1. Anaconda环境的安装。
到官网(点这里)下载对应的Anaconda安装包。Anaconda有Python 2.7和Python 3.6版本的,我这里下载的是Python 3.6版本,Anaconda集成了Python软件,安装好Anaconda之后就不需要另外安装Python了。
下载好的 .exe文件,直接点击安装。选择对应的安装目录,其他的都默认安装即可。
2. Pycharm的安装。
到官网(点这里)下载对应的Pycharm安装包。社区版是免费的。
下载好 .exe安装文件后选择好安装目录直接默认安装即可。
3. 配置Pycharm + Anaconda开发环境
安装好Pycharm后打开Pycharm。

点击Configure -> Settings
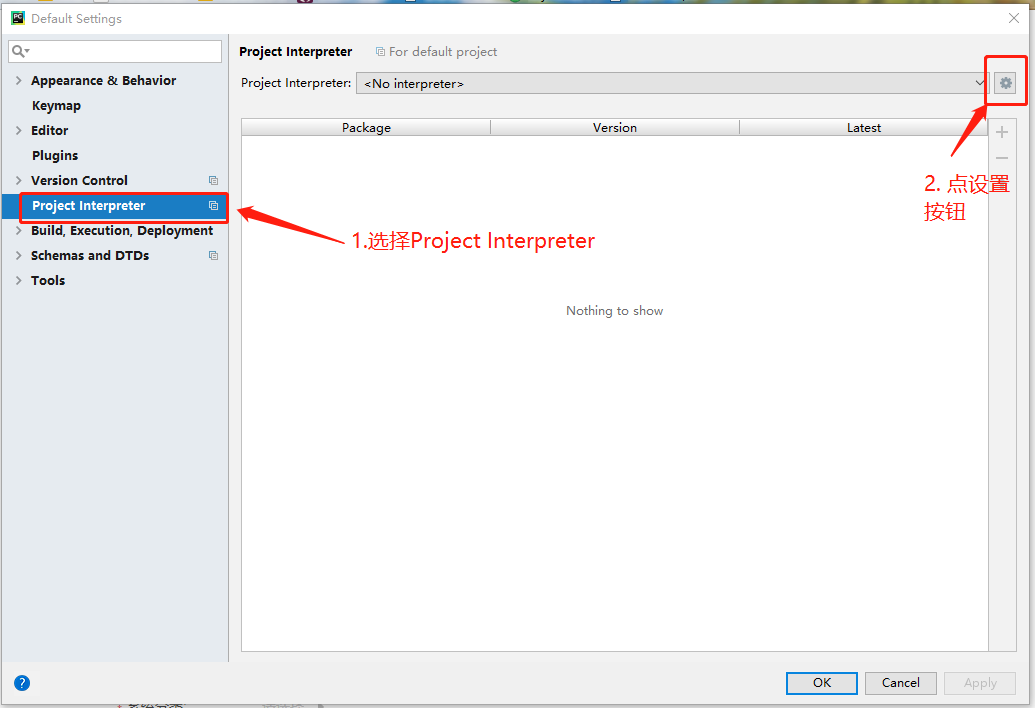
选择 Add local -> Conda Environment, 如果出现Anaconda installation is not found,用管理员身份打开CMD, 输入下面命令:
