欢迎来我的博客 http://www.blackblog.tech,我的简书 https://www.jianshu.com/u/55a1bc4688c6
前几日,学校期末作业要求我们使用机器学习的方法解决一个实际问题,思考了很久,尝试做了很多选题,最终决定做一个cDCGAN,即条件深度卷积生成对抗网络。
为什么做这个选题呢?
生成对抗网络这几年实在是火爆,图片上色,视频去马赛克,包括英伟达最近展出的白马变棕马,白天变黑夜,都是使用生成对抗网络实现的。
2014年”Generative Adversarial Nets”这篇论文中所提到的生成对抗网络是一个无监督的生成对抗网络,且没有使用卷积与反卷积操作。
今天我们以MNIST手写集为数据集,使用tensorflow实现cDCGAN(条件深度卷积生成对抗网络)
算法描述
生成对抗网络(Generative Adversarial Nets)启发自博弈论中的两人零和博弈,GAN模型中的两位博弈方分别有生成网络(Generator)与判别网络(Discriminator)充当。当生成网络G捕捉到样本数据分布,用服从某一分布的噪声z生成一个类似真实训练数据的样本,与真实样本越接近越好;判别网络D一般是一个二分类模型,在本文中D是一个多分类器,用于估计一个样本来自于真实数据的概率,如果样本来自于真实数据,则D输出大概率,否则输出小概率。本文中,判别网络需要在此基础上实现分类功能。
在训练的过程中,需要固定一方,更新另一方的网络状态,如此交替进行。在整个训练的过程中,双方都极力优化自己的网络,从而形成竞争对抗,知道双方达到一个动态的平衡。此时生成网络训练出来的数据与真实数据的分布几乎相同,判别网络也无法再判断出真伪。
本文中生成对抗网络主要分为两部分,生成网络(Generator)与判别网络(Discriminator)。向生成网络内输入噪声,通过多次反卷积的方式得到一个28x28x1的图像作为X_fake,此时将真实的图像X_real与生成器生成的X_fake放入判别网络,判别网络使用多次卷积与Sigmoid函数并通过交叉熵函数计算出判别网络的损失函数D_loss,通过判别网络的损失函数D_loss计算得到生成网络损失函数G_loss。使用G_loss与D_loss对生成网络与判别网络进行参数调整。
算法流程
1.输入噪声z
2.通过生成网络G得到X_fake=G(z)
3.从数据集中获取真实数据X_real
4.通过判别网络D计算D(real logits)=D(X_real)
5.通过判别网络D计算D(fake logits)=D(X_fake)
6.使用交叉熵函数做损失函数根据D(real logits)计算D(loss real)
7.使用交叉熵函数做损失函数根据D(fake logits)计算D(loss fake)
8.计算判别网络损失函数D_loss=D(loss real)+ D_(loss fake)
9.使用交叉熵函数做损失函数计算生成网络损失函数G_loss
10.使用D_loss对判别网络进行参数调整,使用G_loss对生成网络参数进行调整
网络结构
生成网络

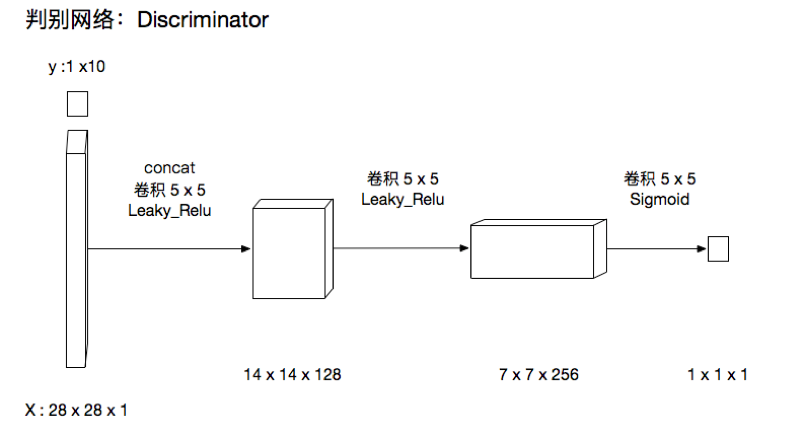
判别网络
数据集
MNIST…..
就不多说啥了
训练环境
系统:Windows 10
框架:tensorflow 1.2
CPU:Intel core i5-4210H
GPU:Nvidia GTX 960M 4G(买不起显卡……..)
上代码!
