Abstract
1. image-to-image trainslation
存在的两个问题:
1)many-to-one:将照片映射为edges/segments/semantic labels
2)one-to-many:将labels/sparse user inputs映射为真实图片
一般的做法是predict pixels form pixels;作者的创新点为develop a common network,通用网络,可以用来进行Image translation领域的各种任务。
2. naive方法得到的通常是比较blurry的结果,原因是目标只是通过最小化真实的和预测的像素之间的欧氏距离,因此平均得到的效果应该会使得损失函数最小,所以输出的结果就会变得很blurry以及没有鲜明的色彩;作者针对这个提出的想法是,只明确high-level的目标,即让输出图片和真实图片看起来没有太大的差别。
3.作者表明自己这篇文章的两个主要贡献是:
1)在image-to-image trainslation领域创新了一种通用算法
2)简单网络就可以达到很好的效果

Related Work
1.图像建模中的结构化损失
传统的image-to-image trainslation都是对每个像素进行预测/回归,此时我们对输出空间的结构化并不在意,即,认为输出图片的像素之间是相互独立的;而cGAN则使用了结构化损失;作者提出的损失的特点是为损失可以被学习而且it can penalize any possible structure that differs between output and target;作者提出的结构的特点是a)nothing is application-specific;b)U-Net based architecture;c)convolutional "PatchGAN" classifier as Discriminator
2.方法
GANs G: z映射到y
cGANs G: {x, z}映射到y
2.1 Objective
cGAN
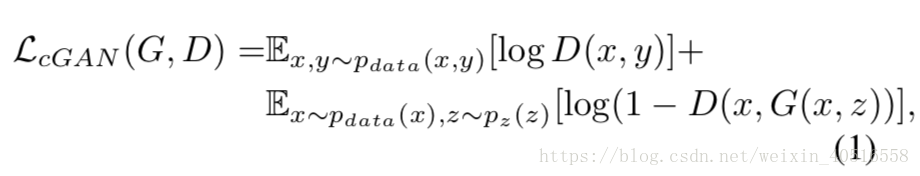
GAN
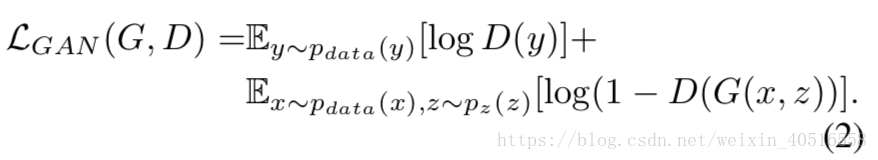
L1 instead of L2
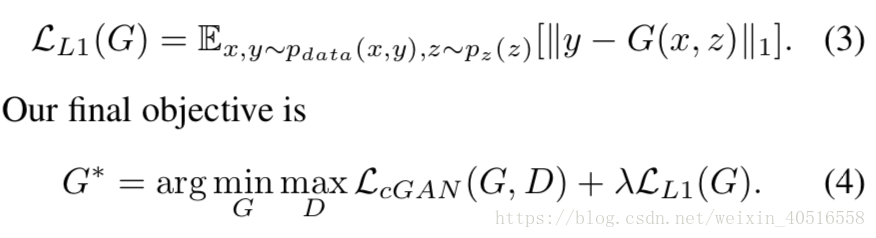
注意,没有噪声z,输出就是确定的。因此要在输入x的基础上加上噪声z。
2.2 网络架构
Generator、Discriminator的结构参考了DCGAN, 两者modules的结构为conv-BN-ReLu。
2.2.1 Generator with skips
image-to-image trainslation结果的特点为input and output differ in surface appearance but with same underlying structure
1.最开始解决这种问题的结构为Encoder-Decoder,即输入一张图片先downsample,再upsample,中间是一个bottleneck layer,这种结构存在的问题是输入和输出之间存在很多的底层信息共享。
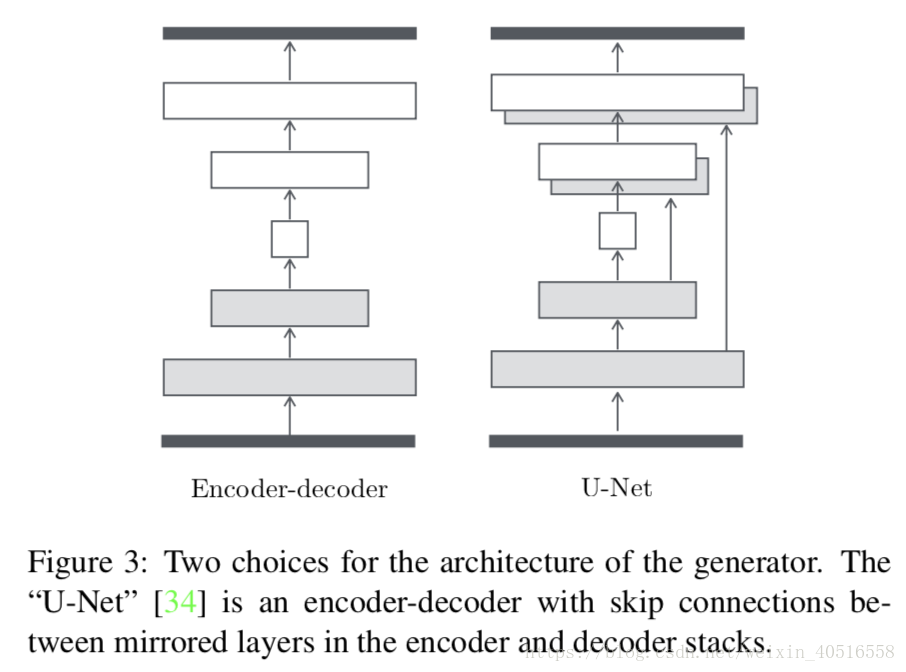
为了避免这种情况作者添加了skip connections,并遵从了U-Net大致形式,即在第i层和第n-i层之间添加skip connections,其中n为总层数。具体结构参考(https://arxiv.org/pdf/1505.04597.pdf)
2.在image generation问题上,L2总是会产生blurry的结果,这种损失在high-frequence上的表现不是很好,在low-frequence上的表现却不错。关于什么是high frequence和low frequence,可以参考:
通俗地说high frequence通常出现在边界上,而low frequence则通常出现在连续的表面;因此选择的方法是用L1去限制GAN在high frequence结构上进行建模。
3.那么如何对high frequence进行建模呢?——PatchGAN
1)将注意力限制在局部图片切片的结构上,提出了所谓的PatchGAN结构;
2)所谓的PatchGAN就是当我们判别一张图片是真还是假时,我们先将其分为NxN个patch之后进行判别的;
3)还可以以卷积地形式进行,即,即使用精度更小的图片训练出来的PatchGAN也可以用于精度更大的图片的判别,最后的输出结果取平均;
4)实验中证明Patch的N可以很小,意味着计算量更少,参数也会更少;
5)PatchGAN将图片建模成一个马尔科夫随机场,即,他认为在一个patch diameter距离之外的pixels之间是相互独立的。