mklink /D %HOMEPATH%\anaconda C:\ProgramData\Anaconda3(红色为对应的Anaconda安装目录,具体参照这里)
选择好Anaconda 环境后点OK, 会创建一个Anaconda环境,
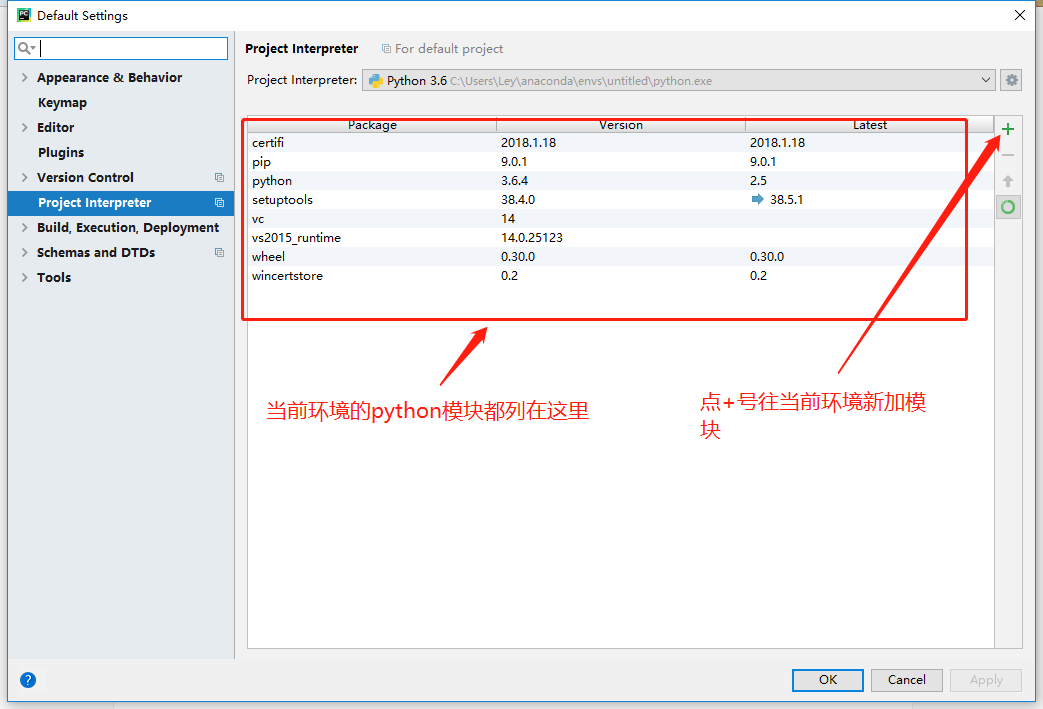
至此,Anaconda + Pycharm安装配置完成。
4. JDK 的安装
到官网(点这里)下载安装对应版本的JDK, 下载好安装包选择对应的安装路径安装即可。
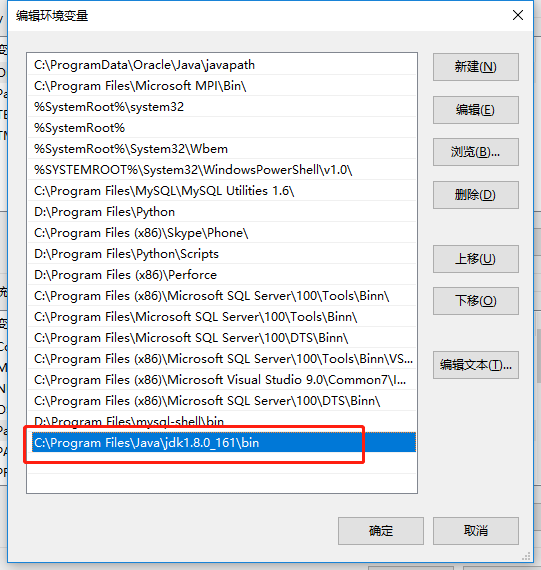
安装好jdk之后配置环境变量,在桌面右击【计算机】--【属性】--【高级系统设置】,然后在系统属性里选择【高级】--【环境变量】,然后在系统变量中找到“Path”变量,并选择“编辑”按钮后出来一个对话框,可以在里面添加上一步中所安装的JDK目录下的bin文件夹路径名:
测试java安装,新建一个CMD窗口,输入 Java -version,出现下图的java 版本信息即安装成功

5. 安装Spark
到Spark官网(点这里)下载对应的Spark安装包,注意选择的Spark版本及其对应的Hadoop版本