一些常量的定义,包括学校率,batch_size,保存的路径等等
import os, time, random,itertools
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import cv2
# 保存图片
dirpath = 'GAN/'
model = 'GAN_MINIST'
if not os.path.isdir(dirpath):
os.mkdir(dirpath)
if not os.path.isdir(dirpath + 'FakeImg'):
os.mkdir(dirpath + 'FakeImg')
# 初始化
IMAGE_SIZE = 28
onehot = np.eye(10)
noise_ = np.random.normal(0, 1, (10, 1, 1, 100))
fixed_noise_ = noise_
fixed_label_ = np.zeros((10, 1))
#用于最后显示十组图像
for i in range(9):
fixed_noise_ = np.concatenate([fixed_noise_, noise_], 0)
temp = np.ones((10, 1)) + i
fixed_label_ = np.concatenate([fixed_label_, temp], 0)
fixed_label_ = onehot[fixed_label_.astype(np.int32)].reshape((100, 1, 1, 10))
batch_size = 100
#一共迭代20次
step = 30
#设置一个全局的计数器
global_step = tf.Variable(0, trainable=False)
#设置学习率
lr = tf.train.exponential_decay(0.0002, global_step, 500, 0.95, staircase=True)
#加载数据集Batch大小:100
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True, reshape=[])leaky_relu的定义
def leaky_relu(X, leak=0.2):
f1 = 0.5 * (1 + leak)
f2 = 0.5 * (1 - leak)
return f1 * X + f2 * tf.abs(X)生成网络的定义:
def Generator(x, labels, Training=True, reuse=False):
with tf.variable_scope('Generator', reuse=reuse):
#初始化参数
W = tf.truncated_normal_initializer(mean=0.0, stddev=0.02)
b = tf.constant_initializer(0.0)
#把数据和标签进行连接
concat = tf.concat([x, labels], 3)
#第一次反卷积,卷积核大小为7*7,输出维度256
out_1 = tf.layers.conv2d_transpose(concat, 256, [7, 7], strides=(1, 1), padding='valid', kernel_initializer=W, bias_initializer=b)
out_1 = tf.layers.batch_normalization(out_1, training=Training)#batch norm
out_1 = leaky_relu(out_1, 0.2)
#第二次反卷机,卷积核大小为5*5,输出维度128
out_2 = tf.layers.conv2d_transpose(out_1, 128, [5, 5], strides=(2, 2), padding='same', kernel_initializer=W, bias_initializer=b)
out_2 = tf.layers.batch_normalization(out_2, training=Training)#batch norm
out_2 = leaky_relu(out_2, 0.2)
#第三次反卷机,卷积核大小5*5,输出维度1
out_3 = tf.layers.conv2d_transpose(out_2, 1, [5, 5], strides=(2, 2), padding='same', kernel_initializer=W, bias_initializer=b)
out_3 = tf.nn.tanh(out_3)
return out_3判别网络的定义
def Discriminator(x, real, Training=True, reuse=False):
with tf.variable_scope('Discriminator', reuse=reuse):
#初始化参数
W = tf.truncated_normal_initializer(mean=0.0, stddev=0.02)
b = tf.constant_initializer(0.0)
#把数据和标签进行连接
concat = tf.concat([x, real], 3)
#第一次卷积 卷积核为5*5 输出维度为128
out_1 = tf.layers.conv2d(concat, 128, [5, 5], strides=(2, 2), padding='same', kernel_initializer=W, bias_initializer=b)
out_1 = leaky_relu(out_1, 0.2)
# 第二次卷积 卷积核为5*5 输出维度256
out_2 = tf.layers.conv2d(out_1, 256, [5, 5], strides=(2, 2), padding='same', kernel_initializer=W, bias_initializer=b)
out_2 = tf.layers.batch_normalization(out_2, training=Training)#batch norm
out_2 = leaky_relu(out_2, 0.2)
#第三次卷积,卷积和为7*7,输出维度为1
out_3 = tf.layers.conv2d(out_2, 1, [7, 7], strides=(1, 1), padding='valid', kernel_initializer=W)
logits = tf.nn.sigmoid(out_3)
return logits, out_3输出图片
def show_result(num_epoch, show = False, save = False, path):
test_images = sess.run(G_noise, {noise: fixed_noise_, labels: fixed_label_, Training: False})
size_figure_grid = 10
fig, ax = plt.subplots(size_figure_grid, size_figure_grid, figsize=(5, 5))
for i, j in itertools.product(range(size_figure_grid), range(size_figure_grid)):
ax[i, j].get_xaxis().set_visible(False)
ax[i, j].get_yaxis().set_visible(False)
for k in range(10*10):
i = k // 10
j = k % 10
ax[i, j].cla()
ax[i, j].imshow(np.reshape(test_images[k], (IMAGE_SIZE, IMAGE_SIZE)), cmap='gray')
label = 'Step {0}'.format(num_epoch)
fig.text(0.5, 0.04, label, ha='center')
