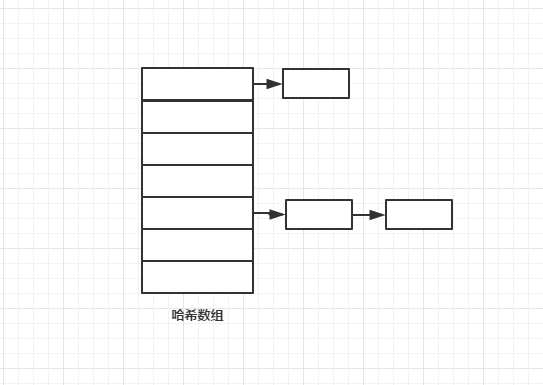
首先是对key值哈希,得到key在哈希数组中的下标。HashMap中哈希是调用对象key的hashCode()方法,然后再做异或处理。
如果当前下标上已经有值,说明有两个元素的映射到相同的下标。此时,需要第二次判断,调用key对象的equals方法,对象不相同则插入链表的表尾,对象相同则覆盖。
四、验证
根据前面的分析,改造我们定义的Student类,为Student类增加hashCode()与equals()方法。
-
public class Student {
-
private Integer id;
-
-
private String name;
-
-
public Student(Integer id, String name) {
-
this.id = id;
-
this.name = name;
-
}
-
-
-
public String toString() {
-
return "Student{" +
-
"id=" + id +
-
", name='" + name + '\'' +
-
'}';
-
}
-
-
-
public boolean equals(Object o) {
-
if ( this == o) return true;
-
if (o == null || getClass() != o.getClass()) return false;
-
-
Student student = (Student) o;
-
-
return id.equals(student.id);
-
}
-
-
-
public int hashCode() {
-
return id.hashCode();
-
}
-
}

此时,HashSet中只有一个对象。