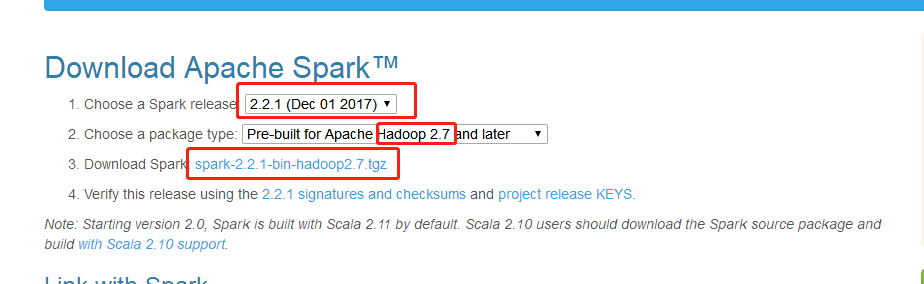
这里选的是Spark 2.2,Hadoop 2.7,点击下载压缩包。下载后得到一个下面这样的压缩文件,用解压软件解压:
![]()
重命名解压出来的文件夹名为Spark, 把文件夹复制到你想要的目录,我复制到D盘根目录下面。
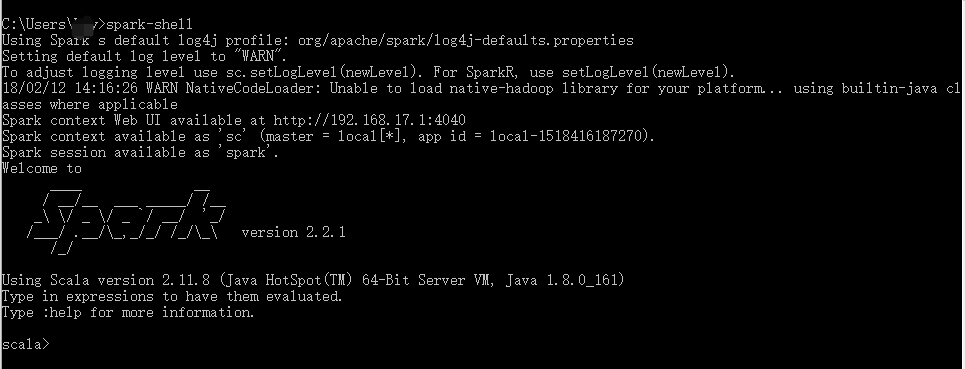
将Spark的bin目录添加到系统变量PATH里面,打开命令行输入 spark-shell,出现下面的说明Spark安装成功了。
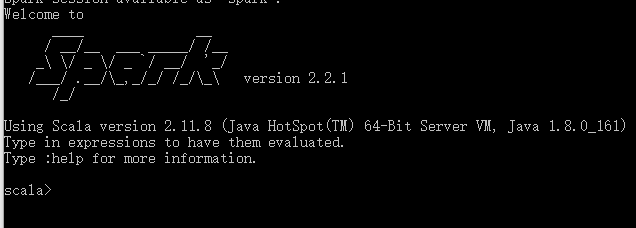
6. Hadoop 安装
到官网(点这里)下载对应的Hadoop版本,我们之前Spark对应的Hadoop是2.7的,所以这里选择2.7.1版本下载。
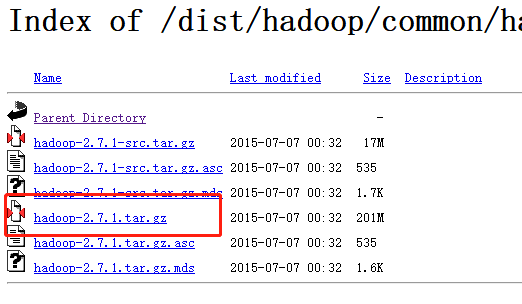
下载好安装包之后解压安装包,把文件夹名改成hadoop,并和Spark一样,将hadoop的bin目录加到系统变量path里面。
7. 配置Spark环境