if save:
plt.savefig(path)
if show:
plt.show()
else:
plt.close()placeholder
x = tf.placeholder(tf.float32, shape=(None, IMAGE_SIZE, IMAGE_SIZE, 1))
noise = tf.placeholder(tf.float32, shape=(None, 1, 1, 100))
labels = tf.placeholder(tf.float32, shape=(None, 1, 1, 10))
real = tf.placeholder(tf.float32, shape=(None, IMAGE_SIZE, IMAGE_SIZE, 10))
Training = tf.placeholder(dtype=tf.bool)调整参数
# 运行生成网络哦
G_noise = Generator(noise, labels, Training)
# 运行判别网络
D_real, D_real_logits = Discriminator(x, real, Training)
D_fake, D_fake_logits = Discriminator(G_noise, real, Training, reuse=True)
# 计算每个网络的损失函数
#算判别器真值的损失函数
Dis_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real_logits, labels=tf.ones([batch_size, 1, 1, 1])))
#算判别器噪声生成图片的损失函数
Dis_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake_logits, labels=tf.zeros([batch_size, 1, 1, 1])))
#损失函数求和
Dis_loss = Dis_loss_real + Dis_loss_fake
#计算生成器的损失函数
Gen_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake_logits, labels=tf.ones([batch_size, 1, 1, 1])))
# 提取每个网络的变量
tf_vars = tf.trainable_variables()
Dis_vars = [var for var in tf_vars if var.name.startswith('Discriminator')]
Gen_vars = [var for var in tf_vars if var.name.startswith('Generator')]
# 调整参数 设计是用来控制计算流图的,给图中的某些计算指定顺序
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
optim = tf.train.AdamOptimizer(lr, beta1=0.5)#寻找全局最优点的优化算法,引入了二次方梯度校正 衰减率0.5
D_optim = optim.minimize(Dis_loss, global_step=global_step, var_list=Dis_vars)#优化更新训练的模型参数,也可以为全局步骤(global step)计数
G_optim = tf.train.AdamOptimizer(lr, beta1=0.5).minimize(Gen_loss, var_list=Gen_vars)#寻找全局最优点的优化算法,引入了二次方梯度校正 衰减率0.5
运行
# 开启一个session,
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
#对MNIST做一下处理
train_set = (mnist.train.images - 0.5) / 0.5
train_label = mnist.train.labels
for i in range(step):
Gen_losses = []
Dis_losses = []
i_start_time = time.time()
index = random.sample(range(0, train_set.shape[0]), train_set.shape[0])
new_set = train_set[index]
new_label = train_label[index]
for j in range(new_set.shape[0] // batch_size):
#对判别器进行更新
x_ = new_set[j*batch_size:(j+1)*batch_size]
label_ = new_label[j*batch_size:(j+1)*batch_size].reshape([batch_size, 1, 1, 10])
real_ = label_ * np.ones([batch_size, IMAGE_SIZE, IMAGE_SIZE, 10])
noise_ = np.random.normal(0, 1, (batch_size, 1, 1, 100))
loss_d_, _ = sess.run([Dis_loss, D_optim], {x: x_, noise: noise_, real: real_, labels: label_, Training: True})
#对生成器进行更新
noise_ = np.random.normal(0, 1, (batch_size, 1, 1, 100))
y_ = np.random.randint(0, 9, (batch_size, 1))
label_ = onehot[y_.astype(np.int32)].reshape([batch_size, 1, 1, 10])
real_ = label_ * np.ones([batch_size, IMAGE_SIZE, IMAGE_SIZE, 10])
loss_g_, _ = sess.run([Gen_loss, G_optim], {noise: noise_, x: x_, real: real_, labels: label_, Training: True})
#计算训练过程中的损失函数
errD_fake = Dis_loss_fake.eval({noise: noise_, labels: label_, real: real_, Training: False})
errD_real = Dis_loss_real.eval({x: x_, labels: label_, real: real_, Training: False})
errG = Gen_loss.eval({noise: noise_, labels: label_, real: real_, Training: False})
Dis_losses.append(errD_fake + errD_real)
Gen_losses.append(errG)
if(j%10==0):
pic = dirpath + 'FakeImg/' + model + str(i *new_set.shape[0] // batch_size + j+1) + '_' +str(i + 1) + '.png'
show_result((i + 1), save=True, path=pic)
print('判别器损失函数: %.6f, 生成器损失函数: %.6f' % np.mean(Dis_losses), np.mean(Gen_losses))
pic = dirpath + 'FakeImg/' + model + str(i + 1) + '.png'
show_result((i + 1), save=True, path=pic)
sess.close()生成结果
迭代了30次

总体的效果还是可以的,除了9有点看不清之外,0-8的轮廓还是很清晰的。
GAN的用途非常广泛,过几天在写一个生成脸部图片的网络。