CMD窗口输入spark-shell会报下面的错误,是因为Hadoop的bin目录下没有winutils.exe文件的原因。

到GitHub下载对应Hadoop版本的winutils.exe文件,我选择2.7.1版本的winutils.exe文件,下载好后放到Hadoop的bin目录下。
输入spark-shell会报下面python错误。

在系统变量path里面也加入python,指向Anaconda的Python执行文件。
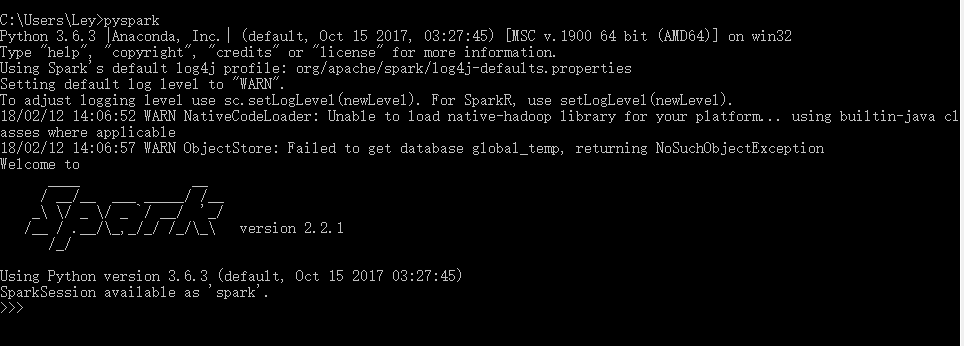
打开命令行,输入pyspark
最后总结下环境变量。
1. 新加系统环境变量:
HADOOP_HOME D:\hadoop
SPARK_HOME D:\spark
2. 在系统环境变量path中加入下面变量:
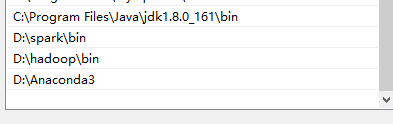
打开cmd, 输入spark-shell, 完美如下图:
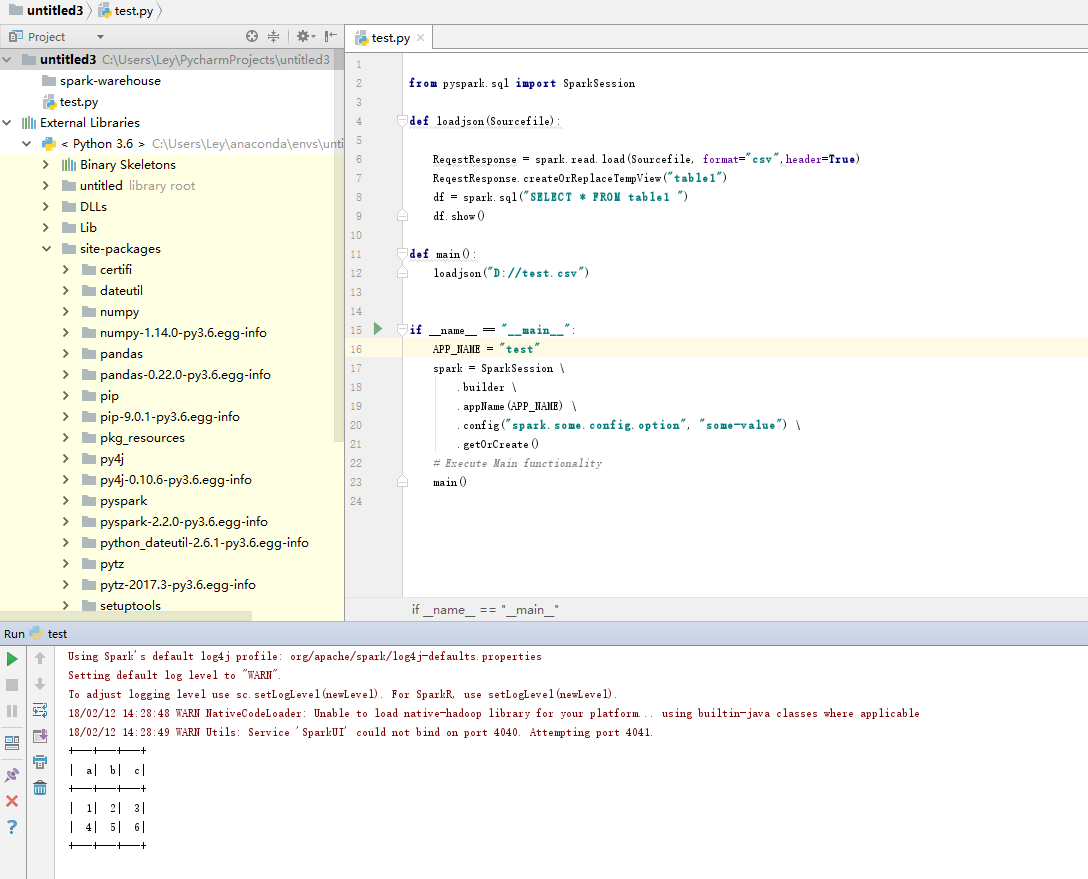
最后就可以打开Pycharm, 导入pyspark模块,开始玩转python版Spark了
测试: